






目录
一、数据库
① K-V:Redis,Memcache
② 文档:MongoDB
③ 搜索:Elasticsearch,Solr
④ 可扩展性分布式:HBase
二、NoSQL
NoSql可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。
是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
三、认识Redis
Redis是一种键值型的NoSql数据库,这里有两个关键字:
- 键值型
- NoSql
其中键值型,是指Redis中存储的数据都是以key、value对的形式存储,而value的形式多种多样,可以是字符
串、数值、甚至json:

而NoSql则是相对于传统关系型数据库而言,有很大差异的一种数据库。
三、关系数据库与非关系数据库对比
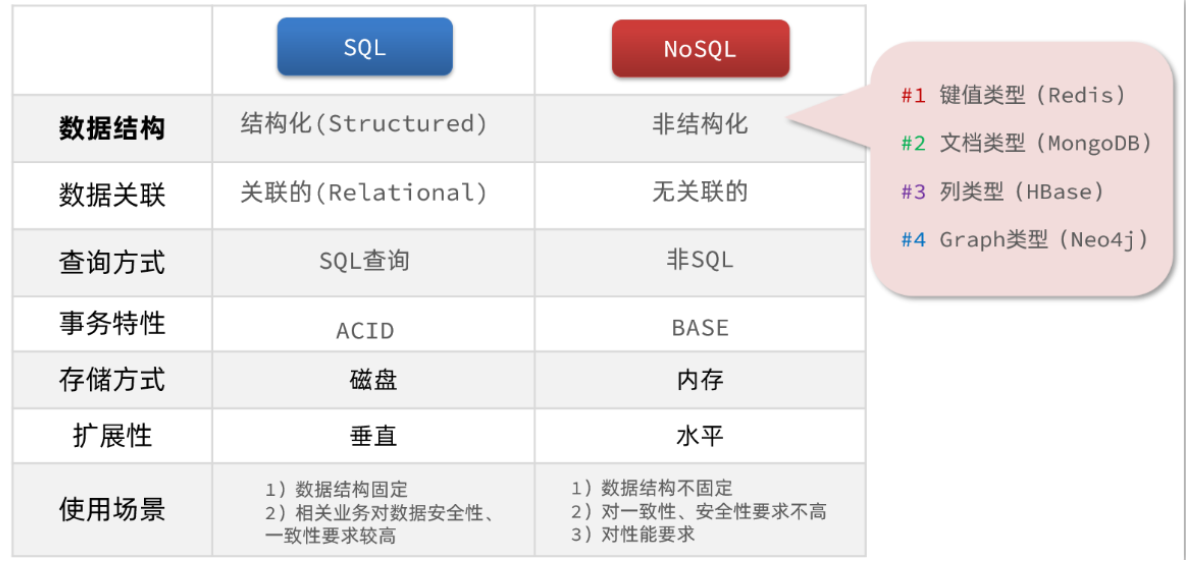
1. 结构化与非结构化
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束等等信息,

