







一、 实验目的
对 C 语言的一个子集设计并实现一个简单的词法分析器,掌握利用状态转换图设计词
法分析器的基本方法。
二、实验要求
利用该词法分析器完成对源程序字符串的词法分析。输出形式是源程序的单词符号二
元式的代码,并保存到文件中。
三、开发环境
硬件环境:PC机 windows10 64位
编程语言:C++
运行环境:VS
四、实验内容
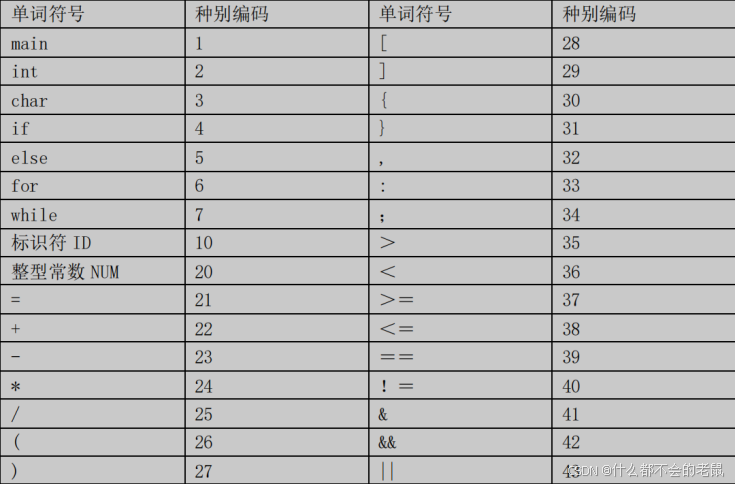
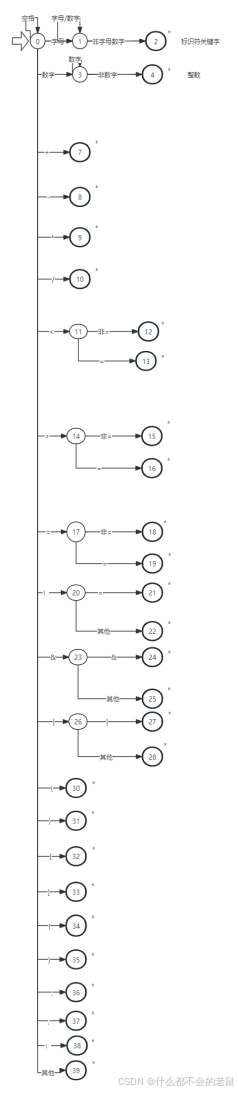
(1) 假设该语言中的单词符号及种别编码如下表所示。
单词符号及种别编码
(2) 五类符号
第一类:标识符 letter(letter | digit)* 无穷集
ID 和 NUM 的正规定义式为:
ID→letter(letter | didit)*
NUM→digit digit*
letter→a | … | z | A | … | Z
digit→ 0 | … | 9
第二类:常数 (digit)+ 无穷集
第三类:关键字 main int char if else for while
第四类:界符 ‘/*’、‘//’、 () { } [ ] " " ' , : ; 等
第五类:运算符 = + - * / & < <= > >= == != && ||、等
如果关键字、标识符和常数之间没有确定的算符或界符作间隔,则至少用一个空格作
间隔。空格由空白、制表符和换行符组成。
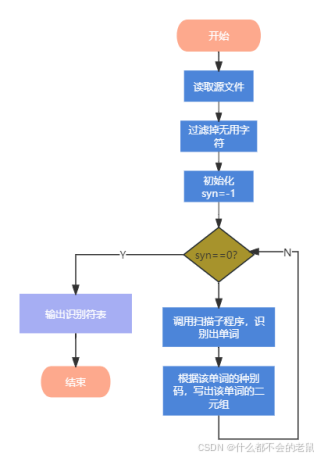
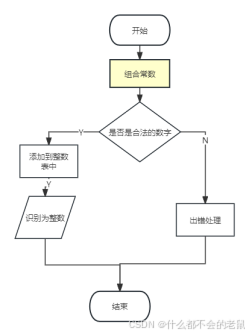
(3) 设计词法分析器的步骤:
①实验程序流程图:
②实验流程说明:
通过程序源文件读取文件内容,这里我加上了一个“$”代表文件结束的标识符,当文件中读取到“$”时,读取结束。
既然对文件内容的有效提取,当然不能缺少对文件的预处理,从头到尾进行扫描,去除注释的内容(去除//和/* */的内容),以及一些影响程序运行的符号(换行符、回车符、制表符等),空格此时当然不能去除,举个例子:int i=3;这个语句,如果去掉空格就变成了inti=3,就没有意义啦,所以此时预处理的时候空格不能去除。
经过前面两步(知道文件读取什么时候结束、对文件内容进行预处理),接下来就对源文件从头到尾进行扫描了,在扫描的时候首先看当前的字符是不是空格,如是空格,则继续扫描下一个字符,直到不是空格为止,然后再看该字符是不是字母,若是则进行标识符和关键字的识别,如是数字,则进行数字判断,否则对该字符的可能情况进行依次判断,如果将所有可能都走一遍还是没有确认该字符的身份,就认定其为错误符号,输出该错误符号然后结束。每次识别完一个单词后,单词都存储在token[]中,然后确定这个单词的种别码,最后进行下一个单词的识别。
然后利用程序对每次识别的种别码syn进行判断,对不同的单词种别做出不同的反应,对于标识符则将其插入标识符表中,对于关键字则输出该关键字的种别码和助记符,直到程序读取到“$”时,syn=0代表程序结束。
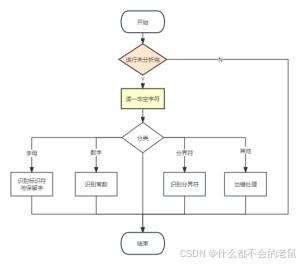
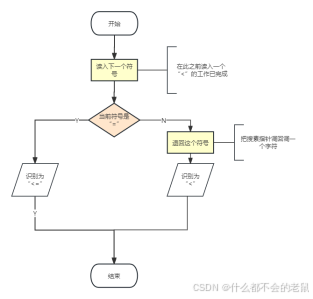
③子程序具体化流程图:
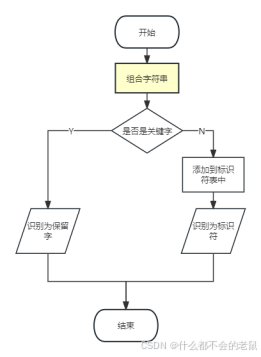
④标识符和保留字的识别流程图:
⑤识别标识符和保留字的子程序流程图:
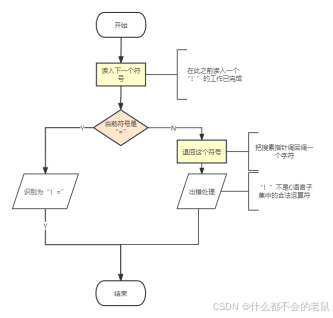
⑥程序编写注意事项的流程图:
(1)对于运算符“<=”的处理流程(“>=的处理方式同理”):
(2)对于运算符“!=”的处理流程:
⑦程序文件结构:
⑧状态转换图:
⑨主要代码段:
void Scanner(int& syn, char resourceProject[], char token[], int& pProject) {//根据DFA的状态转换图设计 int i, count = 0;//count用来做token[]的指示器,收集有用字符 char ch;//作为判断使用 ch = resourceProject[pProject]; while (ch == ' ') {//过滤空格,防止程序因识别不了空格而结束 pProject++; ch = resourceProject[pProject]; } for (i = 0; i < 20; i++) {//每次收集前先清零 token[i] = '\0'; } if (IsLetter(resourceProject[pProject])) {//开头为字母 token[count++] = resourceProject[pProject];//收集 pProject++;//下移 while (IsLetter(resourceProject[pProject]) || IsDigit(resourceProject[pProject])) {//后跟字母或数字 token[count++] = resourceProject[pProject];//收集 pProject++;//下移 }//多读了一个字符既是下次将要开始的指针位置 token[count] = '\0'; syn = searchReserve(reserveWord, token);//查表找到种别码 if (syn == -1) {//若不是保留字则是标识符 syn = 10;//标识符种别码 } return; } else if (IsDigit(resourceProject[pProject])) {//首字符为数字 while (IsDigit(resourceProject[pProject])) {//后跟数字 token[count++] = resourceProject[pProject];//收集 pProject++; }//多读了一个字符既是下次将要开始的指针位置 token[count] = '\0'; syn = 20;//常数种别码 } else if (ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == ';' || ch == '(' || ch == ')' || ch == '^' || ch == ',' || ch == '\"' || ch == '\'' || ch == '~' || ch == '#' || ch == '%' || ch == '[' || ch == ']' || ch == '{' || ch == '}' || ch == '\\' || ch == '.' || ch == '\?' || ch == ':') {//若为运算符或者界符,查表得到结果 token[0] = resourceProject[pProject]; token[1] = '\0';//形成单字符串 for (i = 0; i < 23; i++) {//查运算符界符表 if (strcmp(token, operatorOrDelimiter[i]) == 0) { syn = 21 + i;//获得种别码,使用了一点技巧,使之呈线性映射 break;//查到即推出 } } pProject++;//指针下移,为下一扫描做准备 return; } else if (resourceProject[pProject] == '<') {//<,<=,<< pProject++;//后移,超前搜索 if (resourceProject[pProject] == '=') { syn = 38; } else if (resourceProject[pProject] == '<') {//左移 pProject--; syn = 58; } else { pProject--; syn = 36; } pProject++;//指针下移 return; } else if (resourceProject[pProject] == '>') {//>,>=,>> pProject++; if (resourceProject[pProject] == '=') { syn = 37; } else if (resourceProject[pProject] == '>') { syn = 59; } else { pProject--; syn = 35; } pProject++; return; } else if (resourceProject[pProject] == '=') {//=.== pProject++; if (resourceProject[pProject] == '=') { syn = 39; } else { pProject--; syn = 21; } pProject++; return; } else if (resourceProject[pProject] == '!') {//!,!= pProject++; if (resourceProject[pProject] == '=') { syn = 40; } else { syn = 68; pProject--; } pProject++; return; } else if (resourceProject[pProject] == '&') {//&,&& pProject++; if (resourceProject[pProject] == '&') { syn = 42; } else { pProject--; syn = 41; } pProject++; return; } else if (resourceProject[pProject] == '|') {//|,|| pProject++; if (resourceProject[pProject] == '|') { syn = 43; } else { pProject--; syn = 54; } pProject++; return; } else if (resourceProject[pProject] == '$') {//结束符 syn = 0;//种别码为0 } else {//不能被以上词法分析识别,则出错。 printf("error:there is no exist %c \n", ch); exit(0); } }⑩实验运行与测试
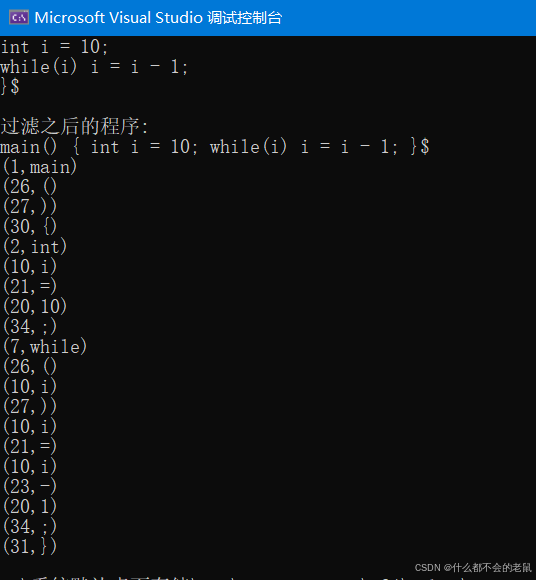
测试程序(rc.txt):
测试运行结果:
输出二元组保存文件结果(compile.txt与标准结果一致):
五、完整代码
