






集合的使用(主要是ArryList的使用)
1.知识点
java集合框架中的各种接口:
Collection接口存储一组不唯一,无序的对象
List接口存储一组不唯一,有序(插入顺序)的对象
Set接口存储一组唯一,无序的对象
Map接口存储一组键值对象,提供key到value的映射
ArrayList实现了长度可变的数组,在内存中分配连续的空间,遍历元素和随机访问元素的效率比较高
LinkedList采用了链表存储方式,插入和删除元素时效率比较高
Vector类类似于ArrayList,但是Vector类是同步的,在多个线程同时访问时安全性更好,但性能稍差
Stack类继承自Vector类,实现一个后进先出的栈
ArrayList类
基本概念:
-
ArrayList类支持可随需要而增长的动态数组
-
ArrayList类对象以一个初始大小被创建,当超过它的大小,可以自动增长,当对象被删除后,可以自动缩小
-
ArryList相对于数组来说更加灵活,更加方便。
具体的使用方法
构造方法:
//和数组的实例化对象相似,可以把ArryList看成一个动态的数组。
//因为储存地址是连续的也可以利用下标访问
ArryList 变量名 = new ArryList();
//这边实例化的对象都是Object类的,所以在使用其自带的函数的时候需要强行转换成对应的类型
这波可以通过泛型来解决强转的问题(因为强制转换不安全,而且Object可以插入任何数据)文章后面为了方便都是使用泛型
使用泛型实例化对象
//T为模板,代表其中可以放类或者其他数据类型
ArryList<T> 变量名 = new ArryList<T>();
ArryList实例化时大小默认开10,我们也可以手动分配空间
ArrayList(int capacity) //构造一个具有指定初始容量的空列表ArryList中一些方法名(都是通过 对象.方法名 去调用该方法)
| 方法名 | 说明 |
|---|---|
| boolean add(Object o) | 在列表的末尾顺序添加元素 |
| void add(int index, Object o) | 在指定的索引位置添加元素,索引位置必须介于0和列表中元素个数之间 |
| int size() | 返回列表中的元素个数 |
| Object get(int index) | 返回指定索引位置处的元素。取出的元素是Object类型,使用前需要进行强制类型转换 |
| boolean contains(Object o) | 判断列表中是否存在指定元素 |
| boolean isEmpty() | 判断列表是否为空 |
| boolean remove(Object o) | 从列表中删除元素, 在大多数情况下,当arrayList包含UserDefined数据类型的项时,此方法不会给出正确的结果。它只适用于原始数据类型。因为用户希望根据对象字段的值删除项,并且无法通过Remove函数进行比较。 |
| Object remove(int index) | 从列表中删除指定位置元素,起始索引位置从0开始,注意删除元素后的所有元素下标都会改变 |
| void clear() | 删除列表中的所有元素 |
具体细节方法可以参考(7条消息) Java集合常用方法介绍_xyphf的博客-CSDN博客_java集合常用方法![]() https://blog.csdn.net/xyphf/article/details/84000952
https://blog.csdn.net/xyphf/article/details/84000952
或者百度其他方法
迭代器
因为在一些集合中数据储存不是按照内存顺序进行储存的,不能通过下标直接访问,所以用迭代器进行遍历访问和操作
迭代器的创建
在对集合使用`for-each`循环时实际上是使用迭代器在进行遍历
//创建名为it泛型为<Worker>的迭代器,然后需要容器中的方法进行赋值
Iterator<Worker> it = list.iterator();创建完迭代器后指向容器,下面介绍常用的遍历操作方法
Iterator<Worker> it = list.iterator();
while(it.hasNext()) {//判断是否存在下一个元素
Worker path = it.next();//next方法返回下一个元素的内容
System.out.println(path.toString());
}
}
映射接口Map
- 映射是一个存储关键字/值对的集合
- 给定一个关键字,就可以得到它的值。关键字和值都是对象,每一对关键字/值称为一项
- 关键字必须是唯一的,但值是可以重复的
- Map接口映射关键字到值。当一个值被存储到Map对象后,可以使用它的关键字来检索它
- SortedMap接口继承了Map,用于确保项按关键字升序排序。
- Map.Entry是Map的一个内部类接口,描述映射中的项(键值对)
Map是没有提供迭代器方法的所以要访问必须通过set创建迭代器
Iterator<Worker>it = set.iterator();
while(it.hasNext()){
Map.Entry res = it.next();
System.out.println(res.getValue().toString());
}
HashMap类
HashMap类使用散列表实现Map接口,同时继承自AbstractMap类
散列映射并不保证它的元素的顺序。因此,元素加入散列的顺序并不一定是它们被迭代函数读出的顺序
2.例题
1.编写程序,要求能完成以下功能:
(1)设计一个Worker(工人)类,此类包括以下内容:
①3个私有成员变量:no(工号,String型,只读),name(姓名,String型,可读写),salary(工资,double型,可读写)。
②一个能创建指定工号、姓名和工资的工人的构造方法。
③3个私有变量的getter和setter方法。
④重写继承自Object的toString方法,返回字符串“<no>号工人<name>,每月工资为<salary>元”。
⑤重写继承自Object的equals方法,只有当形参对象与此对象的各个成员变量值都相同时,才返回true,否则返回false。
(2)编写一个测试程序WorkerTest类,要求在main方法中完成以下功能:
①使用泛型<Worker>创建一个ArrayList对象,并在其中添加三个工人,基本信息如下:
| 工号 | 姓名 | 工资 |
| 1001 | 张三 | 3000 |
| 1003 | 李四 | 3500 |
| 1004 | 王五 | 2500 |
②在张三之后添加一个工人,基本信息为“工号:1002,姓名:赵六,工资:3200”。
③统计并输出工人的总人数。
④利用for循环遍历,依次输出各个工人的姓名。
⑤删除“工号为1003,姓名为李四,工资为3500”的员工信息。删除前,先判断是否存在该员工信息,如果有则删除,并输出“成功删除员工信息!”;否则输出“不存在该员工信息,删除失败!”
