







文章目录
关于多层神经网络搭建部分的数学推导,我放在了实验总结部分,其中涉及到很多矩阵的运算,可以查看我的这篇文章简单了解一下: 矩阵求导之布局分析。
关于为什么没有实验二的文章,大概是因为实验二不太像个正经实验…😅
一、实验要求
在计算机上验证和测试多层神经网络的原理和算法实现,测试多层神经网络的训练效果,同时查阅相关资料。
二、实验目的
- 掌握多层神经网络的基本原理;
- 掌握多层神经网络的算法过程;
- 掌握反向传播的算法过程;
三、实验内容
1. 多层神经网络Python实现:
阅读和测试多层神经网络类代码,观察多层神经网络训练过程和结果,并对隐藏层Dense类和多层神经网络MLPClassifier类的代码进行详细注释。
1.1 导入所需的函数库
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron #感知机
from sklearn.neural_network import MLPClassifier #多层神经网络
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
1.2 定义分界线绘制函数
'''分界线绘制函数'''
def plot_decision_boundary(model, X, y):
x0_min, x0_max = X[:,0].min()-1, X[:,0].max()+1
x1_min, x1_max = X[:,1].min()-1, X[:,1].max()+1
x0, x1 = np.meshgrid(np.linspace(x0_min, x0_max, 100), np.linspace(x1_min, x1_max, 100))
Z = model.predict(np.c_[x0.ravel(), x1.ravel()])
Z = Z.reshape(x0.shape)
plt.contourf(x0, x1, Z, cmap=plt.cm.Spectral)
plt.ylabel('x1')
plt.xlabel('x0')
plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(y))
1.3 定义基类:Layer
'''定义一个基类:层Layer'''
class Layer:
def __init__(self):
pass
#前向计算
def forward(self, input):
return input
#反向传播
def backward(self, input, grad_output):
pass
1.4 定义激活函数层:Sigmoid
'''定义Sigmoid层'''
class Sigmoid(Layer):
def __init__(self):
pass
def _sigmoid(self,x):
return 1.0/(1+np.exp(-x))
def forward(self,input):
return self._sigmoid(input)
# 这里的input是:激活函数sigmoid的输入,即:z(z=X*W+b)
# 这里的grad_output是:损失函数J(a,y)对sigmoid函数的输出a(a=sigmoid(z))做偏导
def backward(self,input,grad_output):
# 计算sigmoid函数(标量变元标量函数)对它的输入z(z=X*W+b)的偏导
sigmoid_grad = self._sigmoid(input)*(1-self._sigmoid(input))