// CIFA_ANALYZE.cpp : 定义控制台应用程序的入口点。 // #include "stdio.h" #include "stdlib.h" #include "string.h" #include "iostream" using namespace std; #define _CRT_SECURE_NO_WARNINGS 1 //#define MAXLENGTH 255 /* 一行允许的字符个数 */ //词法分析程序 //首先定义种别码 /* 第一类:标识符 letter(letter | digit)* 无穷集 第二类:常数 (digit)+ 无穷集 第三类:关键字(7) main int char if else for while 第四类:界符 ‘/*’、‘//’、 () { } [ ] " " ' 第五类:运算符 <、<=、>、>=、=、+、-、*、/、^、 对所有可数符号进行编码: ($, 0) (main, 1) (int, 2) (char, 3) (if, 4) (else, 5) (for, 6) (while, 7) (标识符ID, 10) (整型常数NUM, 20) (=, 21) (+, 22) (-, 23) (*, 24) (/ , 25) ((, 26) (), 27) ([, 28) (], 29) ({ ,30) (}, 31) (, , 32) (:, 33) (;,34) (>,35) (<,36) (>=,37) (<=,38) (==,39) (!=,40) (&,41) (&&,42) (||,43) */ /****************************************************************************************/ //全局变量,保留字表 static char reserveWord[7][20] = { "main", "int", "char", "if", "else", "for", "while" }; //界符运算符表,根据需要可以自行增加 static char operatorOrDelimiter[23][10] = { "=", "+", "-", "*", "/", "(", ")", "[", "]", "{", "}", ",", ":", ";", ">", "<", ">=", "<='", "==", "!=", "&", "&&", "||" }; static char IDentifierTbl[1000][50] = { "" };//标识符表 /****************************************************************************************/ /********查找保留字*****************/ int searchReserve(char reserveWord[][20], char s[]) { for (int i = 0; i < 7; i++) { if (strcmp(reserveWord[i], s) == 0) {//若成功查找,则返回种别码 return i + 1;//返回种别码 } } return -1;//否则返回-1,代表查找不成功,即为标识符 } /********查找保留字*****************/ /*********************判断是否为字母********************/ bool IsLetter(char letter) {//注意C语言允许下划线也为标识符的一部分可以放在首部或其他地方 if (letter >= 'a' && letter <= 'z' || letter >= 'A' && letter <= 'Z' || letter == '_') { return true; } else { return false; } } /*********************判断是否为字母********************/ /*****************判断是否为数字************************/ bool IsDigit(char digit) { if (digit >= '0' && digit <= '9') { return true; } else { return false; } } /*****************判断是否为数字************************/ /********************编译预处理,取出无用的字符和注释**********************/ void filterResource(char r[], int pProject) { char tempString[10000]; int count = 0; for (int i = 0; i <= pProject; i++) { if (r[i] == '/' && r[i + 1] == '/') {//若为单行注释“//”,则去除注释后面的东西,直至遇到回车换行 while (r[i] != '\n') { i++;//向后扫描 } } if (r[i] == '/' && r[i + 1] == '*') {//若为多行注释“/* 。。。*/”则去除该内容 i += 2; while (r[i] != '*' || r[i + 1] != '/') { i++;//继续扫描 if (r[i] == '$') { printf("注释出错,没有找到 */,程序结束!!!