⑥利用迭代器遍历元素,输出删除后各工人的基本信息。
代码如下:
import java.util.*;
public class WorkerTest {
public static void main(String[] args) {
ArrayList<Worker> list = new ArrayList<Worker>();
list.add(new Worker("1001","张三",3000d));
list.add(new Worker("1003","李四",3500d));
list.add(new Worker("1004","王五",2500d));
list.add(1, new Worker("1002","赵六",3200d));
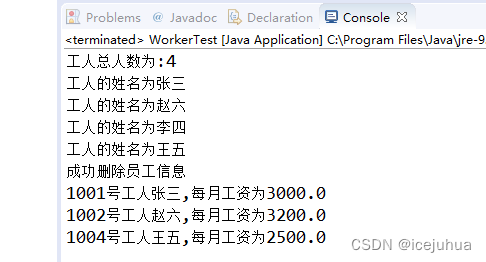
System.out.println("工人总人数为:"+list.size());
for(Worker x:list) {
System.out.println("工人的姓名为"+x.getName());
}
int size = list.size();
for(Worker x:list) {
if(x.getNo()=="1003") {
list.remove(x);
System.out.println("成功删除员工信息");
break;
}
}
if(size==list.size()) System.out.println("未找到该员工信息");
Iterator<Worker> it = list.iterator();
while(it.hasNext()) {
Worker path = it.next();
System.out.println(path.toString());
}
}
}
class Worker{
private String no;
private String name;
private double salay;
public Worker(String no, String name ,double salay) {
this.no = no;
this.name = name;
this.salay = salay;
}
public String getNo() {
return this.no;
}
public String getName() {
return this.name;
}
public double getSalay() {
return this.salay;
}
public void setNo(String no) {
this.no = no;
}
public void setName(String name) {
this.name = name;
}
public void setSalay(double salay) {
this.salay = salay;
}
public String toString() {
return this.no+"号工人"+this.name+",每月工资为"+this.salay;
}
public boolean equals(Worker wok) {
if(wok.no==this.no && wok.name == this.name &&wok.salay==this.salay) {
return true;
}
else return false;
}
}
运行结果
2. 编写一个测试程序MapTest,要求在main方法中完成以下功能:
(1)根据上题的表格,创建3个工人对象。
(2)使用泛型<String, Worker>创建一个HashMap对象,并以工号作为键值加入之前创建的3个工人对象。
(3)从HashMap中查找并显示“1003”号工人的基本信息。
(4)删除“1002”号工人信息。删除前,先判断该键值是否存在,如果存在,则删除该元素,并输出“成功删除1002号工人信息!”;否则输出“不存在1002号工人的信息,删除失败!”
(5)统计并输出删除后的工人总人数。
(6)遍历元素,输出删除后各个工人的基本信息。
代码如下:
import java.util.*;
public class MapTest {
public static void main(String[] args) {
ArrayList<Worker> list = new ArrayList<Worker>();
list.add(new Worker("1001","张三",3000d));
list.add(new Worker("1003","李四",3500d));
list.add(new Worker("1004","王五",2500d));
list.add(1, new Worker("1002","赵六",3200d));
HashMap<String,Worker> wok = new HashMap<String , Worker>();
wok.put("1001", list.get(0));
wok.put("1002", list.get(1));
wok.put("1003", list.get(2));
wok.put("1004", list.get(3));
Set set = wok.entrySet();
int size = wok.size();
Iterator<Map.Entry> it = set.iterator();
while(it.hasNext()) {
Map.Entry res = it.next();
if(res.getKey()=="1003") {
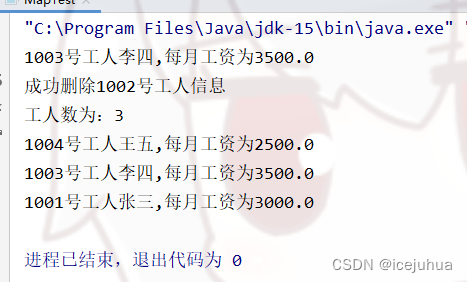
System.out.println(res.getValue().toString());
}
if(res.getKey()=="1002") {
wok.remove(res.getKey());
System.out.println("成功删除1002号工人信息");
break;
}
}
if(size == wok.size()) System.out.println("不存在1002号工人信息,删除失败!");
System.out.println("工人数为:"+(wok.size()));
it = set.iterator();
while(it.hasNext()){
Map.Entry res = it.next();
System.out.println(res.getValue().toString());
}
}
}
运行结果














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









