







说明
1.本篇文章是对书上3到5章的回顾思考,对书上有疑惑的一些地方进行补充说明(红字标明),很多地方未涉及,如果忘了再番薯(翻书)吧。
2.只给出部分实验截图。
正文
表 3.2 SQL的动词
| SQL功能 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE,DROP,ALTER |
| 数据操作 | INSERT,UPDATE,DELETE |
| 数据控制 | GRANT,REVOKE |
第三章 关系数据库标准语言SQL
3.3 数据定义
表 3.3 SQL的数据定义语句
| 操作对象 | 操作方式 | ||
| 创建 | 删除 | 修改 | |
| 模式 | CREATE SCHEMA | DROP SCHEMA | |
|---|---|---|---|
| 表 | CREATE TABLE | DROP TABLE | ALTER TABLE |
| 视图 | CREATE VIEW | DROP VIEW | |
| 索引 | CREATE INDEX | DROP INDEX | ALTER INDEX |
3.3.1 模式的定义与删除
1.定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>;
定义模式实际上定义了一个命名空间,在这个空间中可以进一步定义该模式包含的数据库对象,例如基本表、视图、索引等。
例 3.3 为用户ZHANG创建一个模式TEST,并且在其中定义一个表TAB1。
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1(COL1 SMALLINT,
COL2 INT,
COL3 CHAR(20),
COL4 NUMERIC(10,3),
COL5 DECIMAL(5,2)
);
TAB1表是在用户ZHANG的架构(模式)TEST下创建的。

2.删除模式
DROP SCHEMA<模式名><CASCADE>|<RESTRICT>;
注意:SQL SERVER 不支持 CASCADE(级联),想要删除模式TEST,需先删除TEST下创建的数据库对象。
DROP SCHEMA TEST CASCADE
3.3.2 基本表的定义、删除与定义
3.模式与表
每一个基本表都属于某一个模式,一个模式包含多个基本表。
方法三,设置所属的模式,这样在创建表时表名中不必给出模式名。
当用户创建基本表(其他数据库对象也一样)时若没有指定模式,系统根据搜索路径(search path)来确定该对象所属的模式。
搜索路径包含一组模式列表,关系数据库管理系统会使用模式列表中第一个存在的模式作为数据库对象的模式名。若搜索路径中的模式名都不存在,系统将给出错误。
使用下面的语句可以显示当前的搜索路径:
SHOW search_path:
搜索路径的当前默认值是$user, PUBLIC。其含义是首先搜索与用户名相同的模式名,如果该模式名不存在,则使用 PUBLIC模式。
数据库管理员也可以设置搜索路径,例如:
SET search_path TO"S-T", PUBLIC;
然后,定义基本表:
CREATE TABLE Student(…);
实际结果是建立了S_T.Student基本表。因为关系数据库管理系统发现搜索路径中第一个模式名S-T存在,就把该模式作为基本表 Student所属的模式。
新建查询,SQL的默认模式为dbo,直接 CREATE TABLE创建的表归用户dbo的模式dbo。
3.4 数据查询
3.4.1 单表查询
2.选择表中的若干元组
(2)查询满足条件的元组
④ 字符匹配
语法格式: [NOT] LIKE ‘<匹配串>′ [ESCAPE ‘<换码字符>′ ]
% (百分号)代表任意长度(长度可以为0)的字符串。例如a%b表示以a开头,以b结尾的任意长度的字符串。
_ (下划线)代表任意单个字符。例如a_b表示以a开头,以b结尾的长度为3的任意字符串
SQL SERVER里一个 _(下横线)就可以表示一个汉字
例 3.35 查询以“DB_”开头,且倒数第三个字符为i的课程的详细情况
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i__'ESCAPE'\';
匹配串’DB_%i__'中第一个_因前有 ’ \ ‘,被转义成普通字符’’。i后面的两个’'仍作通配符
5.GROUP BY 子句
GROUP BY子句将查询结果按某一列或多列的值分组值相等的为一组。
对查询结果分组的目的是为了细化聚集函数的作用对象。如果未对查询结果分组,聚集函数将作用于整个查询结果,如前面的例3.41~3.45。分组后聚集函数将作用于每一个组,即每一组都有一个函数值。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*)>=3;

