





Python小记---小飞有点东西
本文档收集于抖音博主 小飞有点东西有趣且有用的知识点
Python基础版
深浅拷贝
Python基础53集,54集
在列表的直接赋值后,改变拷贝的列表会同时改变原来列表的值,所以需要用到copy()函数,但这只是浅拷贝,假如原来的列表里面还嵌套一个列表(可变序列),则嵌套的列表仍然可以被该改变,如果不想改变,就需要使用深度拷贝。
list_1 = ["小明", "小张", ["张三", "李四"]]
list_2 = list_1
list_2[0] = "大明"
print(list_1) # ['大明', '小张', ['张三', '李四']]
print(list_2) # ['大明', '小张', ['张三', '李四']]
# list_1里面的内容也跟着改变了
# 但是我不想list_2的改变影响list_1,于是...浅拷贝
# 浅拷贝
# 先恢复list_1的小明身份,现在list_1的数据为: ["小明", "小张", ["张三", "李四"]]
list_1[0] = "小明"
list_3 = list_1.copy()
list_3[0] = "大明"
list_3[1] = "大张"
list_3[2][0] = "大张三"
list_3[2][1] = "大李四"
print(list_1) # ['小明', '小张', ['大张三', '大李四']]
print(list_3) # ['大明', '大张', ['大张三', '大李四']]
# 我们发现,list_3列表第一层的数据被我们改动了,并且没有影响原列表但是
# 我们发现list_1第二层列表依旧被改变了,因此这只是浅拷贝,其中缘由涉及到内存地址深拷贝
# 深拷贝
# 恢复list_1数据
list_1 = ["小明", "小张", ["张三", "李四"]] # 现在list_1的数据为: ["小明", "小张", ["张三", "李四"]]
import copy
list_4 = copy.deepcopy(list_1)
list_4[0] = "大明"
list_4[1] = "大张"
list_4[2][0] = "大张三"
list_4[2][1] = "大李四"
print(list_1) # ['小明', '小张', ['张三', '李四']]
print(list_4) # ['大明', '大张', ['大张三', '大李四']]
# 两个列表完全独立,不再有相互影响flush
Python基础158集
当我们在文件中只写入少量数据时,io机制并不会立即把数据写进去,就好比火车不会为了一个白菜跑一趟,所以可以利用flush告诉io机制,不要在等了!立即更新数据!
with open('hello.txt', mode='wt', encoding='utf-8') as f:
f.write('a') # 只写入少量数据
f.flush() # 别等了!给我更新数据
# 虽然flush很霸道,但是并不建议使用,因为他会破坏良好的io机制,他的使用场景只在测试阶段
# 来几个常用的函数
# f.readable() 判断文件是否可读
# f.writable() 判断文件是否可写
# f.closed 判断文件是否关闭
# f.econding 获取文件的编码方式
# f.name 获取文件名函数重中之重---形参妙用
Python基础195集
当我们拥有两个函数,且存在函数2调用函数1时,函数2的参数就受到函数1的限制,此时我们就可以利用*args和**kwargs
def fun1(x, y):
print("fun1--->", x, y)
def fun2(a, b):
fun1(a, b) # fun2的参数受限fun1,fun1有几个参数,fun2就必须一样,当我想增加fun1的参数,逼不得已也要改变fun2的参数
fun2(2, 3) # 调用fun2,返回结果: fun1--->2 3
# 为了解决fun1的扩展不会影响到fun2的使用,我们可以利用*args(位置形参)和**kwargs*(关键字形参)
def fun1(x, y, z):
print(x, y, z)
def fun2(*args, **kwargs): # 这种利用形式给我记死!现在这个args就等于一个元组(2,3,4)
fun1(*args, **kwargs) # 现在就相当于 fun1(2,3,4)
fun2(2, 3, 4)
# 此时的2,3,4都是位置实参,而fun2里面并没有定义任何的位置形参和默认形参,也就是说这里的2,3,4都是多出来的位置实参,而多出来的位置实参会被*号处理为元组,然后赋值为args,也就是现在这个args就等于一个元组(2,3,4),在调用fun1的时候,我们又传了一个*args,但此时的args是元组,元组遇到前面有个*号会被打散成位置实参,也就是说现在传入fun1里面的参数又是2,3,4,你就说妙不妙吧!关键字参数利用同理
fun2(2, 3, z=4)
# 同理,这里的2,3都是位置实参,关键字实参z=4,也就是说1,2都是多出来的位置实参,解释与上面相同,我们来说说关键字实参是怎么妙用的,z=4是多出来的关键字实参,它就会被**处理成字典{‘z’:4}然后赋值给kwargs,然后在调用的时候又遇到**就又会被打散成关键字实参z=4,这样传给fun2的实参就能做到原封不动的又传给fun1,所以以后不管fun1的参数怎么调整,都不需要调整fun2global和nonlocal
Python基础207集
global的作用是局部想要修改全局的名字对应的不可变类型的值
global
x = 10
def func():
x = 20
func()
print("x = ",x) # 此时打印的值还是 x = 10,也就是说函数内部里面的赋值影响不了外界
# 那我们应该怎么做? 利用global
x = 10
def func():
global x
x = 20
func()
print("x = ", x) # 打印结果为 x = 20nonlocal
nonlocal,非本地的意思,就是接下里不在本地创建新的名字,也不会去改全局的名字,改的是local上一层局部,也就是这个func1内的x = 20会被改成30
x = 10
def func1():
x = 20
def func2():
nonlocal x
x = 30
print("调用func2之前的 x = ", x)
func2()
print("调用func2之后的 x = ", x)
func1()
print("全局的 x = ",x)
# 需求,让func2里面的x是func1里面的x,即让这个x=20改成x=30利用nonlocal
# 输出结果:
# 调用func2之前的 x = 20
# 调用func2之后的 x = 30
# 全局的 x = 10来个好玩的
充电
def recharge(num):
for i in range(num, 101):
time.sleep(0.05)
print(f"\r当前电量:{i}%",end='')
print("\t电量已充满!")
