






首先参考这篇文章:https://zhuanlan.zhihu.com/p/685943779
为什么FFN需要这么大
常见的说法是Knowledge Neurons。tokens在前一层attention做全连接之后,通过FFN的参数中存放着大量训练过程中学习到的比较抽象的知识来进一步更新。相关的文章比如Transformer Feed-Forward Layers Are Key-Value Memories,Knowledge Neurons in Pretrained Transformers
如果FFN存储着Transformer的知识,那么注定了这个地方不好做压缩加速:
-
FFN变小意味模型容量也变小,大概率会让整体表现变得很差。两个FC中间会有个隐藏层维度的扩展比例,一般设置为4,也就是先把隐藏层维度变成原来的4倍,经过激活函数后再降回来。把这个地方调小会发现怎么都不如大点好。当然太大也不行,因为FFN这里的扩展比例决定了整个Transformer 在推理时的峰值内存占用,有可能造成out-of-memory ,所以大部分我们看到的扩展比例也就在4倍,一个比较合适的性能和内存的平衡。
-
FFN中的activations非低秩。过去CNN上大家又发现激活有明显的低秩特性,所以可以通过low rank做加速。但是FFN中间的outputs很难看出低秩的特性,实际做网络压缩的时候会发现剪枝FFN的trade-off明显不如CNN,而非结构化剪枝又对硬件不友好。
对上面提到的论文Transformer Feed-Forward Layers Are Key-Value Memories进行阅读,看看FFN为什么重要:
Transformer Feed-Forward Layers Are Key-Value Memories
参考这篇:https://zhuanlan.zhihu.com/p/611278136
论文说transformer中的FFN层是Neural memory ---- 什么是Neural memory?
Neural memory是指在神经网络中实现或模拟记忆功能的机制。这种记忆机制使得模型能够存储、检索和利用过去的信息,以改进其在特定任务上的表现。核心思想是让模型具备一种长期和短期的记忆能力,能够在推理过程中访问和更新这些信息,从而更有效地处理具有上下文依赖性或长期依赖性的任务。
FFN层和神经记忆的数学形式几乎相同,只不过前者使用ReLU或Gelu等作为激活函数,神经记忆使用softmax作为激活函数。所以说,FFN层相当于是负责记忆的模块
-
FFN层占据了整个Transformer大约2/3的参数量,它可以视为一个key-value memory,也就是把第一个线性层当做key,第二个线性层当value。其中每一层的 key 用于捕获输入序列的模式(浅层模式+语义模式);value 可以基于key捕获的模式,给出下一个token的词表分布。
-
每层的FF是由多个key-value组合而成,然后结合残差连接对每层的结果进行细化,最终产生模型的预测结果。在第一个线性层中,每个key是一个1*4d的向量(也就是矩阵的一行);在第二个线性层中,每个value是一个1*4d的向量。每一个key向量都能捕获输入序列的模式。
作者认为FF层中的 K 可以作为一种模式检测器,可以检测当前输入序列属于哪种模式,如它可以发现当前句子是以"substitues"结尾(这是比较浅层的字符模式)、当前句子描述的是电视节目(这是语义信息,比较高层)。下图体现了论文中的实验结果:浅层倾向于检测出浅层模式,高层倾向于检测语义模式
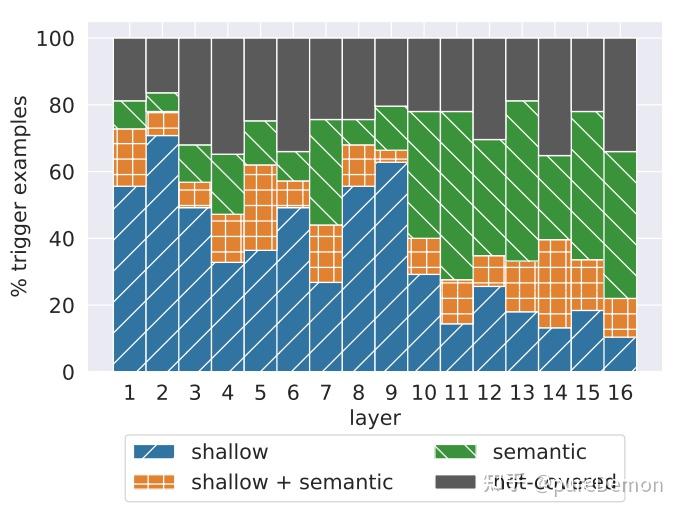
可以看出,layer小的时候,蓝色占比大,也就是shallow语义比例高;layer大之后,绿色占比高,也就是比较深层的语义信息。
深层和浅层应该指的是不同深度的Transformer层。
提升FFN效率的优化
目前最有前景的是改成 Mixture-of-Expert (MoE),GPT4和Mixtral 8x7B没出来之前基本只有Google在做,没人关注。当然现在时代变了,Mixtral 8x7B让MoE起死回生。一些改成MoE的文章:
-
LoRA MoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin
-
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
综述中的优化方法
综述名:A Survey on Efficient Inference for Large Language Models
专注于修改FFN结构的方法
-
MoEfication可以使用模型的预训练权重,将非MoE的LLM转换为MoE版本。这种方法消除了对MoE模型昂贵预训练的需求。为了实现这一点,MoEfication首先将预训练的LLM中的FFN神经元划分为多个组。在每个组内,神经元通常由激活函数同时激活。然后,它将每个神经元组重构为一个专家。
-
Sparse Upcycling 引入了一种方法,直接从密集模型的检查点初始化基于MoE的LLM的权重。在这种方法中,基于MoE的LLM内的专家是密集模型中FFN的精确副本。通过采用这种直接的初始化方法,Sparse Upcycling可以高效地训练MoE模型以实现高性能。
-
MPOE提出通过矩阵乘积算子(MPO)分解来减少基于MoE的LLM的参数。这种方法涉及将FFN的每个权重矩阵分解为包含共同信息的全局共享张量和一组捕获特定特征的局部辅助张量。
专注于改进MoE路由模块的方法
另一种是专注于改进MoE内部路由模块的方法。在之前的MoE模型中,路由模块常常导致负载不平衡问题,这意味着一些专家被分配了大量的token,而其他专家处理的token却很少。这种不平衡不仅浪费了那些未充分利用的专家的能力,从而降低了模型性能,还降低了推理效率。路由模块设计的主要目标是在MoE专家的token分配中实现更好的平衡。下面是具体方法:
-
Switch Transformers 在最终损失函数中引入了一个额外的损失,即负载平衡损失,以惩罚路由模块的不平衡分配。这个损失被定义为token分配分数向量与均匀分布向量之间的缩放点积。因此,只有当所有专家的token分配平衡时,损失才会最小化。这种方法鼓励路由模块在专家之间均匀分配令牌,促进负载平衡,最终提高模型性能和效率。
-
BASE以端到端的方式为每个专家学习一个嵌入,并根据他们嵌入的相似性将专家分配给令牌。为了确保负载平衡,BASE提出了一个线性分配问题,并利用拍卖算法高效地解决这个问题。
-
Expert Choice引入了一种简单而有效的方法来确保MoE基础模型中的完美负载平衡。与之前将专家分配给令牌的方法不同,Expert Choice允许每个专家独立地根据他们的嵌入相似性选择前k个令牌。这种方法确保每个专家处理固定数量的令牌,即使每个令牌可能被分配给不同数量的专家。
关注改进MoE的训练方法
-
SE-MoE引入了一种新的辅助损失函数,称为路由器z损失,旨在在不损害性能的情况下提高模型训练的稳定性。SE-MoE发现,路由模块中softmax操作引入的指数函数可能会加剧舍入误差,导致训练不稳定。为了解决这个问题,路由器z损失对输入指数函数的大logits进行惩罚,从而在训练过程中最小化舍入误差。
-
StableMoE指出了基于MoE的大型语言模型(LLMs)中存在的路由波动问题,这表示在训练和推理阶段专家分配的一致性问题。对于相同的输入令牌,在训练过程中会被分配给不同的专家,但在推理时只激活一个专家。为了解决这个问题,StableMoE建议了一个更一致的训练方法。它首先学习一个路由策略,然后在模型主干训练和推理阶段保持固定。
-
SMoE-Dropout为基于MoE的LLMs设计了一种新的训练方法,提出在训练过程中逐渐增加激活的专家数量。这种方法增强了基于MoE模型的可扩展性,适用于推理和下游微调。
-
GLaM预训练并发布了一系列不同参数大小的模型,展示了它们在少样本任务上与密集型LLMs相当的性能。这个家族中最大的模型参数大小达到1.2万亿。
-
Mixtral 8x7B是一个值得注意的最近发布的开源模型。在推理时,它只使用130亿个活跃参数,并在不同的基准测试中与LLaMA-2-70B模型相比取得了优异的性能。Mixtral 8x7B在每一层中包含8个前馈网络(FFN)专家,每个令牌在推理时被分配给两个专家。

















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









