









目录
总纲
写在前面的话
首先这篇博客绝对原创。读者遇到编程中的任何问题可以留言,看到了就会回复
需要的前瞻知识
这篇博客是假设读者都是已经安装好了Hadoop,Spark,以及对idea插件等,如果在安装这些大数据软件遇到了困难可以根据版本号在CSDN里搜对应的大数据软件安装
用到的软件版本
Hadoop2.7.7;Java1.8.0;sbt1.4.0;Spark2.4.0;Hive2.1.1;ZooKeeper3.5.10;Python3.7.9
数据集
也可点击下面的链接
链接:https://pan.baidu.com/s/13T8IHjAjvbsvQtQ01Ro__Q?pwd=494j
提取码:494j
代码原理(比较重要)
该部分数据分析使用data2.csv,利用各污染物浓度计算每日的AQI值,得到相应的首要污染物和空气质量等级。根据《环境空气质量指数(AQI)技术规定(试行)》(HJ633-2012),空气质量指数(AQI)可用于判别空气质量等级。首先需得到各项污染物的空气质量分指数(IAQI),其计算公式如下:
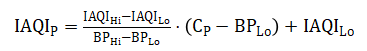
式中各符号含义如下:

对于AQI的计算公式如下:
![]()
空气质量等级范围根据AQI数值划分,等级对应的AQI范围见表3.2。

代码细节为:
(1)首先利用sql语句挑选出所需要的浓度数据,再使用df.collect将其转换成数组;
(2)利用上述公式对表格数据进行计算,存入ArrayBuffer;
(3)将ArrayBuffer转换成Array类型,然后转换成Seq类型,最后转化为RDD;
(4)创建schema以及使用map映射,转化为dataframe格式并储存。


