



系列文章目录
主要介绍头插法、尾插法、遍历、
废话篇:
在开始今天的内容之前,请允许我向大家让我来个自我介绍(不允许也没关系,因为这是我的号!哈哈哈!)
消失的这一年里,相信没人想我(哈哈哈,这一点我还是有自知之明的)。那我去干嘛了呢!哈哈,那当然去读书了,没让我的粉丝失望,我以专业课全年级第一,平时分满分的成绩完成自己机械专业的学习.

于是,我为了完成自己的梦想。自己贷款去报培训班 。培训嵌入式相关技能。并完成第一阶段的考试。成绩并不是很理想。确实竞争压力太大 。和我同培训机构的同学九成以是科班出生。有些事在竞赛队里拿过奖项的进培训班深化的队员,还有一些是在企业已经工作几年后再来报培训渴望高薪的队员。
承认压力很大,但很有动力。因为不同于自学,这样的学习能让我看到差距。也让我看到自己真实的差距。我在机械专看不到我的弱点,这是很可怕的事情。
我现在跟自己说的最多的一句话是:“宁可把每一步走深走实在,也不要走的远。过程很痛苦,但我想这一切的意义
在开始之前,我想跟大家说一件可能会让大家心情堵塞的事情,我头像的“鹅学长”被校管理员抓过去给煮了(555~)

但是,我们的鹅学长是不会离开我们的,因为人在号在,人不在号还在。所以接下来开始正式的链表知识的攻克。
GO!GO!GO!出发喽
前言:
随着学习的深入,我也被培训班的Tony老师带入到“C语言”高级领域当中,表示明显跟不上。但Tony老师的一句话说的让我感觉很有希望:“别看我在讲台上行云流水,你是没看我私底下深耕的样子”。
那么既然如此,就和笔者一起进入:“链表的世界”
会写的很详细,目的也是为了让我自己以后可以看的很方便。其次也加深理解。
一、链表是什么?
概念:
链表的基本概念
链表是一种线性数据结构,由一系列节点(Node)组成,每个节点包含两部分:数据域(存储数据)和指针域(存储指向下一个节点的地址)。与数组不同,链表在内存中无需连续存储,通过指针实现动态连接。
/* 单向链表节点定义*/
struct Node
{
int data;
struct Node* next;
};
/* 创建新节点*/
struct Node* createNode(int data)
{
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
请问呢?你看懂了吗?
 (我表示没看懂!)
(我表示没看懂!)
起初我以为链表是像数组、指针、枚举那样是内嵌在C语言的基本类型。
可后来发现这压根不是。用人话表示就是。他是人发明出来的工具。
下面👇这是链表这位爷的发展历史。
链表的概念起源
链表作为一种数据结构,其核心思想可追溯至1955-1956年。艾伦·纽维尔(Allen Newell)、克里夫·肖(Cliff Shaw)和赫伯特·西蒙(Herbert A. Simon)在开发“逻辑理论家”(Logic Theorist)程序时首次提出链式存储的概念,用于实现动态内存分配和灵活的数据组织。
尽管数组因缓存友好性更受青睐,链表在动态插入/删除操作中仍不可替代。例如,Linux内核的进程调度和文件系统依赖链表管理可变长度的数据结构。
链表的发展反映了计算机科学对灵活性与效率的持续追求,其历史演进与硬件进步和算法创新紧密交织。
(看完这些,你们明白了吗?)
这就是一种数据结构,是一种思想。不是C语言里面的什么东西。说白了他是管理数据用的。明白了不?
你可以想象成一节又一节的车厢(注意:这里不是火车的车厢,因为火车的车厢是车头带)。这里的车厢是每一节都会动。他的动力源是结构体类型的指针“next”。至于为甚么他为什么是动力源。笔者会在下面解释
好!我们看这段代码!
/* 单向链表节点定义*/
struct Node
{
int data;
struct Node* next;
};
/* 创建新节点*/
struct Node* createNode(int data)
{
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
请问呢?你看懂了吗?
相信在这里就有很多信誓旦旦的友友们会跳出来说~
(报告长官!这是定义链表的函数,通过这段函数我们就能利用链表来管理数据了!)
是的!没错!就是因为我是这么想的,所以我弃坑了一年转去学机械了。因为链表我是真的搞不懂。可上培训班之后我知道了。
这个想法是错误的!记住是错误的!


链表是你女朋友!是你女朋友!既要管饭也要管饱!还要管哄!
(拿着上面的具体含义是什么呢?)
我来告诉你!
- 首先看这段代码
/* 单向链表节点定义*/
struct Node
{
int data;
struct Node* next;
};这是在定义一个结构体,告诉编译器要用这种格式定义一个数据。具体什么数据这里不去说!
(我也可以提前告诉你:这个在告诉编译器你要以这样的格式,定义一个链表其中一个节点!)
相当于你是是老板,你告诉一名车厢的装货工人(这个工人就是编译器),左边装货物(数据),右边装发动机(指向下一个节点的指针)

因为只有这样才能让车厢(这里的车厢就是链表的节点),自己跑起来(才能让链表节点指向下个节点)
接下来看具体步骤
二、使用步骤
0.给这个结构体换个名字
(那你们就要问了?老铁,拿什么换!)
答案:typedef
(对于 typedef 具体怎么用这个不用管!要真相管,我就具体和你说说!)
typedef struct Node
{
int date;
struct Node* next;
}Date_t, * Dext_t;“typedef”在这里相当于给“struct Node”换了个名字。就像你妈会叫你“崽崽”、“宝宝”、“乖乖”再或者“败家子”(是的!我妈就叫我“败家子”!)
这些名字不是你的真名,但的的确确能代表你。为了方便理解,我再把结构体这么写
typedef struct Node
{
int date;
struct Node* next;
}GouDan, * ErMaZi;
/*
*GouDan的意思是狗蛋,* ErMaZi的意思是二麻子。都能代表struct Node。
*到后面想用“struct Node”的时候就直接用 GouDan, * ErMaZi!
*/
1.定义头节点
代码如下:
/* 创建头节点*/
struct Node* createNode(int data)
{
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
Date_t* createNode(int data)
{
/* 分配内存空间给新节点 */
Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));
/* 将传入的数据赋值给新节点的数据域 */
newNode->data = data;
/* 将新节点的指针域设置为NULL,表示当前没有下一个节点 */
newNode->next = NULL;
/* 返回新创建的节点 */
return newNode;
}
甚至还可以这么写
GouDan* createNode(int data)
{
/* 分配内存空间给新节点 */
GouDan* newNode = (GouDan*)malloc(sizeof(GouDan Node));
/* 将传入的数据赋值给新节点的数据域 */
newNode->data = data;
/* 将新节点的指针域设置为NULL,表示当前没有下一个节点 */
newNode->next = NULL;
/* 返回新创建的节点 */
return newNode;
}但为了安全起见我们基于第二种方式,加上一个“if”判断。
用于安排那段堆空间--[malloc()开辟失败的情况]
如下:
Date_t* createNode(int data)
{
/* 分配内存空间给新节点 */
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
/* 检查内存分配是否成功 */
if (newNode == NULL)
{
printf("内存分配失败\n");
exit(1);
}
/* 将传入的数据赋值给新节点的数据域 */
newNode->data = data;
/* 将新节点的指针域设置为NULL,表示当前没有下一个节点 */
newNode->next = NULL;
/* 返回新创建的节点 */
return newNode;
}
但我喜欢这么写,这样方便排查改错
(把“createNode”改成“InitList”)
/*初始化一个节点*/
Date_t* InitList(int date)
{
/* 分配内存空间给头节点 */
Date_t* head = (Date_t*)malloc(sizeof(Date_t));
/* 检查内存分配是否成功 */
if (head == NULL)
{
/* 打印内存分配失败信息 */
printf("Memory allocation failed\n");
/* 返回NULL */
return NULL;
}
/* 将传入的数据赋值给头节点的数据域 */
head->date = date;
/* 将头节点的指针域设置为NULL,表示当前没有下一个节点 */
head->next = NULL;
/* 返回初始化后的头节点 */
return head;
}
但在这里有没有发现,为什么?
“Date_t* head = (Date_t*)malloc(sizeof(Date_t));”中的sizeof(* Dete_t)而不是 sizeof(Dext_t);
因为在C语言中,使用
malloc动态分配内存时,sizeof运算符的两种常见写法存在差异:
sizeof(Date_t)是结构体类型,开辟的堆空间大小设计这个结构体的大小,能保证数据域又足够大的空间来装数据。
sizeof(Daxe_t)而 “
sizeof(Daxe_t)”是指针类型指针类型的大小只和操作系统的大小有关
- 32位系统:指针通常为4字节。
- 64位系统:指针通常为8字节
- (特殊架构或嵌入式系统可能有例外)如果是
换言之如果是“sizeof( Dext_t)”那么这里就是4字节(32位操作系统),这明显对于存储整个结构体类型的数据是远远不够的。
恭喜你!这里我们成功申请了第一个头节点
但......别开心的太早。

因为这是你女朋友,你管了他饭,还得管饱!
2.插入数据
这里插入数据分为:
- 头部插入法(俗称:头插)
- 尾部插入法(俗称:尾插)
为了方便理解,我这里就先说尾插
2.1、尾插
代码如下:
/*
* 链表尾插操作
* @param head 链表头指针
* @param date 要插入的数据
* @return 更新后的链表头指针,内存分配失败时返回原头指针
*/
/* 定义链表尾插函数 */
Date_t* LinkList(Date_t* head, int date)
{
/* 检查链表是否为空 */
if (head == NULL)
{
/* 如果链表为空,调用InitList初始化新节点并返回 */
return InitList(date);
}
/* 为新节点分配内存空间 */
Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));
/* 检查内存分配是否失败 */
if (newNode == NULL)
{
/* 输出内存分配失败信息 */
printf("Memory allocation failed\n");
/* 返回原头指针,不改变链表结构 */
return head;
}
/* 设置新节点的数据域 */
newNode->date = date;
/* 将新节点的指针域置空 */
newNode->next = NULL;
/* 创建当前节点指针并指向头节点 */
Date_t* current = head;
/* 遍历链表直到最后一个节点 */
while (current->next != NULL)
{
/* 移动当前指针到下一个节点 */
current = current->next;
}
/* 将新节点链接到链表末尾 */
current->next = newNode;
/* 返回更新后的链表头指针 */
return head;
}
看到这里相信打家大多数是这个表情

