




 文章详细介绍了二叉树的概念、结构、性质以及在实际中的应用,特别强调了满二叉树和完全二叉树的区别。此外,文章深入讲解了堆的概念,包括大根堆和小根堆,并提供了堆排序的实现代码。堆排序的时间复杂度为O(N*logN),适用于TOP-K问题。最后,文章提到了二叉树的遍历方法,包括前序、中序和后序遍历。
文章详细介绍了二叉树的概念、结构、性质以及在实际中的应用,特别强调了满二叉树和完全二叉树的区别。此外,文章深入讲解了堆的概念,包括大根堆和小根堆,并提供了堆排序的实现代码。堆排序的时间复杂度为O(N*logN),适用于TOP-K问题。最后,文章提到了二叉树的遍历方法,包括前序、中序和后序遍历。
二叉树
- 树概念及结构
1.1树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因 为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
有一个特殊的结点,称为根结点,根节点没有前驱结点
除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
因此,树是递归定义的。
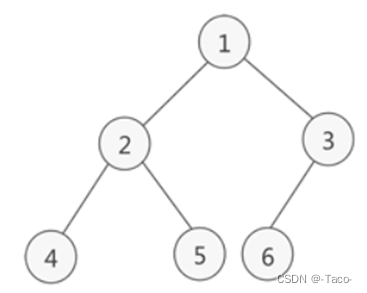
1.2树的相关概念
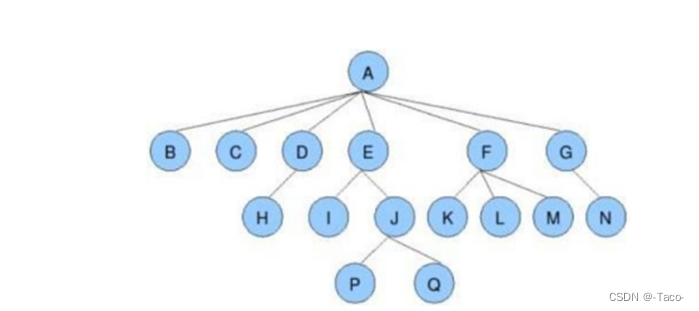
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I...等节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
注:子树是不相交的,除根结外,每个结点有且仅有一个父节点,一棵N个结点的树有N-1条边。
- 3树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间 的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法 等。我们这里就简单的了解其中最常用的孩子兄弟表示法(左孩子右兄弟)
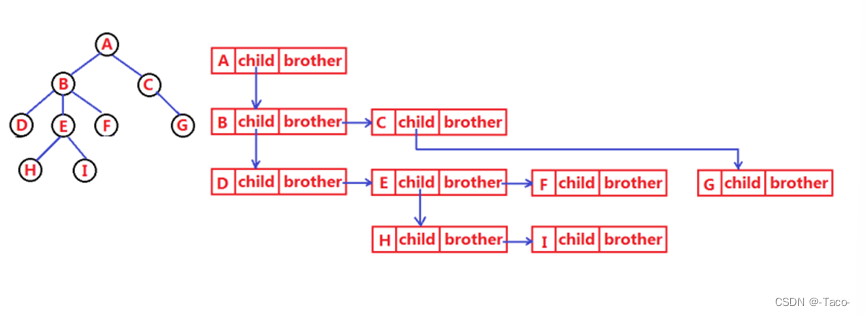
typedef int DataType;
struct Node
{
struct Node* _firstChild1; // 第一个孩子结点
struct Node* _pNextBrother; // 指向其下一个兄弟结点
DataType _data; // 结点中的数据域
};
1.4树在实际中的应用
文件系统就是树在实际生活中的应用
2.二叉树概念及结构
2.1概念
一棵二叉树是结点的一个有限集合,该集合:
1. 或者为空
2. 由一个根节点加上两棵别称为左子树和右子树的二叉树组成
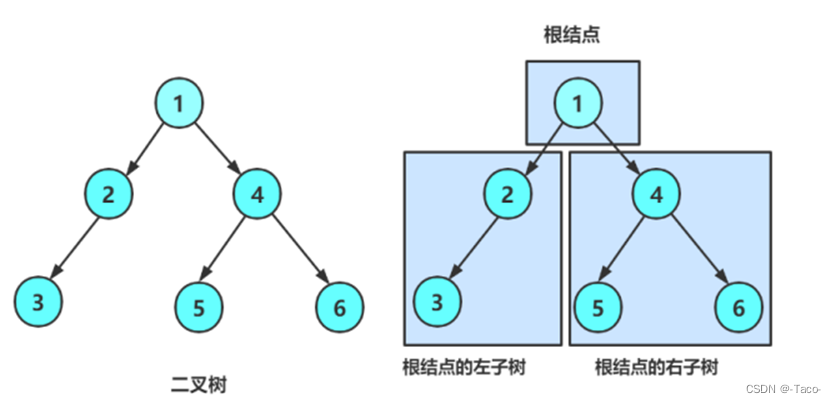
1. 二叉树不存在度大于2的结点
2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树

3 特殊的二叉树:
1. 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是 说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。
2. 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对 应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树
堆排序—时间复杂度O(N*logN)
Topk---类似点外卖,想吃最好吃的饭,需要在n个里面排序排除最好的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











