






摘要
随着反检测技术的不断发展,产生了大量形态多样的恶意代码变种,传统检测技术已无法准确检测出该种未知恶意代码。由于数据可视化方法能将恶意代码的核心表现在图像特征中,因此可视化恶意代码检测方法受到越来越多关注。首先对传统恶意代码检测技术进行概括总结,然后介绍当前主流的恶意代码可视化方法,接着分析了基于恶意代码图像的机器学习与深度学习检测方法,具体涵盖了该方法所用的模型结构、创新点及评估结果,最后对当前检测技术所面临的问题进行总结,并阐述了未来可能的研究方向,旨在助力恶意代码检测技术的发展。
关键词
反检测技术; 恶意代码; 数据可视化; 机器学习; 深度学习
0 引言
在大数据时代,互联网的发展加快了人们生活节奏,极大程度提高了生活品质,但在很多方面都存在着无法避免的安全问题。随着计算机技术的不断发展,越来越多黑客通过网络攻击来获取利益,恶意代码即是其中的常见手段之一。恶意代码的泛滥给国家、社会及个人带来了巨大危害。2020年,国家互联网应急中心CNCERT捕获恶意程序样本数量超过4 200万个,日均传播次数达到482万余次,涉及恶意程序家族近34.8万个[1]。因此,如何快速、准确地检测出恶意代码,是目前网络安全领域的研究热点。
目前,国内外针对恶意代码检测技术进行全面综述的文献较少。如文献[2]从动态、静态和形式化3个角度分析各种检测方法的原理及优缺点,但文献发表时间较长,缺乏先进性与全面性;文献[3]是一篇全面描述在Windows平台上进行恶意软件检测的综述性文章,从特征提取、特征处理及分类器设计方面对智能检测进行归纳与总结,但对当前研究热点(基于可视化的恶意代码检测)的分析较少。本文对不同类型的恶意代码检测方法进行全面的调研分析,从恶意代码可视化方法、图像特征提取、分类器设计、当前检测所面临的问题4个方面系统地进行探究,总结了近年来针对恶意代码检测的新兴技术,提出未来可能的研究方向,旨在提高恶意代码检测的准确率与效率。
1 传统恶意代码检测方法
恶意代码也称为恶意软件,是指通过各种手段对用户、计算机或网络造成破坏的软件。通过人工分析恶意代码具体函数来检测恶意软件,不仅时间成本高,而且检测效率低、实用性差。依据是否运行程序可将传统恶意代码检测技术分为静态检测、动态检测与混合检测3类。
1.1 静态检测技术
静态检测技术不需要运行恶意软件,其研究重点在于如何准确、有效地提取静态特征。通常对恶意代码文件进行反编译、反汇编、文件结构分析以及控制流与数据流分析,提取程序中的指令、字节序列、文件头部信息等作为静态特征。该方法的优点在于能耗小、风险低、速度快,且对实时性要求低,对恶意样本覆盖率高,可快速捕获语法和语义信息进行全面分析,但缺点是受到经变形、多态、代码混淆技术处理后的恶意代码干扰,会出现误报和漏报的情况。本文根据静态特征种类对不同静态检测技术进行探究与分析。
恶意代码的字节序列特征通常使用N-Gram方法提取,原因是恶意代码由字符、文字和符号等构成,包含了语义和区块结构,所以统计语言模型N-Gram适用于恶意代码特征提取。N-Gram方法需要设置一个长度为n的滑动窗口,在原始字节序列上进行平滑操作,将长度为n的子序列频率作为特征,提取方式如图1所示。Schultz等[4]是第一个使用N-Gram方法在基于Windows平台下提取特征的,其将特征输入到各个分类器,并通过五倍交叉验证实验验证了N-Gram方法优于单纯基于签名的方法。滑动窗口大小是N-Gram方法的重要参数,将直接影响到恶意代码检测准确率。如果n值过小,提取的特征缺乏代码的整体性,容易陷入局部最优;如果n值过大,会影响特征之间的相关性。Kolter等[5]设置不同n值的N-Gram法进行特征提取,旨在找出最优n值以提高恶意代码检测准确率。由于N-Gram特征提取存在方法单一、效率较低等问题,通常将N-Gram提取的字节序列特征与其他特征融合或采用不同n值特征进行训练[6-7]。