部分代码
对于代码我分成了几个部分,有部分代码和之前只有细微差别
Task3函数的代码(主要部分)
def Task3(df: DataFrame): Unit = {
println("Task3Begin")
val so2Limits = Array(0, 50, 150, 475, 800, 1600, 2100, 2620)
val no2Limits = Array(0, 40, 80, 180, 280, 565, 750, 940)
val coLimits = Array(0, 2, 4, 14, 24, 36, 48, 60)
val o3Limits = Array(0, 100, 160, 215, 265, 800, 9999, 99999)
val pm10Limits = Array(0, 50, 150, 250, 350, 420, 500, 600)
val pm25Limits = Array(0, 35, 75, 115, 150, 250, 350, 500)
val okLimits = Array(0,50,100,150,200,300,99999)
val okLevel = Array("优","良","轻度污染","中度污染","重度污染","严重污染")
val iaqiRanges = Array(0, 50, 100, 150, 200, 300, 400, 500 )
// 选择SO2列
val dataArray = ArrayBuffer[String]()
val levelArray = ArrayBuffer[String]()
val AQIArray = ArrayBuffer[String]()
val mainPollutionArray = ArrayBuffer[String]()
val so2Df = df.selectExpr("`SO2监测浓度(μg/m3)`")
val timeDf = df.selectExpr("`监测日期`")
val no2Df = df.selectExpr("`NO2监测浓度(μg/m3)`")
val pm10Df = df.selectExpr("`PM10监测浓度(μg/m3)`")
val pm25Df = df.selectExpr("`PM2.5监测浓度(μg/m3)`")
val o3Df = df.selectExpr("`O3最大八小时滑动平均监测浓度(μg/m3)`")
val coDf = df.selectExpr("`CO监测浓度(mg/m3)`")
//#####SO2
// 收集到数组
val so2Array = so2Df.collect().map(_.getFloat(0))
var op = 0
for (so2 <- so2Array) {
// println(so2)
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < so2Array.length && flag) {
if (so2 >= so2Limits(i) && so2 < so2Limits(i+1)){
flag = false
}
found = found + 1
}
// println(found)
val AQI = (iaqiRanges(found + 1) - iaqiRanges(found)) * (so2 - so2Limits(found)) / (so2Limits(found + 1) - so2Limits(found)) + iaqiRanges(found)
// println(AQI)
AQIArray += AQI.toString
levelArray += "优"
mainPollutionArray += "so2"
op+=1
}
//#####NO2
//no2Limits
// 收集到数组
val no2Array = no2Df.collect().map(_.getFloat(0))
op = 0
for (no2 <- no2Array) {
// println(so2)
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < no2Array.length && flag) {
if (no2 >= no2Limits(i) && no2 < no2Limits(i+1)){
flag = false
}
found = found + 1
}
// println(found)
val AQI = (iaqiRanges(found + 1) - iaqiRanges(found)) * (no2 - no2Limits(found)) / (no2Limits(found + 1) - no2Limits(found)) + iaqiRanges(found)
// println(AQI)
if(AQI > AQIArray(op).toFloat ){
AQIArray(op) = AQI.toString
mainPollutionArray(op) = "no2"
}
// AQIArray += AQI.toString
// levelArray += "ok"
// mainPollutionArray += "so2"
op = op + 1
}
//#####co
// 收集到数组
val coArray = coDf.collect().map(_.getFloat(0))
op = 0
for (opp <- coArray) {
// println(so2)
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < coArray.length && flag) {
if (opp >= coLimits(i) && opp < coLimits(i+1)){
flag = false
}
found = found + 1
}
// println(found)
val AQI = (iaqiRanges(found + 1) - iaqiRanges(found)) * (opp - coLimits(found)) / (coLimits(found + 1) - coLimits(found))+ iaqiRanges(found)
// println(AQI)
if(AQI > AQIArray(op).toFloat){
AQIArray(op) = AQI.toString
mainPollutionArray(op) = "co"
}
// AQIArray += AQI.toString
// levelArray += "ok"
// mainPollutionArray += "so2"
op = op + 1
}
//#####o3
// 收集到数组
val o3Array = o3Df.collect().map(_.getFloat(0))
op = 0
for (opp <- o3Array) {
// println(so2)
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < o3Array.length && flag) {
if (opp >= o3Limits(i) && opp < o3Limits(i+1)){
flag = false
}
found = found + 1
}
// println(found)
val AQI = (iaqiRanges(found + 1) - iaqiRanges(found)) * (opp - o3Limits(found)) / (o3Limits(found + 1) - o3Limits(found))+ iaqiRanges(found)
// println(AQI)
if(AQI > AQIArray(op).toFloat){
AQIArray(op) = AQI.toString
mainPollutionArray(op) = "o3"
}
// AQIArray += AQI.toString
// levelArray += "ok"
// mainPollutionArray += "so2"
op = op + 1
}
//#####pm10
// 收集到数组
val pm10Array = pm10Df.collect().map(_.getFloat(0))
op = 0
for (opp <- pm10Array) {
// println(so2)
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < pm10Array.length && flag) {
if (opp >= pm10Limits(i) && opp < pm10Limits(i+1)){
flag = false
}
found = found + 1
}
// println(found)
val AQI = (iaqiRanges(found + 1) - iaqiRanges(found)) * (opp - pm10Limits(found)) / (pm10Limits(found + 1) - pm10Limits(found))+ iaqiRanges(found)
// println(AQI)
if(AQI > AQIArray(op).toFloat){
AQIArray(op) = AQI.toString
mainPollutionArray(op) = "pm10"
}
// AQIArray += AQI.toString
// levelArray += "ok"
// mainPollutionArray += "so2"
op = op + 1
}
//#####pm25
// 收集到数组
val pm25Array = pm25Df.collect().map(_.getFloat(0))
op = 0
for (opp <- pm25Array) {
// println(so2)
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < pm25Array.length && flag) {
if (opp >= pm25Limits(i) && opp < pm25Limits(i+1)){
flag = false
}
found = found + 1
}
// println(found)
val AQI = (iaqiRanges(found + 1) - iaqiRanges(found)) * (opp - pm25Limits(found)) / (pm25Limits(found + 1) - pm25Limits(found))+ iaqiRanges(found)
// println(AQI)
if(AQI > AQIArray(op).toFloat){
AQIArray(op) = AQI.toString
mainPollutionArray(op) = "pm25"