recharge(20)
# \r的作用就是不停的刷新,使print一直跳到当前行的开头,end=‘’,避免了print自带的换行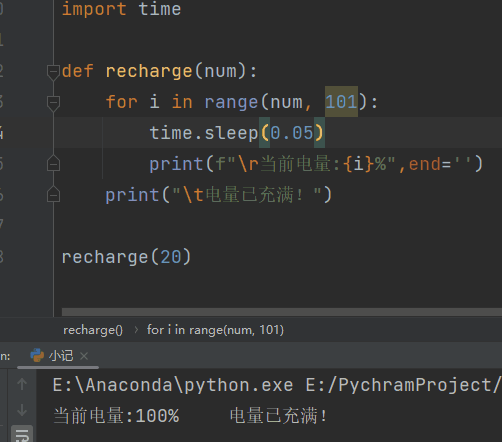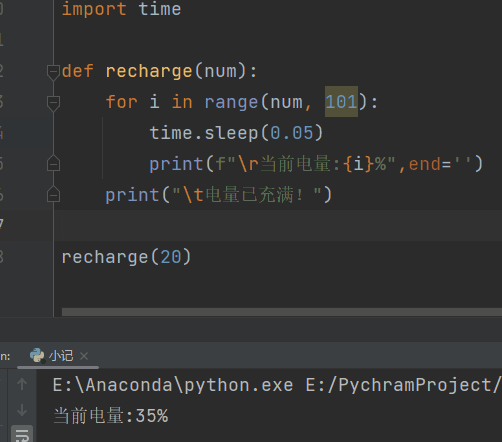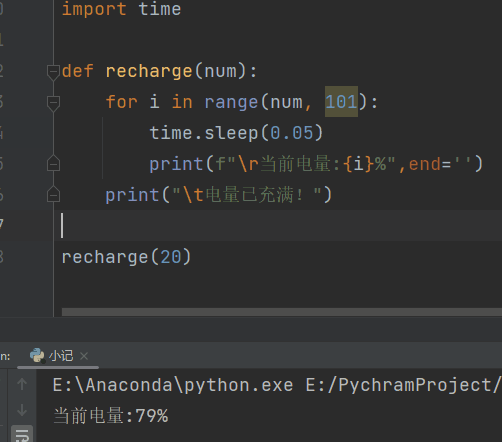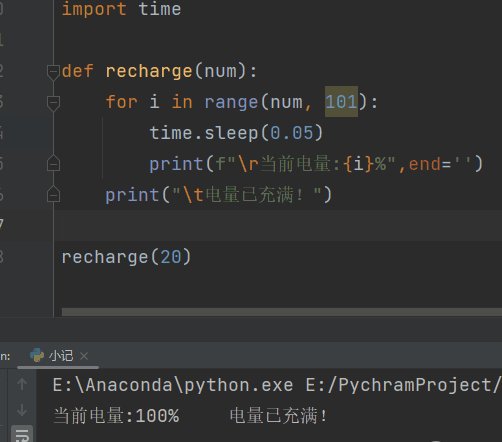
进度条
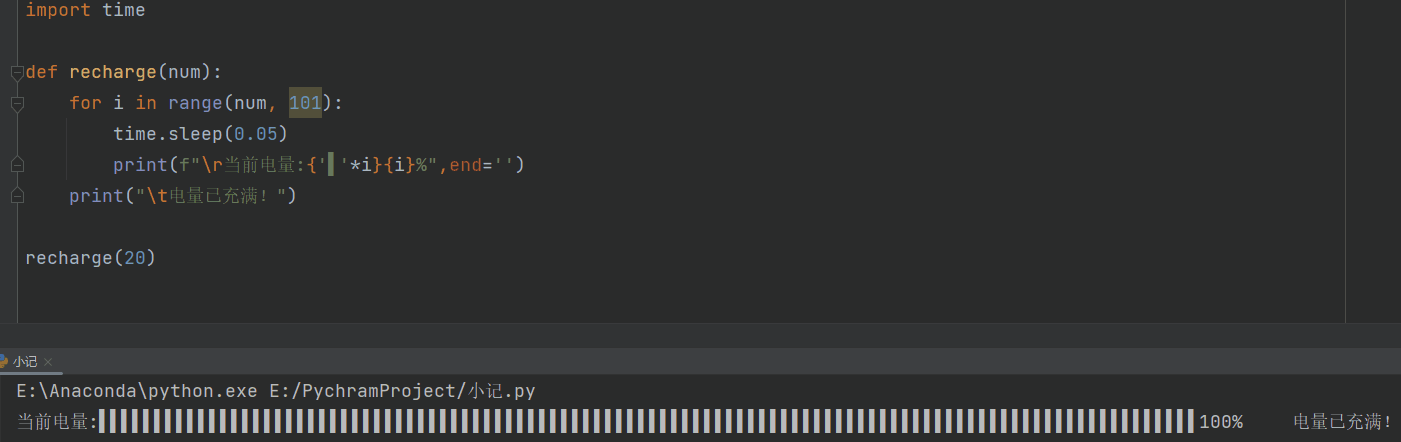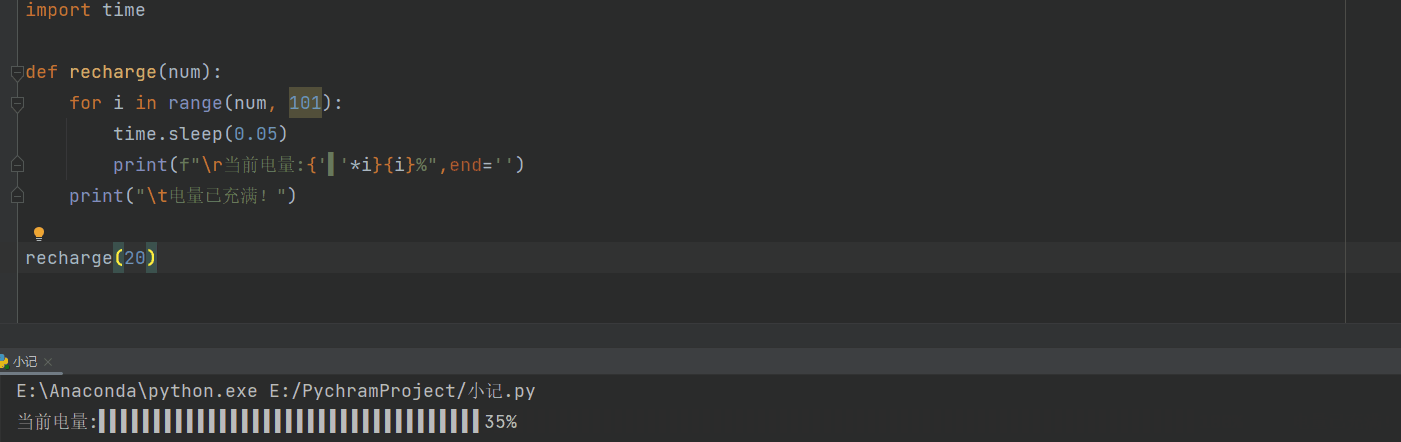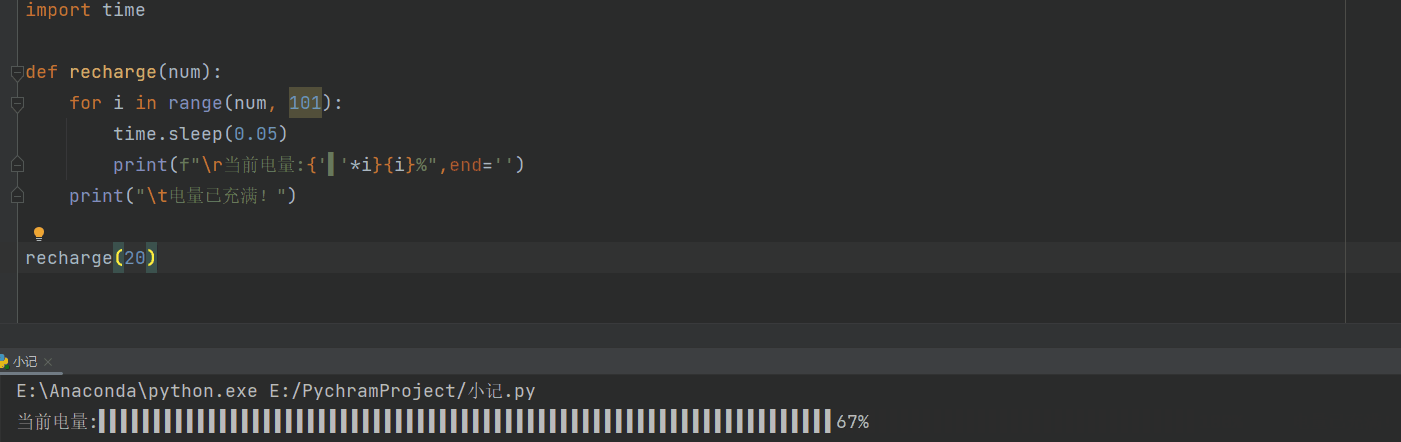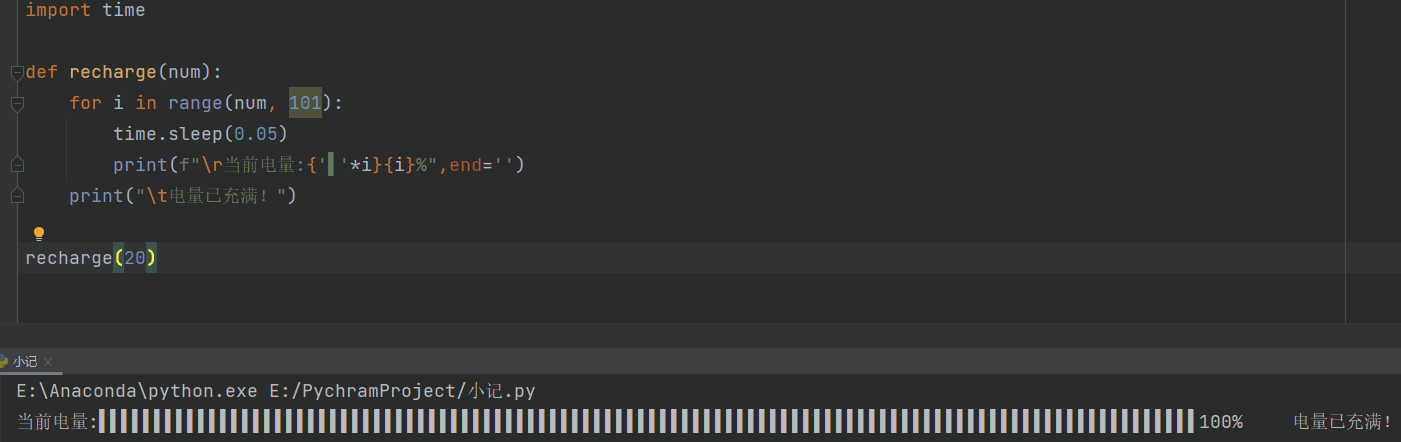
进度条2
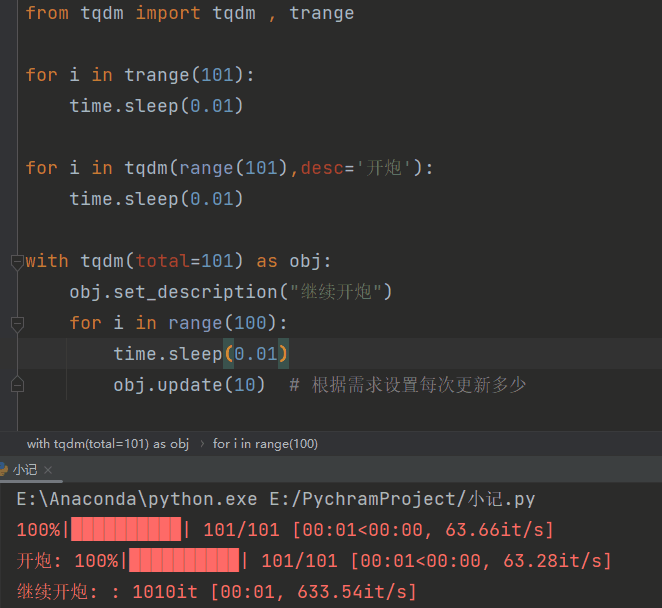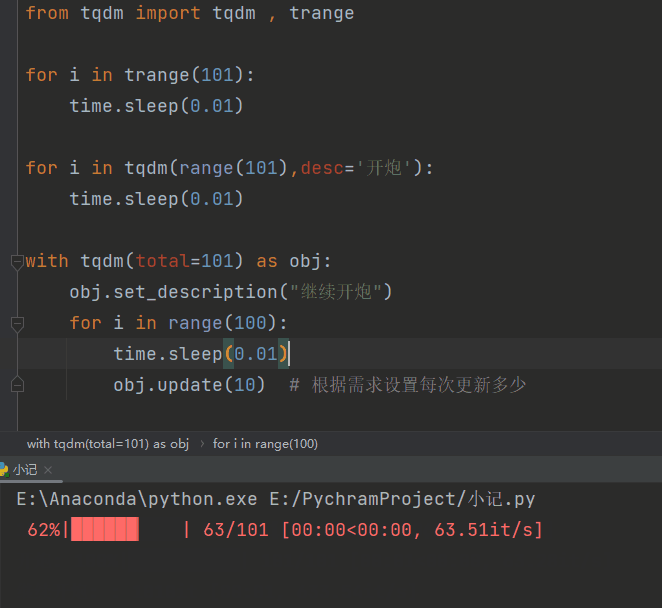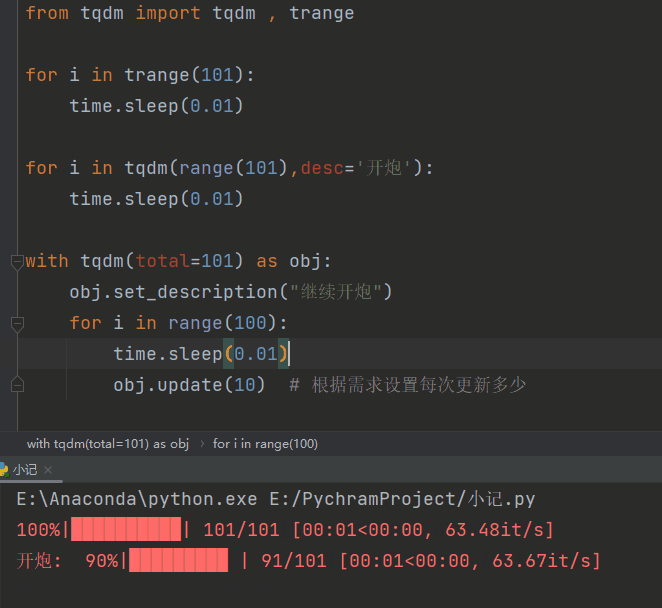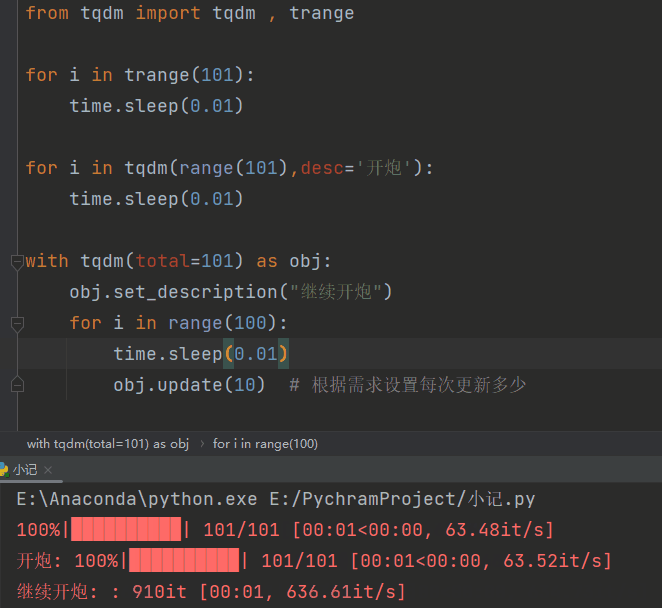
装饰器
Python基础227集
装饰器:不修改被装饰对象的源代码,也不修改调用方式的前提下,给被装饰对象添加新的功能。下面我们来写一个计算程序运行时间的装饰器
import time
def print_time(func):
def wrapper(*args,**kwargs):
start = time.time()
response = func(*args,**kwargs)
end = time.time()
print(f"程序耗时:{end-start}")
return response
return wrapper
@print_time
def recharge(num):
for i in range(num, 101):
time.sleep(0.05)
print(f"\r当前电量:{'▌'*i}{i}%",end='')
print("\t电量已充满!")
recharge(20)无参装饰器模板
Python基础231集
def outer(func): # 外包一个def是为了传递装饰对象func
