







 本文介绍了Python爬虫的基础,包括使用正则表达式抓取网页数据和Bs4库的安装。文章详细讲解了HTML的基本语法规则,如元素、标签和属性,并提供了实例展示如何使用Bs4解析HTML,提取所需信息。通过学习,读者能够掌握爬虫数据抓取及初步的HTML解析技巧。
本文介绍了Python爬虫的基础,包括使用正则表达式抓取网页数据和Bs4库的安装。文章详细讲解了HTML的基本语法规则,如元素、标签和属性,并提供了实例展示如何使用Bs4解析HTML,提取所需信息。通过学习,读者能够掌握爬虫数据抓取及初步的HTML解析技巧。
Python爬虫学习
前言
本来是写了一个博客的,

但是没有通过,方法和上一节类似,我直接贴上代码吧
import requests
wangzhi_list=[]
domain = 'https://dy.dytt8.net/'
url='https://dy.dytt8.net/index2.htm'
resp=requests.get(url)
resp.encoding='gb2312'#指定字符集
res=resp.text
obj=re.compile(r'2022新片精品.*?<ul>(?P<xinxi>.*?)</ul>',re.S)
obj2=re.compile(r'◎译 名 (?P<mv>.*?)/.*?<a href="(?P<dizhi>.*?)"',re.S)
rrr=obj.finditer(res)
for i in rrr:
xinxi=i.group('xinxi')
#print(i.group('xinxi'))
obj1=re.compile(r"</td.*?href='(?P<lianjie>.*?)'>",re.S)
rrr1=obj1.finditer(xinxi)
for i1 in rrr1:
#print(i1.group('lianjie'))
wangzhi= domain+ i1.group('lianjie').strip("/") #拼接地址 去掉不需要的部分,根据网址自己修改
#print(wangzhi)
wangzhi_list.append(wangzhi) #将信息存储到列表里
for lj in wangzhi_list:
resp1=requests.get(lj)
resp1.encoding = 'gb2312' # 指定字符集
res1=resp1.text
# print(resp1.text)
rrr2=obj2.finditer(res1)
for i3 in rrr2:
print(i3.group('mv'))
print(i3.group('dizhi'))
不管了,接着学习另一种解析Bs4解析
一、Html语法规则
通过元素与标签来获取相关信息,我们再看页面源代码的时候,会发现页面源代码里面全部都是文本,并没有图片,那图片是怎么显示的呢。
HTML是超文本标记语言,是用来描述网页的一种语言,用各种标签以及文本来描述 web 页面,浏览器可以读取 html 文件并且显示。
一、根元素
<doctype> 定义文档类型。
<html> 定义 HTML 文档。
二、元数据元素
<head> 定义关于文档的信息。
<meta> 定义关于 HTML 文档的元数据。
<link> 定义文档与外部资源之间的关系,一般用于引入样式表。
<base> 定义页面上所有链接的默认地址或默认目标。
<title> 定义文档标题。
<style> 定义文档的样式信息。
三、脚本元素
<script> 定义客户端脚本。
<noscript> 定义当浏览器不支持脚本的时候所显示的内容
四、块元素
<body> 定义文档的主体。
<h1>、<h2>...<h6> 定义文档标题。
<p> 定义文档段落。
<blockquote> 定义块引用。
<ul>、<ul>、<dl> 定义列表。
<table> 定义表格。
1、列表元素
无序列表
<ul> 定义无序的列表。
<li> 定义列表项。
有序列表
<ol> 定义有序的列表。
<li> 定义列表项。
定义列表
<dl> 定义定义列表。
<dt> 定义定义术语。
<dd> 定义定义描述。
2、表格元素
<table> 定义表格。
<thead> 定义表格的页眉。
<tbody> 定义表格的主体。
<tfoot> 定义表格的页脚。
<th> 定义表格的表头行。
<tr> 定义表格的行。
<td> 定义表格单元。
五、表单元素
<form> 定义供用户输入的表单。
<input> 定义输入域。
<textarea> 定义文本域 (一个多行的输入控件)。
<lable> 定义一个控制的标签。
<select> 定义一个选择列表。
<option> 定义下拉列表中的选项。
<optgroup> 定义选项组。
<button> 定义一个按钮。
<fieldset> 定义域。
<legend>
定义域的标题。
六、文本元素
1、文本格式化元素
<em> 定义着重文字。
<strong> 定义加重语气。
<sup> 定义上标字。
<sub> 定义下标字。
<ins> 定义插入字。
<del> 定义删除字。
<b> 定义粗体文本。
<i> 定义斜体文本。
<big> 定义大号字。
<small> 定义小号字。
2、“计算机输出”标签
<code> 定义计算机代码。
<kbd> 定义键盘码。
<pre> 定义预格式文本。
3、引用、引用和术语定义
<q> 定义简短引用。
<blockquote> 定义长引用。
<address> 定义地址。
七、链接与图像
<a> 定义超链接
<img> 定义图像。
<map> 定义图像地图。
<area> 定义图像地图中的可点击区域。
八、<div> 和 <span>
<div> 定义文档中的分区或节(division/section)。
<span> 定义 span,用来组合文档中的行内元素。
九、框架
<frameset> 定义如何将窗口分割为框架。(注:<frameset>元素只能嵌套在<html> 元素或<frameset>元素自身中!)
<frame> 定义放置在每个框架中的 HTML 文档。
十、内联框架
<iframe> 定义内联的子窗口(框架)。
一、HTML全局属性
1、核心属性
属性 描述
id 设置元素的唯一 id。
class 设置元素的一个或多个类名(引用样式表中的类)。
style 设置元素的行内样式(CSS内联样式)。
title 设置有关元素的额外信息(可在工具提示中显示)。
2、语言属性
属性 描述
lang 设置元素内容的语言代码。
3、键盘属性
属性 描述
accesskey 设置访问元素的键盘快捷键。
tabindex 设置元素的 tab 键次序。
二、常见元素属性:
1、<a>元素的属性:
属性 描述
href 指定链接到互联网或你的计算机上的一个资源的别称。
target 指定打开链接的目标窗口。
title 指定所要链接到页面的文本描述。
2、<img>元素的属性:
属性 描述
src 指定向服务器请求的资源。
alt 指定图像无法显示时的替代文本。
语法规则:
<标签 属性=“属性值”>被标记的内容</标签>
<img src="xxx.jpg"/>
可以通过属性定位到页面元素,用于提取数据,这种就是bs4解析
二、安装Bs4
pip install bs4
使用pip list 查看
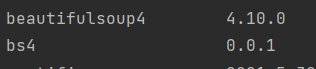
安装完成



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