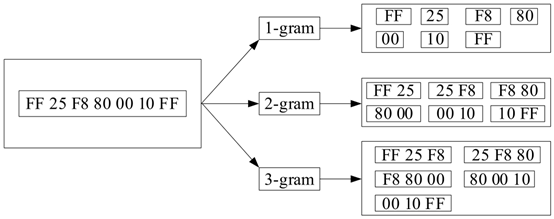
图1 N-Gram提取字节序列特征
Fig. 1 N-Gram extracts byte sequence features
PE文件通常由DOS头、PE头与各类区块段组成,具体结构如图2所示。由于PE头是特有的可执行文件头,包含程序文件的结构特征、动态链接库及导入导出表等信息,所以PE头信息也可作为恶意代码检测的静态特征。Li等[8]将恶意代码样本中的文件头、熵、DLL等信息作为特征,并通过实验证明了训练出的分类器对重要类别的自动规避攻击具有鲁棒性;Kumar等[9]组合了PE头的原始值与派生值,对比了集成特征集与原始特征集(头部信息、熵等特征)在机器学习分类器中的效果,通过实验证明了集成特征集训练出的分类器能以较高精度与较低成本分类出良性或恶性代码。
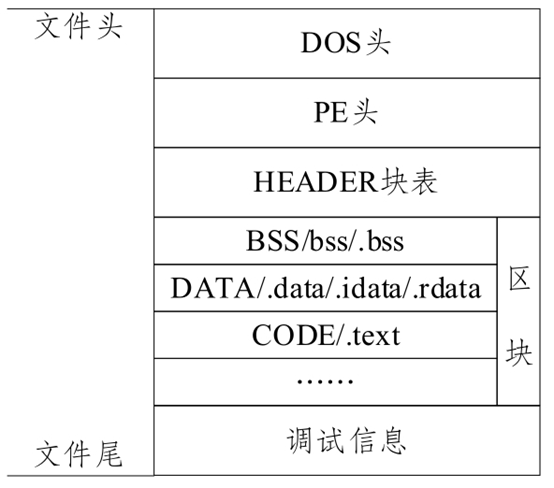
图2 PE文件结构
Fig. 2 PE file structure
除上述两种静态特征外,还有动态链接库(DLL)、API序列、可阅读字符串和熵等信息可作为静态特征。但随着对抗反汇编、反调试、反虚拟机、加壳与脱壳等恶意代码反检测技术的发展,使得传统静态检测方法提取的特征不能准确代表恶意代码攻击信息。
1.2 动态检测技术
动态检测技术是指监控恶意代码在虚拟环境(模拟器)中运行的行为。为充分展现恶意代码的行为及隐藏功能,需在运行前赋予恶意代码足够的权限。要保障含有不同攻击内容的恶意代码能正常运行,需要配置不同运行环境,如操作系统版本、运行必备软件等。动态检测方法的优点在于能识别新型恶意代码,有效处理静态检测中存在的误报、漏报等问题,但缺点是恶意代码对运行环境要求高,且所需的时间成本高。
Kim等[10]使用序列对比算法(MSA)对API序列进行动态分析,该方法能快速分析识别恶意代码及其变种,并对网络入侵作出快速响应;陈佳捷等[11]将CucKoo沙箱与改进的DynamoRIO系统作为虚拟环境,从Cuckoo报告、网络日志与行为信息记录中提取特征并融合,并使用基于双向门循环单元(BGRU)的机器学习模型,检测结果表明该模型性能优于LSTM与BLSTM等模型;周杨等[12]在传统沙箱中运行恶意代码得到动态分析报告,并将API调用信息中函数的调用时序、返回值等参数作为特征,利用统计与计算两种方式构建训练所需特征集,实验结果证明,改进后的Vec-LR优于SVM、RF、DT等算法,但该方法的缺点在于沙箱运行及特征抽取阶段消耗了大量时间。
观察虚拟环境中的恶意代码行为是动态检测的唯一方式,无需对恶意代码进行解密与解压缩操作。有些恶意代码变种能检测虚拟环境的存在,此时由动态行为产生的特征不能准确代表其恶意行为。虽然强制代码执行隐藏路径使其能充分展现恶意行为,但是通常容易出现路径爆炸、运行超时等问题。每个恶意代码都需设定不同的虚拟环境,可沙箱环境终究与真实计算机环境存在差异,将导致一些功能无法触发或表现有所不同。动态检测除时间成本高外,还面临一些安全问题,比如内核级的特殊权限、网络连接等都会带来一些安全隐患[13]。
1.3 混合检测技术
对于加壳的恶意代码,很难对其进行反汇编操作,意味着无法准确提取代表其恶意行为的特征,所以常规静态检测技术很难分类出加壳等变种恶意代码。通过观察恶意代码在虚拟环境中的行为,可检测到加壳恶意代码的隐藏行为,但这种方式存在安全隐患,且时间成本高,实用性与可扩展性差。因此,这种加壳的恶意代码适用于动静结合的分析方法,即混合分析。通常首先使用动态分析对加壳恶意代码进行去壳,然后通过静态分析脱壳代码,进而全面获取代码的恶意攻击行为[14]。混合检测旨在结合静态检测与动态检测的优势,在确保准确率的同时降低资源与时间开销。