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res # 返回被装饰对象的返回值
return wrapper # 为了让wrapper能被全局访问,因此返回
# 关于装饰器的完美伪装可以观看Python基础233集实时模板
Python基础232集
Pycharm:File -> Settings -> Edit -> Live Templates,选择**+,点击Live Templates**,在输入框abbreviation选择缩写词,即你输入什么内容可以调出模板,Description:对模板的描述,然后点击Define,将Python勾选,点击OK完成
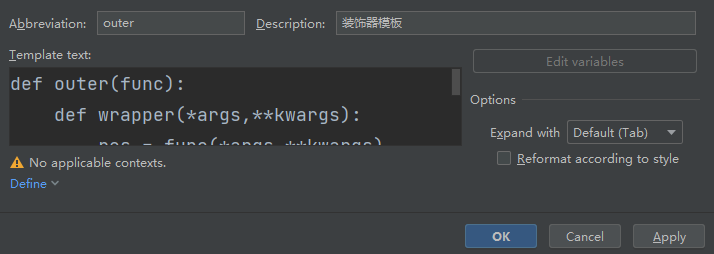
有参装饰器
有参装饰器模板
Python基础236集
def g_outer(x):
def outer(func):
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res
return wrapper
return outer有参装饰器应用
Python基础239集
# 装饰器的编写
def auth(source):
def outer(func):
def wrapper(*args,**kwargs):
name = input("请输入账号>>>").strip()
pwd = input("请输入密码>>>").strip()
if source == "file":
print("基于文件方式的登录验证")
if name == "jack" and pwd == "123":
res = func(*args,**kwargs)
return res
else:
print("账号或密码错误!")
elif source == "mysql":
print("基于mysql方式的登录验证")
if name == "jack" and pwd == "123":
res = func(*args, **kwargs)
return res
else:
print("账号或密码错误!")
else:
print("不支持该验证方式")
return wrapper
return outer
# 应用的开始
@auth("file")
def home():
print("welcome!")
