






我知道关于YOLOv5训练自己的数据集教程特别多,但是对于很久不训练的我找了一下午的教程都没有学会或者各种错误(可能是个人水平有限),所以一气之下我决定写一篇通俗易懂的新手如何训练自己的数据集。(手把手带着大家一起搭建环境、源码下载、数据集的标注、参数的修改、性能的评估等)
一.前期准备
一台windows系统的PC机,如果有一个不错的GPU就更好了,
(1)数据集到底是个什么玩意?
数据集分为:训练集、验证集、测试集;训练集就是我们需要用来训练网络的,验证集:是我们可以随时观测到模型训练的情况进行参数的一些修改,测试集:就是训练完成后用训练好的权重进行测试的数据。
(2)什么是labelimg、labelme?
labelimg:主要用于目标检测的目标框绘制,得到关于我们训练的边框位置、类别等数据;怎么去下载这个东西呢?
#你们应该有canda各种软件了
win+r输入cmd进入终端
conda create -n yolov5 python=3.7
#进入你运行yolo的环境
pip install labelimg
#或者
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelimg
OK出错了
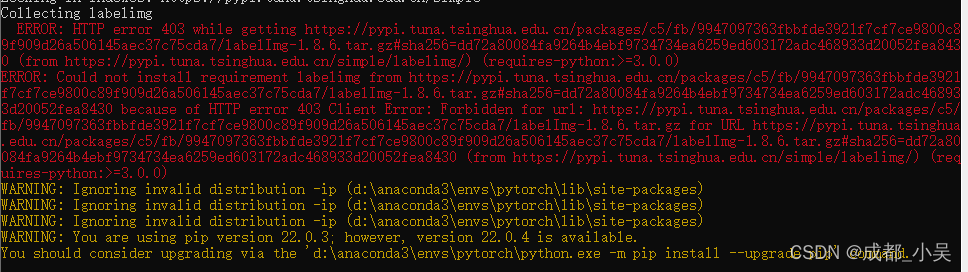
好像不能用清华镜像源,直接pip install labelimg;
下载完成后:
#直接输入
labelimg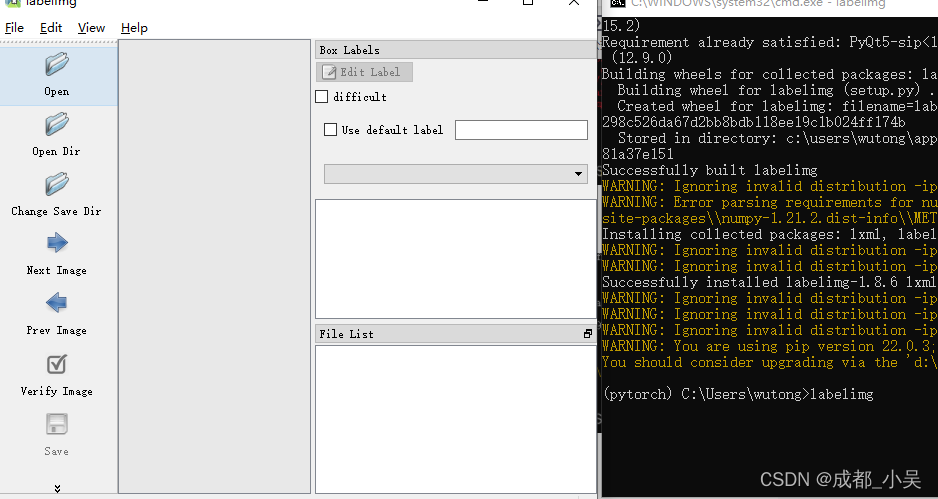
把你的数据集(你的图片放在一个文件夹例如:images),另外创建一个生成后的数据保存文件夹(例如:Annotations),点击file-open dir(这是你的数据集路径),点击file-chenge save dir(这是你的输出路径)
现在就可以进行标注了 ,点击edit-create,框出你要检测的东西,给他输入一个你想要把他分成什么类别比如:person等都可以。这里还有一些快捷键和几种不同的标注格式,
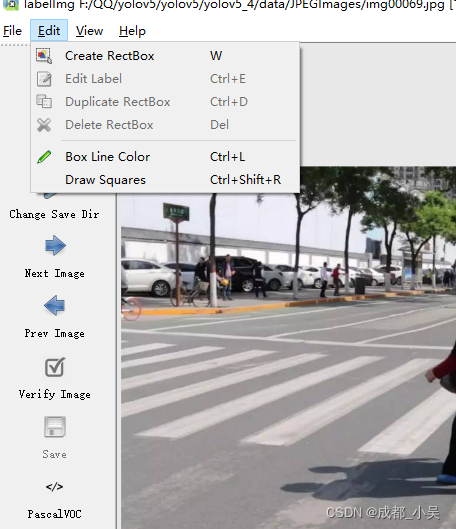
比如左边的:

voc标注方式,最后生成的是.xml格式的文件,
而再次点击它会出现yolo格式的标注,最会生成的txt格式的文件,
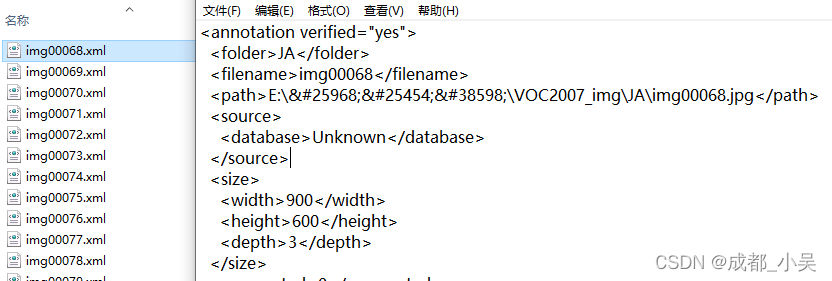
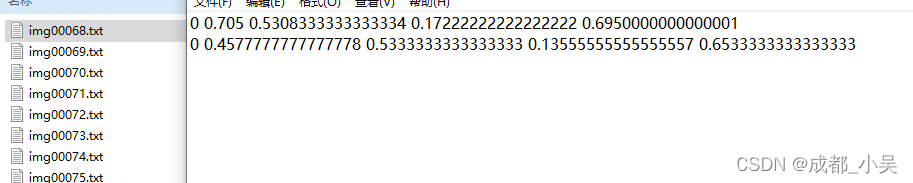