# 返回:损失函数J对其输入a的偏导*sigmoid函数对其输入z的偏导 = 损失函数J对z的偏导
return grad_output*sigmoid_grad.T
1.5 定义隐藏层:Dense
'''定义隐藏层'''
class Dense(Layer):
def __init__(self, input_units, output_units, learning_rate=0.1):
# 定义学习率
self.learning_rate = learning_rate
# 定义权重w(矩阵),行数是输入个数,列数是输出个数
# 每一个列向量就是一组输入对应当前输出的权重,几个输出就有几列
self.weights = np.random.randn(input_units, output_units)#初始化影响很大
# 定义偏差b(向量),长度等于输出个数
# 每一个分量就是一组输入对应当前输出的偏差,几个输出就有几个分量
self.biases = np.zeros(output_units)
'''前向积累,计算输出值'''
def forward(self,input):
# z=X*W+b,x为上一层的输出a_(i-1),或最开始的输入
z = np.dot(input,self.weights)+self.biases
return z
'''反向传播,计算梯度'''
def backward(self,input,grad_output):
# 计算J对当前层输入x的梯度,grad_output是损失函数J对隐藏层输出z的偏导,而z对输入x的偏导就是权重w
grad_input = np.dot(self.weights,grad_output)
#print('dJ/dx:',grad_input.shape,'\n','dJ/dz:',grad_output.shape,'\n','weights=dz/dx:',self.weights.shape,'\n')
# 计算J对当前层权重w的梯度,grad_output是损失函数J对隐藏层输出z的偏导,而z对权重w的偏导就是当前层输入input
# 因为使用整体的损失对w求偏导,所以除以样本数量(input.shape[0])求均值
grad_weights = np.dot(grad_output,input)/input.shape[0]
#print('dJ/dw:',grad_weights.shape,'\n','input=dz/dw:',input.shape,'\n','dJ/dz:',grad_output.shape,'\n')
# 同理,使用整体的损失对b求偏导,所以求均值
grad_biases = grad_output.mean()
# 利用梯度下降法优化当前层的w和b
self.weights = self.weights - self.learning_rate*grad_weights.T
self.biases = self.biases - self.learning_rate*grad_biases.T
# 返回J对当前层输入的梯度,用于前一层计算
return grad_input
1.6 定义多层神经网络:MLPClassifier
'''定义多层神经网络层'''
class MLPClassifier(Layer):
def __init__(self):
self.network = []
# 添加一个2输入,5输出的隐藏层
self.network.append(Dense(2,5))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