@auth("mysql")
def index():
pass
@auth("ldap")
def default():
pass
home()
index()
default()
# 输出结果:
# 请输入账号>>>jack
# 请输入密码>>>123
# 基于文件方式的登录验证
# welcome!
# 请输入账号>>>jack
# 请输入密码>>>123
# 基于mysql方式的登录验证
# 请输入账号>>>jack
# 请输入密码>>>123
# 不支持该验证方式装饰器叠加
Python基础241集
# 装饰器叠加使用
def outer1(func):
def wrapper(*args,**kwargs):
print("开始执行outer1.wrapper")
res = func(*args, **kwargs)
print("outer1.wrapper执行完毕!")
return res
return wrapper
def outer2(x):
def outer(func):
def wrapper(*args, **kwargs):
print("开始执行outer2.wrapper")
res = func(*args, **kwargs)
print("outer2.wrapper执行完毕!")
return res
return wrapper
return outer
def outer3(func):
def wrapper(*args,**kwargs):
print("开始执行outer3.wrapper")
res = func(*args, **kwargs)
print("outer3.wrapper执行完毕!")
return res
return wrapper
# 这三个装饰器的执行顺序是由下至上,即1->2->3
@outer3 # home = outer3(home) # outer3.wrapper
@outer2(10) # outer = outer2(10) => @outer => home = outer(home) # outer2.wrapper # 现在这个outer2是有参装饰器,所以给了参数10
@outer1 # home = outer1(home) # outer1.wrapper
def home(z):
print("执行home功能 => ", z)
home(0)
# 执行结果:
# 开始执行outer3.wrapper
# 开始执行outer2.wrapper
# 开始执行outer1.wrapper
# 执行home功能 => 0
# outer1.wrapper执行完毕!
# outer2.wrapper执行完毕!
# outer3.wrapper执行完毕!
"""
现在我用文字来解释一下三个解释器后面的注释,我们从outer1后面的开始看,
@outer1这行代码的背后其实就是直接调用了outer1,然后把下面的函数内存
地址home传进去,即outer1(home),然后把返回值复制给home,即home=outer1(home),
这个返回值就是outer1内部的wrapper内存地址,也就是说这个home指向的是outer1内部
的wrapper内存地址,也就是我们备注的 outer1.wrapper,继续,执行@outer2,就会
立即调用outer2(),然后把下面的函数内存地址传进去,outer2下面的函数内存地址就是这
个home,也就是这个outer1.wrapper,把它传给outer2,然后得到的值又赋值给home,现在
这个home的值就变成了outer2内部的wrapper内存地址了,也就是我们备注的outer2.wrapper
继续往上走,执行@outer3,调用outer3,然后把下面的函数内存地址home,这个home就是
outer2.wrapper,然后把返回值复制给home,此时此刻,这个home就变成了outer3内部的wrapper了
"""yield浅讲
yield的功能
yield跟return有一点相识,yield也可以把函数暂停在yield处,并且返回一个值
当将yield赋值给一个值时
def func(x):
print(f'{x}开始执行')
while True:
y = yield None # 默认也为None
print("\n",x,y,"\n")
g = func(1)
print(g) # <generator object func at 0x00000204D428E580>
next(g) # 1开始执行
next(g) # 1 None
next(g) # 1 None
# 我们要清楚只要函数表达式里面出现了yield,我们再来调用函数就跟函数内部的代码没有关系了,
# 只有当我们调用__next__()方法的时候,才回去执行他内部的代码yied可以接受send的传值,并将他给一个变量
def func(x):
print(f'{x}开始执行')
while True:
y = yield None # 默认也为None
print("\n",x,y,"\n")
g = func(1)
g.send(None) # 相当于next(g)
g.send(10) # send给yield传值,yield又把值传给y
# 返回结果
# 1开始执行
#
# 1 10 三元表达式
Python基础255集
三元表达式:条件成立时返回的值 if 条件 else 条件不成立时返回的值
# 三元表达式:条件成立时返回的值 if 条件 else 条件不成立时返回的值
x = 6
y = 9
res = x if x>y else y
print(res) # 9列表生成式
Python基础256集
列表生成式:[ 结果 for item in 可迭代对象 (if 条件) ]
l = ["康师傅_牛肉面","统一_牛肉面","白象"]
# 需求把后缀为牛肉面的取出来
new_l = []
for name in l:
if name.endswith('牛肉面'):
new_l.append(name)
print(new_l) # ["康师傅_牛肉面","统一_牛肉面"]
# 利用列表生成式一行代码搞定
new_l = [name for name in l if name.endswith('牛肉面')]
print(new_l) # ["康师傅_牛肉面","统一_牛肉面"]字典生成式
Python基础258集
l = [("康师傅_牛肉面",5),("统一_牛肉面",6),("白象",7)]
res = {k,v for k,v in l if not k.startswith("康师傅")}
print(res) # {'统一_牛肉面':6,'白象':7}问题来了,列表,字典都有生成式,那元组也有咯?不!元组没有!因为元组本身就是不可变的!倒是有集合生成式,就是把列表的中括号换成大括号而已~
几个快捷键
竖着选中:alt + shift + 左键

某个词全选:左键选中某词 + alt + j(j多按一次多选中一个,然后可以进行更改)
函数参数的类型提示
Python基础278集
我们期望使用者在看到我们的参数时就知道我们的name应该传入str类型,age应该传入int类型,且知道返回值为int类型,我们就可以这样书写,age默认为8,值得一提的是这只是参数类型提示,即使你不按提示传参也不会报错
# 函数参数的类型提示
def func(name:str,age:int=8) -> int:
print(name,age)
return 10
func(666) # 666 8
func(666,[2,3,5]) # 666 [2, 3, 5]
func("小米") # 小米 8
func("小米",888) # 小米 888导入区别
Python基础285集
你是否会疑惑,为什么我们有时候导入模块是import xxx,有时候又是from xxx import yyy?