(这是什么?)
不急!为了方便大家理解我来给你们写注释,把这个代码分为四块!
- 首先看第一块
/* 检查链表是否为空 */
if (head == NULL)
{
/* 如果链表为空,调用InitList初始化新节点并返回 */
return InitList(date);
}这里说的是一种极端情况说在“main”函数是头节点申请失败,没有头节点怎么办。也就是整个链表为空的情况怎么办,所以我们就再调用一次函数 “InitList(date)” 来申请“头节点”
申请成功就进行下一句
- 然后第二块
/* 为新节点分配内存空间 */
Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));
/* 检查内存分配是否失败 */
if (newNode == NULL)
{
/* 输出内存分配失败信息 */
printf("对不起!尾部节点堆空间申请失败!~\n");
/* 返回原头指针,不改变链表结构 */
return head;
}
/* 设置新节点的数据域 */
newNode->date = date;
/* 将新节点的指针域置空 */
newNode->next = NULL;看到这里大家发现没有,这一段是不是和 函数 “InitList(date)”
/*初始化一个节点*/
Date_t* InitList(int date)
{
/* 分配内存空间给头节点 */
Date_t* head = (Date_t*)malloc(sizeof(Date_t));
/* 检查内存分配是否成功 */
if (head == NULL)
{
/* 打印内存分配失败信息 */
printf("对不起!头节点堆空间申请失败!\n");
/* 返回NULL */
return NULL;
}
/* 将传入的数据赋值给头节点的数据域 */
head->date = date;
/* 将头节点的指针域设置为NULL,表示当前没有下一个节点 */
head->next = NULL;
/* 返回初始化后的头节点 */
return head;
}注意:
/* 将传入的数据赋值给头节点的数据域 */ head->date = date; /* 将头节点的指针域设置为NULL,表示当前没有下一个节点 */ head->next = NULL;这里的语句不是,把我们新定义的这个指针移动到下一个值哈!这里只是调用之前定义的结构体来进行一个节点的创造哈。如下
typedef struct Node { int date; struct Node* next; }Date_t, * Dext_t;
还有一个疑问,这唯一不同的就是
- 函数里 LinkList(date):
/* 检查内存分配是否失败 */ if (newNode == NULL) { /* 输出内存分配失败信息 */ printf("对不起!尾部节点堆空间申请失败!~\n"); /* 返回原头指针,不改变链表结构 */ return head; }
- 函数:InitList(date)
/* 检查内存分配是否成功 */ if (head == NULL) { /* 打印内存分配失败信息 */ printf("对不起!头节点堆空间申请失败!\n"); /* 返回NULL */ return NULL; }
其他的都如出一辙,都是在调用下面这个格式
typedef struct Node { int date; struct Node* next; }Date_t, * Dext_t;
只是一直在赋值罢了
或许你们要问?
为什么要这么做?
我上面不是已经通过 函数 “ InitList(date) ”定义了一个节点了吗?为什么还要在函数 LinkList(date) 里。再重新定义一遍呀?看图
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇
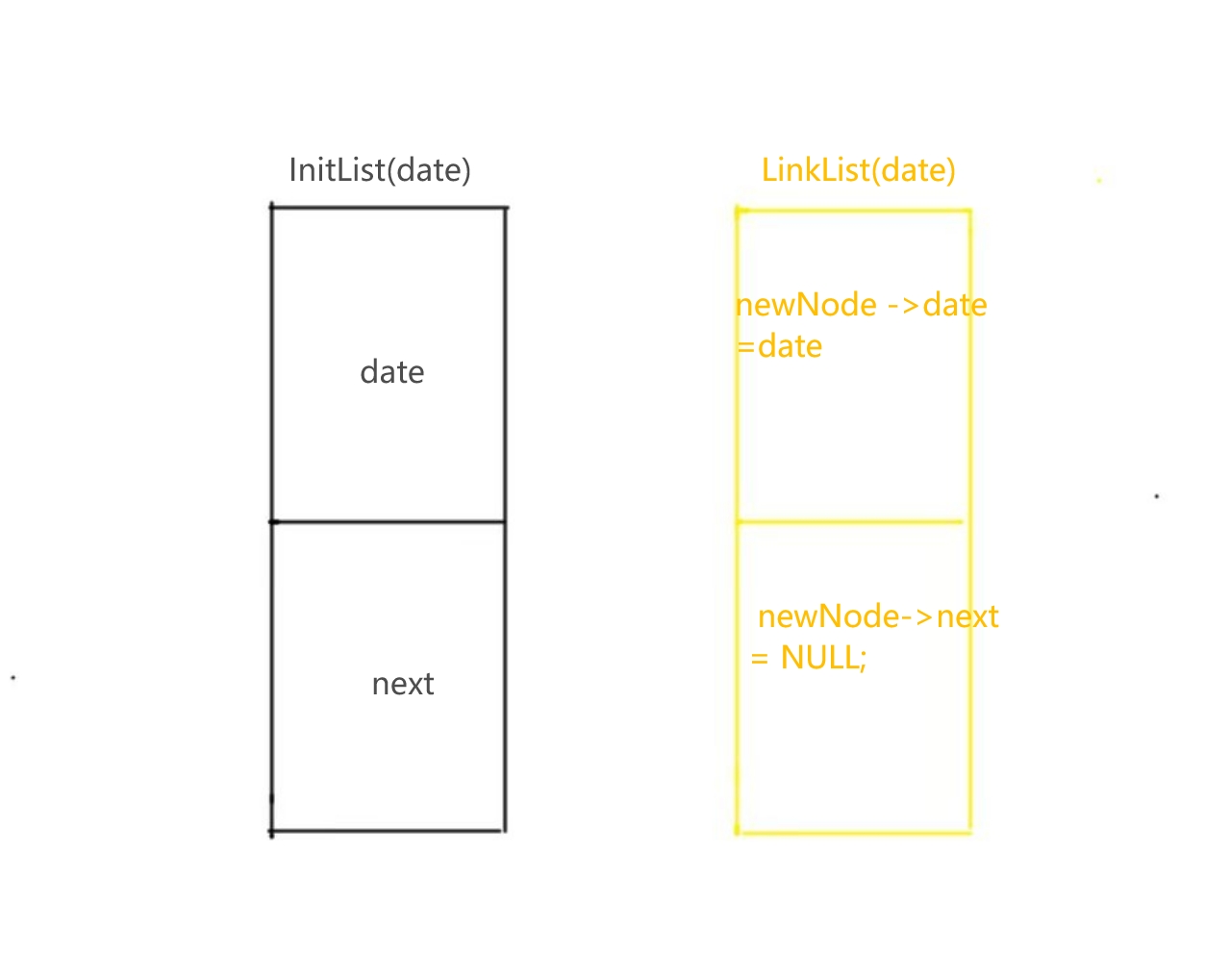
我们知道 InitList(date) 这里只定义一个头节点,可链表的接续必须要有两个以上才能被称之为一个链表的接续,但是我们在这里看到的是什么?下一个节点(黄色的那个方格)被函数LinkList(date)定义,
所以我们这里就可以知道这两个函数虽然是在做相似的事情,但实际上在内存里面做的却是定义了两个节点,那我们现在有了两个节点之后,那我们该如何将这个节点联系起来呢?
这就要来到我们第3步操作。来连接这两个节点的针。
- 然后第三块
/* 创建当前节点指针并指向头节点 */ Date_t* current = head;相信在这里大家又会有个疑问?为什么我们不能直接用我们上面定义好的那个 节点呢?
/* 将传入的数据赋值给头节点的数据域 */ head->date = date;因为我们在这里需要去铭记一件事,因为我们在上面定义的那个语句,它是一个创造列表新节点的一个语句,并不是要将这两个节点连起来,就像两个个车厢一样,他们现在就是两个车厢,也就是链表的两个节点。
不具备相连功能,那么我们在下面创造的这第3块语句,恰恰就是我们连接这两个车厢的钩子类似一这样
经过这样一遍历我们就成功把这两个节点的头部找到了
接着我们再利用语句
/* 移动当前指针到下一个节点 */ current = current->next;这两个语句类似于
i++; i=i+1;
- 图解为
不过这里是加了个限制条件,那就是这个指针遍历到指针域为空的情况下。所以加了
while (current->next != NULL) { /* 找到链表的最后一个节点*/ current = current->next; }找到链表,最后一个节点的情况就是链表的指针域为空,这里一旦为空循环就不执行,而此时 current 的值也变成了链表最后一个情况的值此时,current= current->next 不再执行。current->next 在此时储存的就是这个链表最后的一个值如图。
然后就把 最后一个空的值 (蓝色的值)
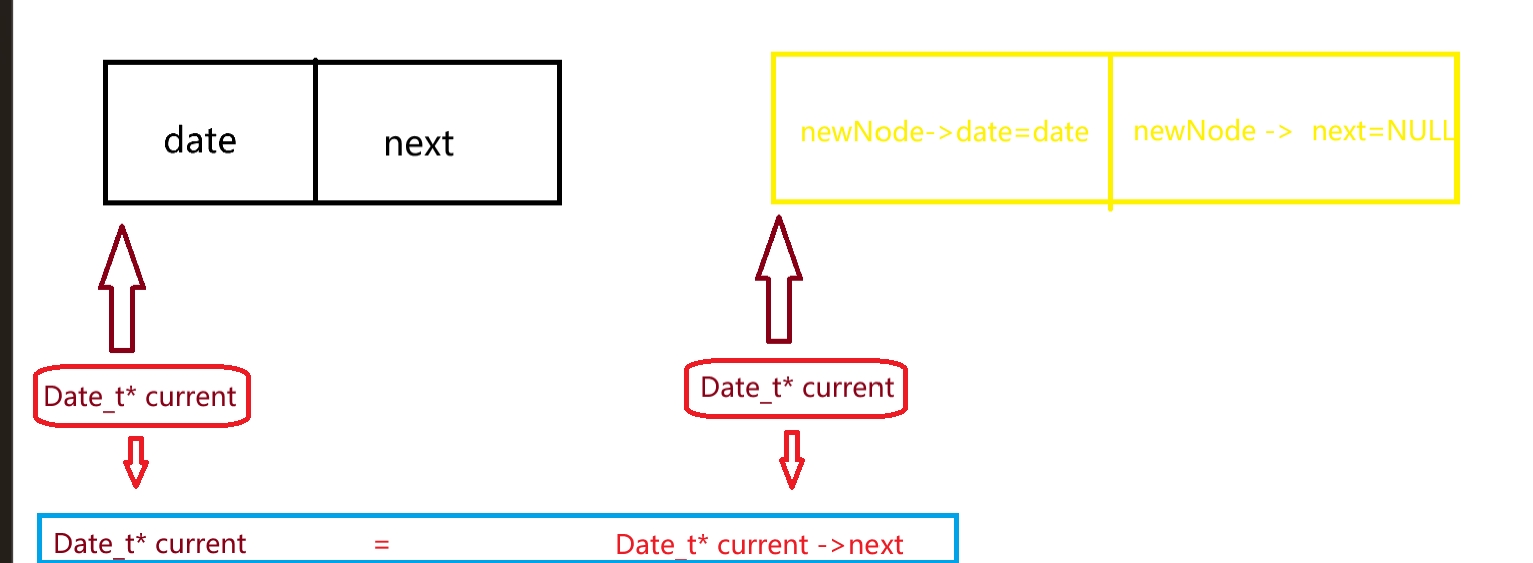