HAVING短语作用于组,从中选择满足条件的组。
3.4.2 连接查询
2.自身连接
连接操作不仅可以在两个表之间进行,也可以是一个表与自己进行连接,称为表的自身连接
为Course表取两个别名,一个是First,另一个是SECOND
FIRST表(Course表)

SECOND表(Course表)
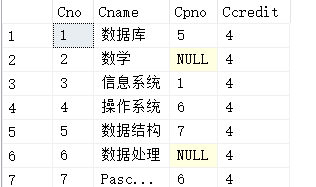
SELECT FIRST.Cno,SECOND.Cpno
FROM Course FIRST,Course SECOND
WHERE FIRST.Cpno=SECOND.Cno;

3.外连接
在通常的连接操作中,只有满足连接条件的元组才能作为结果输出。如例3.49的结果表中没有201215123和201215125两个学生的信息,原因在于他们没有选课,在SC表中没有相应的元组,导致 Student中这些元组在连接时被舍弃了。
有时想以 Student表为主体列出每个学生的基本情况及其选课情况。若某个学生没有选课,仍把 Student的悬浮元组保存在结果关系中,而在SC表的属性上填空值NULL,这时就需要使用外连接。
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUTER JOIN SC ON(Student.Sno=SC.Sno);

使用USING来去掉结果中的重复值
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUTER JOIN SC USING(Sno);
3.4.3 嵌套查询
3.外连接
例 3.57 找出每个学生超过他自己选修课程平均成绩的课程号
SELECT Sno,Cno
FROM SC x
WHERE Grade>=(SELECT AVG(Grade) /*某学生的平均成绩*/
FROM SC y
WHERE y.Sno=x.Sno);
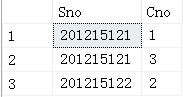
x是表SC的别名,又称为元组变量,可以用来表示SC的一个元组。内层查询是求个学生所有选修课程平均成绩的,至于是哪个学生的平均成绩要看参数x.Sno的值,而该值是与父查询相关的,因此这类查询称为相关子查询
理解:
(1) 从外层查询中取出SC的一个元组x,将元组x的Sno值 (201215121)传送给内层查询
SELECT AVG(Grade)
FROM SC y
WHERE y.Sno='201215121';
(2) 执行内层查询,得到值88(近似值,用该值代替内层查询,得到外层查询
SELECT Sno,Cno
FROM SC x
WHERE Grade>=88;
下面结果是分步得到的
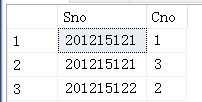
(3) 执行这个查询,得到
(201215121,1)
(201215121,3)
然后外层查询取出下一个元组重复做上述①至步骤的处理,直到外层的SC元组全部处理完毕。结果为
4.带有EXISTS谓词的子查询
带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”
例 3.62 查询选修了全部课程的学生姓名
//即没有一门课程是他不选的
SELECT Sname
FROM Student
WHERE NOT EXISTS
(SELECT*
FROM Course
WHERE NOT EXISTS
(SELECT*
FROM SC
WHERE Sno=Student.Sno AND Cno=Course.Cno));

3.4.4 集合查询
SELECT语句的查询结果是元组集合,所以多个SELECT语句的结果可进行集合操作。集合操作主要包括并操作UNION,交操作INTERSECT和差操作EXCEPT
例 3.66 查询计算机科学系的学生年龄不大于19岁的学生的交集
SELECT *
FROM Student
WHERE Sdept='CS'
INTERSECT
SELECT *
FROM Student
WHERE Sage<=19;

等价于
SELECT*
FROM Student
WHERE Sdept='CS' AND Sage<=19;
例 3.68 查询计算机科学系的学生年龄不大于19岁的学生的差集
SELECT*
FROM Student
WHERE Sdept='CS'
EXCEPT
SELECT*
FROM Student
WHERE Sage<=19;