直接用import导入会在当前的名称空间里面产生一个名字,这个名字指向的是模块的名称空间,而用from这种方式产生的名字就不再是指向模块的名称空间了,而是直接指向模块的名称空间里面对应的功能的内存地址,用from导入后,我们再想在当前名称空间里面用xxx这个名字就用不到了,因为from这种方式不会在当前名称空间里面产生xxx这个名字,只会产生import后面跟的名字yyy,也就是说,我们用import导入时,想使用里面的功能,就必须‘xxx.yyy',而用from的当时就可以直接yyy调用。名称空间的查找关系是在定义阶段确定的
软件目录规范
Python基础301集
假设现在我们的项目名称为catalogue
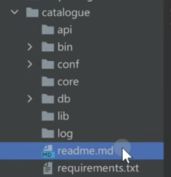
api: 存放接口文件
**bin: **放置程序的可执行文件,比如程序的启动文件run.py或者setup.py(这里面放置我们的安装、部署、打包的脚本)
**conf:**涉及到用户自定义的配置,里面一般有一个settings.py
core: 放置核心代码逻辑,核心代码的逻辑一般利用run.py调用
db: 对数据库相关操作的功能,比如对数据库的增删改查
lib: 放置程序中常用的模块,就是程序中很多地方都会用到的常用功能
log: 存放项目日志
README.md: 对软件的一个解释说明
requirements.txt: 只能是这个名,用来存放软件的外部依赖,例如一些第三模块以及版本
hash浅利用
Python基础341集
hash算法指的是一类算法,而不是一个算法它具有输入敏感,结果不可逆的特点,简单的hash算法是可以暴力破解的,因为hash的计算结果位数一样,但是我们输入结果千奇百怪,所以一定有一种输入方式得到和你一样的hash值。现在例如MD5和sha1已经被破解,所以你想要用的话至少从sha256开始。
import hashlib
h1 = hashlib.md5()
h1.update("abc".encode('utf-8'))
h1.update("123".encode('utf-8'))
res = h1.hexdigest() # abc123的计算结果
print(res) # e99a18c428cb38d5f260853678922e03
# 密码加盐(添加干扰)
import hashlib
h1 = hashlib.md5()
h1.update("这是我的密码加盐".encode('utf-8'))
h1.update("abc".encode('utf-8'))
h1.update("123".encode('utf-8'))
h1.update("我再加点盐加盐".encode('utf-8'))
res = h1.hexdigest() # 这样密码就是‘这是我的密码加盐abc123我再加点盐加盐’的计算结果
print(res) # ad35991b38f6e62a673c13aed7fa959a
import hashlib
# 切换成sha256计算结果明显变长
h1 = hashlib.sha256()
h1.update("abc".encode('utf-8'))
h1.update("123".encode('utf-8'))
res = h1.hexdigest() # abc123的计算结果
print(res) # 6ca13d52ca70c883e0f0bb101e425a89e8624de51db2d2392593af6a84118090文件完整性校验
Python基础345,346集
可以通过hash算法校验你下载的安装包是否被篡改过,主要思路就是读取你下载的安装包进行某种加密,然后比对该安装包官网的加密结果是否一致
Python进阶版
隐藏属性
Python进阶版21集
在面向对象的编程思想中,当我们在类里面想要隐藏某属性或者方法时可以在前面加上 __
class Test:
name = "小明"
def func(self):
print("我是方法func")
obj = Test() # 实例化对象
print(obj.name) # 小明
obj.func() # 我是方法func
##########隐藏属性##############
class Test:
__name = "小明"
def __func(self):
print("我是方法func")
obj = Test() # 实例化对象
# print(obj.name) # 'Test' object has no attribute 'name'
# obj.func() # 'Test' object has no attribute 'func'
print(Test.__dict__) # 发现他们的名字变成了’_Test__name‘和’_Test__func‘
print(obj._Test__name) # 小明
obj._Test__func() # 我是方法func
# 访问成功!可以看出其实这只是假隐藏,因为他的本质不过是给我们的方法和属性改了一个名字,但值得一提的是,这种隐藏属性对外不对内,内部函数可以用它,例如我们的func2函数就能调用内部里面的属性和方法。
class Test:
__name = "小明"
def __func(self):
print("我是方法func")
def func2(self):
print("我在调用__name:", self.__name)
print("我是func2,我将调用func", end='')
self.__func()
obj = Test() # 实例化对象
obj.func2()
# 输出结果:
# 我在调用__name: 小明
# 我是func2,我将调用func我是方法func为什么对外不对内,因为在类的定义阶段检查子代码语法的时候,类内部所有的__开头的名字都会统一改名,这就是说__name早就变成了_Test__name,函数func2访问的属性也是改名之后的,所以他可以访问。需要注意的是改名只在类的定义阶段,检查子代码语法的时候发生,我们在类的外面是做不到隐藏属性的,例如
Test.__y = 20
print(Test.__dict__) # __y属性的名字还是__y上面说的是基于类来做隐藏,基于对象来做隐藏一个道理
class Test:
def __init__(self, name, age):
self.__name = name
self.__age == age
obj = Test("小明",18) # 实例化对象
print(obj.name) # 'Test' object has no attribute 'name'
print(obj.__age) # 'Test' object has no attribute '__age'为何隐藏属性?
Python进阶23集
作为类的设计者,我们设计的属性务必是要给使用者使用的,但是为啥要隐藏?是为了规范使用者的使用!比我我们原先有这个类
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age当我们隐藏起自己的属性后还想给使用者用的话,就需要给这两个属性单独开接口,让使用者通过接口来使用这两个属性,于是我们的函数就变成这样了
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self):
return self.__name
def get_age(self):
return self.__age
obj = Test("小明", 18) # 实例化对象
print(obj.get_name()) # '小明' 使用者就通过这个接口调用到了我们的属性
print(obj.get_age()) # 18 我们这么做有什么意义呢?意义重大!一旦我们把这两个属性隐藏起来后,使用者就不能随意改我们的属性了,他要是想改我们的属性又必须通过我们的接口,那在我给接口,那我不得管管你,所以我们的代码就变成了这样
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self):
return self.__name
def get_age(self):
return self.__age
def set_age(self,new_age):
if type(new_age) is not int:
print("傻呗,年龄必须是整型!")
else:
self.__age = new_age那我们为什么又要隐藏函数呢,是为了让使用者简单,比如使用者只是想买一个包子,他就只需要调用buy这个函数,不需要看到那些繁琐的小步骤~
class Test:
def __pay(self):
print("给钱")
def __take(self):
print("拿包子")
def __run(self):
print("回家")
def __ok(self):
print("开吃")
def buy(self):
self.__pay()
self.__take()
self.__run()
self.__ok()
obj = Test()
obj.buy()
# 输出结果:
# 给钱
# 拿包子
# 回家
# 开吃在java上是不是有新的理解啊~哈哈哈哈
property
Python进阶26集
上面讲到了使用者想修改属性的就必须要调用我们的接口,比如这样,obj.get_age(),但是这很不方便,他们想得到一个属性明明只需要obj.age,那可咋办。property闪亮登场!
property:把绑定给对象的方法伪装成一个数据属性
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self):
return self.__name
@property
def age(self):
return self.__age
@age.setter
def age(self, new_age):
if type(new_age) is not int:
print("傻呗,年龄必须是整型!")
else:
self.__age = new_age
@age.deleter
def age(self):
del self.age
obj = Test("小明", 18)
print(obj.age) # 18
obj.age = 20 # 修改
print(obj.age) # 20 单继承查找
Python进阶35集
class Test1:
def f1(self):
print("Test1.f1")
def f2(self):
print("Test1.f2")
self.f1()
class Test2(Test1):
def f1(self):
print("Test2.f1")
obj = Test2()
obj.f2()
# 输出结果:
# Test1.f2
# Test2.f1输出结果竟然是Test1.f2和Test2.f1,为什么不是Test1.f2和Test1.f1? 我们来看看类f2函数里面的self.f1()的self到底是谁,对象在调用绑定方法的时候,哪个对象调用的绑定方法,就会把那个对象作为第一个参数传进去,现在我们用的是obj调用的绑定方法即便是这个绑定方法不在类Test2里面,他在其父类里面也是一样的,obj调用的f2,那就会把obj作为第一个参数传进去所以这个f2里面的self其实就是我们的对象obj,也就说self.f1()同样是通过obj在调用f1,那查找顺序还是,先在自己哪里找,自己没有才会去父类找,可是我们这里类Test2里面有f1,因此才有上面的输出结果。
那我就想在self.f1()的时候访问的就是类Test1里面的f1怎么做呢?那就是将self.f1()变成Test1.f1()或者利用隐藏方法变成self.__f1(),但是Test1里面的f1()方法也要变成__f()。此时即使在Test2里面的f1方法变成__f1也不会有影响(因为隐藏属性和方法会重新命名为_类名__属性或方法名)
想要知道某个类的继承查找顺序可以通过打印其MRO列表:print(类名.mro())
super注意点
Python进阶46集
super找属性的时候不是直接去父类找,而是要参照对象所属类的mro列表而且还不是从mro列表的第一个类开始找,而是从mro列表里的super所处类的下一个类开始找
class A:
def f1(self):
print("A.f1")
super().f1()
class B:
def f1(self):
print("B.f1")
class C(A, B):
pass
obj = C()
obj.f1()
print(C.mro())
# 输出结果:
# A.f1
# B.f1
# [<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
类方法--@classmethod
Python进阶53集
类方法的作用就是把类传进去,通过类能干的事情,其实也就是实例化对象,所以类方法的应用场景还是比较窄的,但是比较吊,通过它我们拥有了一种新的造对象的方式。建议观看视频理解。
静态方法--@staticmethod
Python进阶54集
静态方法的意思就是对象和类都可以调用它,而且也没有自动传参的效果了,他就是一个普通函数了
class B:
@staticmethod
def f1():
print("B.f1")反射机制
Python进阶55集
**动态语言:**在执行代码赋值的时候才识别他的数据类型
**静态语言:**在定义变量的时候就要指定他的数据类型
**反射机制:**在程序运行过程中,(让程序自己能)动态获取对象信息以及动态调用对象方法的功能
几个内置方法
dir(): 该方法可以查看到一个对象下面可以点出来那些属性dir(obj)
hasatter: 判断这个对象是否有某一个属性hasatter(obj,'name')
getatter: 获取某一个属性getatter(obj,'name')
setatter: 给某一个属性赋值setatter(obj,'name','李白')
delatter: 删除某一属性delatter(obj,'name')
这四个内置函数就是通过字符串的形式来操作对象的属性的
class Ftp:
def put(self):
print("上传文件")
def get(self):
print("下载文件")
def interact(self):
opt = input("请输入:")
if hasattr(self, opt): # 判断有没有opt这个属性
getattr(self, opt)() # 如果有就利用getattr()获取这个属性然后加()调用
else:
print("功能不存在")
obj = Ftp()
obj.interact()
# 输出结果:
# 请输入:xxx
# 功能不存在
# 请输入:get
# 下载文件
#######修改版#########
class Ftp:
def put(self):
print("上传文件")
def get(self):
print("下载文件")
def interact(self):
opt = input("请输入:")
getattr(self, opt, self.warning)() # 如果有就利用getattr()获取这个属性然后加()调用
def warning(self):
print("功能不存在!")
