




04.数据操作(与课程对应)
1、导入torch
import torch
2、使用 arange 创建一个行向量 x,包含以 0 开始的前 12 个整数,默认创建为浮点数
x = torch.arange(12) # 0到11所有的数拿出来(步长默认1);左闭右开区间
y = torch.arange(start=1, end=20, step=2)
运行结果:

3、通过张量的 shape 属性来访问张量(沿每个轴的长度)的形状
print("x.shape:", x.shape)
运行结果:

4、通过 numel 访问张量中元素的总数
print("x.numel():", x.numel())
运行结果:

5、改变一个张量的形状而不改变元素数量和元素值,可以调用 reshape 函数
X = x.reshape(3, 4)
print("X:", X)
运行结果:

6、使用全0、全1、其他常量或者从特定分布中随机采样的数字
(1)全0
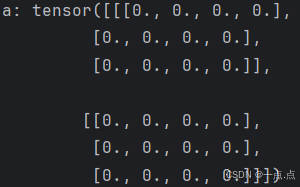
a = torch.zeros((2, 3, 4)) # 元素全0
print("a:", a)
运行结果:
(2)全1
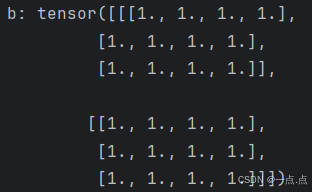
b = torch.ones((2,3,4)) # 元素全1
print("b:", b)
运行结果:
(3)常量
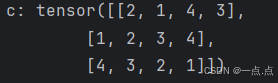
c = torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]]) # 通过提供包含数值的python列表(或嵌套列表)来为所需张量中的每个元素赋予确定值
print("c:", c)
运行结果:
7、常见的标准算术运算符(+、-、*、/ 和 **)都可以被升级为 按元素运算
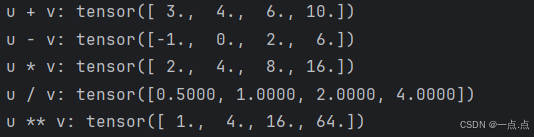
u = torch.tensor([1.0, 2, 4, 8])
v = torch.tensor([2, 2, 2, 2])
print("u + v:", u + v, "\nu - v:", u - v, "\nu * v:", u * v, "\nu / v:", u / v, "\nu ** v:" ,u ** v)
运行结果:
8、将多个张量连结在一起
m = torch.arange(12, dtype=torch.float32).reshape((3, 4))
n = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
(1)按行合并
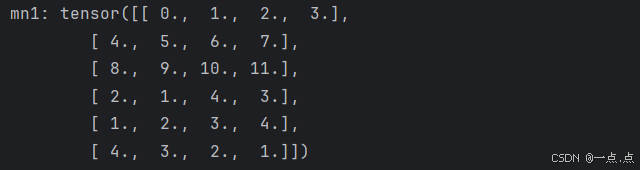
mn1 = torch.cat((m, n), dim=0) # 按行合并
print("mn1:", mn1)
运行结果:
(2)按列合并
mn2 = torch.cat((m, n), dim=1) # 按列合并
print("mn2:", mn2)
运行结果:

9、通过逻辑运算符构建二元张量
print(m == n) # 按元素值进行判断
运行结果:

10、对张量中的所有元素进行求和sum(),会产生一个只有一个元素的张量
print(m.sum())
运行结果:

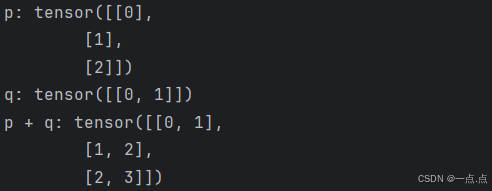
11、广播机制:即使形状不同(维度相同),仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作
p = torch.arange(3).reshape((3, 1))
q = torch.arange(2).reshape((1, 2))
print("p:", p, "\nq:", q)
print("p + q:", p + q) # 广播机制
运行结果:
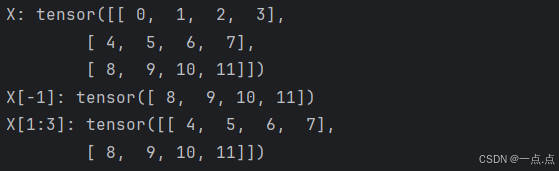
12、 元素的访问: 可以[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素
print("X:", X, "\nX[-1]:", X[-1], "\nX[1:3]:", X[1:3])
运行结果:
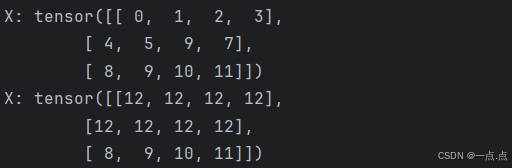
13、元素修改写入:可以通过指定索引来将元素写入矩阵
X[1, 2] = 9 # (1)将第1行第2列的元素值改为9
print("X:", X)
X[0:2, :] = 12 # (2)为多个元素赋值相同的值,只需要索引所有元素,然后为它们复制;第0行与第1行、所有列
print("X:", X)
运行结果:
14、运行一些操作可能会导致为新结果分配内存
before = id(n) # n的id存起来
n = n + m # 将 n + m 再赋值为 n; n + m结果一加再创建一个新的变量,名字为n
print(id(n) == before) # False:新的n的id是不会等于之前的,因为之前的y的内存已经被析构掉了
# 解决方法:执行原地操作
z = torch.zeros_like(n) # 创建一个z,用zeros_like()即与n的shape、数据类型均相同,但所有元素为0
print("id(z):", id(z)) # id(z): 2040830618176
z[:] = m + n # z里面所有的元素 = m + n
print("id(z):", id(z)) # id(z): 2040830618176
运行结果:

