




如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
1. 写在前面
生成式对抗网络(GAN)自2014年由Ian Goodfellow提出以来,一直是深度学习领域最引人注目的技术之一。它就像是两个AI模型在进行一场“猫鼠游戏”:一个负责制造假币(生成器),另一个负责识别假币(判别器)。随着博弈的进行,造假者的手段越来越高明,鉴别专家的眼力也越来越毒辣,最终我们就能得到一个能够以假乱真的生成模型。
本篇教程将带你使用MindSpore框架,从零开始构建并训练一个GAN模型。我们的目标很单纯:让模型学会自己“写”出数字来。我们将使用经典的MNIST手写数字数据集作为训练素材,通过全连接网络来实现生成器和判别器。
GAN图像生成:https://www.mindspore.cn/tutorials/zh-CN/master/generative/gan.html
1.1 准备工作与数据处理
在开始构建模型之前,我们需要先把数据准备好。MNIST数据集包含6万张训练图片和1万张测试图片,都是28x28像素的灰度图。
1.1.1 数据下载与加载
首先,我们需要下载数据集并进行解压。MindSpore提供了便捷的数据下载工具,可以轻松搞定这一步。
from download import download
# 下载并解压MNIST数据集
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip"
download(url, ".", kind="zip", replace=True)
下载完成后,我们需要构建数据管道。这里使用MindSpore的MnistDataset接口来加载数据,并进行必要的预处理,比如将像素值归一化、打乱顺序以及分批次(Batch)。
此外,我们还需要为生成器准备“原材料”——隐码(Latent Code)。隐码通常是从高斯分布中随机采样的向量,生成器就是根据这些随机噪声来生成图像的。
import numpy as np
import mindspore.dataset as ds
batch_size = 128
latent_size = 100 # 隐码的长度,即输入生成器的随机向量维度
train_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/train')
test_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/test')
def data_load(dataset):
# 将数据集转换为生成器数据集,指定列名
dataset1 = ds.GeneratorDataset(dataset, ["image", "label"], shuffle=True, python_multiprocessing=False)
# 数据增强与预处理
# 1. 将图像数据转换为float32
# 2. 生成对应的高斯分布随机噪声作为隐码
mnist_ds = dataset1.map(
operations=lambda x: (x.astype("float32"), np.random.normal(size=latent_size).astype("float32")),
output_columns=["image", "latent_code"]
)
# 只保留图像和隐码,丢弃标签(因为GAN是无监督学习,不需要标签)
mnist_ds = mnist_ds.project(["image", "latent_code"])
# 批量操作,drop_remainder=True表示丢弃最后不足一个batch的数据
mnist_ds = mnist_ds.batch(batch_size, True)
return mnist_ds
mnist_ds = data_load(train_dataset)
iter_size = mnist_ds.get_dataset_size()
print('Iter size: %d' % iter_size)
名词解释
