



目录
插入几个新字段
在"a b c d"的b后面插入3个字段e f g。
echo "a b c d" | awk '{$2=$2" e f g";print}'
-
echo "a b c d":这将在终端输出字符串"a b c d",并通过管道将其传递给下一个命令。 -
|:这是一个管道操作符,用于将前一个命令的输出作为后一个命令的输入。 -
awk '{$2=$2" e f g";print}':这是awk的脚本部分,用来对输入进行处理。-
{$2=$2" e f g";print}是一个awk的动作块,由大括号{}包围。 -
$2表示当前处理的行的第二个字段(使用空格分隔的字段),即"b"。$2=$2" e f g"的意思是将第二个字段(即"b")与"e f g"连接起来,形成"b e f g"。 -
print是一个awk的内置函数,用于打印当前处理的行。因此,这个命令将打印修改后的行,即"a b e f g c d"。
-
格式化空白
移除每行的前缀、后缀空白,并将各部分左对齐。
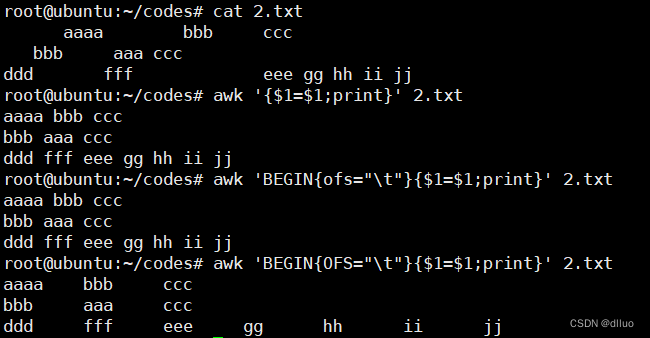
-
awk '{$1=$1;print}' 2.txt:这是awk的脚本部分,用来对输入进行处理。-
{$1=$1;print}是一个awk的动作块,由大括号{}包围。 -
$1=$1是一个空操作,它将重新分配第一个字段(即$1)的值给它自己。这实际上是awk中的一个常见技巧,它可以使awk对输入行进行重新格式化,去除多余的空格,并将字段之间的空格调整为单个空格。 -
print是一个awk的内置函数,用于打印当前处理的行。因此,这个命令将打印经过处理后的行,其中字段之间只有一个空格,多余的空格已被删除。 -
2.txt是要处理的输入文件。
-
-
BEGIN{OFS="\t"}这一部分是awk的 BEGIN 块。BEGIN 块在处理输入之前执行一次,并且可以用于设置初始条件和变量。这里的意思是在处理输入之前,将输出字段分隔符 (OFS) 设置为制表符(\t)。
读取.ini配置文件中的某段
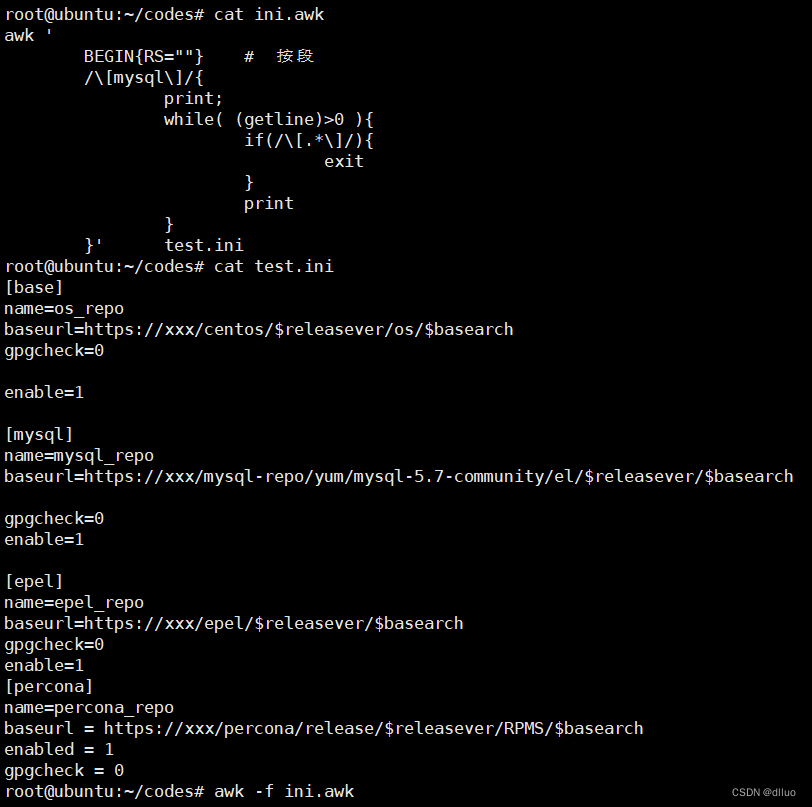
-
BEGIN{RS=""}:在处理输入之前,将输入记录分隔符RS设置为空字符串。这样设置可以使awk将空行作为记录分隔符,从而将文件中的每个段落作为一个记录。 -
/\[mysql\]/:这是一个模式匹配条件,用于匹配包含[mysql]的行。当遇到这样的行时,以下动作块将被执行。 -
{print; while((getline)>0){ if(/\[.*\]/) {exit} print} }:这是匹配成功时执行的动作块。-
print语句用于打印匹配到的行。 -
while ((getline)>0)用于循环读取下一行。当getline函数返回非零值时,表示成功读取了一行。循环会一直继续,直到遇到新的段落(以[开头的行)。 -
if (/\[.*\]/) {exit}:如果读取到新的段落开始的行,则退出循环。 -
print语句在循环内部,用于打印每行数据(该行不是新的段落开始的行)。
-
根据某字段去重
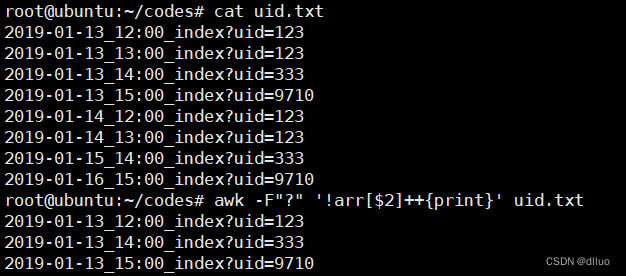
-
-F"? ":这个选项用于指定字段分隔符为问号(?),-F表示字段分隔符选项,"?"是指定的分隔符。 -
!arr[$2]++{print}:这是一个条件和动作的组合。-