最后第四块
/* 将新节点链接到链表末尾 */ current->next = newNode;意思为: current->next = newNode;
current 的下一个值为 newNode;
以上就是尾插的全部操作了
2.1.2、尾插总结
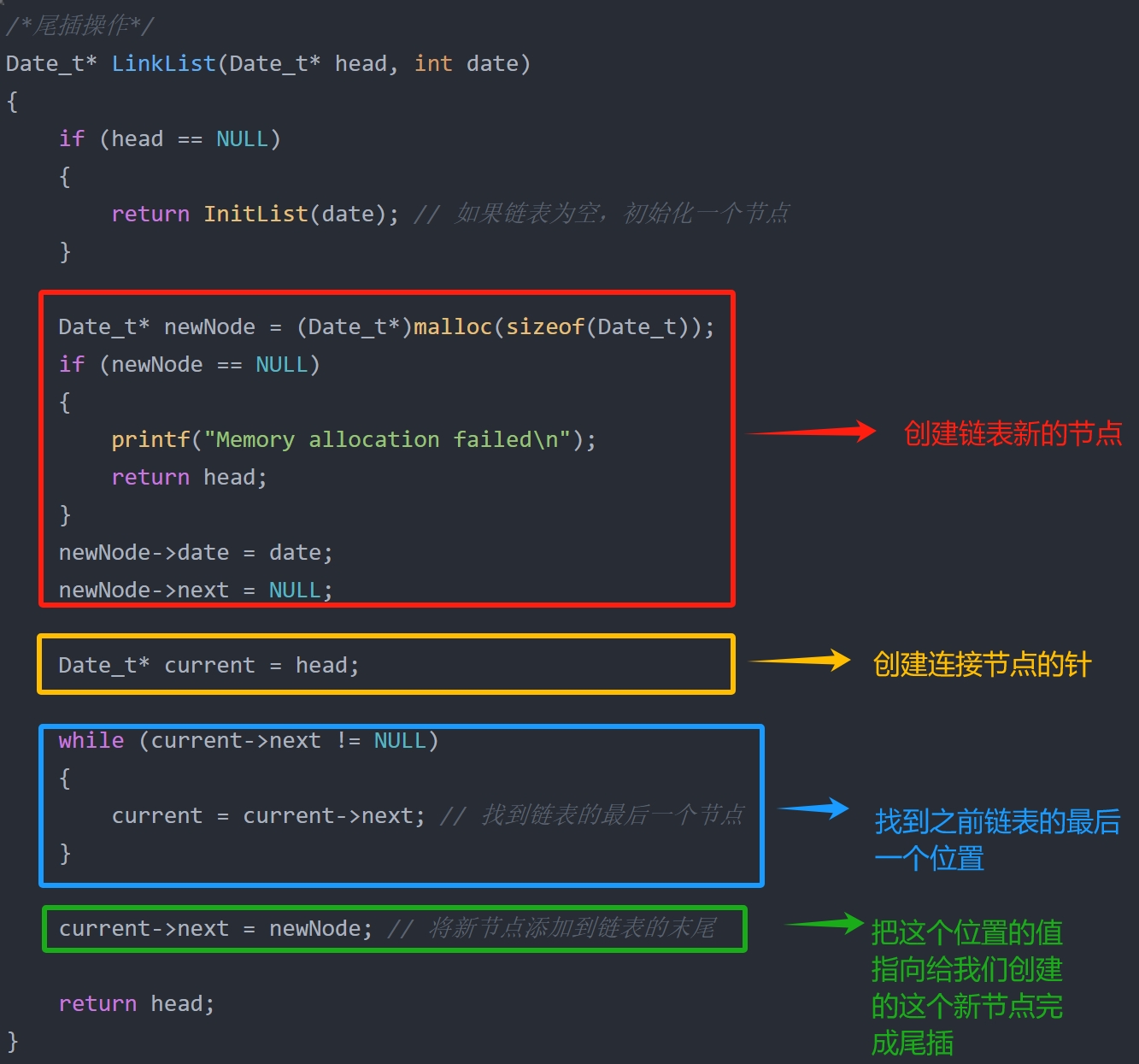
所以你明白吗?链表真的就是你女朋友!
2.2、头插
代码如下:
/*头插操作*/
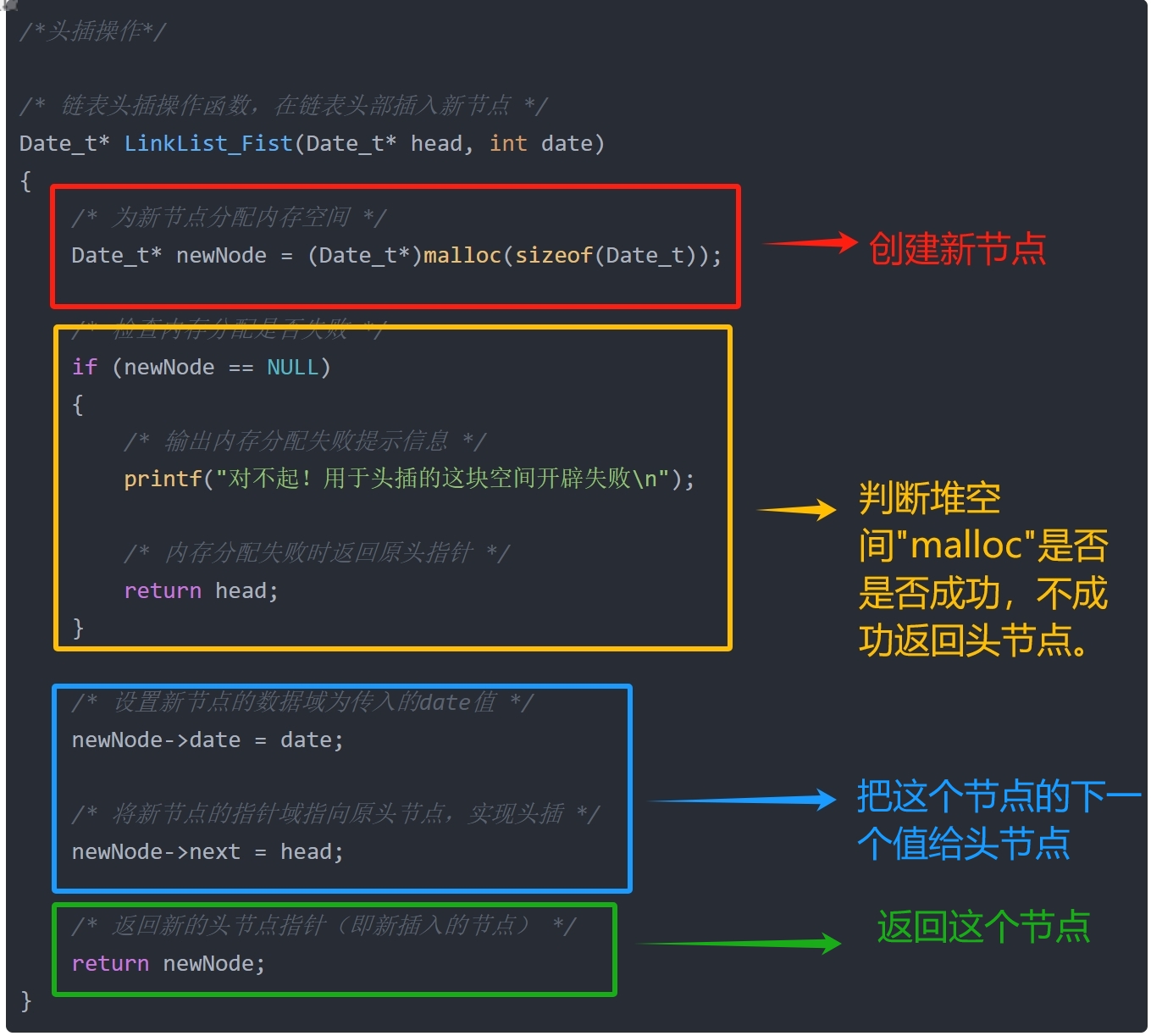
/* 链表头插操作函数,在链表头部插入新节点 */
Date_t* LinkList_Fist(Date_t* head, int date)
{
/* 为新节点分配内存空间 */
Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));
/* 检查内存分配是否失败 */
if (newNode == NULL)
{
/* 输出内存分配失败提示信息 */
printf("对不起!用于头插的这块空间开辟失败\n");
/* 内存分配失败时返回原头指针 */
return head;
}
/* 设置新节点的数据域为传入的date值 */
newNode->date = date;
/* 将新节点的指针域指向原头节点,实现头插 */
newNode->next = head;
/* 返回新的头节点指针(即新插入的节点) */
return newNode;
}但如果你要是没看,我......

好吧!其实,写的那么长
非必要的时候......我也不会看
那我继续跟你说
首先依旧把代码分成四段
- 首先看第一段
/* 为新节点分配内存空间 */ Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));这一段就是利用堆函 malloc() 再内存中开辟大小为 sizeof(Date_t) 的堆空间用于存储数据。
- 你把节点想像成一些已经成型“腊肠馅”。

腊肠馅 -> 链表里的节点
- 而“堆空间”就是“肠衣”
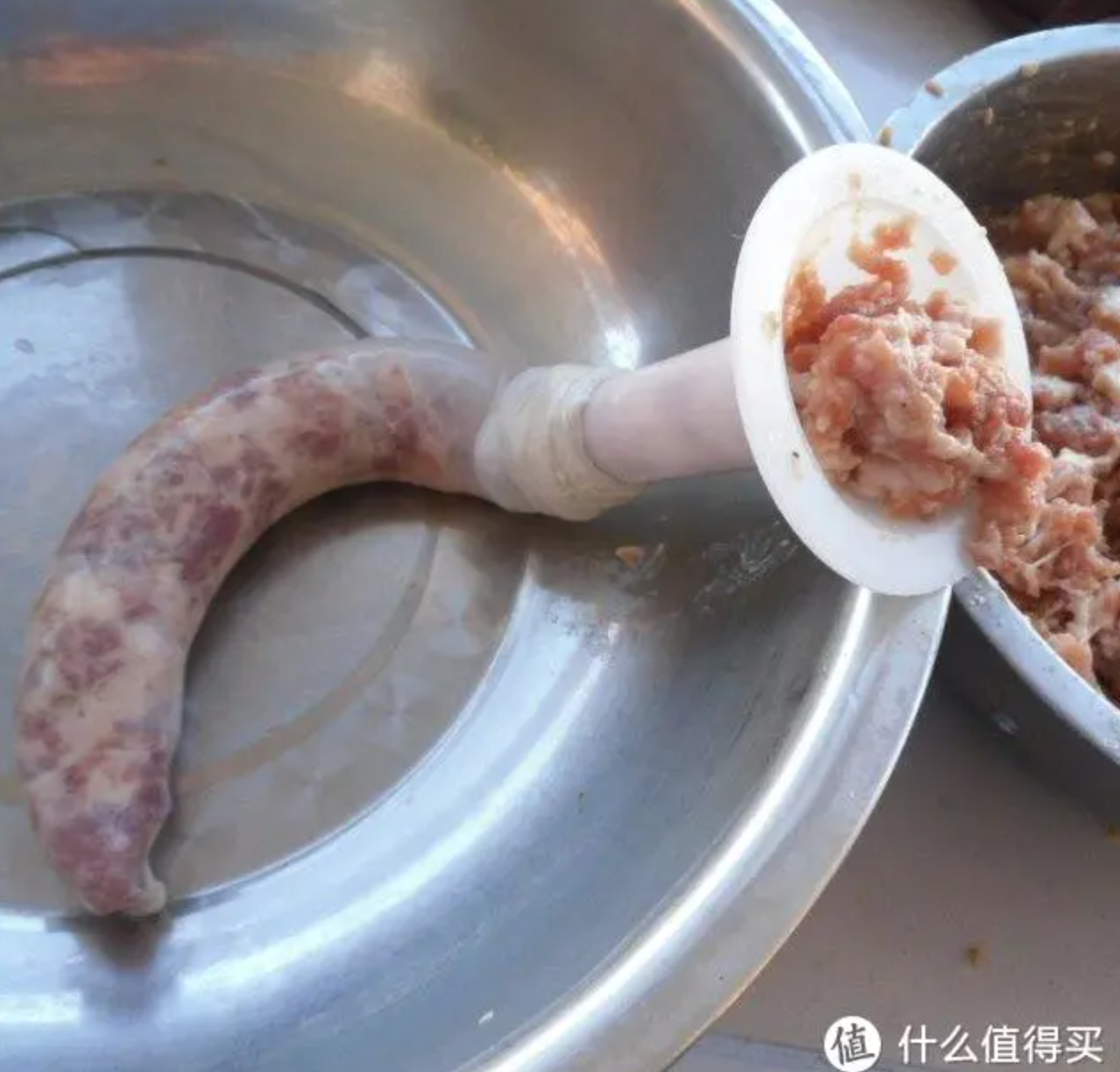
肠衣=堆空间“malloc()”
- 指针呢指针就是,指向下一个节点的绳子

一个绳子就是一节腊肠--一个指针就是一个节点 图片出处:吃了这么多年烤肠,才知道外面薄薄的一层,原来是用这种东西做的
https://post.smzdm.com/p/akxx0onr/
- 在程序中就是
(等下.....搜图片的时候有点饿了,我去点个广式腊肠煲仔饭.....)

