



好久没写文章了,今天有时间更新一下吧,稍微看了一下某易云最新的JS加密:
首先是歌曲:先过滤出
/player/url/v1
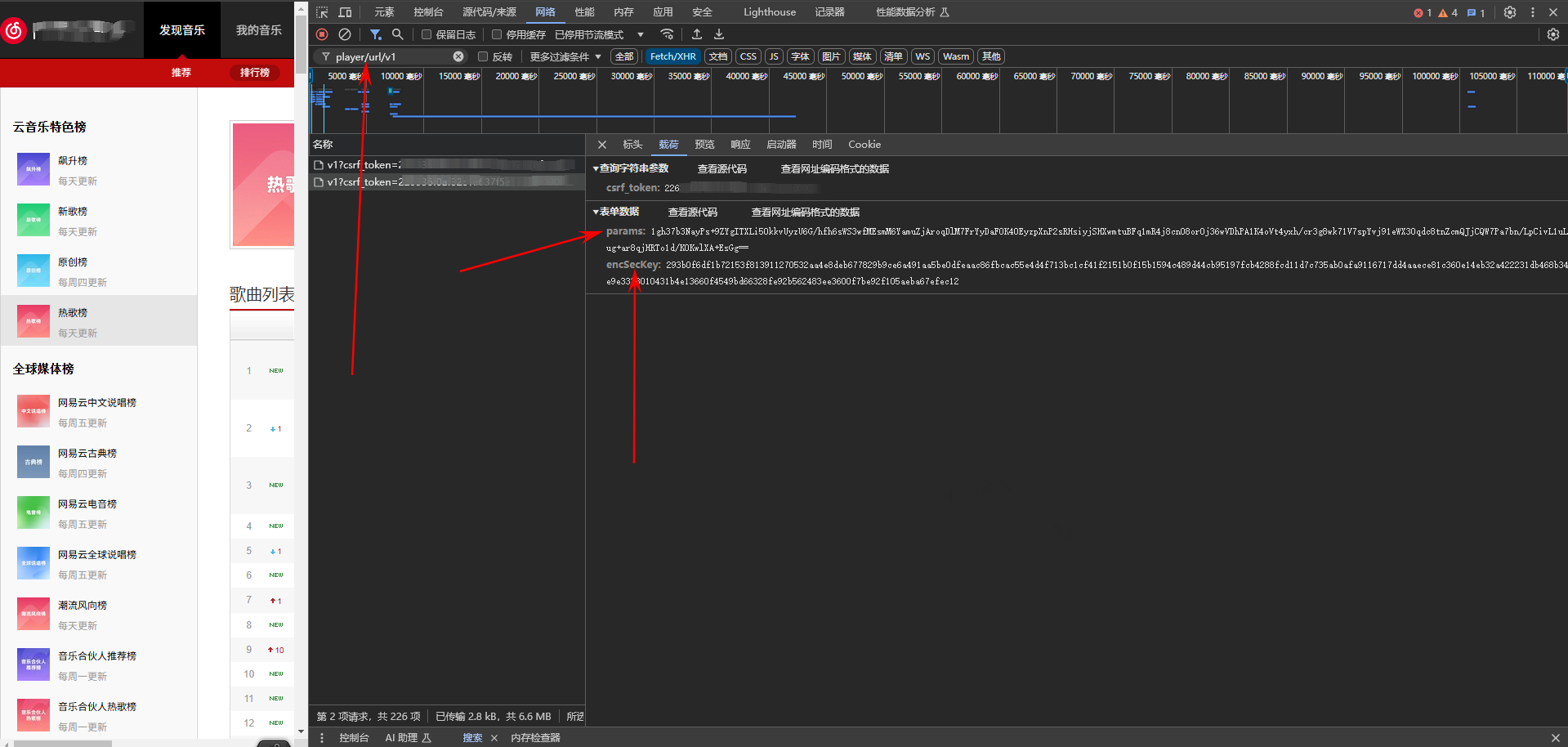
params和encSecKey是两个关键字段,那么我们先来打断点找到这个加密混淆起始的地方,
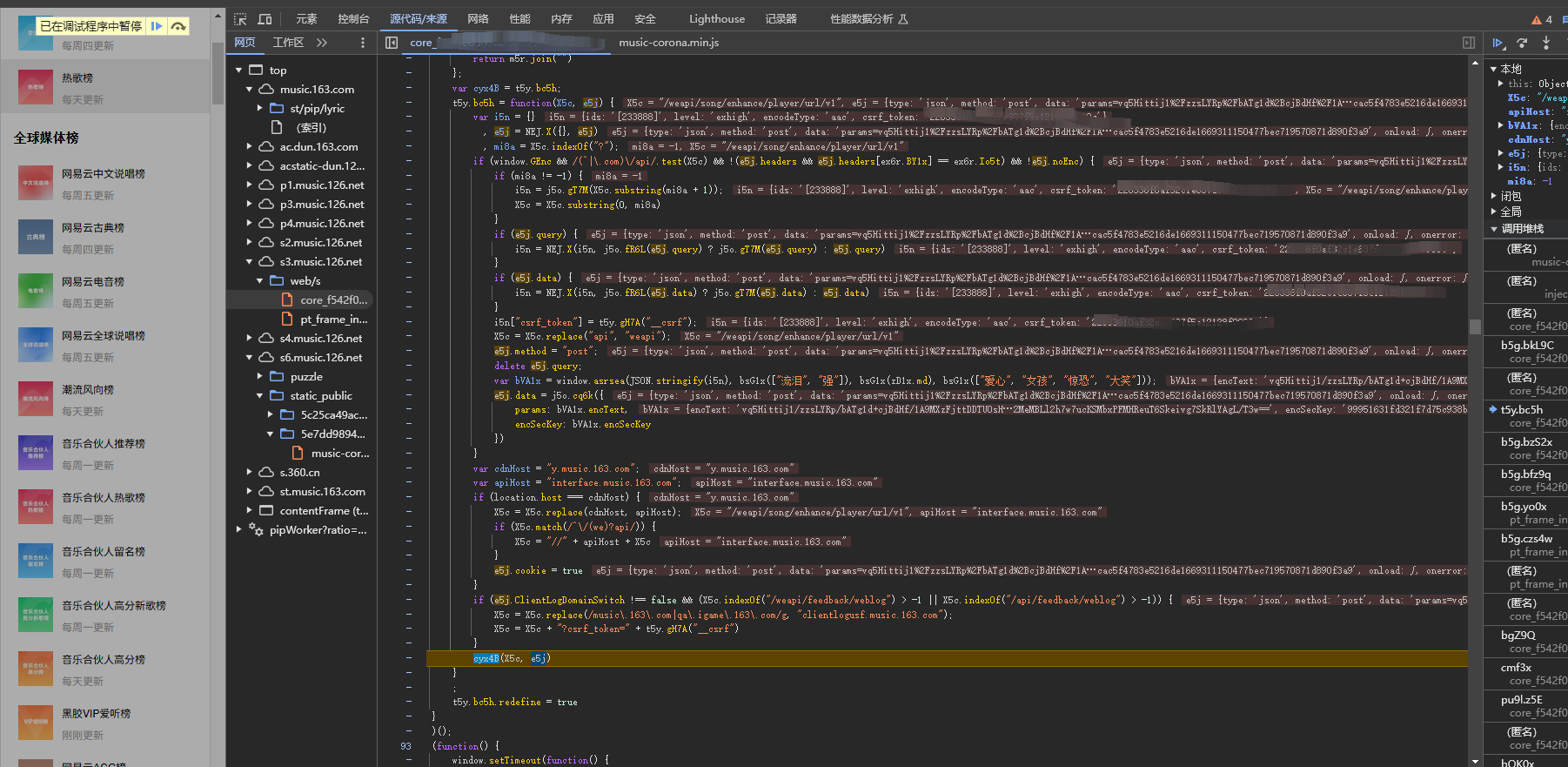
控制台看一下果然是是这里
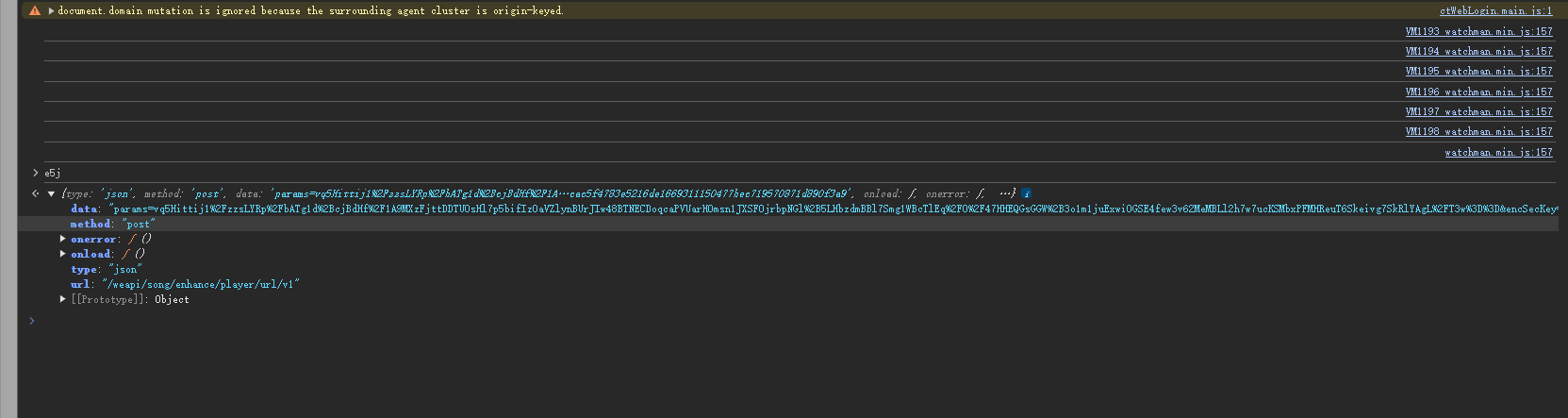
分析了一下后脱机算法写出来:
const crypto = require("crypto");
const presetKey = "0CoJUm6Qyw8W8jud";
const iv = "0102030405060708";
const pubKey = "010001";
const modulus =
"00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725" +
"152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312" +
"ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424" +
"d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8" +
"e7";
function aesEncrypt(text, key) {
const cipher = crypto.createCipheriv("aes-128-cbc", key, iv);
cipher.setAutoPadding(true);
return cipher.update(text, "utf8", "base64") + cipher.final("base64");
}
function rsaEncrypt(text) {