最后我们需要的是.txt文件格式的标注,但是如果你要是忘了后面还是有代码将xml转换为txt格式的代码,快捷键:W是启动标注,A是上一张,D是下一张图片,(就像我们以前打CF前后左右键)在view里面点击自动保存。
数据集就标注完成了,现在你手里有两个文件夹一个存放原始图片的,一个是存放标注文件的,
labelme:主要是用于分割的一个工具,这里先不讲解。
二.yolov5如何去训练
大家应该都下载好了自己的源码了,如果没有可以点击下载源码(到githu搜索YOLOV5也可以下载),我这里还是延续上一篇文章,yolov5的4.0版本,很多人在这里都遇到一些问题
NO model SPPF
#
tensor a no match tensor b首先我们应该想到的是自己权重版本下载错误的原因
我们拿到源码和数据集怎么去运行train.py,需要改哪些地方

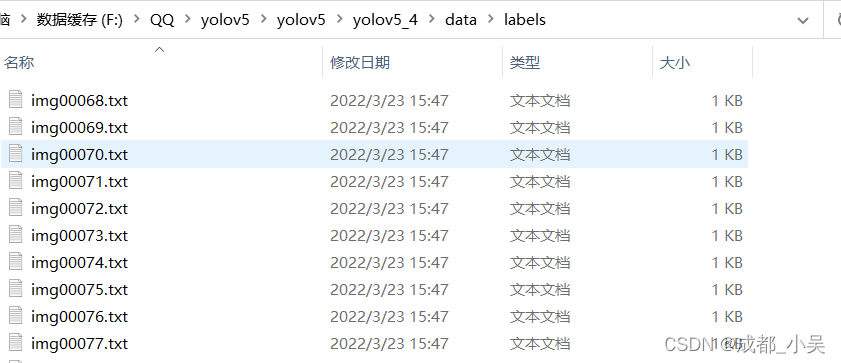
(1)首先你应该把你刚刚的两个文件放到data文件夹里面去:把原图片放到JPEGimages文件夹,把标签文件还是放在原来的文件里面,images里面是源码自带的文件夹所以不管他,
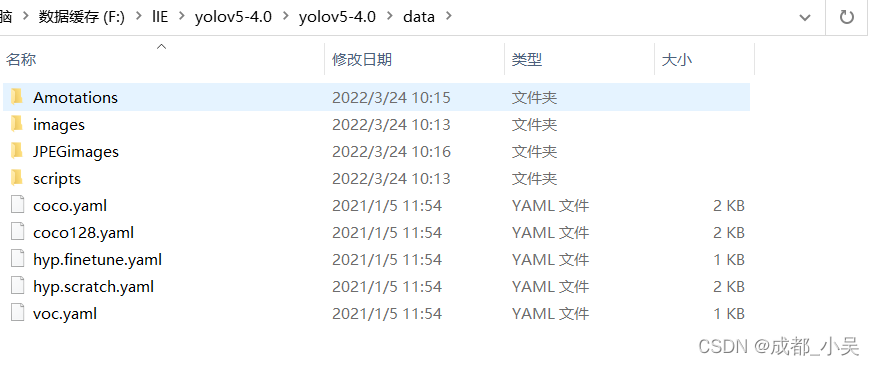
现在我们训练是需要两个文件train.txt、val.txt、原图片、.txt格式的标注文件。所以我们这里要运行一个代码将数据集分为训练集、测试集、验证集等几个txt文件(先不用管几个反正需要的只有train、val),就在data目录下创建一个python代码:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = 'D:/FOD/yolov5/yolov5_4/data/images/'+total_xml[i][:-4] +'.jpg' '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行完这个代码会出现以下文件夹:
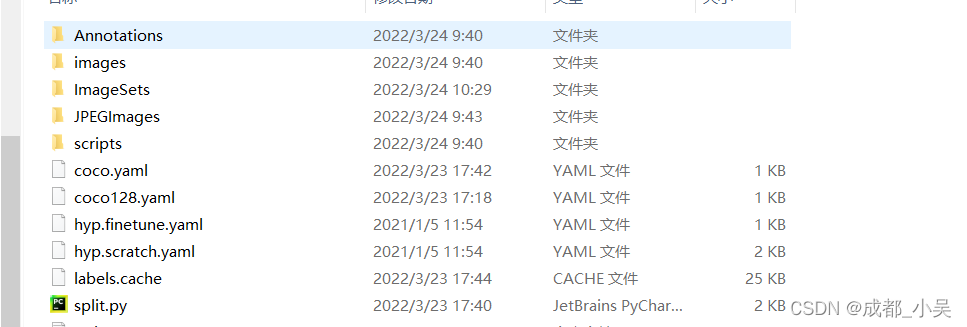
imagesets-mian里面就存放着我们一会需要的train.txt, val.txt等四个文件,
最重要的问题也是经常训练出错的问题:没有找到图片啊,图片加载失败啊什么的

就是刚刚我们生成数据集的代码里面,生成的四个文件主要是存放的数据集的路径:

这四个文件里面存放的是我们的图片路径,所以我们就要改一下上面name的代码,改成你自己的文件路径:比如D:/张三/李四/yolov5/data/JPEGimages/img.jpg, 记住一定要是英文路径,斜杠一定要这个斜杠,必须要有后缀。我们这里JPEGimages存放的原图片所以就写成JPEGimages;