- 然后看第二段
/* 检查内存分配是否失败 */ if (newNode == NULL) { /* 输出内存分配失败提示信息 */ printf("对不起!用于头插的这块空间开辟失败\n"); /* 内存分配失败时返回原头指针 */ return head; }这一段就是保证安全用的,用于方便用户调试程序,如果失败就返回。没啥好说的
- 接着看第三段
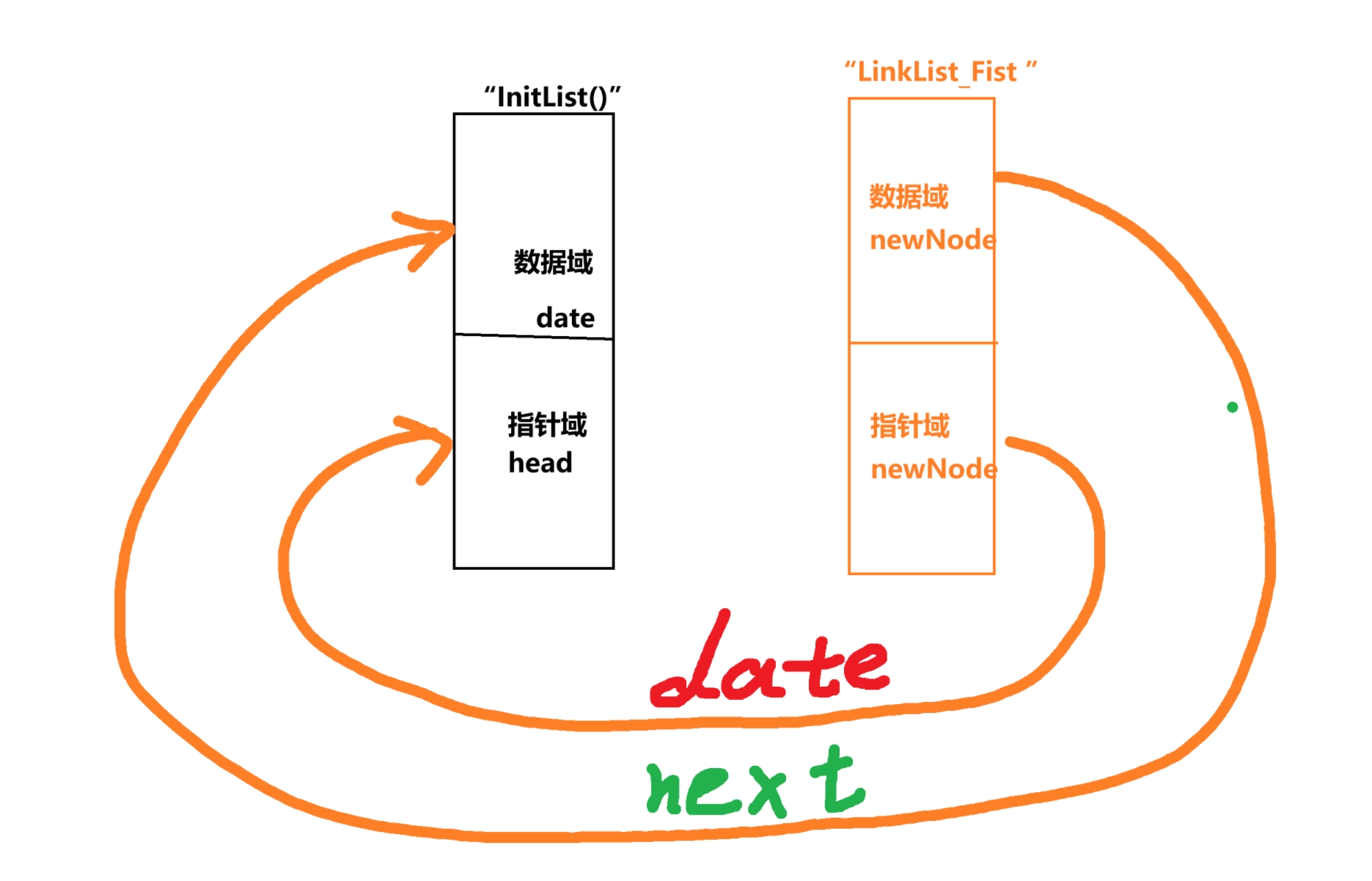
/* 设置新节点的数据域为传入的date值 */ newNode->date = date; /* 将新节点的指针域指向原头节点,实现头插 */ newNode->next = head;说人话就是,我在 “LinkList_Fist ” 这个函数创造的这个节点的下一个节点的数据域指向我在 “InitList(int date)” 这个函数下的数据域;我在 “LinkList_Fist ” 这个函数创造的这个指针的下一个节点的指针域指向我在 “InitList(int date)” 这个函数下的指针域
请把下面的这个语句想象成你的“后任”,也就是你的“后女友(或“后男友”)”🙂
(具体为什么会这样,或者说这个功能是怎么实现。我后面跟你说)newNode->datenewNode->next = head;
这句话的意思就是你的 “后女友(后男友)” 就是你谈的第一个 “女友(男友)”,也叫“头男友或(头女友)”
俗称“初恋”
你们就这样 手牵着手(数据域指向数据域),脚牵着脚(指针域指向指针域)走进了蜜雪冰城。
(细品!你细品!)

如果你想不通......我.......
我......先无语两秒钟......
两秒钟过后:我拿这一句话给你看
i+1=i; 或 (i+1)=i;(看懂了吗?亲~)



最后看最后一段
/* 返回新的头节点指针(即新插入的节点) */ return newNode;没啥好说的就是返回这个节点给主函数
总结:

(呐~报告长官!)
(我该怎么区分头插和尾插呢?)
对于这个问题我告诉你
你可以关闭你的手机或者卸载你电脑里的 VS 及相关插件,这样你的电脑就打不开 “.c”文件 。
这样你就看不到这个代码。这样你的问题自然就没有了。
就像你出BUG了,你把源程序全部删掉。这样就不会有报错了。至于能不能跑起来,那是项目经理的事情。不是我们这种月薪 3500 的“普!通!人!”操心的事情!
呵~呵~呵~
呵~呵~
呵~
那认真的,我该怎么区分头插和尾插呢?
一个技巧:
看这个函数下定义的用于插入的这个节点,是在前面或者后面
例如看下面两段代码:
- 代码一
Date_t* LinkList_Fist(Date_t* head, int date) { /* 为新节点分配内存空间 */ Date_t* newNode = (Date_t*)malloc(sizeof(Date_t)); /* 检查内存分配是否失败 */ if (newNode == NULL) { /* 输出内存分配失败提示信息 */ printf("对不起!用于头插的这块空间开辟失败\n"); /* 内存分配失败时返回原头指针 */ return head; } /* 设置新节点的数据域为传入的date值 */ newNode->date = date; /* 将新节点的指针域指向原头节点,实现头插 */ newNode->next = head; /* 返回新的头节点指针(即新插入的节点) */ return newNode; // 返回新的头节点 }
- 代码二
Date_t* LinkList(Date_t* head, int date) { if (head == NULL) { return InitList(date); // 如果链表为空,初始化一个节点 } Date_t* newNode = (Date_t*)malloc(sizeof(Date_t)); if (newNode == NULL) { printf("Memory allocation failed\n"); return head; } newNode->date = date; newNode->next = NULL; Date_t* current = head; while (current->next != NULL) { current = current->next; // 找到链表的最后一个节点 } current->next = newNode; // 将新节点添加到链表的末尾 return head; }我们就看着这两个代码的这两个部分
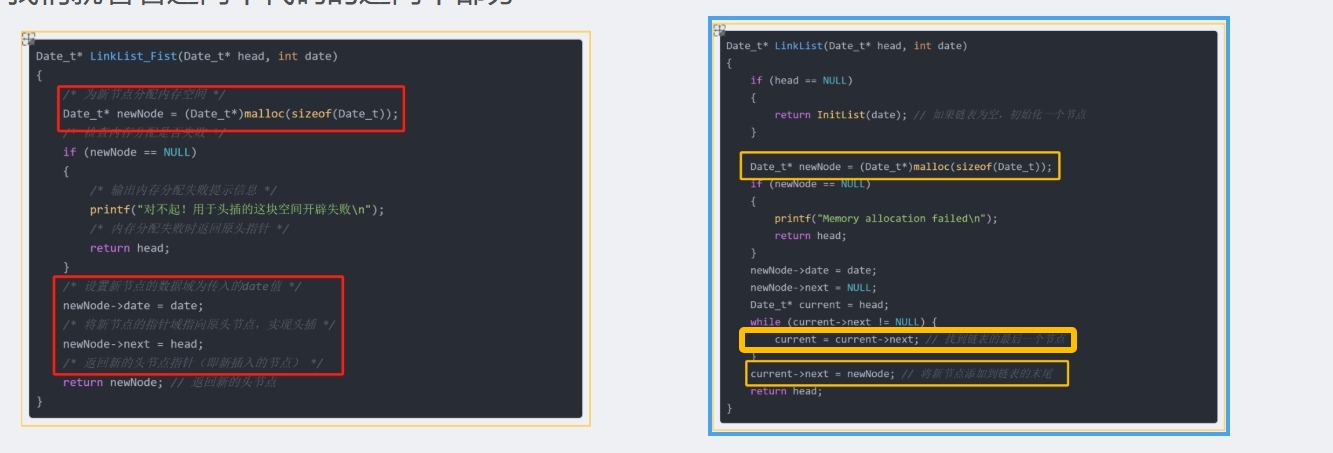
如果 -> 的值在等号右边,就是把下一个值赋值给上一个值,这个就是尾插
如果 -> 的值在等号左边,就是把上一个值赋值给下一个值,这个就是头插
三、链表的遍历操作
如果你看到这里想放弃了
那你就放弃吧;或许因为你的放弃或许能成就更多的人......
如果你放弃之后又 心有不甘
那你就,那你就去超市买两个 粑粑柑 ,这样你就心里有甘了
呵~呵~呵~
呵~呵~
呵~