Islam等[15]提出一种基于两个静态特征与一个动态特征的分类模型,将函数长度频率与可打印字符串信息矢量化成静态特征向量,从日志文件中提取API特性(API函数名、参数)构成动态特征向量,组合3个向量后用于分类器训练;Santos等[16]提出一种混合恶意软件检测器(OPEM),将操作码的出现频率(静态特征)与执行程序的轨迹信息(动态特征)相结合。针对恶意代码快速增长导致动态沙箱资源消耗过大的问题,梁光辉等[17]提取恶意代码的模糊哈希特征(静态)和动态行为特征,将无监督聚类学习与有监督分类学习结合后用于恶意代码检测。
虽然混合检测方法涵盖了静态与动态检测的优点,能根据具体的恶意代码家族制定针对性的特殊检测方式,但是这种方式也会消耗大量资源,并且混合检测的复杂度与工作量使这种方式不适用于大规模数据集。
2 恶意代码可视化方法分析
尽管恶意代码衍生了大量变体,但同类恶意家族代码中的核心具有相似性与传承性。这种变体会导致基于签名的检测方法失效,但将恶意代码可视化为图像不会从本质上改变图像纹理及结构特征,该方式能有效对抗恶意代码混淆。与人工提取特征向量相比,恶意代码图像包含丰富、几乎全部的恶意代码信息。无论是通过图像结构、纹理与颜色分析(局部特征和全局特征提取),还是通过深度学习算法自动学习图像特征,恶意代码可视化都能最大程度上减少混淆技术带来的影响。
2.1 可视化为灰度图像
Nataraj等[18]将恶意代码.text区块的二进制数据可视化为灰度图像,利用GIST算法提取图像特征,并使用k最近邻(kNN)算法进行分类,开启了基于可视化的恶意代码检测方法研究。目前,将恶意代码可视化为灰度图像是检测恶意代码的主流方法,以下对常见的灰度可视化方法进行具体介绍。
Nataraj矢量化是将恶意代码二进制文件作为编码源,并把原始二进制序列切割成长度为8bit的子序列,产生的8位二进制串通过进制转换到[0,255],正好对应像素区间。由于每个恶意代码文件包含的攻击类型不同,导致可视化图像大小不一,因此通过文件大小固定图像宽度,将恶意代码可视化为长条状的灰度图像,具体可视化步骤如图3所示。Nataraj矢量化与B2M算法思想相同,这种灰度可视化方法已被广泛应用于恶意代码检测中[19-22]。Han等[23]在Nataraj矢量化基础上增加了熵图,利用熵图特征进一步判断恶意代码图像的相似性,改进了图像纹理特征提取方法及相似度度量策略。
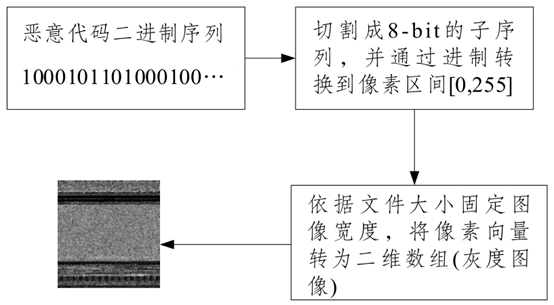
图3 Nataraj矢量化具体步骤
Fig. 3 Nataraj vectorization specific steps
在2015年黑帽大会上,Davis等[24]提出反汇编的恶意代码矢量化方法,将反汇编的十六进制数据作为编码源,每个十六进制数据转换到4-bit的二进制并填充到64bit,其中每位二进制乘以255,对应像素灰度值0或255。这种方式将恶意代码可视化为只含像素值0和255的灰度图,图像每一行矢量都对应一条机器码。在此基础上,蒋永康等[25]进一步探究了编码长度、编码量等参数选择,并给出具体的深度学习模型。
Ni等[26]提出一种结合操作码序列与LSH提取恶意软件特征的MCSC算法,将恶意代码进行反汇编,获取汇编指令中的操作码序列,并使用SimHash与双线性插值法将操作码序列转换为恶意代码图像,具体可视化步骤如图4所示。因为恶意代码变体通过该方式可视化的图像在某些区域存在相似的指纹,所以通过图像处理技术识别同类恶意代码变体具有可行性。