我们的标注文件默认为.xml,如果你已经是.txt格式的你就直接在data文件夹下面创建一个labels文件夹把他们放到里面去,为了以防万一再把所有的txt文件放到JPEGimages存放原图的文件夹如下:你这里应该是JPEGimages下面
labels文件:
如果是.xml的话我们运行下面的代码:将xml格式转换为txt格式的就完事了;
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 数据标签
classes = ['person'] #需要修改
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if w>=1:
w=0.99
if h>=1:
h=0.99
return (x,y,w,h)
def convert_annotation(rootpath,xmlname):
xmlpath = rootpath + '/Annotations'
xmlfile = os.path.join(xmlpath,xmlname)
with open(xmlfile, "r", encoding='UTF-8') as in_file:
txtname = xmlname[:-4]+'.txt'
print(txtname)
txtpath = rootpath + '/labels' #生成的.txt文件会被保存在labels目录下
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath,txtname)
with open(txtfile, "w+" ,encoding='UTF-8') as out_file:
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
out_file.truncate()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
rootpath='F:\\QQ\yolov5\yolov5\\yolov5_4\\data' ##需要修改的地方改成你的路径
xmlpath=rootpath+'\\Annotations'这就是xml的路径
list=os.listdir(xmlpath)
for i in range(0,len(list)) :
path = os.path.join(xmlpath,list[i])