- 隐码 (Latent Code): 可以理解为生成图像的“种子”。它是一个低维的随机向量,包含了生成图像的潜在特征信息。生成器的作用就是把这个看不懂的“种子”解码成我们能看懂的图像。
1.1.2 数据可视化与固定噪声构造
为了直观地看到我们正在处理什么样的数据,我们可以从数据集中取出一个Batch并显示出来。
import matplotlib.pyplot as plt
# 创建字典迭代器,获取一组数据
data_iter = next(mnist_ds.create_dict_iterator(output_numpy=True))
figure = plt.figure(figsize=(3, 3))
cols, rows = 5, 5
# 展示前25张图片
for idx in range(1, cols * rows + 1):
image = data_iter['image'][idx]
figure.add_subplot(rows, cols, idx)
plt.axis("off")
plt.imshow(image.squeeze(), cmap="gray")
plt.show()

在训练过程中,为了能客观地评估生成器的进步,我们需要一组固定的“考题”。我们在训练开始前就生成一批固定的随机噪声,在每个Epoch结束后,都用这同一批噪声让生成器生成图像。这样,我们就能通过肉眼观察图像质量的变化,来判断生成器是不是真的在变强。
import random
from mindspore import Tensor, dtype
# 设置随机种子,保证每次运行结果一致
np.random.seed(2323)
# 创建25个长度为100的随机向量,作为测试用的固定隐码
test_noise = Tensor(np.random.normal(size=(25, 100)), dtype.float32)
random.shuffle(test_noise)
1.2 模型构建
GAN的核心在于两个网络的博弈:生成器(Generator)和判别器(Discriminator)。
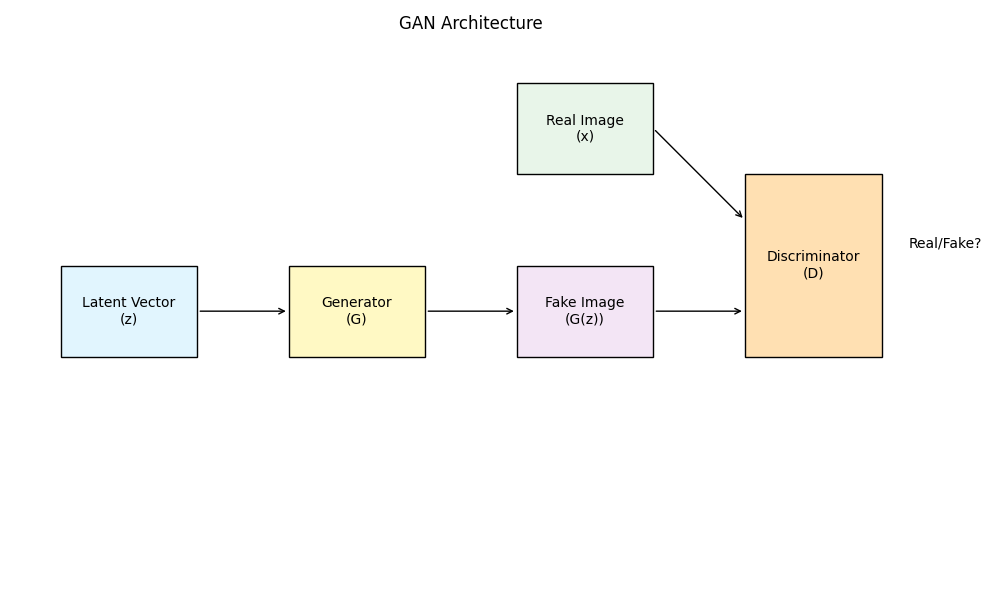
考虑到MNIST图片比较简单(单通道、尺寸小),我们不需要使用复杂的卷积网络,简单的全连接网络(Dense Layer)配合ReLU激活函数就足以胜任。
1.2.1 生成器 (Generator)
生成器的任务是“无中生有”。它接收一个100维的随机向量,经过层层放大和变换,最终输出一个28x28的图像矩阵。
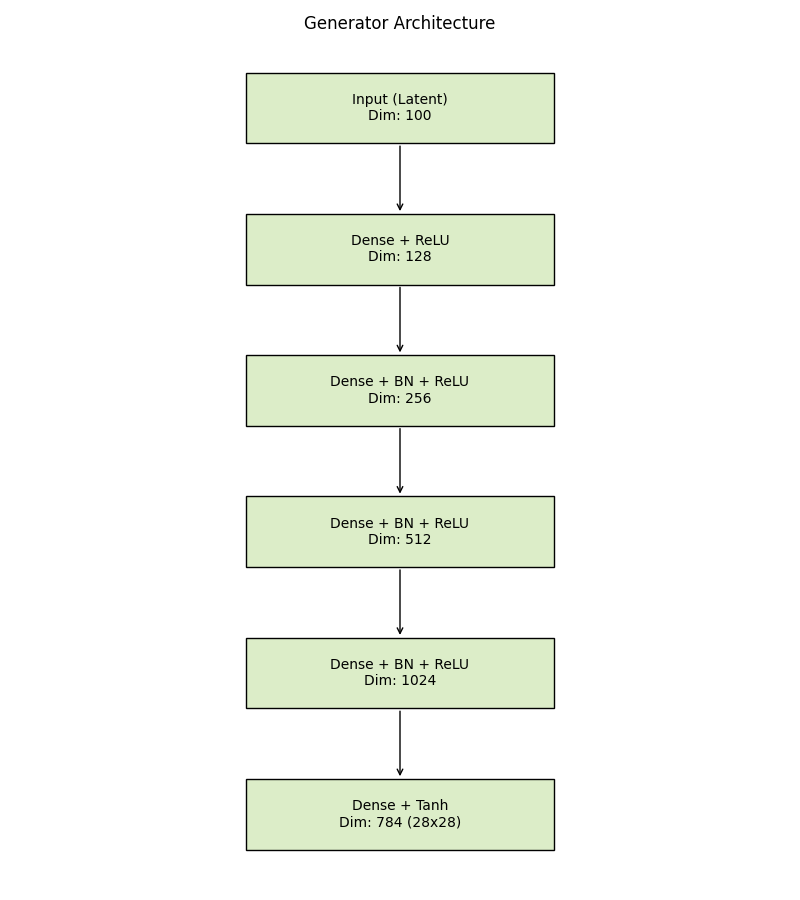
我们在输出层使用Tanh激活函数,将像素值映射到[-1, 1]区间。这是一种常见的做法,因为Tanh函数的输出中心是0,有助于模型的收敛。
from mindspore import nn
import mindspore.ops as ops
img_size = 28 # 图像尺寸
class Generator(nn.Cell):
def __init__(self, latent_size, auto_prefix=True):
super(Generator, self).__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell()
# 第一层:将100维隐码映射到128维
self.model.append(nn.Dense(latent_size, 128))
self.model.append(nn.ReLU())
# 第二层:128 -> 256
self.model.append(nn.Dense(128, 256))
self.model.append(nn.BatchNorm1d(256))
self.model.append(nn.ReLU())
# 第三层:256 -> 512
self.model.append(nn.Dense(256, 512))
self.model.append(nn.BatchNorm1d(512))
self.model.append(nn.ReLU())