好!接下来我们看这段代码
1.源代码
/*遍历操作*/
/* 遍历链表并打印所有节点数据 */
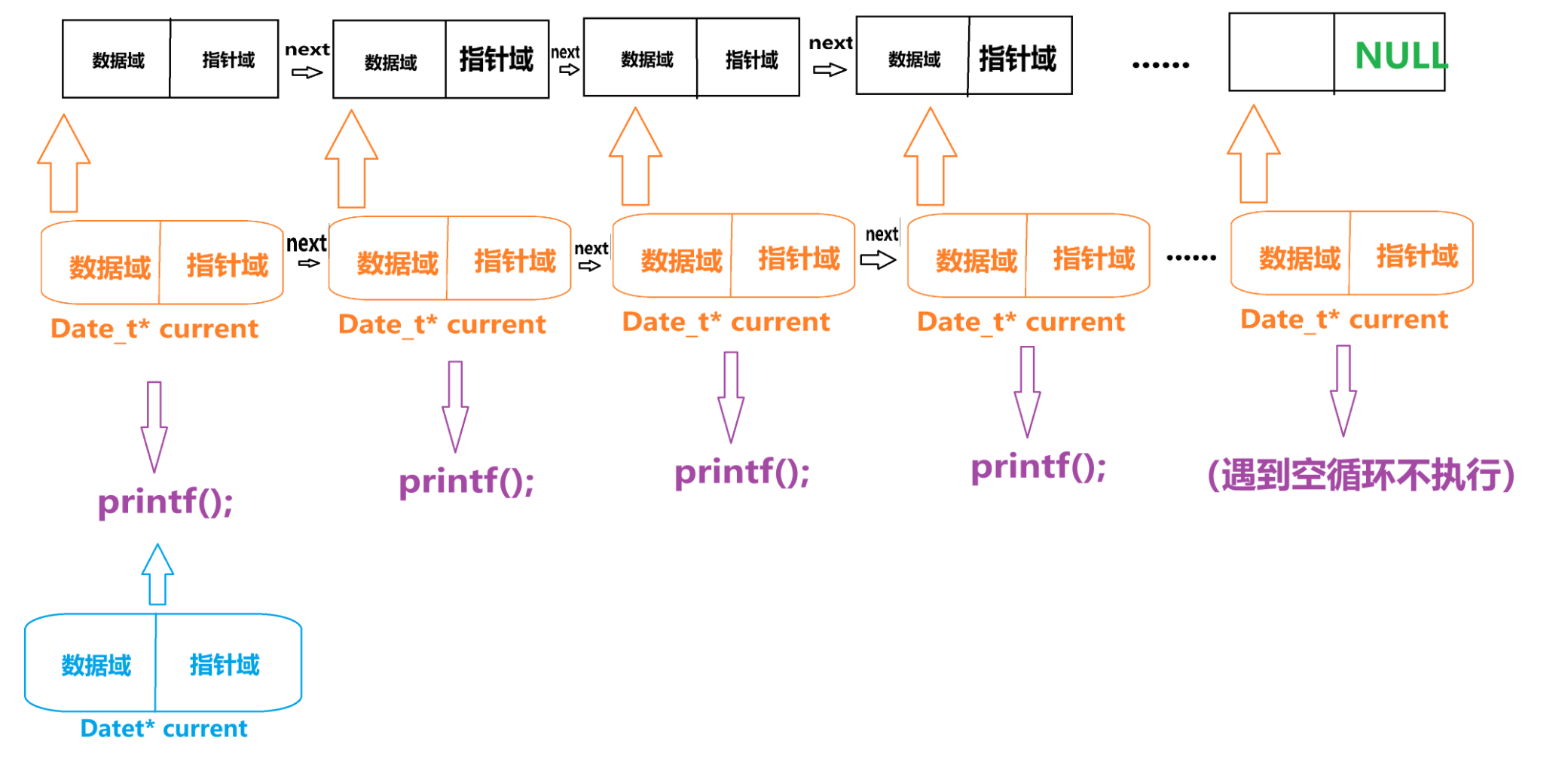
void Tarversal(Date_t* head)
{
/* 创建当前节点指针并初始化为头节点 */
Date_t* current = head;
/* 循环遍历链表,直到当前节点为NULL(链表末尾) */
while (current != NULL)
{
/* 打印当前节点的数据域,后跟空格分隔 */
printf("%d ", current->date);
/* 将当前指针移动到下一个节点 */
current = current->next;
}
/* 遍历结束后打印换行符,美化输出格式 */
printf("\n");
}
什么?你说,你看不懂中文注释?

void Tarversal(Date_t* head)
{
Date_t* current = head;
while (current != NULL)
{
printf("%d ", current->date);
current = current->next;
}
printf("\n");
}

那.....这样你就看的懂了
读者:欸!不是?
我问了吗?你就说

接下来我就带你们分析这段代码
2.分析
- 源代码一
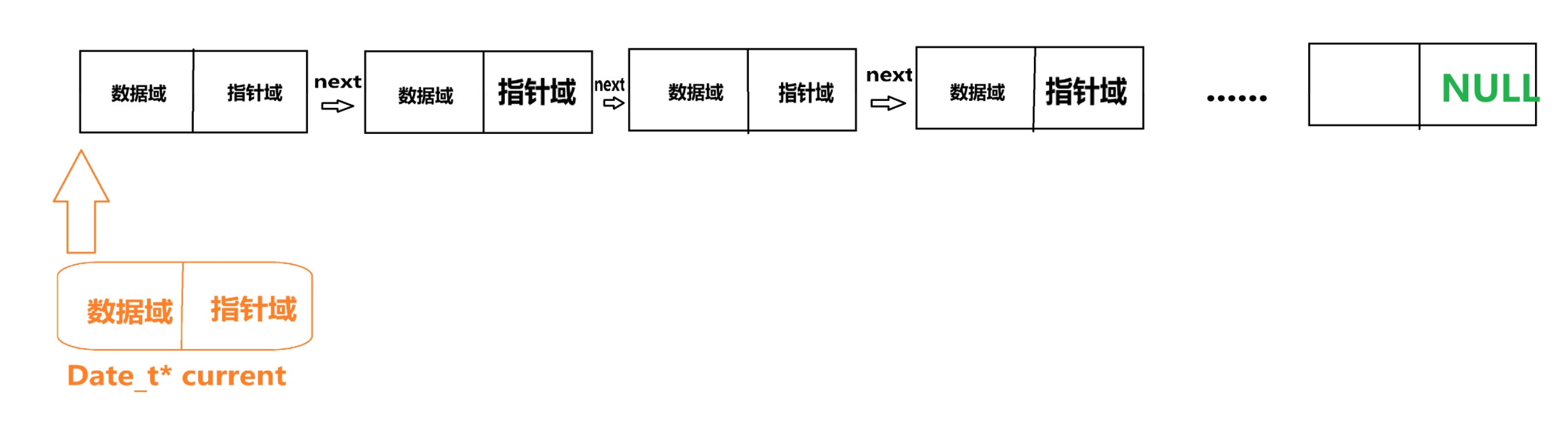
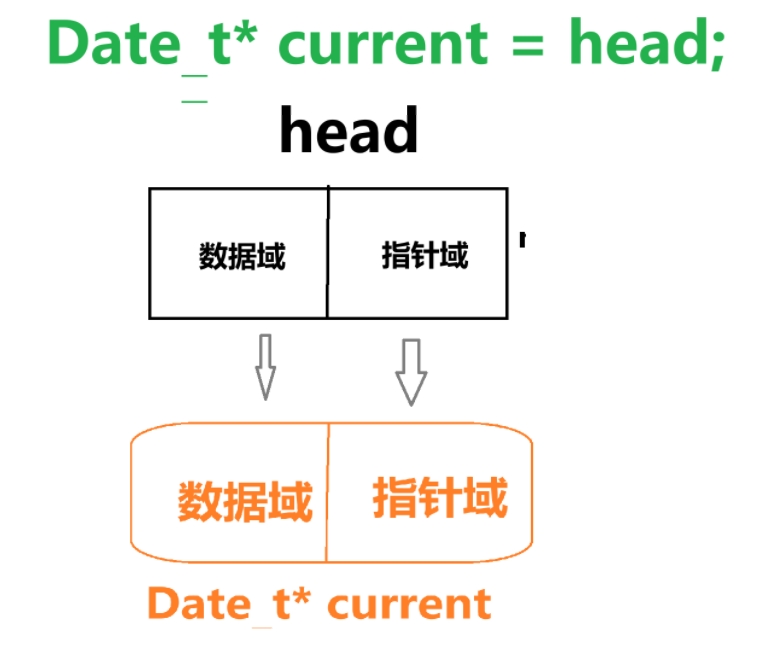
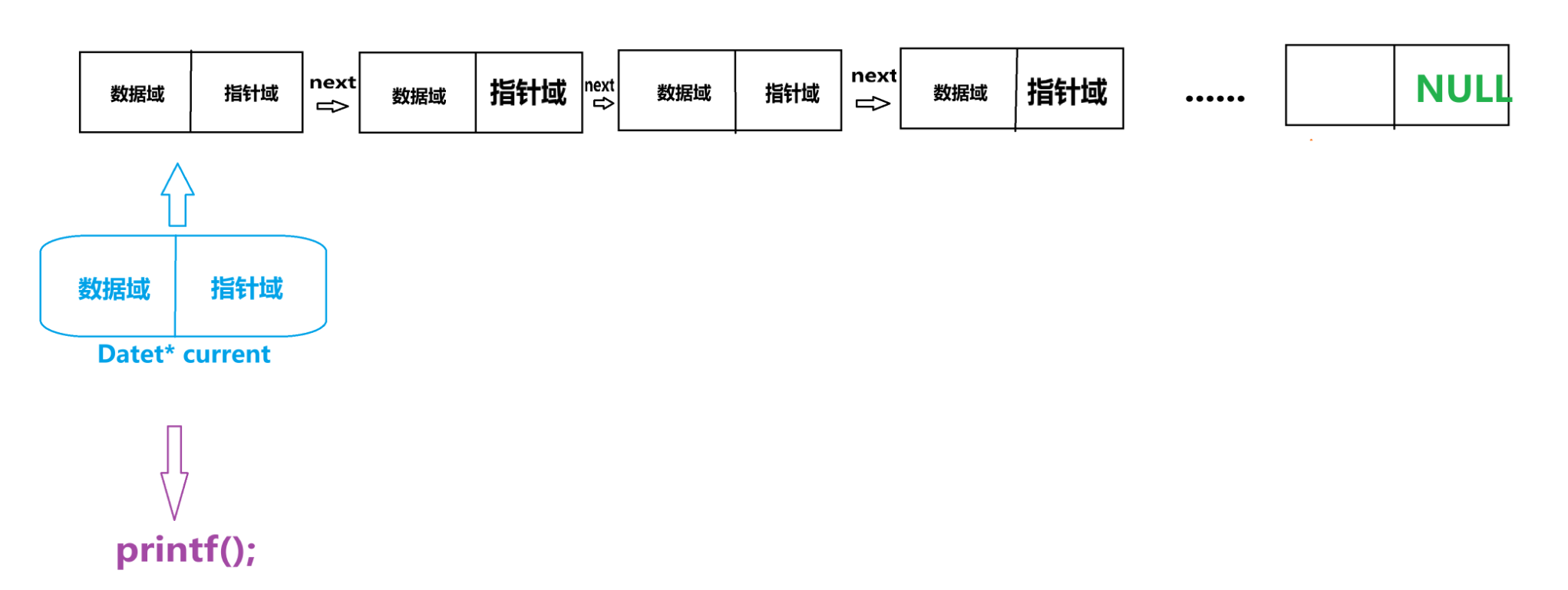
/* 创建当前节点指针并初始化为头节点 */ Date_t* current = head;这里在做什么呢?
这里在 Tarversa() 函数下定义了一个用于遍历的指针,然后通过赋值操作让这个指针对齐头节点
如图:
因为这个指针是 Date_t* 所以他具有和链表节点相同的数据结构,但区别在于他仅仅只是用于遍历,不参与“增”“删”“改”,仅仅只用于“查”这个操作。
- 他们长这样
- 所以也可以是这样
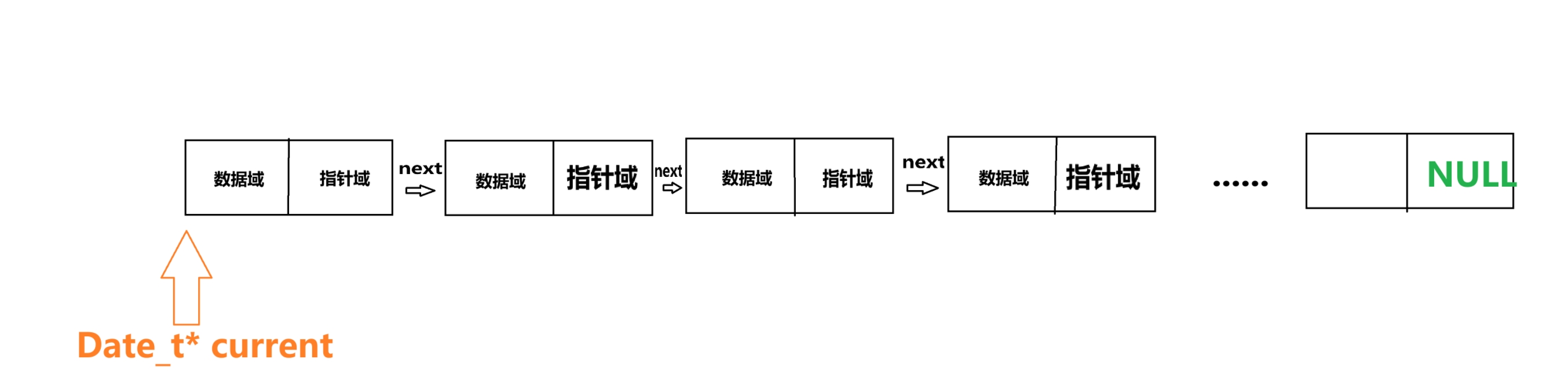