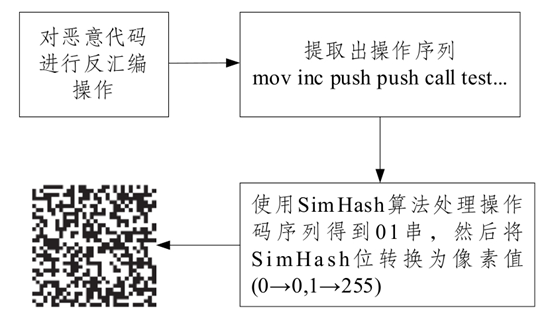
图4 Ni可视化具体步骤
Fig. 4 Ni visualization specific steps
乔延臣等[27]提出一种基于汇编指令词向量的恶意代码可视化方法,首先通过反汇编操作得到汇编代码,将指令看作词,函数看作句子,从而把恶意代码文件转换为文档,然后对文档使用Word2Vec算法获取汇编指令词向量,统计训练集中Top100的汇编指令,据此将每个文档转换为矩阵,最后归一化矩阵得到可视化的灰度图像。具体操作步骤如图5所示。
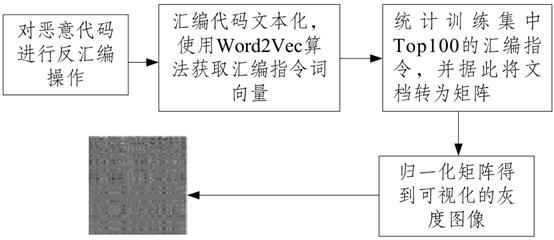
图5 基于汇编指令词向量的可视化方法
Fig. 5 Visualization method based on assembly instruction word vector
陈小寒等[28]不仅考虑了恶意代码原始信息,而且考虑了原始代码与时序特征相关联的能力,增强了分类特征的信息密度。首先提取出汇编代码中的操作码序列,利用双向递归神经网络(BRNN)对其进行处理,然后使用Simhash算法将原始编码与预测编码融合,生成灰度特征图像。
上述5种将恶意代码可视化为灰度图像的方法均取得了不错的分类效果,在一定程度上克服了代码混淆技术带来的影响,在实际应用中通常采取多种可视化方法进行对比分析。可视化的灰度图像其实并不能确定其包含全面的恶意攻击信息,由于同类恶意家族代码可视化的灰度图像具有相似的指纹特征,而不同家族间的差异较大,所以将恶意代码可视化为灰度图像进行分类检测具有可行性。
2.2 可视化为彩色图像
由于灰度图只有单个通道,能包含的信息较少,不能全面地将恶意代码攻击信息体现在图像中,导致可视化的灰度图像特征不明显,不能很好地反映出恶意代码特性。相比恶意代码灰度图像,将恶意代码可视化为彩色图像既保留了灰度主要特征,又强调了二进制文件中重复出现的数据片段,使得同类恶意家族的彩色图像具有相似的纹理、颜色与结构特征。
代码复用技术已普遍应用于恶意代码中,使得属于同类家族的恶意代码变种拥有相似的二进制序列片段,因此采用可视化技术分析恶意代码具有可行性。王博等[29]将恶意代码二进制序列分割成RGB三通道值,从而将恶意代码可视化为彩色图像,由于并不是每个恶意代码的比特位都是24比特的整数倍,所以不足24比特的用1补足,具体可视化步骤如图6所示(彩图扫
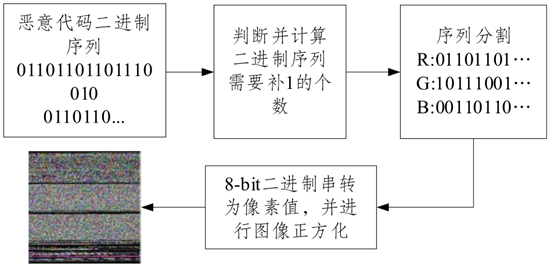
图6 基于二进制序列分割的可视化方法
Fig. 6 Visualization method based on binary sequence segmentation
OSID码可见,下同)。但该方法的不足之处在于模型过于复杂,且参数量大、训练效率不高。针对上述问题,蒋考林等[30]提出基于多通道图像与AlexNet神经网络的恶意代码检测方法,采用彩色图像特征提取、局部响应归一化等技术,在降低模型复杂度的同时,提升了模型泛化能力。在恶意代码可视化方面,其在恶意代码二进制序列末尾数据量不足3字节的情况下,用0进行补足,然后将像素序列正方化。
以同类恶意家族代码的操作码频率相近、异族操作码频率差异较大为前提,任卓君等[31]提出一种基于操作码频率的恶意代码可视化分析方法。首先提取汇编恶意代码中的操作码序列,然后对序列进行缩放采样并转换到整数区间[0,253],统计数量排前15的操作码类型来设计色谱,以此区分常见与罕见的操作码指令,最后根据颜色向量在RGB空间中的次序重排操作码,实现根据操作码频率将恶意代码可视化为彩色图像。这种可视化方法可解决图像视觉区分度不强、分类精度不高等问题。同时,其对比了Gist特征与卷积神经网络学习到的特征对恶意代码图像分类结果的影响。
