







零基础入门深度学习
前言
接下来跟随书本中的教程,首先脱离框架尝试搭建一个神经网络,通过这个过程来了解一下深度学习中的一些基础概念,这里,就以波士顿房价预测的案例为例。在阅读书本资料的同时,也加入一些自己的理解。
由于内容过长阅读耐心也会下降,这里将其中最长的训练过程单独摘出来做一个章节。
一、问题定义——波士顿房价预测
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的HelloWorld,和大家对房价的认知相同,房价由很多因素影响,在该数据集中提供了13种可能影响房价的因素和该类房屋的均价,期望构建一个基于14个因素进行房价预测的模型。对于我们遇到的这类问题,一开始的时候,都要先认清要解决什么问题,根据所提供的问题和数据的特征,可以把问题分为分类任务还是回归任务,像这种具有连续值的数据,就可以直接当作回归任务来解决。
再细分一下,比如在视觉任务场景中,拿到数据后就要弄清楚这是一个分类任务、检测任务,还是一个分割任务。如果是分类任务,需要学习的标签有多少种,是否是细粒度类型,如果是检测任务,每张图片中要多目标进行检测,不同目标的交叉情况,标签的可靠程度等等,总之,别在一开始就走错了路。
二、构建模型流程
很多深度学习问题,尤其是有监督问题,都要经历这样一个流程,新手阶段遇到的问题,大致都是通用的。一般也以这四部分(数据读取和处理,模型结构,模型训练配置参数,模型训练文件)对代码进行拆分和组织,以保证训练过程的高效和可靠。
1.数据处理
- 1.1 读入数据
import numpy as np # 导入矩阵运算库
import json # 导入json库
# 读入训练数据
datafile='./work/housing.data'
data = np.fromfile(datafile, sep=' ') # data文件中默认分隔符
- 1.2 数据形状变换
# 读入数据是一维的,数据集中0-13个样本(14个值),14-27(14个值)等之后被粘合为了一行,需要按行拆分,
# 之后按组进行划分,以矩阵的方式处理训练集测试集会很方便。
feature_names = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS',
'RAD','TAX','PTRATIO','B','LSTAT','MEDV']
feature_nums = len(feature_names)
data = data.reshape([data.shape[0]//feature_num, feature_num])
- 1.3 数据集划分
数据集划分主要分为训练集、验证集和测试集,开始的时候很多地方只分训练集和验证集,或者也有只分训练集和测试集的,也未尝不可。
最标准的还是分三份,训练集用于学习规律存入模型,验证集用于一边建模型学习规律,一边验证模型所记录的规律是否可靠,有没有学走偏,测试集用于独立去评估规律的质量。
这里我们因为问题比较简单,只需要训练集和验证集也行。这里将数据集中80%做训练集,20%做测试集。
ratio = 0.8
offset = int(data.shape[0]*ratio) # 前80%行的行号
training_data = data[:offset] # 取矩阵的前80%行做训练集
training_data.shape
- 1.4 数据归一化处理
数据归一化对每个要学习的特征进行归一化处理,将每个特征的取值缩放到0~1范围,这样主要有两个作用,一个是模型的训练更加高效,另一个是特征前的权重大小可以代表该变量对预测结果的贡献度,换句话说就是只需要知道数据对这一维特征的贡献程度就行,不需要以精确的数值衡量。
# 计算train数据集的最大值,最小值和平均值
maximums, minimums, avgs = training_data.max(axis=0),\
training_data.min(axis=0),\
training_data.sum(axis=0)/training_data.shape[0]
for i in range(feature_num): # 对14个维度的特征全部进行处理
data[:, i] = (data[:,i] - minimums[i])/(maximums[i]-minimums[i]) # 将每一行[:]的第i列(0, 13)共14列的数据进行归一化
- 1.5 封装数据吞吐对象
这里将前面预处理得到数据的过程封装到一个函数中,并将训练集和测试集返回
import numpy as np # 导入矩阵运算库
import json # 导入json库
def load_data():
# 读入训练数据
datafile='./work/housing.data'
data = np.fromfile(datafile, sep=' ') # data文件中默认分隔符
feature_names = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS',
'RAD','TAX','PTRATIO','B','LSTAT','MEDV']
feature_nums = len(feature_names)
data = data.reshape([data.shape[0]//feature_num, feature_num])