}
// AQIArray += AQI.toString
// levelArray += "ok"
// mainPollutionArray += "so2"
op = op + 1
}
//######监测日期
val timeArray = timeDf.collect().map(_.getString(0))
for (time <- timeArray) {
dataArray+=time
}
op = 0
for (aqi <- AQIArray) {
val aqii=aqi.toFloat
val endIndex = 8
var found = -1
var flag = true
for (i <- 0 until endIndex if i < okLimits.length && flag) {
if (aqii >= okLimits(i) && aqii < okLimits(i+1)){
flag = false
}
found = found + 1
}
levelArray(op) = okLevel(found)
op += 1
}
/combo
// var combo1Array = dataArray.zip(AQIArray)
// var combo2Array = combo1Array.zip(levelArray)
// var comboArray = combo2Array.zip(mainPollutionArray)
var comboArray = ArrayBuffer.empty[Array[String]]
comboArray += timeArray.toArray
comboArray += AQIArray.toArray
comboArray += levelArray.toArray
comboArray += mainPollutionArray.toArray
val outArray = comboArray.toArray.transpose
// val transposed = original.map(_.toArray).transpose
// for(i <- 0 until outArray.length){
// for(j <- 0 until outArray(i).length){
// print(outArray(i)(j))
// print(' ')
// }
// println(' ')
// }
var arrRDD = spark.sparkContext.parallelize(outArray)
// val rowRDD = arrRDD.map(attributes => Row(attributes(0), attributes(1),attributes(2),attributes(3)))
val rowRDD = arrRDD.map(attributes => Row.fromSeq(attributes))
val schema_out = StructType(Seq(
StructField("time", StringType),
StructField("AQI", StringType),
StructField("level", StringType),
StructField("primaryPollution", StringType)
))
val df_out = spark.createDataFrame(rowRDD, schema_out)
// val rowRDD = spark.sparkContext.parallelize(dataArray)
// .map(attr => Row(
// attr(0),
// attr(1),
// attr(2),
// attr(3)
// ))
// // 转换为DataFrame
// val df_out = spark.createDataFrame(rowRDD,schema_out)
df_out.show()
df_out.write.option("header", true).mode("overwrite").csv("file:///root/work/Task3/out.csv")
}
主函数代码
def main(args: Array[String]): Unit = {
// Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
// Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
Logger.getLogger("org").setLevel(Level.ERROR)
println("Test Begin")
// println(SparkSession.getClass)
val df = spark.read
.schema(schema)
.option("header", "true")
.csv("file:///root/res.csv")
// df.show()
// Task1(df)
// Task2(df)
val df_data2 = spark.read
.schema(schema_data2)
.option("header", "true")
.csv("file:///root/data2.csv")
// df_data2.show()
Task3(df_data2)
// Task4(df)
}运行spark
[root@master ~]# ./spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh导包
对于包依赖的安装我会过几天更新,具体是步骤0.1,如果有人看到了这里但是我忘了更新可以提醒我!
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
import org.apache.spark.SparkConf
import org.apache.log4j.{Level,Logger}
import org.apache.spark.mllib.stat.Statistics
import scala.collection.mutable.ArrayBuffer一些Spark信息的和schema的导入
val schema = StructType(Array(
StructField("", FloatType),
StructField("监测时间", StringType),
StructField("SO2监测浓度(μg/m³)", FloatType),
StructField("NO2监测浓度(μg/m³)", FloatType),
StructField("PM10监测浓度(μg/m³)", FloatType),
StructField("PM2.5监测浓度(μg/m³)", FloatType),
StructField("O3监测浓度(μg/m³)", FloatType),
StructField("CO监测浓度(mg/m³)", FloatType),
StructField("温度(℃)", FloatType),
StructField("湿度(%)", FloatType),
StructField("气压(MBar)", FloatType),
StructField("风速(m/s)", FloatType),
StructField("风向(°)", FloatType),
StructField("云量", FloatType),
StructField("长波辐射(W/m²)", FloatType)
))
val schema_data2 = StructType(Array(
StructField("监测日期", StringType),
StructField("SO2监测浓度(μg/m3)", FloatType),
StructField("NO2监测浓度(μg/m3)", FloatType),
StructField("PM10监测浓度(μg/m3)", FloatType),
StructField("PM2.5监测浓度(μg/m3)", FloatType),
StructField("O3最大八小时滑动平均监测浓度(μg/m3)", FloatType),
StructField("CO监测浓度(mg/m3)", FloatType)
))
val spark = SparkSession
.builder()
.master("spark://192.168.244.130:7077")
.getOrCreate()
如果spark链接报错
如果链接spark的时候会失败,可以使用下面的代码替换之前的(但是这个只能是测试的时候用,是假的Spark,具体报错的debug过几天我也会做,忘了有读者需要可以提醒我)
val spark = SparkSession
.builder()
.master("local[2]")
.getOrCreate()运行结果
Test Begin
Task3Begin
+---------+---------+--------+----------------+
| time| AQI| level|primaryPollution|
+---------+---------+--------+----------------+
|2019-4-16| 70.0| 良| no2|
|2019-4-17|141.81818|轻度污染| o3|
|2019-4-18| 46.25| 优| no2|
|2019-4-19| 62.5| 良| no2|
|2019-4-20| 85.0| 良| no2|
|2019-4-21| 66.25| 良| no2|
|2019-4-22| 40.0| 优| no2|
|2019-4-23| 35.0| 优| pm10|
|2019-4-24| 42.5| 优| o3|
|2019-4-25| 39.5| 优| o3|
|2019-4-26| 44.0| 优| pm10|
|2019-4-27| 60.0| 良| no2|
|2019-4-28| 52.5| 良| no2|
|2019-4-29| 42.5| 优| no2|
|2019-4-30| 57.5| 良| o3|
| 2019-5-1| 40.5| 优| o3|
| 2019-5-2| 41.25| 优| no2|
| 2019-5-3|76.666664| 良| o3|
| 2019-5-4| 80.0| 良| no2|
| 2019-5-5| 65.0| 良| no2|
+---------+---------+--------+----------------+
only showing top 20 rows
Process finished with exit code 0
















 9915
9915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