text = text.split("").reverse().join("");
const hexText = Buffer.from(text).toString("hex");
const bigIntText = BigInt("0x" + hexText);
const bigIntPubKey = BigInt("0x" + pubKey);
const bigIntModulus = BigInt("0x" + modulus);
const encrypted = bigIntText ** bigIntPubKey % bigIntModulus;
return encrypted.toString(16).padStart(256, "0");
}
function createSecretKey(size) {
const chars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
let key = "";
for (let i = 0; i < size; i++) {
key += chars.charAt(Math.floor(Math.random() * chars.length));
}
return key;
}
function weapi(data) {
const text = JSON.stringify(data);
const secKey = createSecretKey(16);
const firstPass = aesEncrypt(text, presetKey);
const params = aesEncrypt(firstPass, secKey);
const encSecKey = rsaEncrypt(secKey);
return { params, encSecKey };
}
// 主入口:命令行调用时返回 JSON
if (require.main === module) {
const input = process.argv[2]; // 接收 JSON 字符串
const data = JSON.parse(input);
console.log(JSON.stringify(weapi(data)));
}
module.exports = weapi;
再写一个程序调用这段js:
import subprocess
import json
import requests
# ====== 调用 Node.js weapi.js 脚本 ======
def get_weapi_params(data: dict):
process = subprocess.run(
["node", "weapi.js", json.dumps(data, ensure_ascii=False)],
capture_output=True,
text=True,
check=True
)
return json.loads(process.stdout)
# ====== 构造 payload(关键!) ======
def build_song_payload(song_id: int, csrf: str = "") -> dict:
return {
"ids": f"[{song_id}]",
"level": "exhigh",
"encodeType": "aac",
"csrf_token": csrf
}
# ====== 发请求 ======
def get_song_url(song_id: int):
csrf_token = "替换成你自己的"
# 1. 构造 payload
payload = build_song_payload(song_id, csrf=csrf_token)
# 2. weapi 加密
crypto_data = get_weapi_params(payload)
cookies = {
"__csrf": csrf_token,
"MUSIC_U": "替换成你自己的"
}
headers = {