if ('.xml' in path)or('.XML' in path):
convert_annotation(rootpath,list[i])
print('done', i)
else:
print('not xml file',i)
这个代码创建在项目的文件下也就是和你的train.py在一起创建,运行完之后:
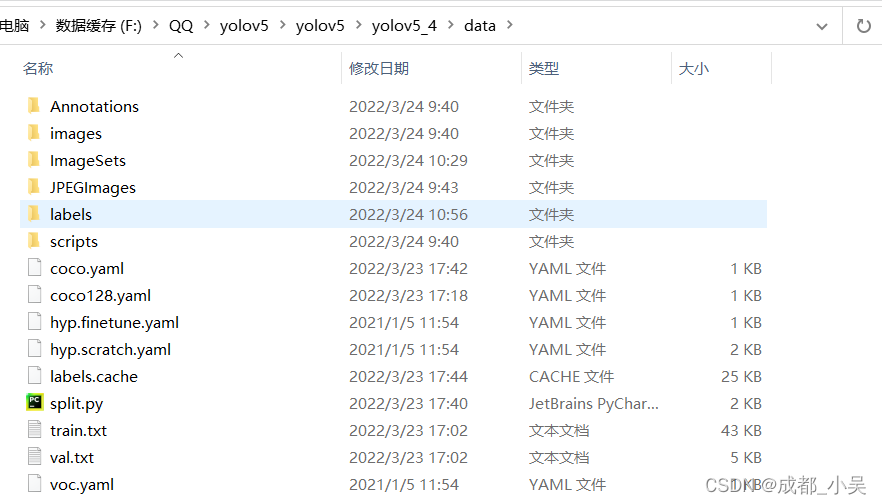
数据集分配问题解决了之后我们要修改coco.yaml,models文件夹下面yolov5s.yaml文件的东西,
coco.yaml里面存放的是train.txt,和val.txt的存放路径,以及类别数量,和类别名字:也就是我们刚刚代码生成的文件路径,
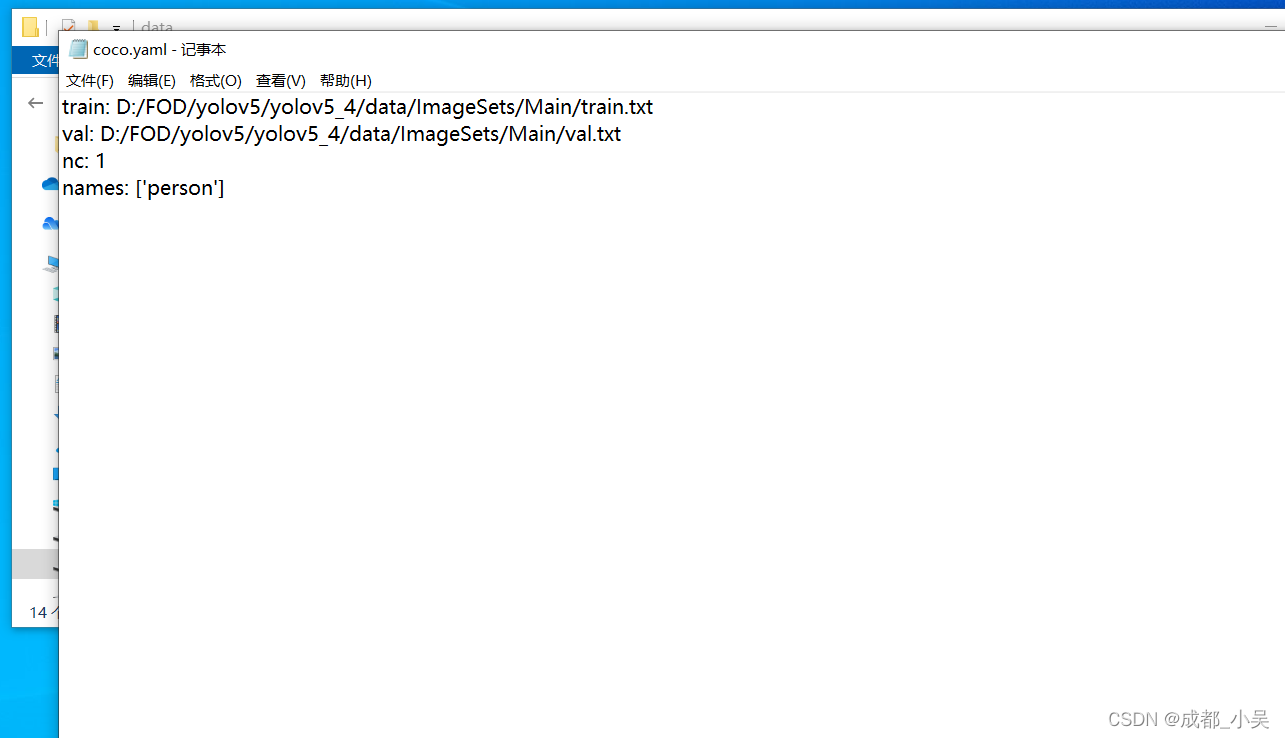
yolov5s.yaml改一下类别就可以了,改成你自己的类别数量。
基本上没有需要改的了,我们直接打开train.py看看:直接划到最下面参数部分,

代码里面的data,从data里面的coco.yaml读取train.txt(训练集的地址),train.txt就是存放的图片路径这样就可以读取到图片,标签的话自动定位到对应到labels文件的标签,weights就是预训练模型,epoch训练的轮数,我一般设置的是200,300,batch_size是多少张图片打包,如果电脑不好就是1,2,8,16,32,64,越大就是电脑需要的性能越好,device:设置为0,workers:代表启动的线程数,如果电脑不好就设置为0,表示主线程。
这样我们就可以直接运行这个代码了,运行完之后在根目录下面runs--train里面找到自己的权重,有一个best.pt用来去检测。
三.性能评价指标
3.1训练完成以后,上级领导可能会问这个东西怎么判定他的准确率啊或者一个性能的好坏啊;
所以我们就需要分析一下数据的指标图如下:
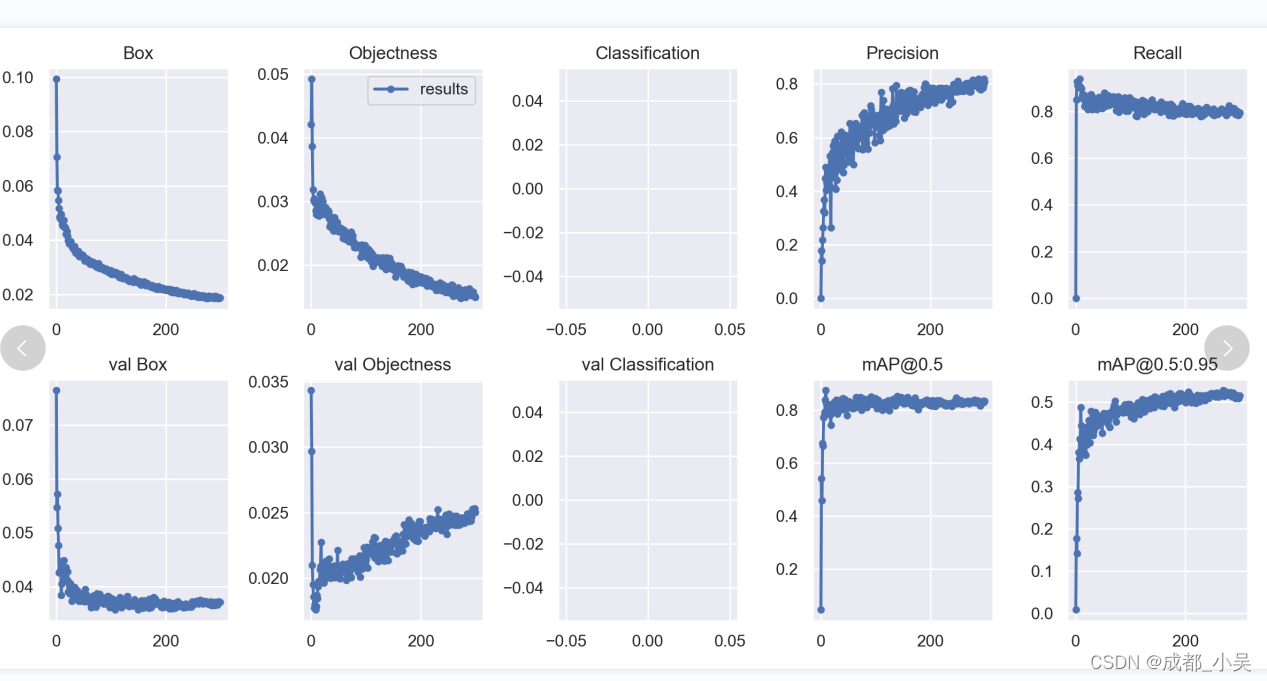
Box : Giou loss 作为预测框与真实框的损失,通俗一点的话就是损失函数越小边框的预测准确率越高。
Objects:目标检测损失,越小越准确‘
classification:类别损失函数,我这里只是一个类别所以没有,越小的话类别准确率越高。
Precision:精度(找对的正类/所有找到的正类);
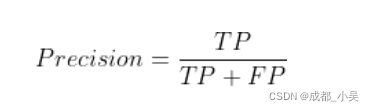

①. 真阳性(True Positive,TP):样本的真实类别是正例,并且模型预测的结果也是正例,预测正确
