




 本文介绍了redisearch+springboot中创建JSON索引和添加JSON文档的方法。创建索引时可指定索引名称、数据类型等参数,索引与JSON文档关联同步。添加文档可用RedisJSON写入命令,还介绍了多种查询方式,如模糊查询、多条件查询等,且JSON方式比HASH更快。
本文介绍了redisearch+springboot中创建JSON索引和添加JSON文档的方法。创建索引时可指定索引名称、数据类型等参数,索引与JSON文档关联同步。添加文档可用RedisJSON写入命令,还介绍了多种查询方式,如模糊查询、多条件查询等,且JSON方式比HASH更快。
上一篇学习了redisearch+hash的使用redisearch+springboot的简单使用
FT.CREATE {index}
[ON {data_type}]
[PREFIX {count} {prefix} [{prefix} ..]
[LANGUAGE {default_lang}]
SCHEMA {identifier} [AS {attribute}]
[TEXT | NUMERIC | GEO | TAG ] [CASESENSITIVE]
[SORTABLE] [NOINDEX]] ...使用FT.CREATE命令可以建立索引,语法中的参数意义如下;
- index:索引名称;
- data_type:建立索引的数据类型,目前支持JSON或者HASH两种;
- PREFIX:通过它可以选择需要建立索引的数据前缀,比如
PREFIX 1 "product:"表示为键中以product:为前缀的数据建立索引; - LANGUAGE:指定TEXT类型属性的默认语言,使用chinese可以设置为中文;
- identifier:指定属性名称;
- attribute:指定属性别名;
- TEXT | NUMERIC | GEO | TAG:这些都是属性可选的类型;
- SORTABLE:指定属性可以进行排序。
创建索引
FT.CREATE 当您使用该命令创建JSON索引后,存储在数据库中的任何现有和未来的 JSON 文档会自动与之关联。
使用以下语法创建 JSON 索引:
FT.CREATE {index_name} ON JSON SCHEMA {json_path} AS {attribute} {type} 每个 JSONPath 表达式的结果(即json中的字段)都和索引中称为 attribute(以前hash中称为 field)的逻辑名称相关联。
例如,此命令创建一个索引,该索引代表 与JSON 文档中的name、description 、brandName和price相关联进行索引,设置索引语言为chinese:
> FT.CREATE itemIdx ON JSON LANGUAGE chinese SCHEMA $.name AS name TEXT $.description as description TEXT $.brandName AS brandName TAG $.price AS price NUMERIC SORTABLE