"Content-Type": "application/x-www-form-urlencoded",
"Referer": "https://music.163.com/",
"Origin": "https://music.163.com",
"User-Agent": "Mozilla/5.0"
}
# 3. 请求接口
resp = requests.post(
"https://music.163.com/weapi/song/enhance/player/url/v1",
data=crypto_data,
headers=headers,
cookies=cookies,
params={"csrf_token": csrf_token}
)
try:
return resp.json()
except Exception:
print(resp.text)
return None
# ====== 示例调用(数字是歌曲ID) ======
print(get_song_url(这里添加数字))
也是能跑的:
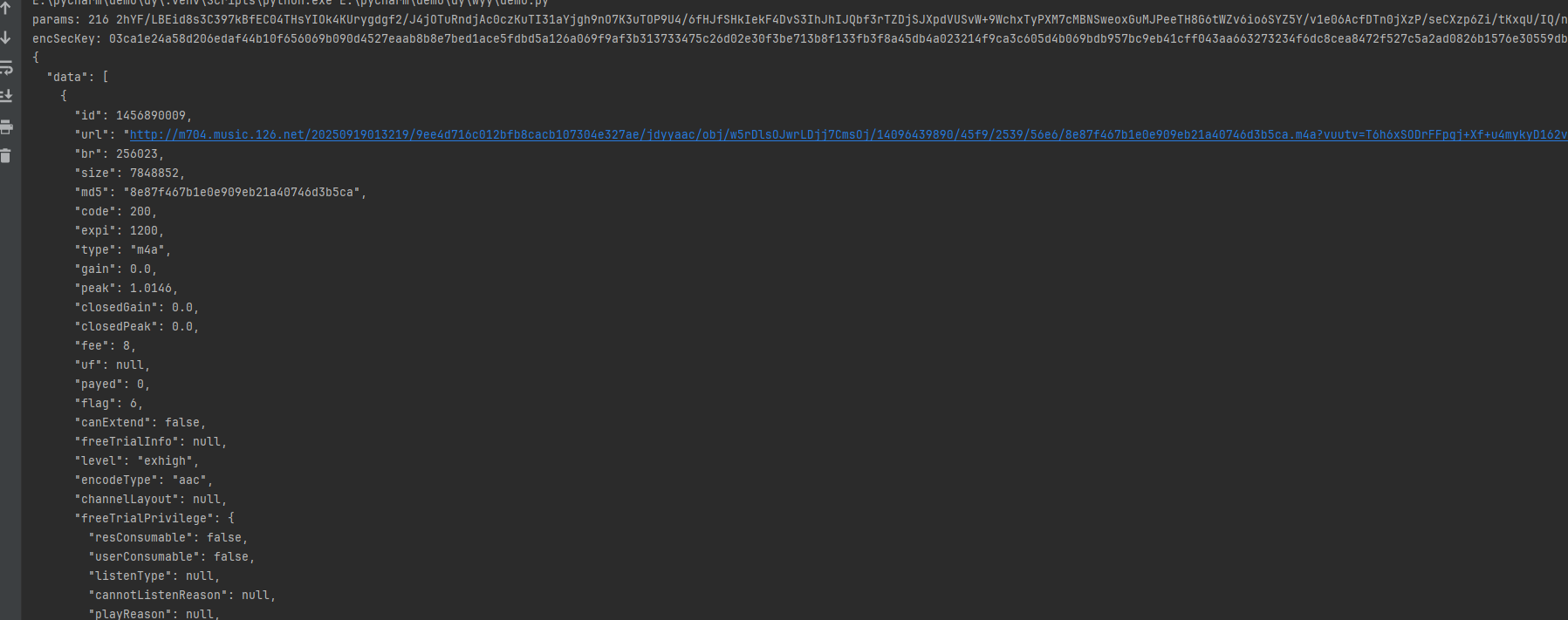
点击连接也是听到了《罗生门》,这里我只是演示就不批量了。
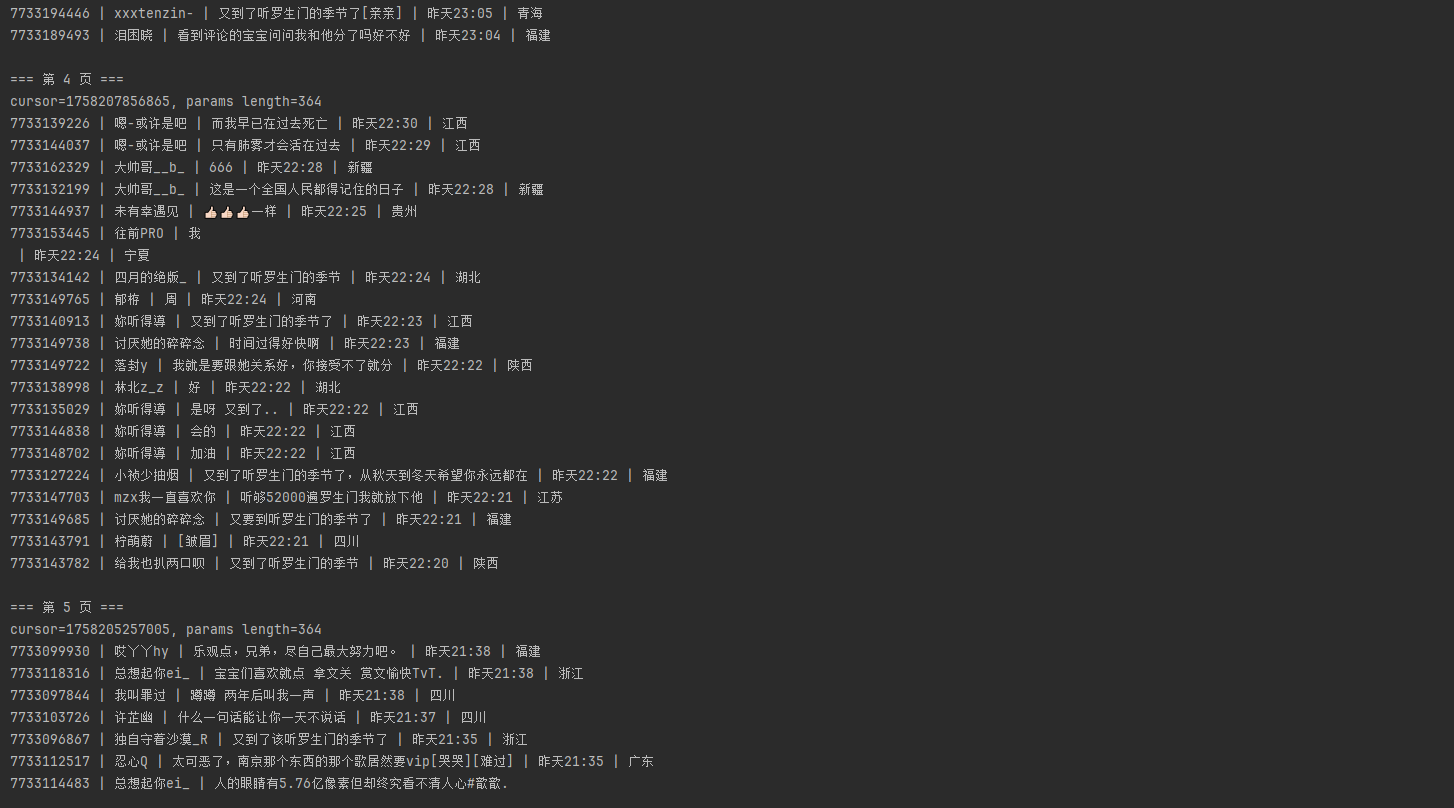
全部评论:
这里我要说下,歌曲的params是216位,评论的params是364位。这是因为传入的参数不同。

废话不多说直接上代码:
import subprocess
import json
import requests
import time
# 调用 js 脚本生成 params + encSecKey
def get_weapi_params(data: dict):
process = subprocess.run(
["node", "weapi.js", json.dumps(data)],
capture_output=True,
text=True,
check=True
)
