






一个几万甚至超过十万数据量的excel导入到数据库中的业务也是经常可以遇到,如果采用传统的方案将excel中的数据直接读到内存中然后写入数据库,此时可能会出现导入速度慢、内存不足或者数据库写入失败等问题。下面介绍一种安全且快速的导入数据方案。
1、对sheet数据处理
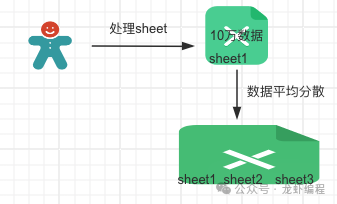
将大数据量的excel数据平均分散到若干个sheet中,这样做的目的是让后端开启多个线程来快速处理sheet数据。
2、后端处理excel数据
后端接收到前端出来的excel数据后,利用EasyExcel解析excel中的数据,然后将数据写入数据库中,其处理excel的整体流程图如下所示:
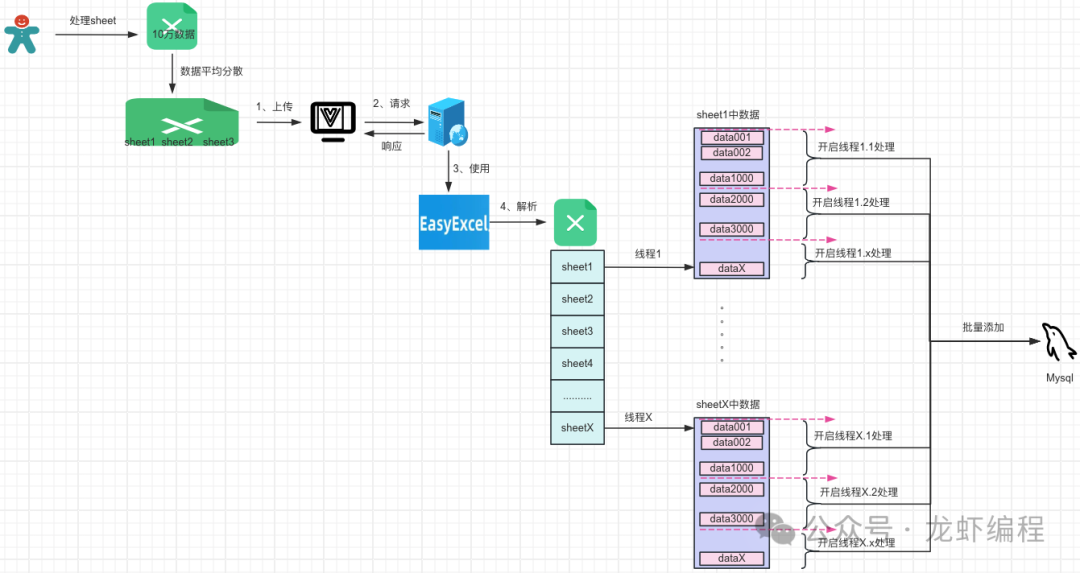
后端处理excel数据的基本思想:后端开启和sheet页等量的线程,每个线程单独处理对应的sheet页上的数据,在每个sheet页中又开启若干个异步线程处理批量将解析好的数据插入的数据库中,其流程图如下所示:
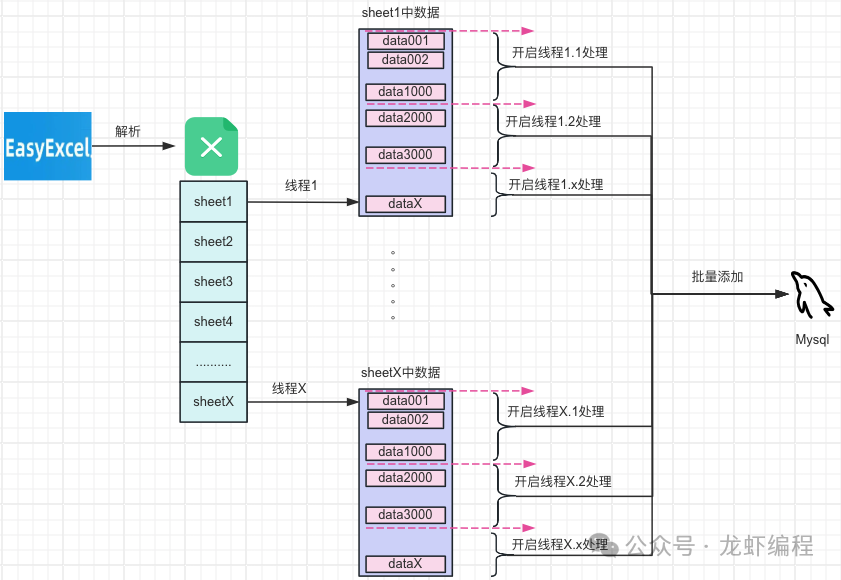
通过将数据平均分到不同的sheet中,然后再将每个sheet的数据按照一定数量为一组批量的插入到数据库,单个sheet的工作流程如下:
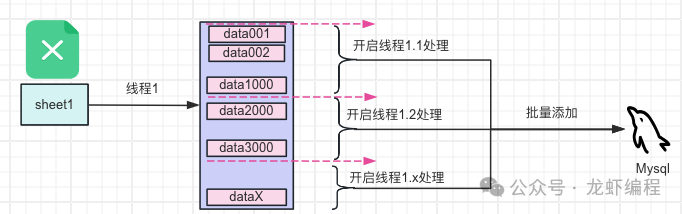
通过分sheet方式和在sheet中将数据分组处理的方式,一方面保证数据数据的处理速度,另一方面可以实现将读取并处理好的数据从内存中清理掉来保证内存不会被占满。
Mysql默认情况下的批处理方式逐条执行SQL语句,这样的效率非常的低,为了提高批量添加数据的效率需要开启Mysql的批处理。配置如下:

效果如下:

3、方案的落地实现
controller层
@RestController
@RequestMapping("/excel")
@Slf4j
public class ExcelController {
ExecutorService executorService = Executors.newCachedThreadPool();
@Resource
private ExcelService excelService;
@PostMapping("/importExcel")
public String importExcel(@RequestParam("file")MultipartFile file) throws IOException {
//将sheet的任务加集合中
List<Callable<Object>> taskList = Lists.newArrayList();
//获取sheet的个数
List<ReadSheet> readSheets = EasyExcelFactory.read(file.getInputStream()).build().excelExecutor().sheetList();
int sheetSize = readSheets.size();
for (int i = 0; i < sheetSize; i++) {
int sheetNum = i;
taskList.add(()-> {
EasyExcel.read(file.getInputStream(), ExcelEntity.class, new ExcelListener(excelService, sheetNum)).sheet(sheetNum).doRead();
return null;
});
}
try {
executorService.invokeAll(taskList);
} catch (Exception e) {
log.error("导入出现异常", e);
throw new RuntimeException("执行失败");
}
return "success" ;
}
}easyexcel的监听类
@Getter
@Slf4j
public class ExcelListener extends AnalysisEventListener<ExcelEntity> {
private List<ExcelEntity> dataList = new ArrayList<>();
private ExcelService excelService;
private Integer sheetNum;
long startTimeMillis;
private final ExecutorService executorService = Executors.newFixedThreadPool(20);
public ExcelListener(ExcelService excelService, Integer sheetNum){
this.excelService = excelService;
this.sheetNum = sheetNum;
this.startTimeMillis = System.currentTimeMillis();
}
@Override
public void invoke(ExcelEntity excelEntity, AnalysisContext analysisContext) {
dataList.add(excelEntity);
if (dataList.size() >= 1000) {
saveBatch();
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
if (CollectionUtils.isNotEmpty(dataList)) {
saveBatch();
}
}
private void saveBatch() {
List<ExcelEntity> excelEntityArrayList = Lists.newArrayList(dataList);
executorService.execute(new SaveTask(excelEntityArrayList, excelService, sheetNum, startTimeMillis));
dataList.clear();
}
}
@Slf4j
class SaveTask implements Runnable {
private List<ExcelEntity> excelEntityList;
private ExcelService excelService;
private Integer sheetNum;
private long startTime;
public SaveTask(List<ExcelEntity> excelEntityList, ExcelService excelService, Integer sheetNum, long startTime) {
this.excelEntityList = excelEntityList;
this.excelService = excelService;
this.sheetNum = sheetNum;
this.startTime = startTime;
}
@Override
public void run() {
excelService.saveBatch(excelEntityList);
log.info("第{} sheet完成入库, 消耗时间:{} 毫秒", sheetNum, System.currentTimeMillis() - startTime);
}
}service层
@Service
@Slf4j
public class ExcelService {
@Resource
private ExcelTestMapper excelTestMapper;
public void saveBatch(List<ExcelEntity> excelEntityList) {
excelTestMapper.batchInsert(excelEntityList.stream().map(v-> {
ExcelTest excelTest = new ExcelTest();
BeanUtils.copyProperties(v, excelTest);
return excelTest;
}).collect(Collectors.toList()));
}
}mapper层
public interface ExcelTestMapper {
int batchInsert(@Param("excelTestList") List<ExcelTest> excelTestList);
}
----------------------mapper.xml--------------------
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.excel.mybatis.mapper.ExcelTestMapper">
<resultMap id="baseMap" type="com.excel.mybatis.entity.ExcelTest">
<id column="id" jdbcType="INTEGER" property="id"/>
<result column="student_num" jdbcType="VARCHAR" property="studentNum"/>
<result column="student_name" jdbcType="DOUBLE" property="studentName"/>
<result column="student_address" jdbcType="INTEGER" property="studentAddress"/>
</resultMap>
<sql id="baseTable">
excel_test
</sql>
<insert id="batchInsert">
insert into excel_test(student_num, student_name, student_address)
values
<foreach collection="excelTestList" item="excelTest" separator=",">
(#{excelTest.studentNum}, #{excelTest.studentName}, #{excelTest.studentAddress})
</foreach>
</insert>
</mapper>配置文件:
server:
port: 8080
spring:
application:
name: mybatis-service
#数据库的配置
datasource:
username: longxia
password: longxiabiancheng
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/longxia?rewriteBatchedStatements=true&serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
#mybatis的实体类和mapper.xml文件的位置信息
mybatis:
type-aliases-package: com.excel.mybatis.entity
mapper-locations: classpath:mapper/*.xml
#执行包下的日志级别
logging:
level:
com.excel.mybatis.mapper: debug数据表:
CREATE TABLE `excel_test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`student_num` varchar(64) NOT NULL,
`student_name` varchar(64) NOT NULL,
`student_address` varchar(64) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13513 DEFAULT CHARSET=utf8 COMMENT='excel测试'总结:
(1)excel数据量很大的时候不适合采用传统的一次性导入的方式,要么分批导入要么采用分sheet和单sheet中数据分组处理相结合的方式来完成,这样可以保证不会出现内存不足的问题。
(2)执行批量处理添加数据的时候,需要通过配置开启Mysql的批处理功能。















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