# 第四层:512 -> 1024
self.model.append(nn.Dense(512, 1024))
self.model.append(nn.BatchNorm1d(1024))
self.model.append(nn.ReLU())
# 输出层:1024 -> 784 (28*28)
self.model.append(nn.Dense(1024, img_size * img_size))
# 使用Tanh将输出值压缩到[-1, 1]
self.model.append(nn.Tanh())
def construct(self, x):
img = self.model(x)
# 将平铺的向量重塑回图像形状 (N, 1, 28, 28)
return ops.reshape(img, (-1, 1, 28, 28))
net_g = Generator(latent_size)
net_g.update_parameters_name('generator')
1.2.2 判别器 (Discriminator)
判别器的任务是“明辨真伪”。它接收一张图片(无论是真实的还是生成的),输出一个0到1之间的概率值。1代表它认为这是真图,0代表是假图。
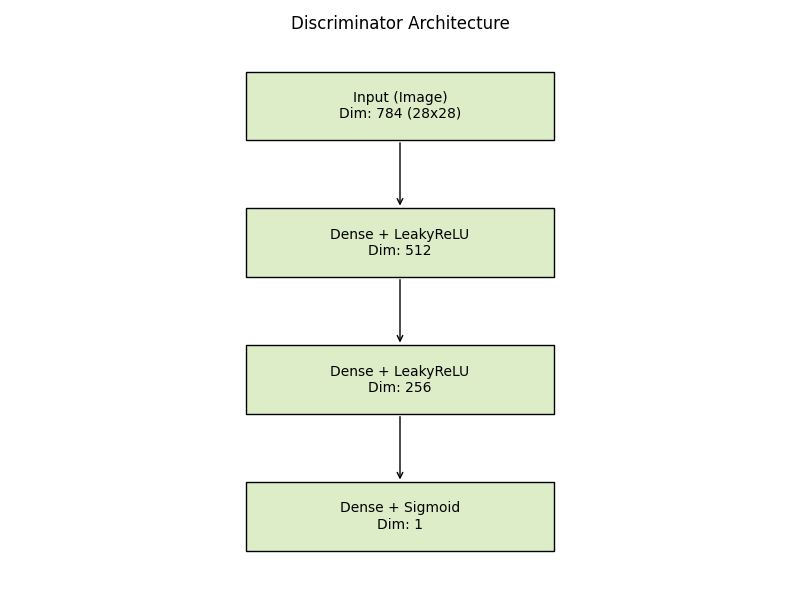
这里我们使用LeakyReLU作为激活函数,它在负值区间也有一个很小的斜率,可以避免神经元“死亡”的问题。输出层使用Sigmoid函数,将结果压缩成概率值。
class Discriminator(nn.Cell):
def __init__(self, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell()
# 输入层:接收平铺后的784维图像向量
# [N, 784] -> [N, 512]
self.model.append(nn.Dense(img_size * img_size, 512))
self.model.append(nn.LeakyReLU())
# 中间层:512 -> 256
self.model.append(nn.Dense(512, 256))
self.model.append(nn.LeakyReLU())
# 输出层:256 -> 1
self.model.append(nn.Dense(256, 1))
# Sigmoid输出概率
self.model.append(nn.Sigmoid())
def construct(self, x):
# 将图像展平
x_flat = ops.reshape(x, (-1, img_size * img_size))
return self.model(x_flat)
net_d = Discriminator()
net_d.update_parameters_name('discriminator')
1.2.3 损失函数与优化器
我们要同时训练两个网络,所以需要定义两个优化器。这里都选用Adam优化器。
损失函数使用二进制交叉熵损失(BCELoss),这在二分类问题中非常标准。
lr = 0.0002 # 学习率
# 二进制交叉熵损失函数
adversarial_loss = nn.BCELoss(reduction='mean')
# 分别为生成器和判别器定义优化器
optimizer_d = nn.Adam(net_d.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999)
optimizer_g = nn.Adam(net_g.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999)
# 更新参数名称,防止冲突
optimizer_g.update_parameters_name('optim_g')
optimizer_d.update_parameters_name('optim_d')
1.3 训练过程
训练GAN就像是在维持一种微妙的平衡。我们需要交替训练判别器和生成器:
-
训练判别器:
- 给它看真图,希望它输出1。
- 给它看生成器造的假图,希望它输出0。
- 计算两部分的损失,更新判别器的参数。
-
训练生成器:
- 生成一批假图,给判别器看。
- 这次我们希望骗过判别器,也就是希望判别器输出1。
- 计算损失,更新生成器的参数。
MindSpore的函数式编程风格在这里体现得很明显,我们定义了前向计算函数,然后利用value_and_grad自动获取梯度。
import os
import time
import mindspore as ms
from mindspore import save_checkpoint
# 训练配置
total_epoch = 200
checkpoints_path = "./result/checkpoints"
image_path = "./result/images"
# 确保目录存在
os.makedirs(checkpoints_path, exist_ok=True)
os.makedirs(image_path, exist_ok=True)
# 生成器的前向计算与损失
def generator_forward(test_noises):
fake_data = net_g(test_noises)
fake_out = net_d(fake_data)
# 生成器的目标是让判别器认为这些假图是真图(标签为1)
loss_g = adversarial_loss(fake_out, ops.ones_like(fake_out))
return loss_g
# 判别器的前向计算与损失
def discriminator_forward(real_data, test_noises):
# 造假图
fake_data = net_g(test_noises)
# 判别器看假图
fake_out = net_d(fake_data)
# 判别器看真图
real_out = net_d(real_data)
# 真图的标签应该是1
real_loss = adversarial_loss(real_out, ops.ones_like(real_out))
# 假图的标签应该是0
fake_loss = adversarial_loss(fake_out, ops.zeros_like(fake_out))
loss_d = real_loss + fake_loss
return loss_d
# 自动微分,获取梯度函数
grad_g = ms.value_and_grad(generator_forward, None, net_g.trainable_params())
grad_d = ms.value_and_grad(discriminator_forward, None, net_d.trainable_params())
def train_step(real_data, latent_code):
# 1. 训练判别器
loss_d, grads_d = grad_d(real_data, latent_code)
optimizer_d(grads_d)
# 2. 训练生成器
loss_g, grads_g = grad_g(latent_code)
optimizer_g(grads_g)
return loss_d, loss_g
# 辅助函数:保存生成的图片
def save_imgs(gen_imgs1, idx):
for i3 in range(gen_imgs1.shape[0]):
plt.subplot(5, 5, i3 + 1)
# 将像素值从[-1, 1]还原到[0, 1]用于显示
plt.imshow(gen_imgs1[i3, 0, :, :] / 2 + 0.5, cmap="gray")
plt.axis("off")
plt.savefig(image_path + "/test_{}.png".format(idx))
# 开启训练模式
net_g.set_train()
net_d.set_train()
losses_g, losses_d = [], []
print("开始训练...")