②. 真阴性(True Negative,TN):样本的真实类别是负例,并且模型将其预测成为负例,预测正确
③. 假阳性(False Positive,FP):样本的真实类别是负例,但是模型将其预测成为正例,预测错误
④. 假阴性(False Negative,FN):样本的真实类别是正例,但是模型将其预测成为负例,预测错误
原文链接:https://blog.csdn.net/m0_54111890/article/details/123362039
Recall:召回率(找对的正类/所有本应该被找对的正类);
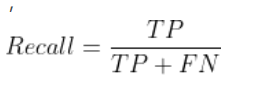
mAP@0.5 & mAP@0.5:0.95:就是mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。(0.5是iou阈值=0.5时mAP的值),mAP只是一个形容PR曲线面积的代替词叫做平均准确率,越高越好。
3.2如何提高训练的效果(mAP)大家可以看一下这篇
3.2 YOLOv5获得最佳训练效果指南
大多数情况下,只要数据集足够大且良好标注(provided your dataset is sufficiently large and well labelled),就可以在不更改模型或训练设置的情况下获得良好的结果。如果一开始没有得到好的结果,在考虑任何更改之前,首先使用所有默认设置进行训练。这有助于建立性能baseline和需要改进的地方。
YOLOv5提供了大量的信息包括训练损失, 验证损失, 精确率(P), 召回率(R), mAP等可视化结果, 包括PR曲线(PR curve), 混淆矩阵(confusion matrix, 马赛克训练, 测试结果等数据集统计图像。这些信息的图像所在目录是yolov5/runs/Train/exp
1 数据集方面
1.1.1每个类别的图像
每个类别的图像张数大于1500张
1.1.2 每个类别的实例
我们人工标注的目标框就是实例,每个类别的实例要大于10000张。
1.1.3 图像的多样性
数据集必须展现出部署环境,推荐来自一天中不同时间、不同季节、不同天气、不同光照、不同角度、不同数据源(在线抓取、本地收集、不同相机)等的图像。
1.1.4 标注的一致性
所有图像中所有类的所有实例都必须标注。部分标注将不起作用。
1.1.5 标注的精度
边框必须紧密地包围每个目标。目标和边框之间不应存在任何空。任何目标都不应缺少标签。
背景图像:背景图像是图像里没有感兴趣目标的图像,加到数据集以减少误报 (FP) 。建议约 0-10% 的背景图像,以帮助减少 FP(COCO数据集有1000张背景图像供参考,占总数的 1%)。