等价于
SELECT *
FROM Student
WHERE Sdept='CS' AND Sage>19;
3.4.5 基于派生表的查询
子查询不仅可以出现在WHERE子句中,还可以出现在FROM中,这时子查询生成的临时派生表(不存在于Database里面)成为中查询查询对象
例 3.57 找出每个学生超过他自己选修课程平均成绩的课程号。
SELECT Sno,Cno
FROM SC,(SELECT Sno,Avg(Grade) FROM SC GROUP BY Sno)
AS Avg_sc(avg_sno,avg_grade)
WHERE SC.Sno=Avg_sc.avg_sno and SC.Grade>=Avg_sc.avg_grade

这里FROM子句中的子查询将生成一个派生表Avg_sc该表由 avg_sno和 avg_grade两个属性组成,记录了每个学生的学号及平均成绩。主查询将SC表 Avg_sc按学号相等进行连接,选出修课成绩大于其平均成绩的课程号。
如果子查询中没有聚集函数,派生表可以不指定属性列,子查询 SELECT子句后面的列名为其默认属性。例如例3.60查询所有选修了号课程的学生姓名,可以用如下查询完成:
SELECT Snmae
FROM Student,(SELECT Sno FROM SC WHERE Cno='1') AS SC1
WHERE Student.Sno=SC1.Sno;
3.7 视图
3.7.1 定义视图
1.建立视图
例 3.85 建立信息系学生的师徒并要求进行修改和插入操作时,仍需保证该视图只有信息系的学生
CREATE VIEW IS_Student
AS
SELECT Sno,Sname,Sage
FROM Student
WHERE Sdept='IS'
WITH CHECK OPTION;

关系数据库管理系统执行 CREATE VIEW语句的结果只是把视图的定义存入数据字典,并不执行其中的 SELECT语句。只是在对视图查询时,才按视图的定义从基本表中将数据査出。
由于在定义 IS_Student视图时加上了 WITH CHECK OPTION子句,以后对该视图进行插入、修改和删除操作时,关系数据库管理系统会自动加上 Sdept='IS’的条件。
若一个视图是从单个基本表导出的,并且只是去掉了基本表的某些行和某些列,但保留了主码,则称这类视图为行列子集视图。IS_Student视图就是一个行列子集视图。
视图不仅可以建立在单个基本表上,也可以建立在多个基本表上。
例 3.86 建立信息系选修了1号课程的学生的视图(包括学号、姓名、成绩)。
CREATE VIEW IS_S1(Sno,Sname,Grade)
AS
SELECT Student.Sno,Sname,Grade
FROM Student,SC
WHERE Sdept='IS' AND Student.Sno=SC.Sno AND SC.Cno='1';
例 3.89 将学生的学号及平均成绩定义为一个视图。
CREATE VIEW S_G(Sno,Gavg)
AS
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno;

由于AS子句中 SELECT语句的目标列平均成绩是通过作用聚集函数得到的,所以 CREATE VIEW中必须明确定义组成SG视图的各个属性列名。S_G是一个分组视图
2.删除视图
例 3.91 删除视图BT_S和视图IS_S1
DROP VIEW BT_S; /*成功执行*/
DROP VIEW IS_S1; /*拒绝执行*/
执行此语句时由于IS_S1视图上还导出了IS_S2视图,所以该语句被拒绝执行。如果确定要删除,则使用级联删除语句:
DROP VIEW IS_S1 CASCADE;/*删除了视图IS_S1和由它导出的所有视图*/
3.7.1 查询视图
例 3.92 在信息系的学生的视图中找出年龄小于20岁的学生。
SELECT Sno,Sage
FROM IS_Student
WHERE Sage<20;