return json.loads(process.stdout)
def get_nickname(comment):
user = comment.get("user") or {}
return user.get("nickname") or user.get("name")
def get_comments(song_id, cursor, page_size, page_no):
url = "https://music.163.com/weapi/comment/resource/comments/get"
data = {
"rid": f"R_SO_4_{song_id}",
"threadId": f"R_SO_4_{song_id}",
"pageNo": page_no, # 页码
"pageSize": page_size,
"cursor": cursor,
"offset": (page_no - 1) * page_size,
"orderType": 1,
"csrf_token": "替换你自己的",
}
crypto_data = get_weapi_params(data)
headers = {
"Content-Type": "application/x-www-form-urlencoded",
"Referer": "https://music.163.com/",
"Origin": "https://music.163.com",
"User-Agent": "Mozilla/5.0"
}
cookies = {
'MUSIC_U': '替换你自己的',
'__csrf': '替换你自己的',
}
resp = requests.post(url, data=crypto_data, headers=headers, cookies=cookies)
return resp.json(), crypto_data
resp = requests.post(url, data=crypto_data, headers=headers)
return resp.json(), crypto_data
if __name__ == "__main__":
song_id = 1456890009 #歌曲ID
cursor = -1
page_size = 20
page_no = 1
for _ in range(5):
result, crypto_data = get_comments(song_id, cursor, page_size, page_no)
print(f"\n=== 第 {page_no} 页 ===")
print(f"cursor={cursor}, params length={len(crypto_data['params'])}")
comments = result.get("data", {}).get("comments", [])
if not comments:
print("没有评论了。")
break
# 只打印想要的字段
for c in comments:
location = c.get("ipLocation", {}).get("location")
name = get_nickname(c)
print(f"{c.get('commentId')} | {name} | {c.get('content')} | {c.get('timeStr')} | {location}")
# 更新 cursor
cursor = result.get("data", {}).get("cursor")
page_no += 1
time.sleep(1)
这里我只跑5页:
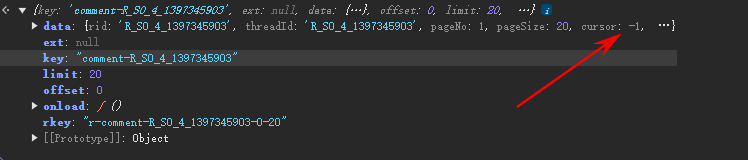
这个cursor就很有意思第一次请求是-1而后面会根据第一次返回的时间戳来请求:
第一次:
第二次:


















 5714
5714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