ratio = 0.8
offset = int(data.shape[0]*ratio) # 前80%行的行号
training_data = data[:offset] # 取矩阵的前80%行做训练集
test_data = data[offset:]
# 获取数据
training_data, test_data = load_data()
x = training_data[:,:-1] # 取一个表格中除了最后一列的所有元素
y = training_data[:,-1:] # 取一个表格中的最后一列的所有元素
2.模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,内部实现的是模型前向计算的过程。如果将输入特征和输出预测值均以向量的形式表示,输入特征x有13个分量,y有1个分量,那么参数权重(待学习的抽象特征)的形状就是13*1。
这里还有一个权重赋值初始化的过程,在正规网络架构里面,也同样要经历这一步,定义合适的网络层权重初始化策略(比如下图中Paddle所支持的初始化策略,后面可以耐心慢慢学),可以很大程度上加快收敛速度,而不是盲目的在庞大空间里摸鱼。
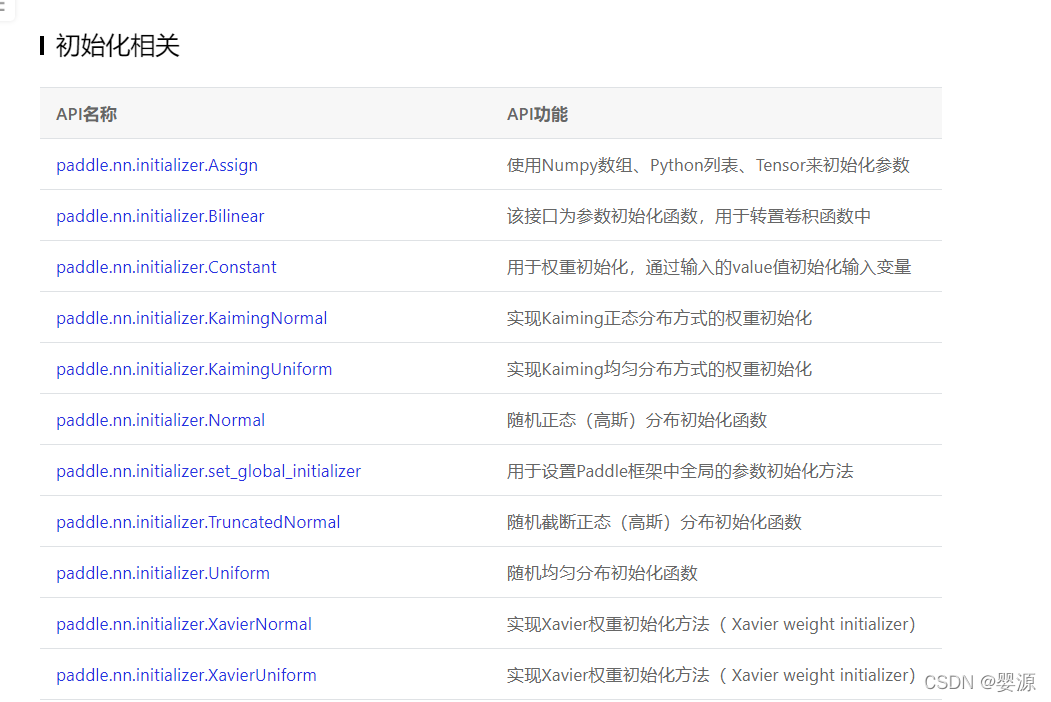
我们可以以下列数值进行初始化
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.shape(w).reshape([13, 1])
取出第一条样本数据,观察样本的特征向量与参数向量相乘的结果,并带上一个随机初始化的偏置项(线性回归中那条直线的偏移量)b=-0.2,完成从特征图和参数计算输出值的过程,即最简单的前向计算。
x1 = x[0] # 训练集数据集中的第一条数据
t = np.dot(x1, w) # 实现y=w*x+b中的w*x
print(t) # 输出w*x
b = -0.2 # 随机初始化的偏移量
z = t+b # 实现y=w*x+b
print(z) # 输出y=wx+b
将以上过程以类和对象的方式来描述,通过写一个代表前向计算的成员函数forward() 来完成上述通过对输入特征和初始化参数进行计算,得到输出预测值的过程,得到的就是一个最简单的单层线性回归模型。其他模型的组网也是类似于这样组织的代码[paddle和torch都是定义forward函数,Tensorflow定义call函数]。
class Network(object):
def __init__(self, num_of_weights):
# num_of_weights:输出特征的维度
# 随机产生w的初始值
# 为了保持程序每次运行结果一致性,此处设置固定的随机数种子
# 如果在框架下,需要固定更多的随机数种子,保证模型结果的可复现性
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
# 基于NetWork网络的定义,也就代表模型计算过程如下,这里就实现了一个模型的初始化过程
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
3.训练配置
模型设计完成后,接下来就是模型配置的环节,需要在这个环节,使用合适的算法衡量出刚刚定义好的初始化模型的好坏,然后在之后的过程中再结合算法的评估结果对模型进行调整。 放到完整的任务中,也就是在这个环节定义好loss函数(损失函数,目标函数)。前面通过模型计算中,x1表示的影响因素对应的房价应该是z,但实际数据告诉你是y。这里我们就需要定义衡量方法来衡量这个过程的好坏。这个类型的回归任务中,最常用的是使用均方误差的结果作为评估指标。而在分类任务中,一般使用的就是交叉熵作为损失函数。
均方误差公式:
L
=
1
/
N
∗
∑
i
(
y
i
−
z
i
)
2
L=1/N*\sum_i(y_i-z_i)^2
L=1/N∗∑i(yi−zi)2
计算一条样本的真实值和预测值之间差的平方和的平均数
接下来我们可以把计算这个过程封装成网络Net()的成员函数loss(),也可以放外部
def loss(self, z, y): # 放入类内部时记得调整这个函数的缩进
error = z-y
cost = error*error
cosy = np.mean(cost)
return cost
# 此处可以尝试一次性计算多个样本的预测值和损失函数计算得到的loss值,也就是之后将会经常提到的计算一个batch的数据的预测值和loss值
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print("predict", z)
loss = net.loss(z, y1)
print("loss", loss)
总结
这里我们实现了对房价预测问题数据集的读取和预处理,并定义了网络,定义了对应的损失函数,接下来要做的事情就是通过这里损失函数计算得到的loss值,对网络内的权重和偏置项进行更新了,也就是对应之后要学习的优化器优化模型参数的过程。整体过程比较麻烦,甚至可以成为一门单独的研究方向设计对应的优化器,所以这里单独留一篇文章讲解。














 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