# 添加一个5输入,1输出的隐藏层
self.network.append(Dense(5,1))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
def forward(self,X):
# 列表存储中间计算结果
self.activations = []
input = X
# 正向循环遍历神经网络
for layer in self.network:
# 正向累积并存储中间值
self.activations.append(layer.forward(input))
# 将列表中存储的最后一个元素(前一次输出)作为下一次运算的输入
input = self.activations[-1]
# assert断言函数,不满足其后的条件则抛出错误,等价于 if not xxx:raise xxx
assert len(self.activations) == len(self.network)
return self.activations
'''本例中用于分界线绘制函数内调用predict方法'''
def predict(self,X):
# 正向累积,并获取最终输出
y_pred = self.forward(X)[-1]
# 根据输出结果实行二分类打标签
y_pred[y_pred>0.5] = 1
y_pred[y_pred<=0.5] = 0
# 返回标签值
return y_pred
'''本例中没用上'''
def predict_proba(self,X):
logits = self.forward(X)[-1]
# 返回最终输出结果,而不是分类后的标签
return logits
'''具体训练方法,由train方法调用'''
def _train(self,X,y):
#先正向计算,再反向传播,梯度下降更新权重参数w,b
self.forward(X)
# 输入列表:layer_inputs,保存了每一层的输入,注意列表间的“+”是连接操作
layer_inputs = [X]+self.activations
# 最后一层的输出
logits = self.activations[-1]
# 这里的损失函数需要自己定义,这里用到最小二乘
loss = np.square(logits - y.reshape(-1,1)).sum()
# 损失函数对l最终输出(logits)的梯度值
loss_grad = 2.0*(logits-y.reshape(-1,1)).T
# 反向循环遍历神经网络(反向传播)
for layer_i in range(len(self.network))[::-1]:
layer = self.network[layer_i]
# 计算损失函数对当前层输出(layer_inputs[layer_i])的梯度
# 用该梯度可以得到损失函数对w和b的梯度,用于优化参数(在backward中进行了)
loss_grad = layer.backward(layer_inputs[layer_i],loss_grad)
return np.mean(loss)
def train(self, X, y):
for e in range(1000):
# 神经网络迭代1000次,计算并查看每一次的损失是否变化
loss = self._train(X,y)
print(loss)
return self
1.7 生成训练集和测试集
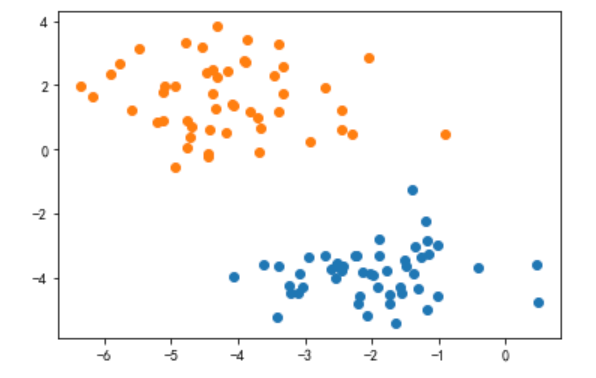