关系数据库管理系统执行对视图的查询时,首先进行有效性检查,检查查询中涉及的表、视图等是否存在。如果存在,则从数据字典中取出视图的定义,把定义中的子查询和用户的查询结合起来,转换成等价的对基本表的查询然后再执行修正了的查询。这一转换过程称为视图消解。
本例转换后的查询语句为:
SELECT Sno,Sage
FROM Student
WHERE Sdept='IS' AND Sage<20;
例 3.94 在S_G视图中查询平均成绩在90分以上的学生和平均成绩
SELECT*
FROM S_G
WHERE Gavg>=90;
SELECT Sno,AVG(Grade)
FROM SC
WHERE AVG(Grade)>=90
GROUP BY Sno
因为WHERE子句是不能用聚集函数作为条件表达式的,因此执行此修正后的查询将会出现语法错误。
//正确转换的查询语句应该是
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno
HAVING AVG(Grade)>=90;
SELECT*
FROM(SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno) AS S_G(Sno,Gavg)
WHERE Gavg>=80;

但定义视图并查询视图与基于派生表的查询是有区别的。视图一旦定义,其定义将水久保存在数据字典中,之后的所有查询都可以直接引用该视图。而派生表只是在语句执行时临时定义,语句执行后该定义即被删除。
3.7.1 更新视图
例 3.97 删除信息系学生视图IS_Student中学号为“201215129”的记录。
DELETE
FROM Student
WHERE Sno='201215129';
转换为对基本表的更新:
DELETE
FROM Student
WHERE Sno='201215129' AND Sdept='IS';
在关系数据库中,并不是所有的视图都是可更新的,因为有些视图的更新不能唯一地有意义地转换成对相应基本表的更新。
例如,例3.89定义的视图S_G是由学号和平均成绩两个属性列组成的,其中平均成绩一项是由 Student表中对元组分组后计算平均值得来的:
CREATE VIEW S_G(Sno,Gavg)
AS
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno;
如果想把视图SG中学号为“201215121”的学生的平均成绩改成90分,SQL语句如下:
UPDATE S_G
SET Gavg=90
WHERE Sno='201215121';
但这个对视图的更新是无法转换成对基本表SC的更新的,因为系统无法修改各科成绩,以使平均成绩成为90。所以S_G视图是不可更新的。
第四章 数据库安全性
4.2 数据库安全性控制
4.2.4 授权:授权与收回
SQL中使用 GRANT和 REVOKE语句向用户授予或收回对数据的操作权限。 GRANT语句向用户授予权限, REVOKE语句收回己经授予用户的权限。
1.GRANT
GRANT语句的一般格式为:
GRANT<权限> [,<权限>]···
ON <对象类型> <对象名>[,<对象类型> <对象名>]···
TO<用户> [,<用户>]···
[WITH GRANT OPTION];
其语义为:将对指定操作对象的指定操作权限授予指定的用户。发出该 GRANT语句的可以是数据库管理员,也可以是该数据库对象创建者(即属主 owner),还可以是已经拥有该权限的用户。接受权限的用户可以是一个或多个具体用户,也可以是 PUBLIC,即全体用户
如果指定了 WITH GRANT OPTION子句则获得某种权限的用户还可以把这种权限再授予其他的用户。如果没有指定 WITH GRANT OPTION子句,则获得某种权限的用户只能使用该权限,不能传播该权限。
SQL标准允许具有 WITH GRANT OPTION的用户把相应权限或其子集传递授予其他用户,但不允许循环授权,即被授权者不能把权限再授回给授权者或其祖先。