for epoch in range(total_epoch):
start = time.time()
for (iter, data) in enumerate(mnist_ds):
image, latent_code = data
# 将图片数据归一化到[-1, 1]
image = (image - 127.5) / 127.5
image = image.reshape(image.shape[0], 1, image.shape[1], image.shape[2])
# 执行一步训练
d_loss, g_loss = train_step(image, latent_code)
if iter % 100 == 0:
print(f"Epoch:[{epoch:3d}/{total_epoch:3d}], step:[{iter:4d}], "
f"loss_d:{d_loss.asnumpy():.4f}, loss_g:{g_loss.asnumpy():.4f}")
# 记录损失
losses_d.append(d_loss.asnumpy())
losses_g.append(g_loss.asnumpy())
# 每个epoch结束后,生成一张测试图,看看效果
gen_imgs = net_g(test_noise)
save_imgs(gen_imgs.asnumpy(), epoch)
# 保存模型权重
if epoch % 10 == 0: # 每10个epoch保存一次,避免文件过多
save_checkpoint(net_g, checkpoints_path + "/Generator%d.ckpt" % (epoch))
save_checkpoint(net_d, checkpoints_path + "/Discriminator%d.ckpt" % (epoch))
print("训练结束!")
1.4 结果分析与推理
训练完成后,我们最关心的当然是效果。
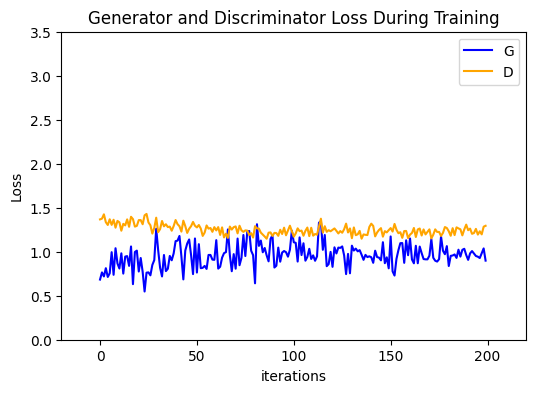
1.4.1 损失曲线
观察损失曲线可以帮助我们判断模型是否收敛。理想情况下,生成器和判别器的损失应该在某个值附近波动,呈现出一种胶着状态。如果一方的损失迅速降为0,说明另一方太弱了,博弈失败。
plt.figure(figsize=(6, 4))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(losses_g, label="G", color='blue')
plt.plot(losses_d, label="D", color='orange')
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
1.4.2 加载模型进行推理
既然模型已经训练好了,我们就可以把训练好的权重加载进来,随时生成我们需要的手写数字。这一步在实际应用中非常重要,被称为“推理”。
# 加载之前保存的第199个epoch的权重
test_ckpt = './result/checkpoints/Generator199.ckpt'
parameter = ms.load_checkpoint(test_ckpt)
ms.load_param_into_net(net_g, parameter)
# 生成新的随机噪声
# 这里的噪声维度必须和训练时保持一致(100维)
test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32))
# 推理:让生成器生成图片
# transpose是将数据格式从(N, C, H, W)转换为(N, H, W, C)以便matplotlib显示
images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy()
# 展示结果
fig = plt.figure(figsize=(3, 3), dpi=120)
for i in range(25):
fig.add_subplot(5, 5, i + 1)
plt.axis("off")
plt.imshow(images[i].squeeze(), cmap="gray")
plt.show()

如果一切顺利,你应该能看到25个像模像样的手写数字。虽然它们可能不如人类书写得那么完美,但考虑到这是由一堆随机数“凭空”变出来的,这已经足够神奇了。
2. 总结
通过这个实战项目,我们完整地走过了GAN的开发流程:从数据准备、模型搭建,到对抗训练和最终推理。
GAN的训练通常比普通神经网络要困难,因为它涉及两个网络的动态博弈,容易出现模式崩塌(Mode Collapse)或不收敛的问题。但在本例中,通过简单的全连接网络和MNIST数据集,我们成功验证了GAN的强大能力。
这只是生成式AI的冰山一角。掌握了基础的GAN之后,你可以进一步探索DCGAN(深度卷积GAN)、CycleGAN(图像风格迁移)等更高级的模型,去创造更多不可思议的内容。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