王润正等[32]利用反汇编工具获取恶意代码中的各区块数据,并转化到RGB彩色图像的各个通道,从而将恶意代码可视化为RGB彩色图像,具体步骤如图7所示。恶意代码分类前需对其各区块段进行分析,因为各区块存放了恶意代码特征信息,能在一定程度上反映出恶意家族的特性。
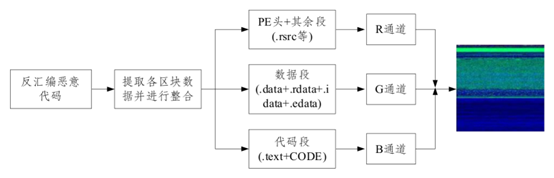
图7 基于区块的可视化方法
Fig. 7 Block-based visualization method
上述研究说明基于彩色图像的可视化方法对恶意代码的分析具有可行性,彩色图像拥有3个通道,能更好地保留恶意代码的特征信息,从而有效对恶意代码及其变种进行检测与分类。但就目前而言,将恶意代码可视化为彩色图像,然后根据彩色图像特征进行恶意代码检测的相关工作较少,仍处于早期发展阶段。
3 恶意代码可视化检测技术研究
同类恶意家族拥有相似的攻击信息,所以可视化图像也具有相似的纹理、颜色、结构等特征。恶意代码被可视化为图像后,提取出图像的全局特征与局部特征,输入到分类器中获取分类结果,此时已将恶意代码的分类问题转化为恶意代码图像分类。在当前研究工作中,分类器主要分为基于机器学习算法的分类器与基于深度学习算法的分类器,二者各有优缺点,通常采用多种分类器进行实验对比,选择一种效果最优的特征提取算法与分类算法。
3.1 基于机器学习的恶意代码检测
机器学习算法能自动分析数据规律,并据此对未知数据进行预测分析,目前机器学习算法已应用于恶意代码检测、入侵检测等计算机安全领域。将恶意代码可视化为图像后,采用基于机器学习的恶意代码检测方法进行检测,其原理是通过图像处理技术从图像中提取不同类型特征,描述待分析样本的恶意攻击行为,每个恶意代码样本均由一个降维后的固定维度向量表示,然后使用机器学习算法对已知标签样本图像进行训练,构建分类器,训练出分类器后便可对未知样本进行检测分析。
使用机器学习算法训练恶意代码图像,难点在于如何使用特征分析技术提取出不易受随机因子干扰且具有家族代表性的信息,优秀的特征分析方法可在去除冗余信息的同时提高模型训练效率。常见的特征分析技术分为特征抽象与特征降维,特征抽象是指将源数据抽象成算法可理解的数据,而特征降维可分为两种:一种是从原有特征集中选出子集,仅单纯进行挑选不改变特征性质,即特征选择;另一种是在原有特征集基础上创造一个新的特征子集,通过空间变换改变了特征性质,即特征提取。
目前基于机器学习算法的恶意代码检测方法已有很多,并取得了不错的分类结果,本节将对其中基于可视化的恶意代码检测方法进行介绍、分析与比较,具体如表1所示。
表1 基于机器学习的可视化恶意代码检测方法
Table 1 Visual malicious code detection methods based on machine learning
| 文献 | 年份 | 数据集 | 图像类型 | 特征 | 机器学习算法 | 准确率(%) | 优点 | 不足 |
| [32] | 2021 | VirusShare | 彩色 | 区段特征 | KNN、SVM、RF | RF 97.53 | 解决了可视化过程中数据损失、单一等问题 | 复杂度高 |
| [33] | 2013 | Offensive Computing Databases | 灰度 | 图像强度、小波与Gabor特征 | SVM | 95.95 | 对代码混淆更加健壮,且无需解包与解密 | 难以应对大规模训练样本,很难解决多分类问题 |