新建用户名U1—U7,和相应的登录名
注意:登录名必须映射到数据库用户才能连接到数据库。 一个登录名可以作为不同用户映射到不同的数据库,但在每个数据库中只能作为一个用户进行映射
CREATE LOGIN U_1 WITH PASSWORD='12345';--新建登录名U_1
CREATE USER U1 FOR LOGIN U_1; --新建用户名
CREATE LOGIN U_2 WITH PASSWORD='12345';
CREATE USER U2 FOR LOGIN U_2;
CREATE LOGIN U_3 WITH PASSWORD='12345';
CREATE USER U3 FOR LOGIN U_3;
CREATE LOGIN U_4 WITH PASSWORD='12345';
CREATE USER U4 FOR LOGIN U_4;
CREATE LOGIN U_5 WITH PASSWORD='12345';
CREATE USER U5 FOR LOGIN U_5;
CREATE LOGIN U_6 WITH PASSWORD='12345';
CREATE USER U6 FOR LOGIN U_6;
CREATE LOGIN U_7 WITH PASSWORD='12345';
CREATE USER U7 FOR LOGIN U_7;
例 4.4 把查询STUDENT表和修改学生学号的权限授权给用户U4。
GRANT UPDATE(Sno),SELECT
ON TABLE Student
TO U4;
这里,实际上要授予U4用户的是对基本表 Student的 SELECT权限和对属性列Sno的 UPDATE权限。对属性列授权时必须明确指出相应的属性列名。
例 4.5 把对表SC的 INSERT权限授予U5用户,并允许将此权限再授予其他用户。
GRANT INSERT
ON TABLE SC
TO U5
WITH GRANT OPTION;
执行此SQL语句后,U5不仅拥有了对表SC的 INSERT权限,还可以传播此权限,即由U5用户发上述 GRANT命令给其他用户。例如U5可以将此权限授予U6(例4.6)
例 4.6
GRANT INSERT
ON TABLE SC
TO U6
WITH GRANT OPTION;
同样,U6还可以将此权限授予U7(例 4.7)
例 4.7
GRANT INSERT
ON TABLE SC
TO U7;
因为U6未给U7传播的权限,因此U7不能再传播此权限。
2.REVOKE
授予用户的权限可以由数据库管理员或其他授权者用 REVOKE语句收回, REVOKE语句的一般格式为
REVOKE <权限>[,<权限>]···
ON<对象类型><对象名>[,<对象类型><对象名
FROM<用户> [,<用户> ]··· [CASCADE|RESTRICT ];
例 4.10 把用户U5对SC表的INSERT权限收回。
REVOKE INSERT
ON TABLE SC
FROM U5 CASCADE;
将用户U5的 INSERT权限收回的同时,级联(CASCADE)收回了U6和U7的 INSERT权限,否则系统将拒绝执行该命令。因为在例4.6中,U5将对s表的 INSERT权限授予了U6,而U6又将其授予了U7(例4.7)
注意:这里默认值为CASCADE,有的数据库管理系统默认值为 RESTRICT,将自动执行级联操作。如果U6或U7还从其他用户处获得对C表 INSERT的权限,则他们仍具有此权限,系统只收回直接或间接从U5处获得的权限。
4.2.5 数据库角色
数据库角色是被命名的一组与数据库操作相关的权限,角色是权限的集合。因此,可以为一组具有相同权限的用户创建一个角色,使用角色来管理数据库权限可以简化授权的过程。
在SQL中首先用 CREATE ROLE语句创建角色,然后用 GRANT语句给角色授权,用 REVOKE语句收回授予角色的权限。
例 4.11 通过角色来实现将一组权限授予一个用户。
步骤如下:
(1)首先创建一个角色R1。
CREATE ROLE R1;
(2)然后使用 GRANT语句,使角色R1拥有 Student表的 SELECT、 UPDATE、 INSERT权限。
GRANT SELECT,UPDATE,INSERT
ON TABLE Student
TO R1;
(3)将这个角色授予王平、张明、赵玲,使他们具有角色R1所包含的全部权限。
GRANT R1
TO 王平,张明,赵玲;
(4)当然,也可以一次性地通过R1来收回王平的这三个权限。
REVOKE R1
FROM 王平;
第五章 数据库完整性
5.7 触发器
例 5.22 将每次对表Student的插入操作所增加的学生个数记录到表StudentInsertLog中。
//标准sql
CREATE TRIGGER Student_Count
AFTER INSERT ON Student
REFERENCEING
NEW TABLE AS DELTA
FOR EACH STATEMENT
INSERT INTO StudentInsertLog(Numbers)
SELECT COUNT(*) FROM Student
//Tsql
CREATE TRIGGER Student_Count
ON Student
AFTER
INSERT
AS
INSERT INTO StudentInsertLog(Numbers)
SELECT COUNT(*) FROM Student
DELTA是一个关系名,其模式与Student相同,包含的元组是INSERT语句增加的元组。
8.3 存储过程和函数
8.3.1 存储过程
存储过程是由过程化SQL语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,因此称它为存储过程。
1.存储过程的优点
(1)运行效率高
(2)降低了客户机和服务器之间的通信量
(3)方便实施企业规则
2.存储过程的用户接口