"OK"添加 JSON 文档
可以使用任何 RedisJSON 写入命令,例如JSON.SET和JSON.ARRAPPEND来创建或修改 JSON 文档。
因为索引与JSON文档是关联同步的,所以只要JSON.SET命令返回,文档就会在索引上可用。任何与索引内容匹配的后续查询都将返回该文档。
现在有这样2个JSON文档数据:
{
"name": "锤子8plus",
"description": "锤子手机-5G-128G",
"brandName":"锤子",
"price": 3299
}{
"name": "华为Mate40 pro",
"description": "HuaWei-5G-128G",
"brandName":"华为",
"price": 6499
}使用JSON.SET命令添加文档 (a1、a2表示文档的ID,唯一)
> JSON.SET a1 $ '{"name": "锤子8plus","description": "锤子手机-5G-128G","brandName":"锤子","price": 3299}'
"OK"
> JSON.SET a2 $ '{"name": "华为Mate40 pro","description": "HuaWei-5G-128G","brandName":"华为","price": 6499}'
"OK"1.建立完索引后,我们就可以使用FT.SEARCH对数据进行查看了,比如使用*可以查询全部;
FT.SEARCH itemIdx *
2.由于我们设置了price字段为SORTABLE,我们可以以price降序返回商品信息;
FT.SEARCH itemIdx * SORTBY price DESC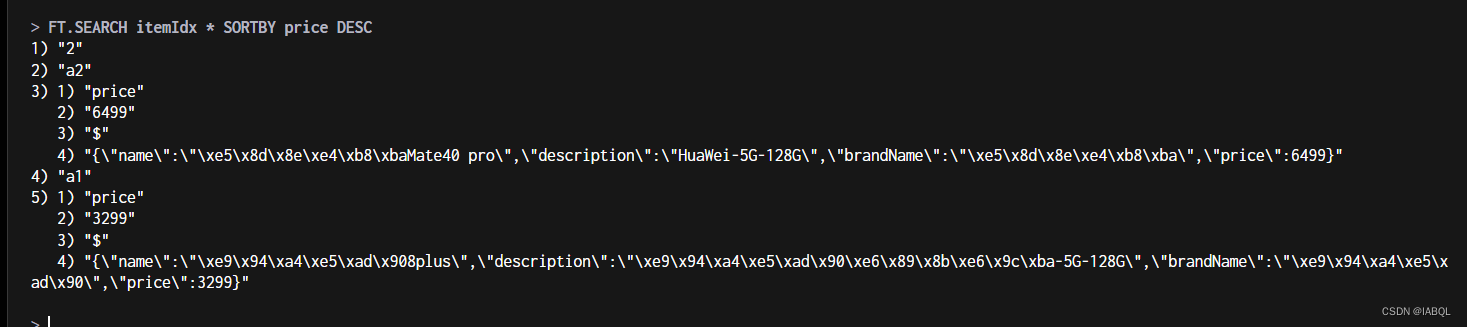
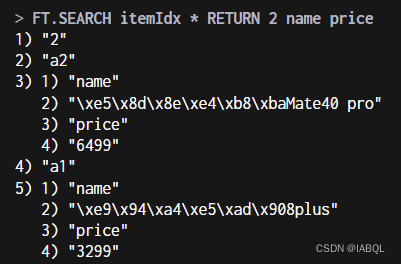
3.还可以返回指定字段的数据;
FT.SEARCH itemIdx * RETURN 2 name price表示返回2个字段,分别是name、price
4.我们把brandName设置为了TAG类型,我们可以使用如下语句查询品牌为华为或锤子的商品;
查询TAG类型,要用{}
FT.SEARCH itemIdx '@brandName:{华为 | 锤子}'
5.由于price是NUMERIC类型,我们可以使用如下语句查询价格在3000~4000的商品;
FT.SEARCH itemIdx '@price:[3000 4000]'
6.还可以使用像like一样的模糊查询,例:查询name以华为开头的
FT.SEARCH item '@name:华为*'
7.在FT.SEARCH中直接指定搜索关键词,可以对所有TEXT类型的属性进行全局搜索,支持中文搜索