1.2 模型选择
更大的模型,如YOLOv5x,在几乎所有情况下都会产生更好的结果,但参数更多,运行速度也更慢。对于移动应用推荐YOLOv5s/m;对于云或桌面应用,推荐YOLOv5l/x。 对于所有YOLOv5系列模型全面的比较,请看这里
1.3 训练设置
在修改任何内容之前,首先使用默认设置进行训练,以建立性能baseline。
( first train with default settings to establish a performance baseline)
training.py的argparser中提供了训练设置的完整列表。
1.3.1 epochs:
从300个epoch开始。如果过早过拟合,那么可以减少epochs。如果在300个epoch后没有发生过拟合,则训练更长时间,即 600、1200 个等epoch。
1.3.2 图像大小
COCO以–img 640的原始分辨率训练,尽管由于数据集中有大量的小目标,它可以从更高分辨率(如-img 1280)的训练中受益。如果有许多小目标,则自定义数据集将从原始或更高分辨率的训练中受益。最佳推理结果是训练时设置的 --img x与推理时设置的–img x相同,例如如果–img 1280训练,则在–img 1280进行推理测试。
1.3.3 batch size
使用自己的硬件资源允许的最大Batch size。小的Batch size会产生较差的batchnorm统计,应该避免。
1.3.4 超参数
默认超参数位于hpy.scratch.yaml中。建议先使用默认超参数进行训练,然后再考虑修改任何参数。一般来说,增加augmentation超参数将减少和延迟过度拟合,从而允许更长的训练时间和更高的最终mAP。减少loss component gain 超参数(如hyp[‘obj’])将有助于减少对特定loss component的过度拟合。
2 以数据为中心的AI(Data-Centric AI)
以数据为中心的AI(data-centric AI)这一概念是吴恩达(Andrew Ng)的提出的。
AI system = Code + Data
Code = model / algorithm
提高模型指标的两种路径
以模型为中心
通过改进模型来提升表现(Asks how you can change the model to improve performance.)
以数据为中心
通过改进数据来提升表现(Asks how you can change or improve your data to improve performance.)