- 源代码二
/* 循环遍历链表,直到当前节点为NULL(链表末尾) */ while (current != NULL) { /* 打印当前节点的数据域,后跟空格分隔 */ printf("%d ", current->date); /* 将当前指针移动到下一个节点 */ current = current->next; }这里在做什么呢?
其中这里再做,把 current 里的数据读出来,因为结构相同就形成一一对应的关系
也就是这样
然后,程序执行语句 “current = current->next;”就是在这里调用之前定义的结构体,里自动跳转的功能(具体这个功能怎么实现的文章末尾说),让这个指针跑到下一个节点,周而复始,一直遇到“NULL(空)”,程序里 “while (current != NULL) ” 条件不满足的时候跳出循环。完成遍历
就像这样
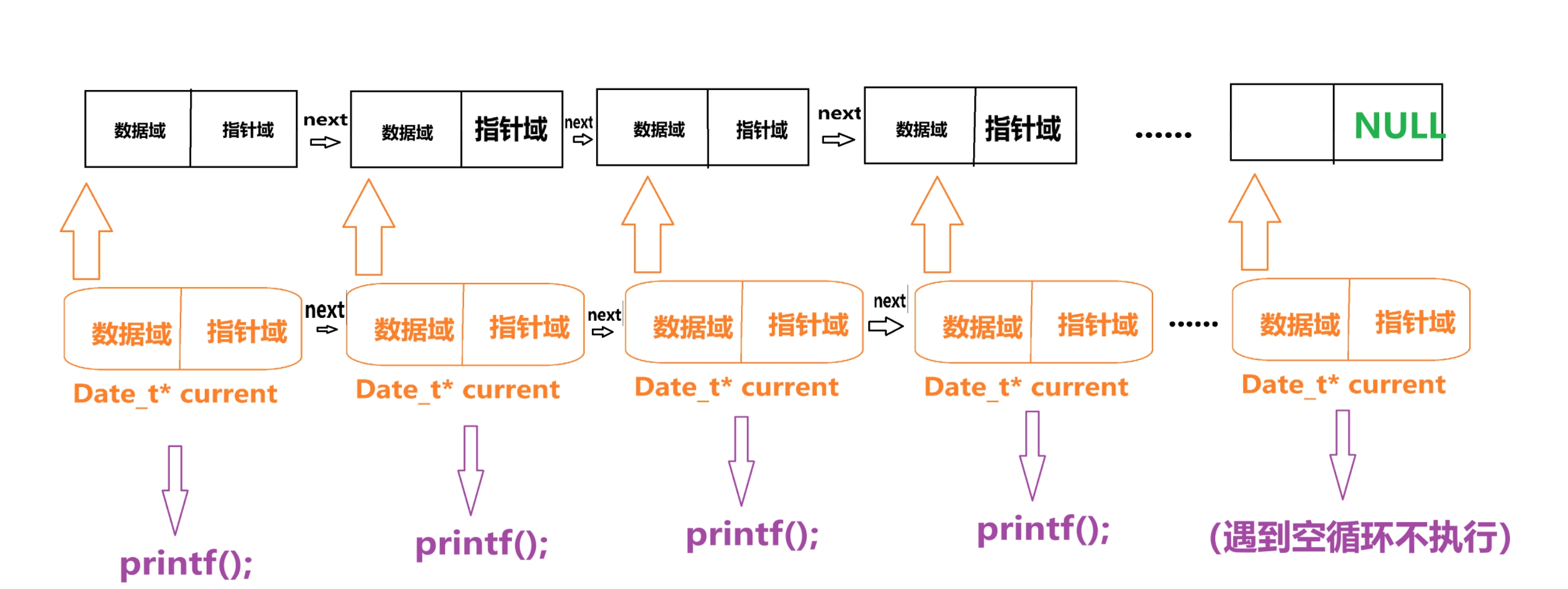
- 源代码三
printf("\n");这个代码就是为了好看换行用的
那么再这里我们是不是发现一个问题
/* 将当前指针移动到下一个节点 */
current = current->next;这个用来查找的语句不断的再申请内存,影响程序整体性能,有没有什么方法让他不用这样呢? 比如像一次性手套那样用一次扔一次
四、查找指针的释放操作
1、原函数
/* 释放操作 */
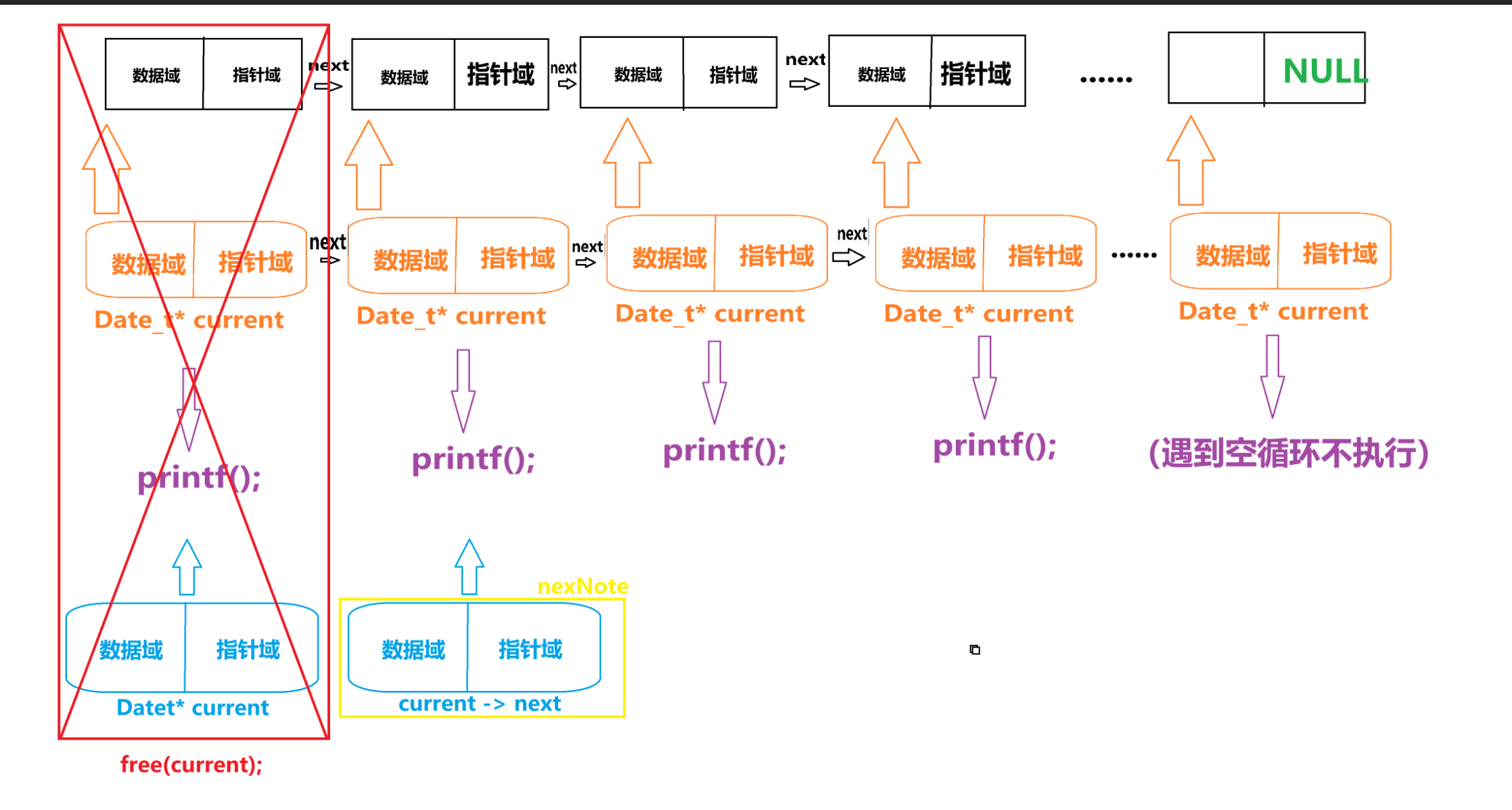
void Release(Datet head)
{
/* 初始化current指针指向头节点 */
Datet* current = head;
/* 当current不为空时循环 */
while (current != NULL)
{
/* 保存下一个节点的指针 */
Datet* nextNode = current->next;
/* 释放当前节点的内存 */
free(current);
/* 将current移动到下一个节点 */
current = nextNode;
}
}
2、解释
/* 初始化current指针指向头节点 */
Datet* current = head;这里做了初始化是定义了一个指针专门用于释放空间的指针 名字为 “current” ,而且与链表头部对齐。
/* 当current不为空时循环 */
while (current != NULL)
{
/* 保存下一个节点的指针 */
Datet* nextNode = current->next;
/* 释放当前节点的内存 */