| [34] | 2017 | ESET NOD32/ VX Heavens 收集 | 灰度 | N-Gram算法、导入函数频率 | DT、LR、NB、GB、KNN、RF | RF 98.90 | 能准确检测已知与未知的恶意代码 | 没有充分利用可视化的图像特征 |
| [35] | 2018 | Nataraj/ Antiy Databases | 灰度 | 全局特征(GIST)、局部特征(LBP或dense SIFT) | KNN、RF | RF 94.98 | 良好的适应性、抗干扰性及抗混合性 | 时间成本高、难以应用于大规模数据场景 |
| [36] | 2019 | Malimg | 灰度 | LGMP特征(D-SIFT和GIST特征) | KNN、SVM、NB | KNN 98.40 | 提取全局与局部特征检测恶意代码 | 局部特征选择速度慢,模型检测速度慢 |
| [37] | 2019 | malwaredb | 灰度 | 灰度共生矩阵、N-Gram算法、改进型信息增益算法(IG) | MLP、Logist、RF | RF 85.00 | 从多个角度提取恶意代码特征 | 误差较大,准确率低 |
| [38] | 2020 | Kaggle BIG2015 | 灰度 | 灰度共生矩阵、N-Gram算法、灰度直方图 | RF | 97.04 | 解决了恶意代码特征提取单一的问题 | 时间成本高,容易过拟合 |
3.2 基于深度学习的恶意代码检测
深度学习是机器学习的分支,是一种端到端的系统,且无需先验知识。深度学习利用大量隐藏层的非线性网络结构对样本进行训练,可将原始数据的特征空间转换到新空间,提取出训练样本的内在特征,提高模型的泛化性。深度学习的最大优点在于能自动学习、提取特征,利用深度学习算法学习恶意代码图像特征并进行预测分析,可减少人工提取特征的时间成本。因其具有可扩展性、灵活性等特点,被广泛应用于恶意代码检测与分类。
Zhao等[39]提出一种基于纹理可视化的深度学习恶意软件分类框架(MalDeep),通过代码映射(灰度图像)、纹理分割与纹理特征提取,将恶意代码表征在一个新的图像纹理特征空间,并构建一个由两个卷积层、两个下采样层与多个全连接层组成的卷积神经网络。实验结果证明了该模型在代价函数、交叉熵、训练与测试损失方面具有良好的收敛性,针对一些后门家族的恶意代码,模型分类准确率能达到99%以上。Chu等[40]利用灰度可视化算法将同源分类问题转化为图像分类问题,构建基于恶意代码图像的卷积神经网络,并通过实验验证该模型具有很强的可扩展性与通用性,在Kaggle数据集上的分类准确率能达到98.60%,但缺点在于没有进一步探究模型参数对分类的影响。
Sun等[41]结合恶意代码静态分析、循环神经网络(RNN)与卷积神经网络(CNN),不仅考虑了恶意代码原始信息,而且考虑了原始代码与时序特征相关联的能力。该过程减少了对类别标签的依赖,保证不丢失有效信息,同时使生成的特征图像非常相似。采用Kaggle数据集进行实验,当训练集与验证集比例为1:30时,准确率能达到92%以上,调整比例为3:1时,准确率超过了99.5%,实验结果验证了该模型具有不错的分类性能。Vasan等[42]将原始恶意代码二进制文件转换为彩色图像,利用微调卷积神经网络(IMCFN)对恶意代码进行检测与识别。该方式能有效检测隐藏代码、混淆恶意软件与恶意软件变种,且时间成本低,IMCFN在Malimg数据集上的准确率为98.82%。