obj = Ftp()
obj.interact()
# 输出结果:
# 请输入:xxx
# 功能不存在
# 请输入:get
# 下载文件__str__:相当于java的toString(),可自定义输出内容
class Test:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"{self.name}:{self.age}"
obj = Test("小明", 18)
print(obj) # 小明:18__del__:在删除对象的时候先执行它,__del__并不是在定义完类之后的时候执行,也不是在实例化对象之后执行,而是在程序的最后一行代码执行完之后执行。
元类
Python基础62集
我们知道关键字class能定义类,那实例化产生类的类就是叫做元类,即元类 --> 实例化 --> 类(Test) --> 实例化 --> 对象(obj),用class这个关键字定义的所有类以及内置的类都是由内置的元素type实例化产生
# 定义了一个类
class Test:
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(f"{self.name}:{self.age}")
# 基于类创建了一个对象
obj = Test("小明", 18)
print(type(obj)) # <class '__main__.Test'>
print(type(Test)) # <class 'type'> 元类
print(type(str)) # <class 'type'> 内置的类也是元类class分析
class关键字是怎么创造类的呢,经历了四步
# 1.类名
class_name = "Test"
# 2.基类
class_bases = (object,)
# 3.执行类子代码,产生名称空间
class_dic = {}
class_body = """
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(f"{self.name}:{self.age}")
"""
exec(class_body, {}, class_dic)
# 4.调用元类
Test = type(class_name, class_bases, class_dic)
print(Test) # <class '__main__.Test'> 这就是我们的类
obj = Test("小明", 18) # 实例化我们的类
obj.info() # 小明:18 成功打印那元类又是怎么做到的呢?
自定义元类
Python进阶65集
Test = Mytype(class_name, class_bases, class_dic)
调用Mytype的__new__方法,产生一个空对象Test
调用Mytype的init方法,初始化Test
返回初始化好的对象Test
# 自定义元类:只有继承了type的类才是元类,所以我们要自定义元类
# 必须让他继承type
# 自定义需求,类名不能有下划线
class Mytype(type):
def __init__(self, class_name, class_bases, class_dic):
if '_' in class_name:
raise NameError("类名不能有下划线!")
if not class_dic.get("__doc__"):
raise SyntaxError("定义类必须写文档注释!")
# metaclass:指定调用的元类
class Test(Object, metaclass=Mytype): # 我们调用的是自定义元类,如果我们的Test命名含有下划线就将报错
"""
这是文档注释
"""
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(f"{self.name}:{self.age}")
__new__
详情见Python进阶67集
class Mytype(type):
def __init__(self, class_name, class_bases, class_dic):
if '_' in class_name:
raise NameError("类名不能有下划线!")
if not class_dic.get("__doc__"):
raise SyntaxError("定义类必须写文档注释!")
def __new__(cls, *args, **kwargs):
# 在这里做一些定制化操作,然后返回
return super().__new__(cls, *args, **kwargs)__call__
详情Python进阶69集
如果想把一个对象做成一个可以加括号调用的对象,就在它的类里面加一个__call__方法。
对象() --> 类内部的__call__
类() --> 自定义元类内部的__call__
自定义元类() --> 内置元类的__call__
触发Mytype的__call__方法:
调用Test的__new__方法
调用Test的__init__方法
返回初始化好的对象
class Mytype(type):
def __call__(self, *args, **kwargs):
Test_obj = self.__new__(self)
self.__init__(Test_obj, *args, **kwargs)
# 这里可以定制化操作
return Test_obj
# metaclass:指定调用的元类
class Test(metaclass=Mytype): # 我们调用的是自定义元类,如果我们的Test命名含有下划线就将报错
"""
这是文档注释
"""
def __init__(self, name, age):
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
obj = object.__new__(cls)
# 这里可以做定制化的操作
return obj
def info(self):
print(f"{self.name}:{self.age}")
obj = Test("小明", 18)
print(obj.__dict__) # {'name': '小明', 'age': 18}属性查找
Python进阶75集
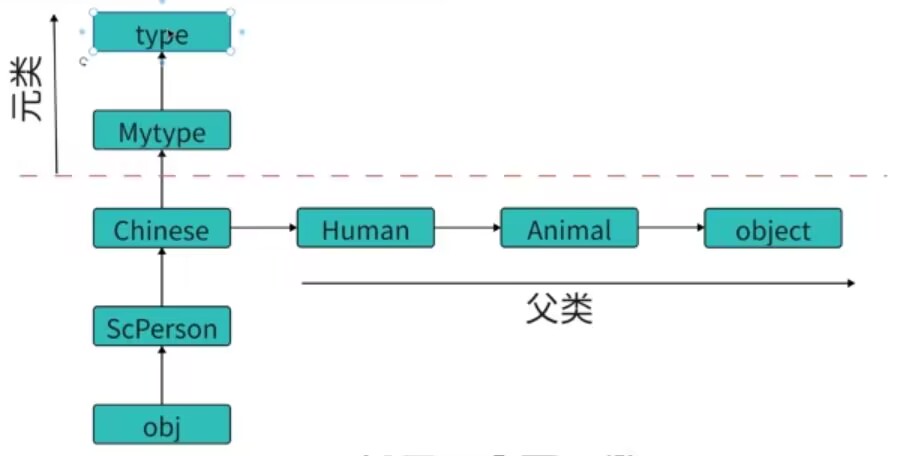
在这样的继承关系下,属性的查找顺序是什么呢?