free(current);
/* 将current移动到下一个节点 */
current = nextNode;
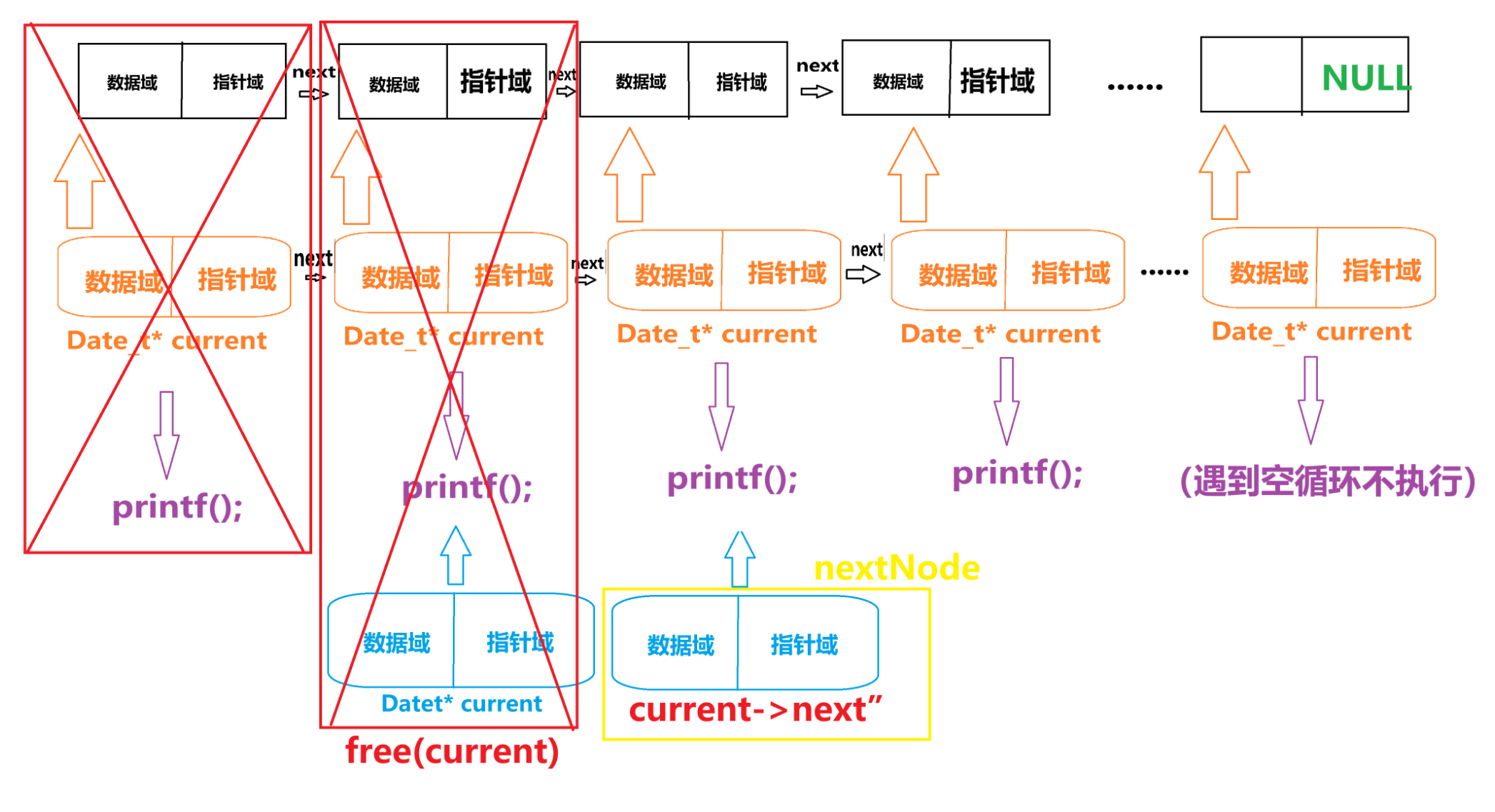
}然后定义了一个用于保存 “current” 下一个节点的指针名字叫 “nextNode”。
问?为什么不直接使用 “current -> next” 呢?
因为 “current” 这个指针我们接下来要连同 “current” 所在的这块空间要一起被释放掉,如果是“current -> next” 的话。因为我们已经释放掉 “current” 所以在编译器中就出现“ -> next ”这个情况。这显然是不被允许的。
所以我们就引用了一个指针 “nextNode” 来做个桥接,用于保护 “current -> next”。
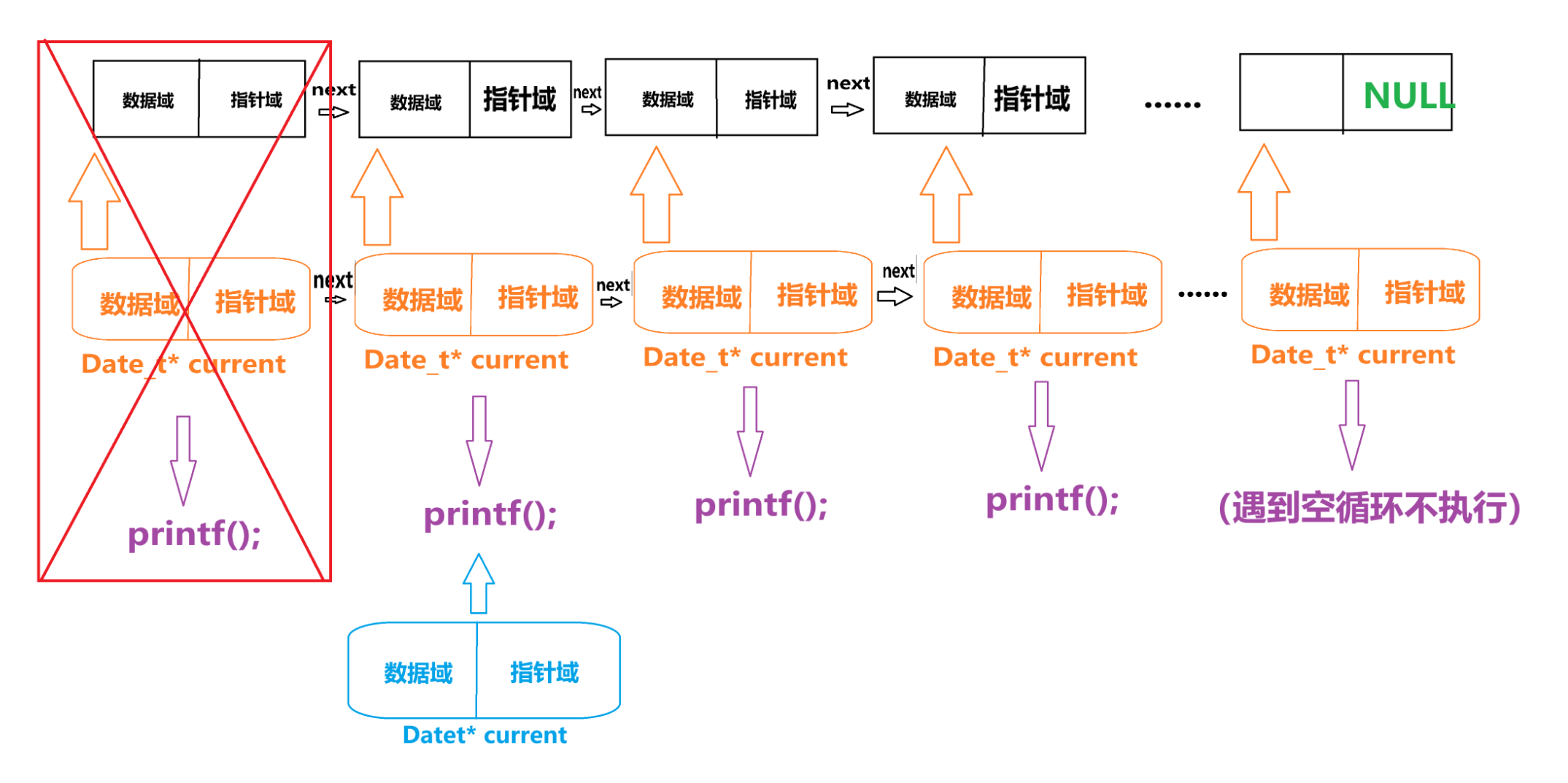
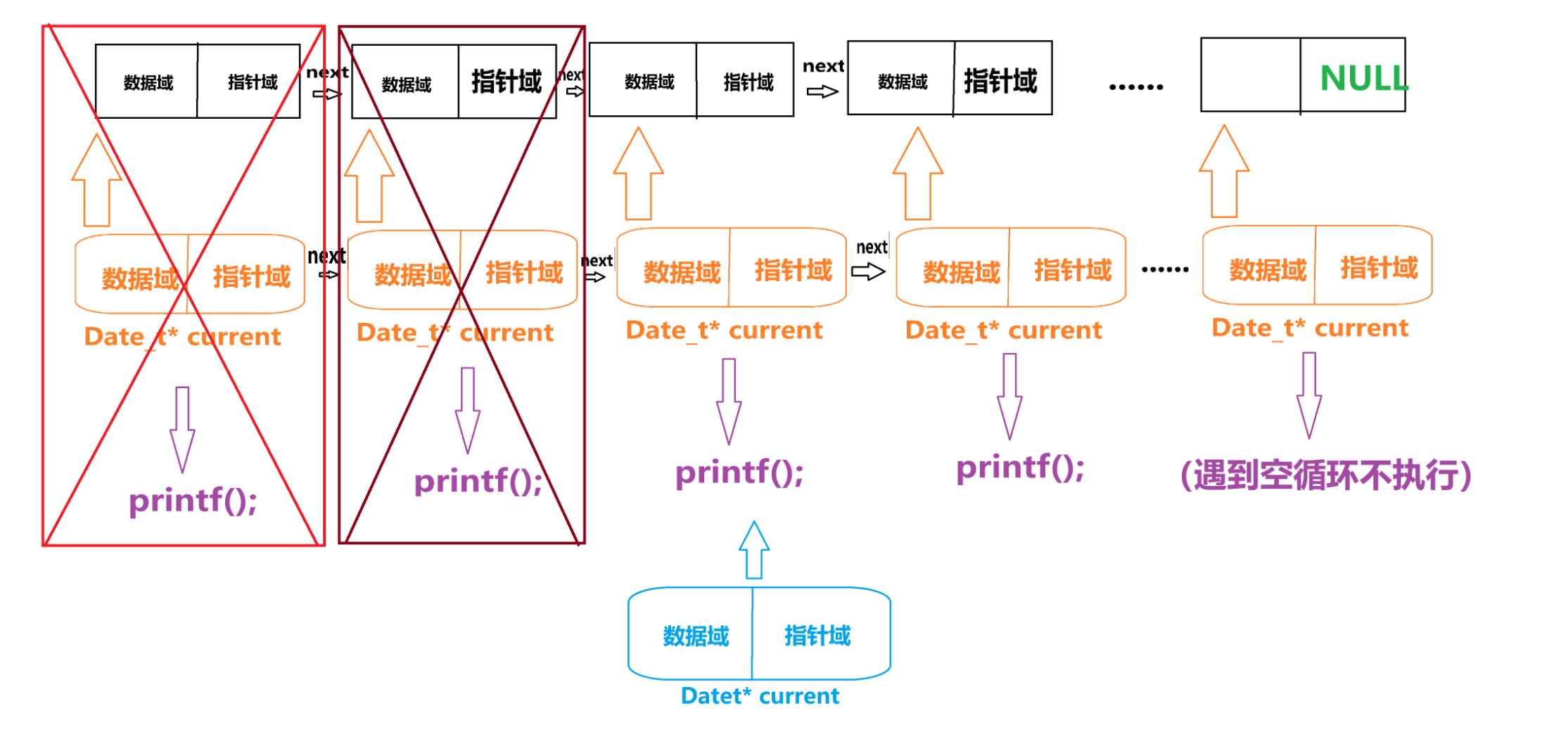
然后“current” 空间以及“current -> next” 在执行 “free(current)” 被释放掉了。
但 “current -> next” 真的被释放掉了吗?
欸~可别忘了 “Datet* nextNode = current->next” 这个语句可是把 “current -> next”保护起来了。
接着 “current = nextNode ” 又把 “current ” 复活了,然后就成了这样
然后再回到循环中执行 就这样 “Datet* nextNode = current->next”
那请问语句 “Datet* nextNode = current->next” 中先执行那个部分?
答案:
- current->next
- Datet* nextNode = current->next
因为优先级的问题
记住口诀:括单术 移关位 逻三赋逗具体优先级的问题,笔者在这里不做赘述,具体请移步翻阅下面这篇文章
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇
C语言运算符优先级
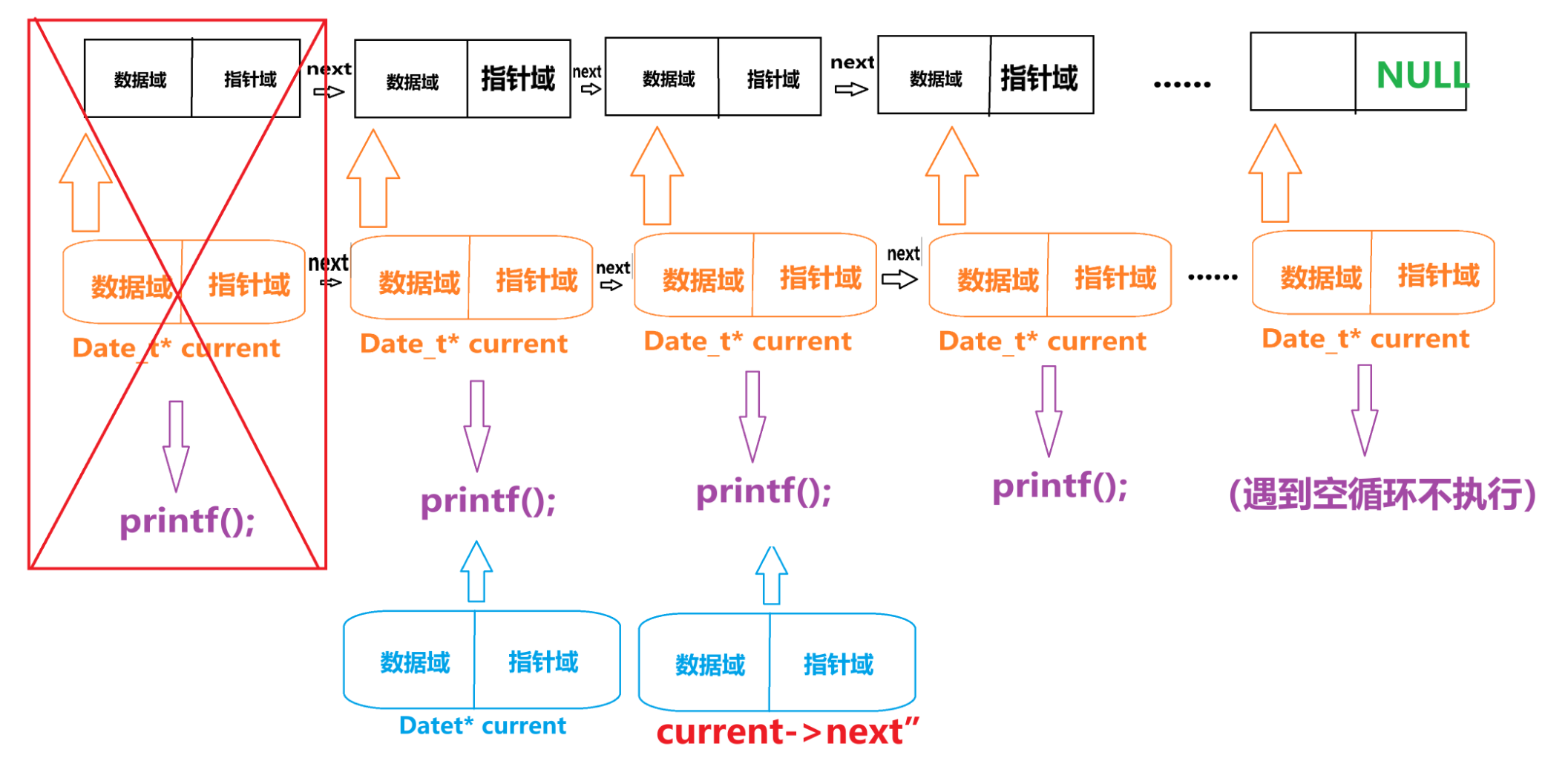
然后再接着执行语句 “current = nextNode;”
就像这样
然后执行语句 “current = nextNode;”就像这样
周而复始......
(但更加严谨的是中间那排橙色的应该是没有的,但这里我就偷个懒过程就不画了)
因为......