目前,越来越多深度学习模型被用于恶意代码检测,如卷积神经网络(CNN)、循环神经网络(RNN)和图卷积神经网络(GCN)等,这些模型通过从大量训练样本中提取恶意代码内在特征进行训练与分类,具有自动化程度高、速度快及资源消耗少等优点。但不足之处在于不能深层次提取特征、模型结构复杂、参数过多及模型泛化能力不足等,仍需作进一步研究。
4 面临的问题及分析
随着恶意代码检测技术的发展,其面临的问题也不容忽视。本节介绍当前检测技术面临的主要问题,并提出对未来的展望,这些问题的存在也意味着相关方向会成为未来研究的重点。
当前数据集存在的问题主要有恶意代码形态多样化、标准数据集较少、数据分布不均衡及数据缺乏标签等。为规避恶意代码检测,网络攻击者会利用代码混淆、重打包等技术制造出多种类型的变种。由于标准数据集较少,且均为非完整性程序,将影响到分类器评估效果。目前公开的基于Windows的恶意软件数据集有4个,即Malimg[43]、Malheur[44]、VirusShare[45]和Microsoft Kaggle[46]。
某些恶意软件需在特定环境下才能显现其恶意行为,并且会检测是否存在虚拟环境,进而避免被收集,这必然会导致收集的数据集分布不均衡。若正负数据样本数量或不同家族的样本数量差距较大,将不利于深度模型学习样本内在特征。在深度学习中,只有输入足够且均衡的训练数据才能有效避免过拟合现象,如果数据集较小,可通过数据增强技术增加样本数量,抑制数据集不平衡带来的不良影响。采用适当的数据增强方法可有效避免过拟合现象,提高模型的泛化性与鲁棒性。
Cui等[47]首先将恶意代码转化为灰度图像,然后针对恶意代码家族样本数量不均匀导致的过拟合问题,采用蝙蝠算法(BA)并结合卷积神经网络对恶意代码图像进行识别与分类。朱晓慧等[48]分别对有监督与无监督数据增强方法进行分析,并阐述了数据增强技术在视觉图像领域的具体应用,论证了该技术能有效解决数据不平衡或数据缺失等问题。近几年主流基于增扩数据的生成式模型有自动编码器、自回归模型与生成对抗网络等,其中生成对抗网络(GAN)可不用预先假设数据分布直接进行采样,理论上可完全拟合真实数据,因此基于GAN的数据增强方法表现突出。基于GAN的数据增强技术在图像领域已相当成熟,将基于GAN的网络安全数据增强与图像处理方法相结合,探讨基于GAN的恶意代码图像增强技术,并结合深度学习算法进行分类与预测,该方式在恶意代码检测领域具有很高的潜在价值。
对收集的恶意代码进行信息标注是一件耗时耗力的工作,如果依照原有恶意代码样本的相关恶意行为判别未知恶意代码,该方式具有挑战性。现有的打标签方法主要依赖于杀毒软件与检测平台,该方式的准确性完全依赖于软件可靠性,而对于新型恶意代码变种,软件泛化能力可能不足,此时仍旧需要专家经验进行辅助分析。
5 结语
本文综述了基于数据可视化进行恶意代码检测的方法,首先介绍传统恶意代码检测方法的原理及优缺点,然后具体分析恶意代码的灰度可视化与彩色可视化方法,从机器学习与深度学习两个角度对现有的各种恶意代码图像分类方法进行全面分析与比较,最后对当前恶意代码检测技术所面临的问题进行总结与思考。在未来研究中,可从以下两方面进行探究:一是探索一种新型的恶意代码可视化方法,使图像能包含独特的家族特征,并利用GAN解决数据集分布不均衡问题,提高模型泛化能力;二是当前检测技术所用的深度学习模型以CNN和RNN为主,而GCN的特别之处在于对象是图数据,并能直接在图数据上进行卷积。当前将GCN用于恶意代码检测的应用较少,未来研究工作可考虑将数据可视化、图像处理、GAN与GCN等方法相结合,以更好地检测出新型恶意代码。















 1294
1294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