obj = ScPerson()
假如查找age属性,通过对象查找属性(即obj.age)的顺序就是先找自己,自己没有找类,类没有找父类,最后object还没有的话就报错,不会涉及到元类
通过类找属性(即ScPerson.age)的时候会先顺着父类的路线找,然后去object里面找,还是没有就会去元类找。
单例模式
Python进阶77集
特点:只允许内存中有一个实例,实现方式有六种
模块
# 新建settings.py,里面存放以下内容
class Test:
def __init__(self,name,age):
self.name = name
self.age = age
obj = Test("小明", 18)
# 使用时直接 from settings import obj类装饰器
def singleton_mode(cls):
obj = None
def wrapper(*args, **kwargs):
nonlocal obj
if not obj:
obj = cls(*args, **kwargs)
return obj
return wrapper
@singleton_mode # Test = singleton_mode(Test)
class Test:
def __init__(self ,name ,age):
self.name = name
self.age = age
obj = Test("小明", 18)
obj2 = Test("大明", 28)
print(obj) # <__main__.Test object at 0x000002B1C59634F0>
print(obj2) # <__main__.Test object at 0x000002B1C59634F0>
# 内存地址输出一样,说明是同一个对象类绑定方法
class Test:
obj = None
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def get_obj(cls, *args, **kwargs):
if not cls.obj:
cls.obj = cls(*args, **kwargs)
return cls.obj
obj = Test.get_obj("小明", 18)
obj2 = Test.get_obj("大明", 28)
print(obj) # <__main__.Test object at 0x000002B1C59634F0>
print(obj2) # <__main__.Test object at 0x000002B1C59634F0>
# 内存地址输出一样,说明是同一个对象__new__方法
class Test:
obj = None
def __init__(self, name, age):
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
if not cls.obj:
cls.obj = super().__new__(cls)
return cls.obj
obj = Test("小明", 18)
obj2 = Test("大明", 28)
print(obj) # <__main__.Test object at 0x000002B1C59634F0>
print(obj2) # <__main__.Test object at 0x000002B1C59634F0>
# 内存地址输出一样,说明是同一个对象元类
class Mytype(type):
obj = None
def __call__(self, *args, **kwargs):
if not self.obj:
self.obj = super().__call__(*args, **kwargs)
return self.obj
class Test(metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
obj = Test("小明", 18)
obj2 = Test("大明", 28)
print(obj) # <__main__.Test object at 0x000002B1C59634F0>
print(obj2) # <__main__.Test object at 0x000002B1C59634F0>
# 内存地址输出一样,说明是同一个对象并发(敬请期待)
Python高阶版
进程
创建进程
Python高阶85集
方式一
from multiprocessing import Process
import time
def func(name):
print(f"{name}任务开始")
time.sleep(2)
print(f"{name}任务结束")
if __name__ == '__main__':
# 1.得到进程操作对象
# target:指定把谁作为一个进程来创建或者说提交什么任务给子进程来执行
# args:传一个元组
p = Process(target=func, args=("hello wrold",))
# 2.创建子进程
p.start()
print("主进程")
# 输出结果:
# 主进程
# hello wrold任务开始
# hello wrold任务结束(2秒之后输出)方式二
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super().__init__()
self.task_name = name
def run(self): # 方法名只能为run
print(f"{self.task_name}任务开始")
time.sleep(2)
print(f"{self.task_name}任务结束")
if __name__ == '__main__':
p = MyProcess("约会")
p.start()
print("主进程")
# 输出结果:
# 主进程
# 约会任务开始
# 约会任务结束(2秒之后输出)**总结:**创建进程就是在内存中申请一块内存空间,然后把需要运行的代码放进去,多个进程的内存空间他们彼此是隔离的,进程与进程之间的数据是没有办法直接交互的,如果想要交互需要借助第三方工具/模块。
join()
Python高阶88集
**join():**让主进程等待子进程运行结束之后再继续执行
from multiprocessing import Process
import time
def func(name, n):
print(f"{name}任务开始")
time.sleep(n)
print(f"{name}任务结束")
if __name__ == '__main__':
start = time.time()
l = []
for i in range(1, 4):
p = Process(target=func, args=(f"hello wrold{i}",i))
p.start()
l.append(p)
for p in l:
p.join()
print("主进程")
end = time.time()
print(end-start)
# 输出结果:
# hello wrold2任务开始
# hello wrold1任务开始
# hello wrold3任务开始
# hello wrold1任务结束
# hello wrold2任务结束
# hello wrold3任务结束
# 主进程
# 3.299180507659912进程号
Python高阶91集
**current_process().pid:**获取当前进程号
from multiprocessing import Process,current_process
import time
def task():
print(f"{current_process().pid}任务执行中")
if __name__ == '__main__':
p = Process(target=task)
print("主进程")
# 输出结果:
# 2116任务执行中
# 主进程os模块中也有获取进程(和父进程)的方法
import os
from multiprocessing import Process,current_process
import time
def task(name='子进程'):
# print(f"{current_process().pid}任务执行中")
print(f"{name}{os.getpid()}执行中")
print(f"{name}的父进程{os.getppid()}执行中")
if __name__ == '__main__':
p = Process(target=task)
p.start()
print("主进程")
# 输出结果:
# 子进程672执行中
# 子进程的父进程14896执行中(pycharm运行的进程)
# 主进程terminate() 杀死当前进程
is_alive()判断进程是否存在
守护进程
Python高阶94集
守护进程:随着操作系统启动而启动,关闭而关闭的就成为守护进程,实现代码p.daemon = True
from multiprocessing import Process
import time
def task(name):
print(f"{name}还活着")
time.sleep(3)
print(f"{name}正常死亡")
if __name__ == '__main__':
p = Process(target=task, args=("妲己",))
p.daemon = True
p.start()
time.sleep(1)
print("纣王驾崩")
# 输出结果:
# 妲己还活着
# 纣王驾崩
# 刚开始妲己还活着,一秒之后,纣王死了,妲己直接俄就死了,输出”妲己正常死亡“的机会都没有互斥锁
Python高阶95集
当多个文件操作同一份数据的时候会出现数据错乱的问题,解决方法就是加锁处理:把并发变成串行,虽然牺牲了运行效率,但是保证了数据安全
注意:不要轻易加锁,加锁只应该在争抢数据的环节
tickets文件内容
{"tick_num": 0}未加锁,我们只有两张票,可是五个人都买票成功?这不科学!