而非关系型数据库则对数据库格式没有严格约束,往往形式松散,自由。
它可以是键值型,也可以是文档型,还可以是图格式,等等。
可以是键值型

也可以是文档型

甚至可以是图格式

2. 关联和非关联
传统数据库的表与表之间往往存在关联,例如,外键关联,
而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合。
案例:
传统数据库的表与表之间往往存在关联,例如外键:
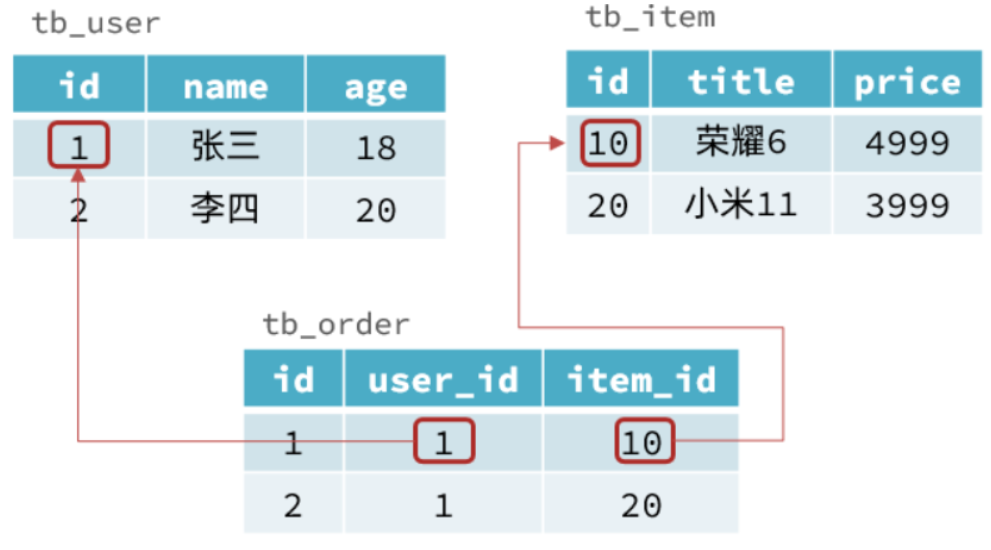
而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
{
id: 1,
name: "张三",
orders: [
{
id: 1,
item: {
id: 10, title: "荣耀6", price: 4999
}
},
{
id: 2,
item: {
id: 20, title: "小米11", price: 3999
}
}
]
}此处要维护“张三”的订单与商品“荣耀”和“小米11”的关系,不得不冗余的将这两个商品保存在张三的订单
文档中,不够优雅。
还是建议用业务来维护关联关系。
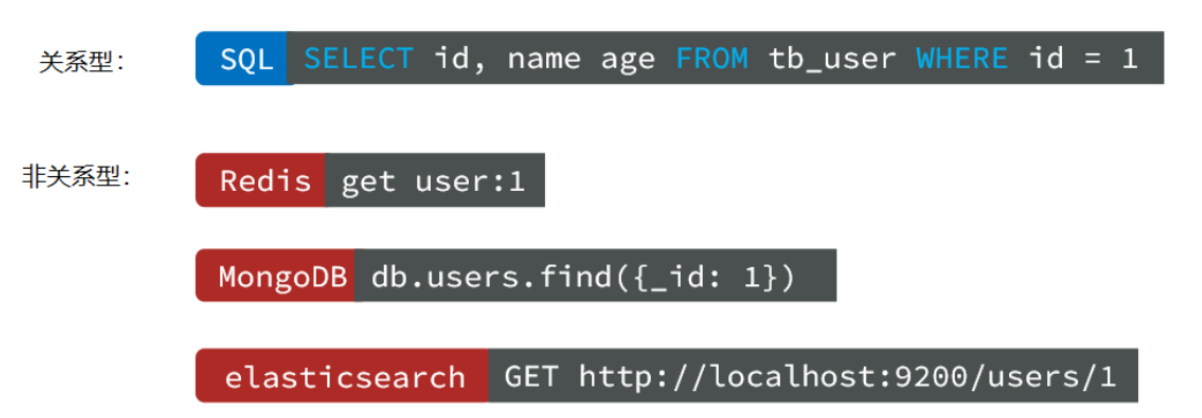
3. 查询方式
传统关系型数据库会基于Sql语句做查询,语法有统一标准;
而不同的非关系数据库查询语法差异极大,五花八门各种各样。
4. 事务
传统关系型数据库能满足事务ACID的原则。
而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
5. 存储方式
关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
6. 扩展性
关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。
称为水平扩展。
关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
7. 总结
7.1. 图形梳理
- 存储方式
-
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
- 扩展性
-
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
7.2. 表格梳理
| 内容 | 关系型数据库 | 非关系型数据库 |
| 成本 | 有些需要收费(Orcale) | 基本都是开源 |
| 查询数据 | 存储存于硬盘中,速度慢 | 数据存于缓存中,速度快 |
| 存储格式 | 只支持基础类型 | K-V,文档,图片等 |
| 扩展性 | 有多表查询机制,扩展困难 | 数据之间没有耦合,容易扩展 |
| 持久性 | 适用持久存储,海量存储 | 不适用持久存储,海量存储 |
| 数据一致性 | 事务能力强,强调数据的强一致性 | 事务能力弱,强调数据的最终一致性 |
7.3. 优缺点
关系型数据库
采用关系模型来组织数据的数据库,关系模型就是二维表格模型。
一张二维表的表名就是关系,二维表中的一行就 是一条记录,二维表中的一列就是一个字段。
优点:
① 容易理解
② 使用方便,通用的sql语言
③ 易于维护,丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大降低了数据冗余和数据不一致的概 率
缺点:
① 磁盘I/O是并发的瓶颈
② 海量数据查询效率低
③ 横向扩展困难,无法简单的通过添加硬件和服务节点来扩展性能和负载能力,
当需要对数据库进行升级和扩展 时,需要停机维护和数据迁移
④ 多表的关联查询以及复杂的数据分析类型的复杂sql查询,性能欠佳。
因为要保证acid,必须按照三范式设计。
数据库:
Orcale,Sql Server,MySql,DB2
非关系型数据库
非关系型,分布式,一般不保证遵循ACID原则的数据存储系统。键值对存储,结构不固定。
优点:
① 根据需要添加字段,不需要多表联查。仅需id取出对应的value
② 适用于SNS(社会化网络服务软件。比如facebook,微博)
③ 严格上讲不是一种数据库,而是一种数据结构化存储方法的集合
缺点:
① 只适合存储一些较为简单的数据
② 不合适复杂查询的数据
③ 不合适持久存储海量数据
四、再次认识Redis
1. 简介
Redis诞生于2009年全称是Remote Dictionary Server 远程词典服务器,它是用C语言开发的一个开源的高性能
键值对(key-value)基于内存的键值型NoSQL数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次
数),是互联网技术领域使用最为广泛的存储中间件。它存储的value类型比较丰富,因此,也被称为结构化的
NoSql数据库。它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如字符串(strings) ,散列(hashes),列表(lists),集合(sets) , 有序集
合(sorted sets)与范围查询,bitmaps, hyperloglogs和地理空间(geospatial)索引半径查询。
Redis内置了复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务
(transactions)和不同级 别的 磁盘持久化(persistence),并通过Redis哨兵(Sentinel) 和自动分区
(Cluster)提供高可用性(high availability)
关系型数据库(RDBMS)
- Mysql
- Oracle
- DB2
- SQLServer
非关系型数据库(NoSql)
- Redis
- Mongo db
- MemCached
2. 特征
- 基于内存存储,读写性能高