\n"); exit(0); } } i += 2;//跨过“*/” } if (r[i] != '\n' && r[i] != '\t' && r[i] != '\v' && r[i] != '\r') {//若出现无用字符,则过滤;否则加载 tempString[count++] = r[i]; } } tempString[count] = '\0'; strcpy(r, tempString);//产生净化之后的源程序 } /********************编译预处理,取出无用的字符和注释**********************/ /****************************分析子程序,算法核心***********************/ void Scanner(int& syn, char resourceProject[], char token[], int& pProject) {//根据DFA的状态转换图设计 int i, count = 0;//count用来做token[]的指示器,收集有用字符 char ch;//作为判断使用 ch = resourceProject[pProject]; while (ch == ' ') {//过滤空格,防止程序因识别不了空格而结束 pProject++; ch = resourceProject[pProject]; } for (i = 0; i < 20; i++) {//每次收集前先清零 token[i] = '\0'; } if (IsLetter(resourceProject[pProject])) {//开头为字母 token[count++] = resourceProject[pProject];//收集 pProject++;//下移 while (IsLetter(resourceProject[pProject]) || IsDigit(resourceProject[pProject])) {//后跟字母或数字 token[count++] = resourceProject[pProject];//收集 pProject++;//下移 }//多读了一个字符既是下次将要开始的指针位置 token[count] = '\0'; syn = searchReserve(reserveWord, token);//查表找到种别码 if (syn == -1) {//若不是保留字则是标识符 syn = 10;//标识符种别码 } return; } else if (IsDigit(resourceProject[pProject])) {//首字符为数字 while (IsDigit(resourceProject[pProject])) {//后跟数字 token[count++] = resourceProject[pProject];//收集 pProject++; }//多读了一个字符既是下次将要开始的指针位置 token[count] = '\0'; syn = 20;//常数种别码 } else if (ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == ';' || ch == '(' || ch == ')' || ch == '^' || ch == ',' || ch == '\"' || ch == '\'' || ch == '~' || ch == '#' || ch == '%' || ch == '[' || ch == ']' || ch == '{' || ch == '}' || ch == '\\' || ch == '.' || ch == '\?' || ch == ':') {//若为运算符或者界符,查表得到结果 token[0] = resourceProject[pProject]; token[1] = '\0';//形成单字符串 for (i = 0; i < 23; i++) {//查运算符界符表 if (strcmp(token, operatorOrDelimiter[i]) == 0) { syn = 21 + i;//获得种别码,使用了一点技巧,使之呈线性映射 break;//查到即推出 } } pProject++;//指针下移,为下一扫描做准备 return; } else if (resourceProject[pProject] == '<') {//<,<=,<< pProject++;//后移,超前搜索 if (resourceProject[pProject] == '=') { syn = 38; } else if (resourceProject[pProject] == '<') {//左移 pProject--; syn = 58; } else { pProject--; syn = 36; } pProject++;//指针下移 return; } else if (resourceProject[pProject] == '>') {//>,>=,>> pProject++; if (resourceProject[pProject] == '=') { syn = 37; } else if (resourceProject[pProject] == '>') { syn = 59; } else { pProject--; syn = 35; } pProject++; return; } else if (resourceProject[pProject] == '=') {//=.== pProject++; if (resourceProject[pProject] == '=') { syn = 39; } else { pProject--; syn = 21; } pProject++; return; } else if (resourceProject[pProject] == '!') {//!,!