1)创建存储过程
CREATE OR REPLACE PROCEDURE 过程名([参数1,参数2,…])
AS <过程化SQL块>;
例8.8:利用存储过程来实现下面的应用:从账户1转指定数额的款项到账户2中。
①首先要有账户表Account,建立并插入两条数据
drop table if exists Account;
create table Account(
accountnum char(3),-- 编号
total float -- 余额
);
insert into Account
values('101',50),('102',100);
select * from Account;
②创建存储过程
if (exists (select * from sys.objects where name = 'Proc_TRANSFER'))
drop procedure Proc_TRANSFER
go
create procedure Proc_TRANSFER
@inAccount int,@outAccount int,@amount float
/*定义存储过程TRANSFER,参数为转入账户、转出账户、转账额度*/
as
begin transaction TRANS
declare /*定义变量*/
@totalDepositOut float,
@totalDepositIn float,
@inAccountnum int;
/*检查转出账户的余额 */
select @totalDepositOut = total from Account where accountnum = @outAccount;
/*如果转出账户不存在或账户中没有存款*/
if @totalDepositOut is null
begin
print '转出账户不存在或账户中没有存款'
rollback transaction TRANS; /*回滚事务*/
return;
end;
/*如果账户存款不足*/
if @totalDepositOut < @amount
begin
print '账户存款不足'
rollback transaction TRANS; /*回滚事务*/
return;
end
/*检查转入账户的状态 */
select @inAccountnum = accountnum from Account where accountnum = @inAccount;
/*如果转入账户不存在*/
if @inAccountnum is null
begin
print '转入账户不存在'
rollback transaction TRANS; /*回滚事务*/
return;
end;
/*如果条件都没有异常,开始转账。*/
begin
update Account set total = total - @amount where accountnum = @outAccount; /* 修改转出账户余额,减去转出额 */
update Account set total = total + @amount where accountnum = @inAccount; /* 修改转入账户余额,增加转入额 */
print '转账完成,请取走银行卡'
commit transaction TRANS; /* 提交转账事务 */
return;
end
以下为标准sql写法
create procedure transfer(inAccount int,outAccount int,amount int)
as
declare totalDepositOut int,
totalDepositIn int,
inAccountnum int;
begin
select total_salary into totalDepositOut from Account where Account_id=outAccount;
if totalDepositOut is null then
rollback;
return;
end if;
if totalDepositOut<amount then
rollback;
return;
end if;
select total_salary into totalDepositIn from Account where Account_id=inAccount;
if totalDepositIn is null then
rollback;
return;
end if;
update Account set total_salary=total_salary-amount where Account_id=outAccount;
update Account set total_salary=total_salary+amount where Account_id=inAccount;
end;
call procedure transfer(1,2,100); --执行
SELECT INTO用于创建表的备份文件(复制表)
ROLLBACK:就是数据库里做修改后未COMMIT之前使用,rollback可以恢复数据到修改之前。
(2)执行存储过程
T-SQL是用EXEC,标准SQL是CALL或者PERFORM
(3)修改存储过程
ALTER { PROC | PROCEDURE } [schema_name.] procedure_name
[ { @parameterdata_type } [= ] ] [ ,…n ]
AS { [ BEGIN ] sql_statement [ ; ] [ ,…n ] [ END ] }
(4)删除存储过程
drop procedure 过程名;















 1542
1542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