15、 转换为numpy张量、转换为tensor张量
A = X.numpy()
B = torch.tensor(A)
print("type(A):", type(A), "\ntype(B):", type(B))
运行结果:

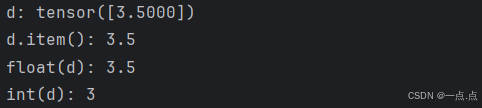
16、将大小为1的张量转换为python标量
d = torch.tensor([3.5])
print("d:", d, "\nd.item():", d.item(), "\nfloat(d):", float(d), "\nint(d):", int(d))
运行结果:
17、完整代码如下:
import torch
# 1、张量表示一个数值组成的数组,这个数组可能有很多维度
print("--------------------1--------------------")
x = torch.arange(12) # 0到11所有的数拿出来(步长默认1);左闭右开区间
print("x:", x) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
y = torch.arange(start=1, end=20, step=2)
print("y:", y) # tensor([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
# 2、通过张量的shape属性来访问张量的 形状;numel()得到张量中元素的 总和
print("--------------------2--------------------")
print("x.shape:", x.shape) # torch.Size([12])
print("x.numel():", x.numel()) # 12
# 3、改变一个张量的形状而不改变元素数量和元素值,可以调用reshape函数
print("--------------------3--------------------")
X = x.reshape(3, 4)
print("X:", X) # tensor([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])
# 4、使用全0、全1、其他常量或者从特定分布中随机采样的数字
print("--------------------4--------------------")
a = torch.zeros((2, 3, 4)) # 元素全0
print("a:", a)
b = torch.ones((2,3,4)) # 元素全1
print("b:", b)
c = torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]]) # 通过提供包含数值的python列表(或嵌套列表)来为所需张量中的每个元素赋予确定值
print("c:", c)
# 5、常见的标准算术运算符(+、-、*、/ 和 **)都可以被升级为 按元素运算
print("--------------------5--------------------")
u = torch.tensor([1.0, 2, 4, 8]) # 1.0,则所有都按浮点数运算
v = torch.tensor([2, 2, 2, 2])
print("u + v:", u + v, "\nu - v:", u - v, "\nu * v:", u * v, "\nu / v:", u / v, "\nu ** v:" ,u ** v)
# 6、将多个张量连结在一起
print("--------------------6--------------------")
m = torch.arange(12, dtype=torch.float32).reshape((3, 4))
n = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
mn1 = torch.cat((m, n), dim=0) # 按行合并
mn2 = torch.cat((m, n), dim=1) # 按列合并
print("mn1:", mn1, "\nmn2:", mn2)
# 7、通过逻辑运算符构建二元张量
print("--------------------7--------------------")
print(m == n) # 按元素值进行判断
# 8、对张量中的所有元素进行求和sum(),会产生一个只有一个元素的张量
print("--------------------8--------------------")
print(m.sum()) # tensor(66.)
# 9、广播机制:即使形状不同(维度相同),仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作
print("--------------------9--------------------")
p = torch.arange(3).reshape((3, 1))
q = torch.arange(2).reshape((1, 2))
print("p:", p, "\nq:", q)
print("p + q:", p + q) # 广播机制
# 10、元素的访问: 可以[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素
print("--------------------10--------------------")
print("X:", X, "\nX[-1]:", X[-1], "\nX[1:3]:", X[1:3])
# 11、元素修改写入:可以通过指定索引来将元素写入矩阵
print("--------------------11--------------------")
X[1, 2] = 9 # (1)将第1行第2列的元素值改为9
print("X:", X)
X[0:2, :] = 12 # (2)为多个元素赋值相同的值,只需要索引所有元素,然后为它们复制;第0行与第1行、所有列
print("X:", X)
# 12、运行一些操作可能会导致为新结果分配内存
print("--------------------12--------------------")
before = id(n) # n的id存起来
n = n + m # 将 n + m 再赋值为 n; n + m结果一加再创建一个新的变量,名字为n
print(id(n) == before) # False:新的n的id是不会等于之前的,因为之前的y的内存已经被析构掉了
# 解决方法:执行原地操作
z = torch.zeros_like(n) # 创建一个z,用zeros_like()即与n的shape、数据类型均相同,但所有元素为0
print("id(z):", id(z)) # id(z): 2040830618176
z[:] = m + n # z里面所有的元素 = m + n
print("id(z):", id(z)) # id(z): 2040830618176
# 13、转换为numpy张量、转换为tensor张量
print("--------------------13--------------------")
A = X.numpy()
B = torch.tensor(A)
print("type(A):", type(A), "\ntype(B):", type(B))
# 14、将大小为1的张量转换为python标量
print("--------------------14--------------------")
d = torch.tensor([3.5])
print("d:", d, "\nd.item():", d.item(), "\nfloat(d):", float(d), "\nint(d):", int(d))
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