arr[$2]:创建一个数组arr,使用第二个字段($2)作为索引。 -
!arr[$2]++:如果数组中指定的索引值为0,则条件成立(即之前没有出现过该索引值)。 -
{print}:在条件满足时打印当前行。
-
筛选给定时间范围内的日志
BEGIN{
# 要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2023 08 5 13 30 01")
}
{
# 取出日志中的日期时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
# 将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
# 通过比较epoch值来比较时间大小
if(tmp_time > which_time){
print
}
}
# 构建的时间字符串格式为:"18/Jul/2023:13:30:00 +0800"
function strptime2(str,dt_str,arr,Y,M,D,H,m,S) {
dt_str = gensub("[/:+]"," ","g",str)
# dt_sr = "18 Jul 2023 13 30 00 08 00"
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
function mon_map(str,mons){
mons["Jan"]=01
mons["Feb"]=02
mons["Mar"]=03
mons["Apr"]=04
mons["May"]=05
mons["Jun"]=06
mons["Jul"]=07
mons["Aug"]=08
mons["Sep"]=09
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}-
BEGIN块:- 在
BEGIN块中,我们使用mktime函数将指定的时间("2023 08 05 13 30 01")转换为epoch值,并将其赋值给which_time变量。
- 在
-
主循环:
- 在主循环中,使用正则表达式匹配整行日志中的日期时间部分,并将匹配结果保存在数组
arr中。
- 在主循环中,使用正则表达式匹配整行日志中的日期时间部分,并将匹配结果保存在数组
-
strptime2函数:strptime2函数用于将日期时间字符串转换为epoch值。- 首先,通过使用
gensub函数将日期时间字符串中的分隔符("/", ":", "+")替换为空格,生成格式为"18 Jul 2023 13 30 00 08 00"的日期时间字符串,保存在变量dt_str中。 - 然后,使用
split函数将dt_str按空格分割,并将结果保存在数组arr中。 - 接下来,根据数组
arr中的元素,提取年份、月份、日期、小时、分钟和秒,并赋值给变量Y、M、D、H、m和S。 - 最后,使用
mktime函数将组合后的日期时间值转换为epoch值,并返回。
-
mon_map函数:mon_map函数用于将英文月份缩写映射为对应的数字。- 在函数内部,使用一个关联数组
mons,将英文月份缩写作为键,数字作为值进行映射。 - 根据传入的英文月份缩写
str,返回相应的数字。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