# 生成散点簇数据集
x_train,y_train = datasets.make_blobs(n_samples=100, n_features=2, centers=2, cluster_std=1)
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1])
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1])
plt.show()
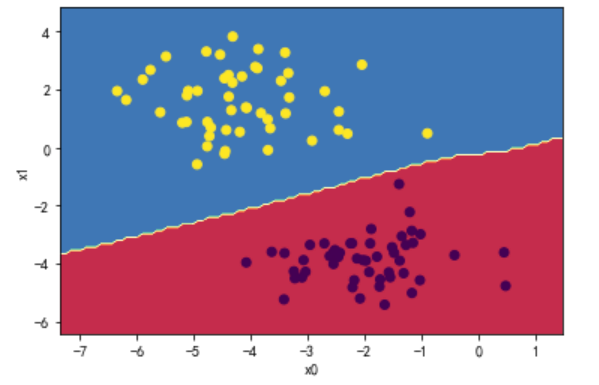
1.8 训练并绘制分界线
MLP = MLPClassifier().train(x_train,y_train)
| 32.17454887891505 31.794027620971942 31.404196873755865 31.004962567950013 … 19.145328784895174 18.54282599092301 17.943890203632968 … 2.009292596684285 2.0019482522644507 1.9946533499084804 1.98740737422343 … 0.49032376234193314 0.48981025722326077 0.4892978159963806 0.488786435393049 |
|---|
plot_decision_boundary(MLP,x_train,y_train)
2. 神经网络对层数和神经元数改进:
对多层神经网络改进,实现对moons数据的分类。
- 增加隐藏层神经元个数
- 增加隐藏层的层数
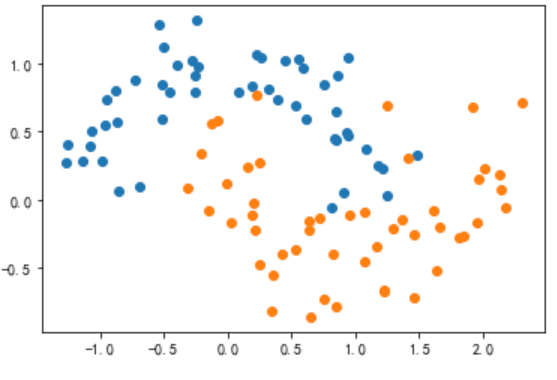
2.1 生成训练集和测试集
x_train,y_train = datasets.make_moons(n_samples=100,noise=0.2,random_state=666)
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1])
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1])
plt.show()
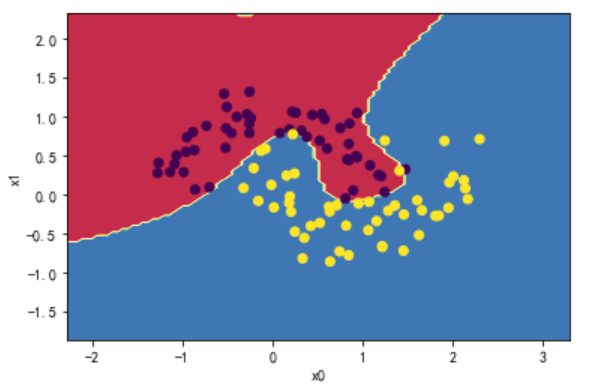
2.2 增加神经网络层数和神经元
class MLPClassifier2(MLPClassifier):
def __init__(self):
self.network = []
# 添加一个2输入,6输出的隐藏层
self.network.append(Dense(2,6,0.5))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
# 添加一个6输入,6输出的隐藏层
self.network.append(Dense(6,8,0.5))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
# 添加一个6输入,4输出的隐藏层
self.network.append(Dense(8,4,0.5))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
# 添加一个6输入,6输出的隐藏层
self.network.append(Dense(4,1,0.5))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
2.3 训练并绘制分界线
MLP = MLPClassifier().train(x_train,y_train)