FT.SEARCH itemIdx '手机'
8.也可以指定搜索的字段,比如搜索description中带有5G字段的商品;
FT.SEARCH itemIdx '@description:5G'
9.还可以搜索description中带有锤子和5G字段的商品;用空格表示AND
FT.SEARCH itemIdx '@description:(锤子 5G)'
10.还可以搜索description中带有锤子或5G字段的商品;用 | 代表或
FT.SEARCH itemIdx '@description:(锤子 | 5G)'
11.还可以多字段,多条件查询,例:搜索name中带有华为字段,并且price在5000~7000的商品
FT.SEARCH itemIdx '@name:(华为) @price:[5000,7000]'
12.还可以使用HIGHLIGHT来进行高亮显示效果(默认对搜索关键字加上<b></b>)
HIGHLIGHT必须跟在return后面,return 1 name表示返回一个name字段;对name字段高亮显示。测试了一下,高亮只对TEXT类型有效。
FT.SEARCH itemIdx '@name:(华为)' return 1 name HIGHLIGHT
13.如果高亮不想使用<b></b>,还可以用TAGS来设置自己想要的标签
FT.SEARCH itemIdx '@name:(华为)' return 1 name HIGHLIGHT TAGS '<p>' '</p>'
14.我们还可用limit来限制搜索返回的数量
FT.SEARCH itemIdx '@description:(5G)' limit 0 2
15.通过FT.DROPINDEX命令可以删除索引,如果不加DD只会删除索引,与索引关联的JSON文档不会删除;如果加入DD选项的话,会连数据一起删除;
FT.DROPINDEX itemIdx DD
使用JSON的方式与HASH相比,JSON更快。在对数据做修改时,hash需要删除整个文档再将修改后的文档添加,而json可以直接对文档中的某一字段修改。
用redisInsight可视化工具可以看到有这样一份文档
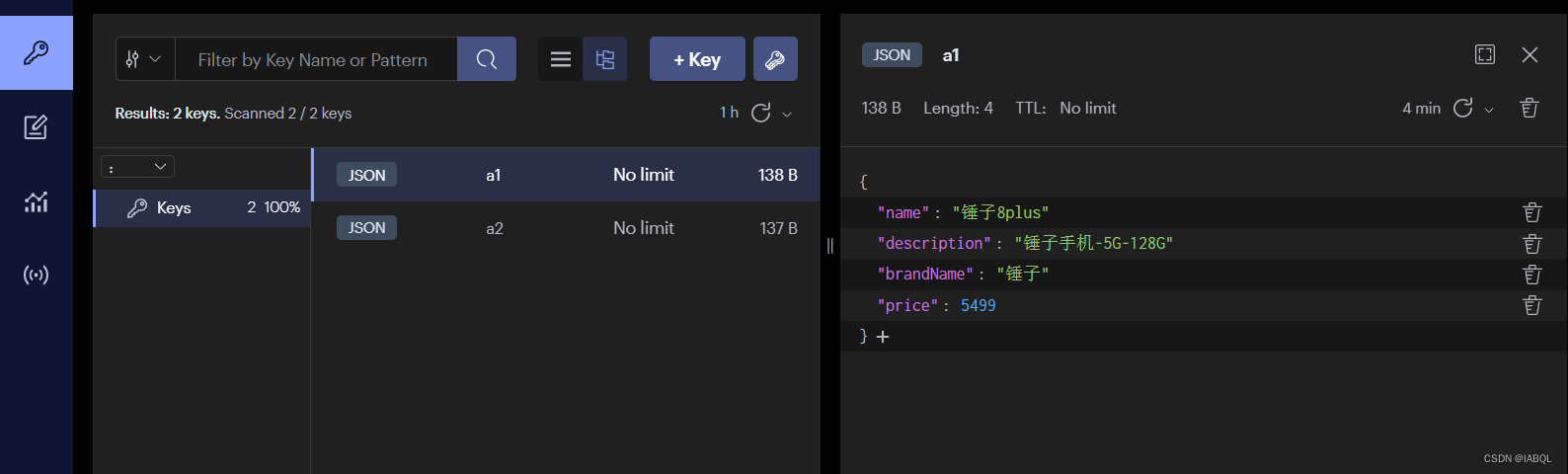
现在想要对文档中的price修改为3499;
在RedisJSON中,获取JSON对象中的属性时需要以 .开头
> JSON.SET a1 .price 3499
"OK"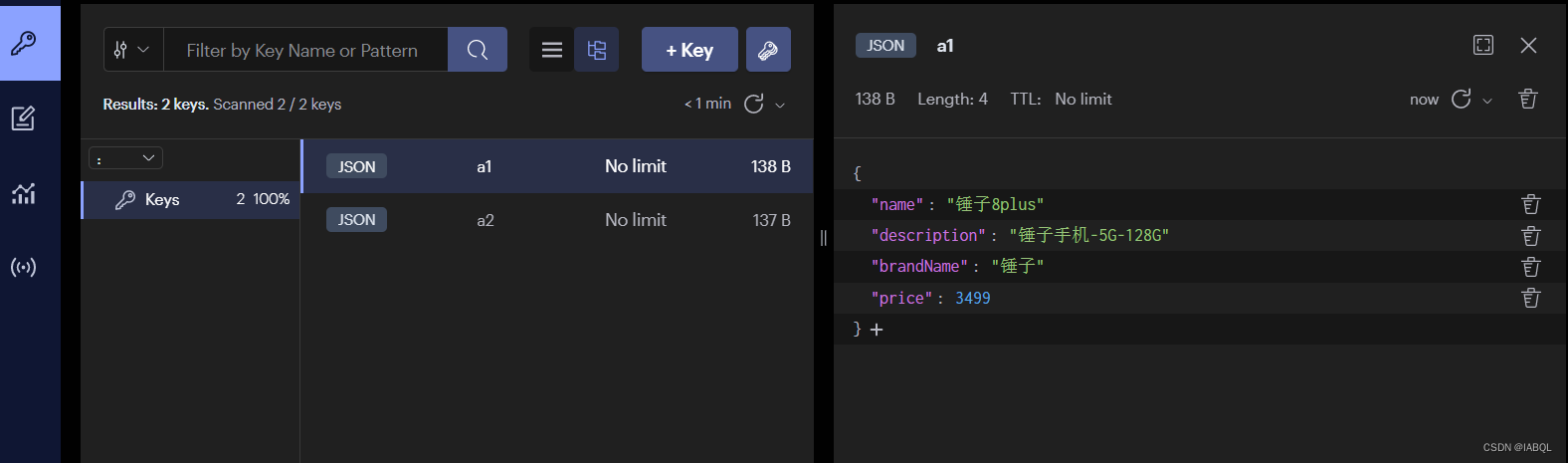
可以看到数据已经改变了。
还有更多的使用方式可以查看官网的介绍https://redis.io/docs/stack/search/indexing_json/#highlight-search-terms


















 1269
1269





 到【灌水乐园】发言
到【灌水乐园】发言