好!接下来解决最后一个问题,也是笔者思考很久的问题。但是是在一个很简单的例子上得到答案的问题
五、程序自动跳转的功能是怎么实现的
首先,我们在看是之前请跟我念三遍咒语
指针就是地址,地址就是指针!
指针就是地址,地址就是指针!
指针就是地址,地址就是指针!
指针就是地址,地址就是指针!
指针就是地址,地址就是指针!
指针就是地址,地址就是指针!

好!我们接下来看,回头看这段代码:
typedef struct Node
{
int date;
struct Node* next;
}Date_t, * Dext_t;就是我么最初的那个定义 的结构体,还记得我说的这句话吗?
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇 👇👇👇👇👇👇👇👇👇👇👇👇👇
我也可以提前告诉你:
这个在告诉编译器你 要以这样的格式 定义一个链表其中一个节点!
OK,接下来再看我们每一次定义链表节点的过程,
Date_t* head = (Date_t*)malloc(sizeof(Date_t));
Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));
Date_t* newNode = (Date_t*)malloc(sizeof(Date_t));
Date_t* current = head;
看到了吗?
大量的应用到 “Date_t” 也就是引用结构体这个格式,就应证了这句话:
“这个在告诉编译器你 要以这样的格式 定义一个链表其中一个节点!”
然后我们再引用 “next” 就可以完成地址的跳转了。那究竟是怎么跳转呢?
关键就是这句话: “struct Node* next”;
在仔细观察一下我们定义,结构体的过程也是: “struct Node”;
那这么两句有什么联系吗?
答案:“有!”
(很精妙,而且这个设计非常的精妙! )
看下面这张图,我们是把内存分成一个又一个的小格子,每个小格子上都有一个特定的编号(这里编号我就不打出来了,因为我想偷懒)

当我们定义这段语句时候
typedef struct Node
{
int date;
struct Node* next;
}Date_t, * Dext_t;实际上就是告诉这个格子这里有个一个格子只能装 “struct Node”类型,有且只能装一种
所以你们大概也能想到这个格子应该是这么装的
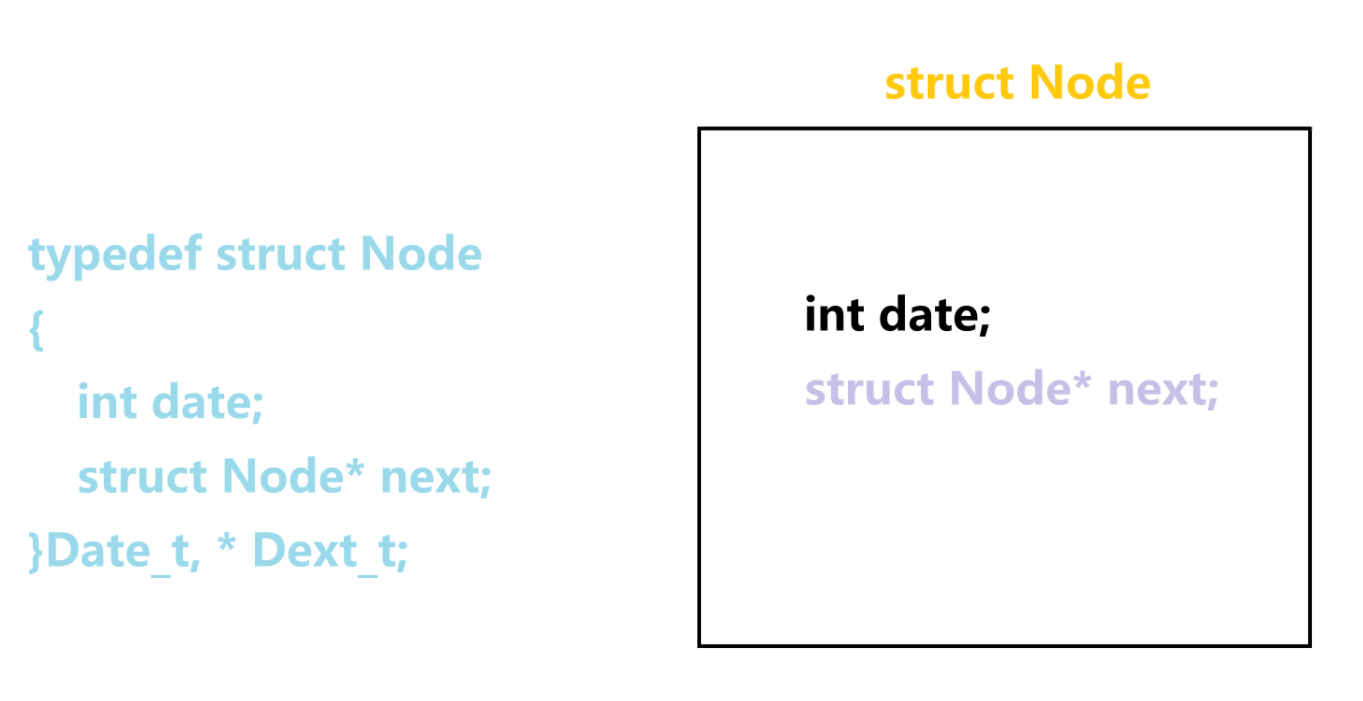
对吗?
我明确的告诉你!
错了!
这个问题,就连我最开始也忽略了,所以导致我列表这个东西一直就是不会一直到最后我用一个很简单的例子才把这个谜底解开。
这个问题最开始解开的,一个启发是我那天学到了枚举,
enum Color
{
RED = 1,
GREEN = 2,
BLUE = 4
};
我们都知道 “在C语言中,枚举(enum)本质上是一种整数类型。”
实际上这个代码就是定义许多整型类型,其本质是只是符号名称,代表特定的整数值。当您定义一个枚举变量时,该变量会占用内存空间,但多个枚举变量不会共享同一个内存空间,每个变量都有自己独立的内存空间。
重点: 多个枚举变量不会共享同一个内存空间
- 接着再看我们最熟悉的这个操作
int a=10; int b=10; int c=10;
int d=10; int e=10; int f=10;
这里定义了很多整形变量,但是这个我们都知道,不会占用同一个空间。
因为在最开始学习C语言的时候,我们都知道一个类型就是占用一个空间,就连枚举这种特殊的类型,都不会共享同一个空间。
ok!我们再回到最初的起点,看看这一句!
typedef struct Node
{
int date;
struct Node* next;
}Date_t, * Dext_t;我们在这里,那么我们在这里就知道了。他在执行每一次程序的时候,都定义了同类型的两种变量,这个操作叫 C语言的自引用指针
接下来,继续看上面的图
很明显是错的,因为他在同一个内存里定义了两个同一种类型的struct变量。
那实际上应该是
那具体是怎么实现的呢?
不严谨好理解的说法就是。
他是被他自己挤出去的 。
严谨的说法就是
在C语言中, "struct Node* next" 作为自引用指针,其"跳转"能力并非自动实现,而是通过程序员显式操作和指针解引用共同完成的。
而且,自引用指针能工作的核心原因:
不完整类型(Incomplete Type)支持:C语言允许在结构体内部使用指向自身的指针(struct Node*)即使此时struct Node 尚未完全定义。也完全合法。因为指针大小固定:无论struct Node最终包含多少成员,struct Node*的大小始终固定(4/8字节),编泽器可安全分配内存
(好了!看到这就要和大家说再见了,还有下面的内容关于“增”、“删”、“该”、“查”以及 双向链表 也会再后续更新。欢迎大家多多关注
在培训结束,B站会同步更新一些好玩的作品,大家可以浅浅的期待两下,
也可以扫码提前关注一下呦~

















 2498
2498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