2.1 听听大佬怎么说的
训练神经网络的第一步是根本不是接触任何神经网络代码,而是从彻底检查数据开始。这一步至关重要。(The first step to training a neural net is to not touch any neural net code at all and instead begin by thoroughly inspecting your data. This step is critical.)
你的模型架构足够好了。总而言之,不要试图和一屋子的博士比聪明。相反,在尝试改进模型之前,请确保数据的质量是一流的。(your model architecture is good enough.To summarize — don’t try to outsmart a room full of PhDs. Instead, make sure the quality of your data is top-notch before trying to improve the model.)
以数据为中心的ML归结为以下三点:
(1)数据飞轮:同步开发模型和数据。(The data flywheel: develop model and data in tandem)
(2)您可以自己对数据进行注释,至少在开始时是这样。(Annotate the data yourself, at least at the beginning)
(3)使用工具尽可能减少MLOps的麻烦(Use tools to reduce the MLOps hassle as much as possible)
注释
tandem: adv. 二马纵列地,这里翻译成两项工作同时展开
MLOps: 全称是Machine Learning Operations ,Andrew Ng在他的ppt中这样描述MLOps最重要的任务是在ML项目生命周期的所有阶段提供高质量的数据。(MLOps’ most important task is to make high quality data available through all stages of the ML project lifecycle.)
就这样匆匆的结束了大家有什么意见可以进QQ群一起交流:471550878;














 9806
9806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