| 38.21754373561508 … 28.10775704700434 … 15.712500154068152 … 7.704956511113001 … 1.5864199654500957 |
|---|
plot_decision_boundary(MLP,x_train,y_train)
3. 激活函数的替换和比较:
实现ReLU激活函数类,与Sigmoid激活函数类作比较,针对同样二分类问题训练的区别。
3.1 定义激活函数层:ReLU
'''定义Relu层'''
class ReLU(Layer):
def __init__(self):
pass
def forward(self,input):
return np.maximum(0,input)
def backward(self,input,grad_output):
# 计算relu函数对其输入z(z=X*W+b)的偏导
# 如果输入大于0,导数为1;否则为0。
relu_grad = input>0
# 返回:损失函数J对其输入a的偏导*relu函数对其输入z的偏导 = 损失函数J对z的偏导
return grad_output*relu_grad
3.2 比较损失下降速度
class MLPClassifier(Layer):
def __init__(self):
self.network = []
# 添加一个2输入,5输出的隐藏层
self.network.append(Dense(2,5))
# 为该隐藏层添加激活函数
self.network.append(ReLU())
# 添加一个5输入,1输出的隐藏层
self.network.append(Dense(5,1))
# 为该隐藏层添加激活函数
self.network.append(Sigmoid())
- 左为隐藏层1使用sigmoid激活函数;右为隐藏层1使用relu激活函数;
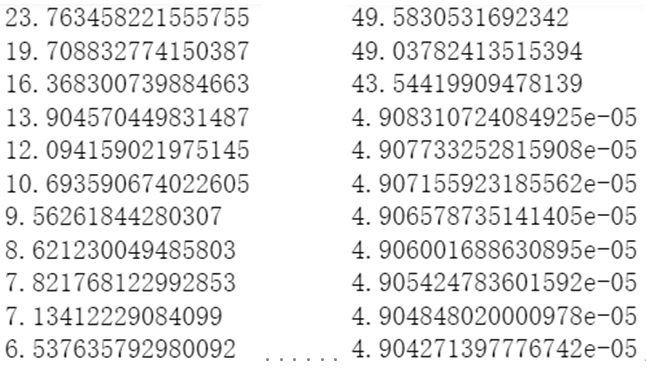
可以看到使用relu激活函数显著加快了学习速率,损失在第四次迭代时呈断崖式下降。
四、实验总结
-
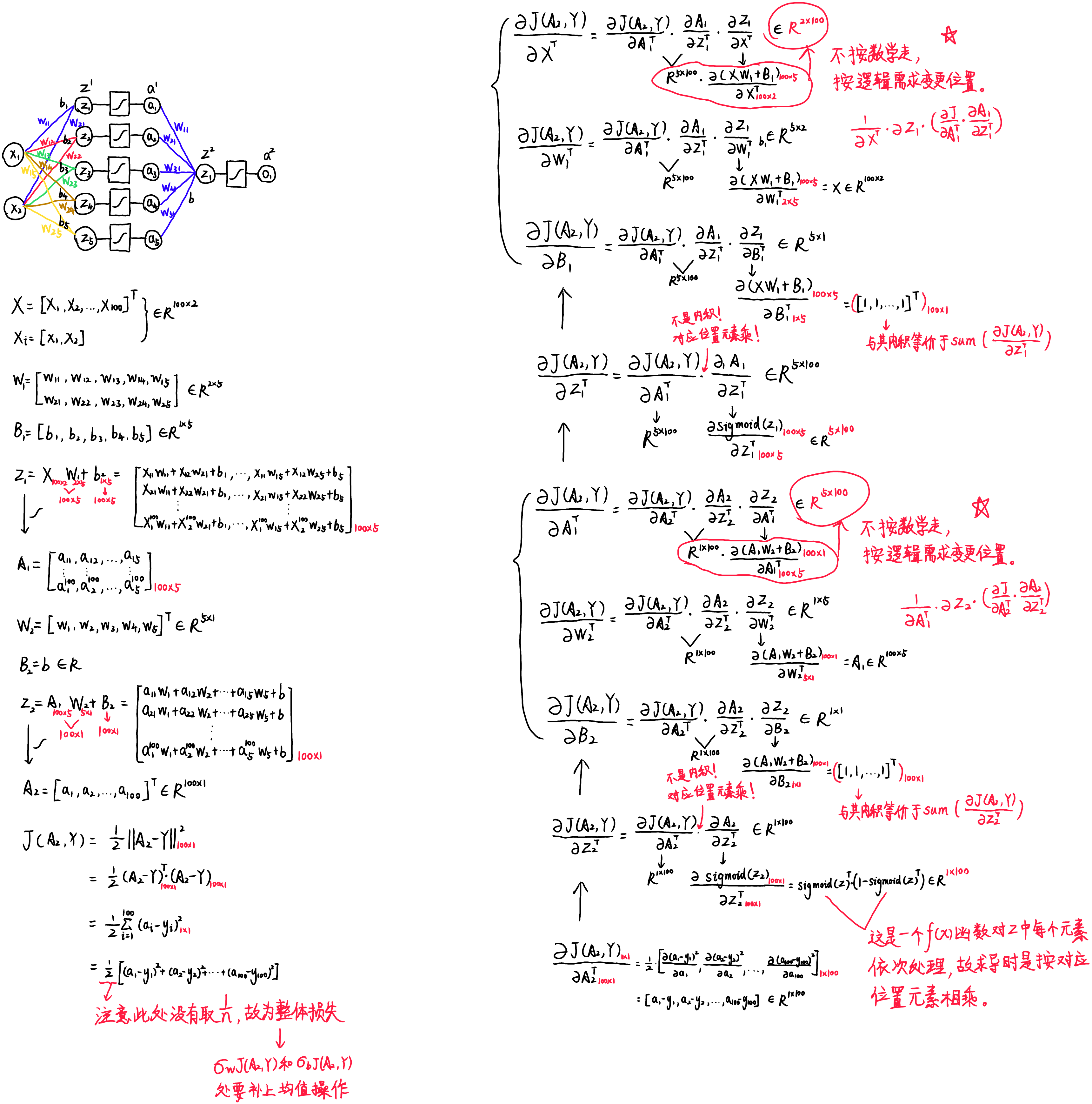
关于题一的数学推导如下:
-
关于上面的推导中采用了分子布局的方式进行整体的计算,结果该式出现与数学上矩阵求导计算顺序不符的问题: δ J ( A 2 , Y ) δ X T \frac{\delta{J(A_{2},Y)}}{\delta{X^{T}}} δXTδJ(A2,Y)
-
不仅如此,若是采用分母布局对整体进行推导,虽然矩阵 X X X 求得的偏导没问题,但又导致了 J ( A 2 , Y ) J(A_{2},Y) J(A2,Y) 对 W W W 和 B B B 的偏导不满足数学上矩阵求导的计算顺序: δ J ( A 2 , Y ) T δ W , δ J ( A 2 , Y ) T δ B \frac{\delta{J(A_{2},Y)^{T}}}{\delta{W}},\frac{\delta{J(A_{2},Y)^{T}}}{\delta{B}} δWδJ(A2,Y)T,δBδJ(A2,Y)T
-
初步分析应该是输入矩阵 X X X 的设计没有满足 Z = X T W + B Z=X^{T}W+B Z=XTW+B ,再加之矩阵运算的复杂性,求导过程中需要进行一定变更,否则就会出现上述矛盾。这一问题的答案将在日后推导,这个实验目前耗时太多了…















 6544
6544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