import json
import random
from multiprocessing import Process, Lock
import time
def search_ticket(name):
with open("tickets", 'r', encoding='utf-8') as f:
dic = json.load(f)
print(f"用户{name}查询余票:{dic.get('tick_num')}")
def buy_ticket(name):
with open("tickets", 'r', encoding='utf-8') as f:
dic = json.load(f)
# 模拟网络延迟
time.sleep(random.uniform(0.1, 1))
if dic.get('tick_num') > 0:
dic["tick_num"] -= 1
with open("tickets", 'w', encoding='utf-8') as f:
json.dump(dic, f)
print(f"用户{name}买票成功")
else:
print(f"余票不足,用户{name}买票失败")
def task(name):
search_ticket(name)
buy_ticket(name)
if __name__ == '__main__':
for i in range(1, 6):
p = Process(target=task, args=(i,))
p.start()
# 输出结果:
# 用户2查询余票:2
# 用户1查询余票:2
# 用户3查询余票:2
# 用户4查询余票:2
# 用户5查询余票:2
# 用户3买票成功
# 用户1买票成功
# 用户2买票成功
# 用户5买票成功
# 用户4买票成功加锁后
import json
import random
from multiprocessing import Process, Lock
import time
def search_ticket(name):
with open("tickets", 'r', encoding='utf-8') as f:
dic = json.load(f)
print(f"用户{name}查询余票:{dic.get('tick_num')}")
def buy_ticket(name):
with open("tickets", 'r', encoding='utf-8') as f:
dic = json.load(f)
# 模拟网络延迟
time.sleep(random.uniform(0.1, 1))
if dic.get('tick_num') > 0:
dic["tick_num"] -= 1
with open("tickets", 'w', encoding='utf-8') as f:
json.dump(dic, f)
print(f"用户{name}买票成功")
else:
print(f"余票不足,用户{name}买票失败")
def task(name, mutex):
search_ticket(name)
mutex.acquire() # 抢锁
buy_ticket(name)
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock()
for i in range(1, 6):
p = Process(target=task, args=(i, mutex))
p.start()
# 输出结果:
# 用户1查询余票:2
# 用户2查询余票:2
# 用户4查询余票:2
# 用户3查询余票:2
# 用户5查询余票:2
# 用户1买票成功
# 用户2买票成功
# 余票不足,用户4买票失败
# 余票不足,用户3买票失败
# 余票不足,用户5买票失败死锁
Python高阶124集
from threading import Thread,current_thread,Lock
import time
mutex1 = Lock()
mutex2 = Lock()
def task():
mutex1.acquire()
print(current_thread().name,"抢到锁1")
mutex2.acquire() # 还未释放锁1就开始抢锁2
print(current_thread().name,"抢到锁2")
mutex2.release() # 先释放锁2,再释放锁1
mutex1.release()
mutex2.acquire()
print(current_thread().name, "抢到锁2")
time.sleep(1)
mutex1.acquire() # 还未释放锁2就开始抢锁1
print(current_thread().name, "抢到锁1")
mutex1.release() # 先释放锁1,再释放锁2
mutex2.release()
if __name__ == '__main__':
for i in range(5):
t = Thread(target=task)
t.start()
# 输出结果:
# Thread-1 抢到锁1
# Thread-1 抢到锁2
# Thread-1 抢到锁2
# Thread-2 抢到锁1
# 程序阻塞了消息队列
Python高阶99集
**消息队列:**实现进程之间的数据通信,很多人可以往里面存,也可以往里面取。存取规则也是先进先出,拿一个数据少一个数据
from multiprocessing import Queue
q = Queue()
q.put('a')
q.put('b')
q.put('c')
q.put('d')
v = q.get() # a ,哪怕你写了q.get('b')得到的还是a
print(v)
# 多进程的情况下可能不够准确
q.full() # 判断队列是否满了
q.empty() # 判断队列是否为空
q.put_nowait() # 当队列满了的时候,再存数据,他会等有空位再存进去,写了该函数,不等待,直接报错
q.get_nowait() # 同理进程间的通信(IPC机制)
Python高阶102集
from multiprocessing import Process,Queue
def task1(q):
q.put("水煮鱼")
def task2(q):
print(q.get())
if __name__ == '__main__':
q = Queue()
p1 = Process(target=task1,args=(q,))
p2 = Process(target=task2,args=(q,))
p1.start()
p2.start()
# 输出结果:
# 水煮鱼
# 第二个进程拿到了第一个进程的数据生产者消费者模型
Python高阶103集
from multiprocessing import Process,Queue,JoinableQueue
import time
import random
"""
JoinableQueue
在Queue的基础上增加了一个计数器机制,每put一个数据,计数器+1
每调用一次task_done()计数器-1
直到计数器为0的时候会走q.join()后面的代码
"""
def producer(name,food,q):
for i in range(1, 6):
time.sleep(random.uniform(0.1,1)) # 模拟做菜时间
print(f"{name}生产了{food}{i}")
q.put(f"{food}{i}")
def consumer(name,q):
while True:
food = q.get() # 当生产者做完了食物,get方法还不知道,会一直等待,就会造成阻塞
time.sleep(random.uniform(0.1,1)) # 模拟吃菜时间
print(f"---{name}吃了{food}")
q.task_done() # 这就是解决阻塞的办法,告诉队列,已经拿走了一个数据,并且已经处理完了
if __name__ == '__main__':
# q = Queue()
q = JoinableQueue() # 我们替换了使用Queue是为了解决消息阻塞
p1 = Process(target=producer,args=("中华小当家","黄金炒饭",q))
p2 = Process(target=producer,args=("神厨小福贵","宫爆鸡丁",q))
c1 = Process(target=consumer,args=("八戒",q))
p1.start()
p2.start()
c1.daemon = True # 开始守护进程
c1.start()
p1.join() # join():让主进程等待子进程运行结束之后再继续执行
p2.join() # 所以保留这两行代码是为了不让消费者吃太快,
# 提前让队列计数器为0,从而走q.join()
q.join() # 等待队列中的所有数据被取完
# 主进程死了,消费者也要跟着陪葬,所以要在上方开启守护进程
# 输出结果:
# 中华小当家生产了黄金炒饭1
# ---八戒吃了黄金炒饭1
# 神厨小福贵生产了宫爆鸡丁1
# 中华小当家生产了黄金炒饭2
# 神厨小福贵生产了宫爆鸡丁2
# ---八戒吃了宫爆鸡丁1
# 中华小当家生产了黄金炒饭3
# 神厨小福贵生产了宫爆鸡丁3
# ---八戒吃了黄金炒饭2
# 中华小当家生产了黄金炒饭4
# 神厨小福贵生产了宫爆鸡丁4
# ---八戒吃了宫爆鸡丁2
# 中华小当家生产了黄金炒饭5
# 神厨小福贵生产了宫爆鸡丁5
# ---八戒吃了黄金炒饭3
# ---八戒吃了宫爆鸡丁3
# ---八戒吃了黄金炒饭4
# ---八戒吃了宫爆鸡丁4
# ---八戒吃了黄金炒饭5
# ---八戒吃了宫爆鸡丁5
#
# Process finished with exit code 0
# 不再有阻塞思考爬虫和该模型的关系?
爬取代码的操作 --> 生产者
处理数据的操作 --> 消费者
线程
进程:资源单位
线程:执行单位
线程的使用方法和进程基本一致(鸭子模型)
创建进程:
申请内存空间,消耗资源
拷贝代码,消耗资源
创建线程:在一个进程里面可以创建多个线程,多个线程之间的数据是共享的
不需要再次申请内存空间
不需要拷贝代码
创建线程
方式一
from threading import Thread
import time
def task(name):
print(f"{name}任务开始")
time.sleep(1)
print(f"{name}任务结束")
if __name__ == '__main__':
t = Thread(target=task,args=("悟空",))
t.start()
print("主线程")
# 输出结果:
# 悟空任务开始
# 主线程
# 悟空任务结束我们看到主进程是在悟空任务开始之后输出,而创建进程是先输出主进程,这说明创建线程代码不需要拷贝一份,速度比进程快了些
方式二
from threading import Thread
import time
class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(f"{self.name}任务开始")
time.sleep(1)
print(f"{self.name}任务结束")
if __name__ == '__main__':
t = MyThread("悟空")
t.start()
print("主线程")
# 输出结果:
# 悟空任务开始
# 主线程
# 悟空任务结束TCP并发
Python高阶110集
tcp服务端:
import socket
from multiprocessing import Process
from threading import Thread
s = socket.socket()
s.bind(('127.0.0.1', 8003))
s.listen(5)
def task(conn):
# 通信循环
while True:
try:
data = conn.recv(1024)
except:
break
if not data:
break
print(data.decode('utf-8'))
conn.send(data.upper())
conn.close()
if __name__ == '__main__':
while True:
conn, addr = s.accept()
# p = Process(target=task, args=(conn,))
p = Thread(target=task, args=(conn,))
p.start()tcp客户端:
import socket
import time
c = socket.socket()
c.connect(('127.0.0.1', 8003))
while True:
c.send(b'hello') # 把hello转成二进制,不能有中文
data = c.recv(1024)
print(data.decode('utf-8'))
time.sleep(2)这样,在启动服务端之后,就可以多次启动客户端了,实现tcp并发
join()方法和锁的使用办法与进程那边一样使用
守护线程:主线程执行完毕之后,他不会立即结束,要等待所有子线程运行完毕后才会结束,因为主线程结束,就意味着主线程所在的进程结束,其他子线程获取不到资源了
GIL全局解释器锁
python解释器版本:
Cpython (C语言写的python)
Jpython
Pypython
在Cpython解释器中,GIL是一把互斥锁,用来阻止同一个进程下的多个线程同时执行,有多个cpu都不能并行,一次只有一个cpu来执行。
GIL不是python的特点,而是Cpython解释器的独有特点
GIL会导致同一个进程下的多个线程不能同时执行,无法利用多核能力
GIL保证的是解释器级别的数据安全
多线程VS多进程
单核
10个任务(计算密集型/io密集型)
多核
10个任务(计算密集型/io密集型)
单核不考虑
多核(cpu10个核)
计算密集型 每一个任务都需要10s
多线程 100+
多进程 10+
io密集型
多线程 节省资源
多进程 浪费资源
如有侵权,联系删除。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