= pProject++; if (resourceProject[pProject] == '=') { syn = 40; } else { syn = 68; pProject--; } pProject++; return; } else if (resourceProject[pProject] == '&') {//&,&& pProject++; if (resourceProject[pProject] == '&') { syn = 42; } else { pProject--; syn = 41; } pProject++; return; } else if (resourceProject[pProject] == '|') {//|,|| pProject++; if (resourceProject[pProject] == '|') { syn = 43; } else { pProject--; syn = 54; } pProject++; return; } else if (resourceProject[pProject] == '$') {//结束符 syn = 0;//种别码为0 } else {//不能被以上词法分析识别,则出错。 printf("error:there is no exist %c \n", ch); exit(0); } } int main() { //打开一个文件,读取其中的源程序 char resourceProject[10000]; char token[20] = { 0 }; int syn = -1, i;//初始化 int pProject = 0;//源程序指针 FILE* fp=NULL,* fp1=NULL; if ((fp = fopen("rc.txt", "r")) == NULL) {//打开源程序 cout << "can't open this file"; exit(0); } resourceProject[pProject] = fgetc(fp); while (resourceProject[pProject] != '$') {//将源程序读入resourceProject[]数组 pProject++; resourceProject[pProject] = fgetc(fp); } resourceProject[++pProject] = '\0'; fclose(fp); cout << endl << "源程序为:" << endl; cout << resourceProject << endl; //对源程序进行过滤 filterResource(resourceProject, pProject); cout << endl << "过滤之后的程序:" << endl; cout << resourceProject << endl; pProject = 0;//从头开始读 if ((fp1 = fopen("compile.txt", "w+")) == NULL) {//打开源程序 cout << "can't open this file"; exit(0); } while (syn != 0) { //启动扫描 Scanner(syn, resourceProject, token, pProject); if (syn == 10) {//标识符 for (i = 0; i < 1000; i++) {//插入标识符表中 if (strcmp(IDentifierTbl[i], token) == 0) {//已在表中 break; } if (strcmp(IDentifierTbl[i], "") == 0) {//查找空间 strcpy_s(IDentifierTbl[i], token); break; } } printf("(%d,%s)\n", syn,token); fprintf(fp1, "(%d,%s)\n", syn,token); } else if (syn >= 1 && syn <= 7) {//保留字 printf("(%d,%s)\n", syn,reserveWord[syn - 1]); fprintf(fp1, "(%d,%s)\n", syn,reserveWord[syn - 1]); } else if (syn == 20) {//const 常数 printf("(%d,%s)\n", syn,token); fprintf(fp1, "%d,%s)\n", syn,token); } else if (syn >= 21 && syn <= 43) { printf("(%d,%s)\n", syn,operatorOrDelimiter[syn - 21]); fprintf(fp1, "(%d,%s)\n", syn,operatorOrDelimiter[syn - 21]); } } for (i = 0; i < 1000; i++) {//插入标识符表中 if (IDentifierTbl[i] == NULL) { printf("第%d个标识符: %s\n", i + 1, IDentifierTbl[i]); } if (IDentifierTbl[i] == NULL) { fprintf(fp1, "第%d个标识符: %s\n", i + 1, IDentifierTbl[i]); } } fclose(fp1); return 0; }




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