- 适合存储热点数据(热点商品、资讯、新闻)

- 企业应用广泛
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
3. 历史简介
2008年,意大利一家创业公司Merzia的创始人Salvatore Sanfilippo为了避免MySQL的低性能,亲自定做一个数
据 库,并于2009年开发完成,这个就是Redis。从2010年3月15日起,Redis的开发工作由VMware主持。从
2013年5月开始,Redis的开发由Pivotal赞助。
说明:
Pivotal公司是由EMC和VMware联合成立的一家新公司。
Pivotal希望为新一代的应用提供一个原生的基础,建 立在具有领导力的云和网络公司不断转型的IT特性之上。
Pivotal的使命是推行这些创新,提供给企业IT架构师和独立 软件提供商。
作者:Antirez
Redis的官方网站地址:Redis - The Real-time Data Platform

4. 支持语言

5. 总结
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支
持多种类型的数据结构,如字符串(strings) ,散列(hashes),列表(lists),集合(sets) , 有序集合
(sorted sets)与范围查询,bitmaps, hyperloglogs和地理空间(geospatial)索引半径查询。 Redis内置了
复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务(transactions)和不
同级 别的 磁盘持久化(persistence),并通过Redis哨兵(Sentinel) 和自动分区(Cluster)提供高可用性
(high availability)
五、你知道使用Redis能做什么?
- 数据缓存
- 消息队列
- 注册中心
- 发布订阅
- 短信验证码
- . . .
















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











