







正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
正则表达式在实际中使用的频率不是很高,很容易遗忘,特做了思维导图,方便记忆查找,后附带详细讲解。
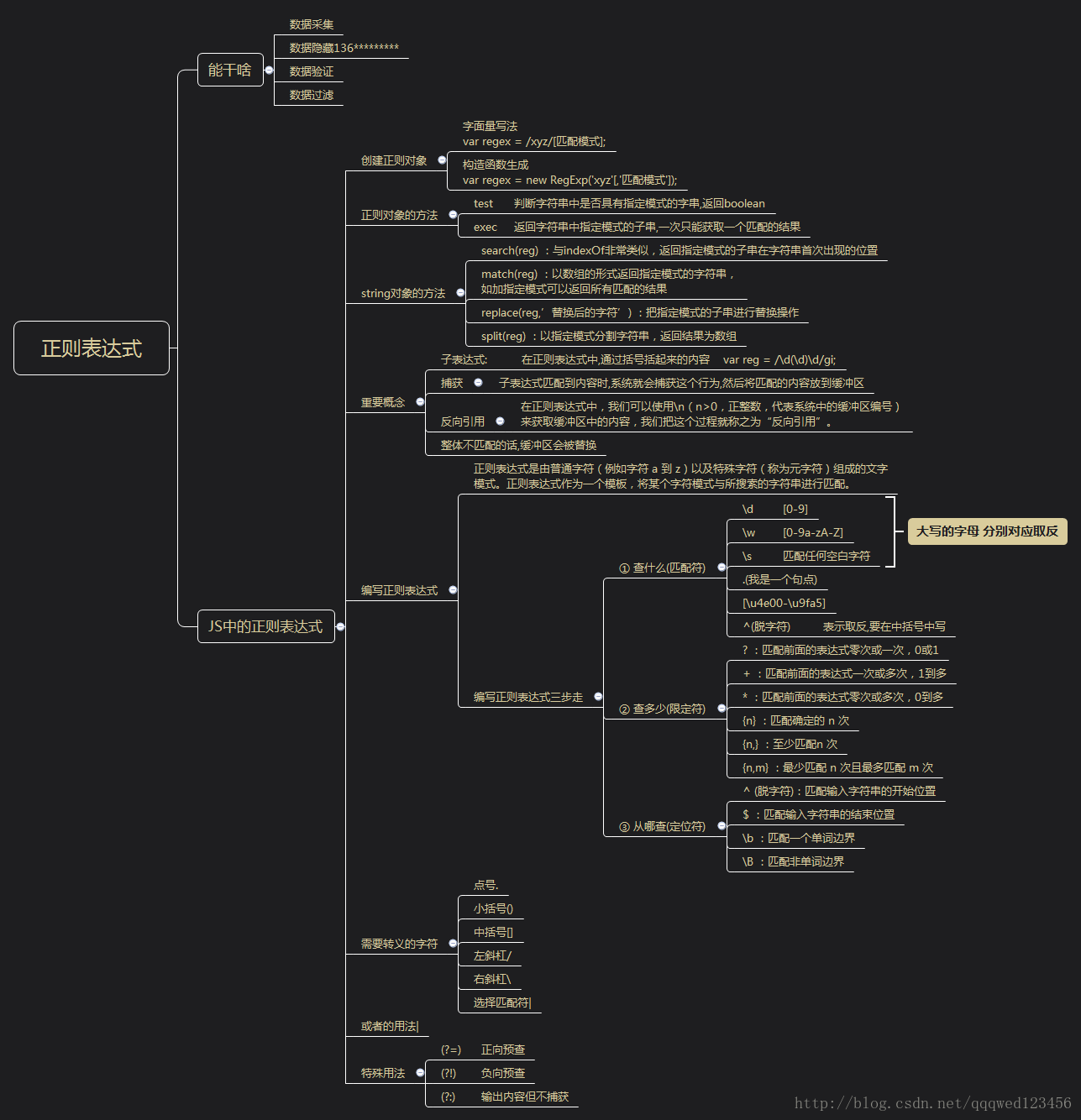
一、正则表达式能做什么?
数据隐藏(188****241张先生)
数据采集(数据爬虫)
数据过滤(论坛敏感词过滤)
数据验证(表单验证,手机号码,邮箱地址…)
二、JS标准库中的正则对象
2.1创建正则对象
- 字面量写法,以斜杠表示开始和结束:
var regex =/xyz/; - 构造函数生成,通过实例化得到对象:
var regex = new RegExp('xyz');
它们的主要区别是,第一种方法在编译时新建正则表达式,第二种方法在运行时新建正则表达式
考虑到书写的便利和直观,实际应用中,基本上都采用字面量的写法
2.2匹配模式
匹配模式也就是修饰符:
表示正则匹配的附加规则,放在正则模式的最尾部。
修饰符可以单个使用,也可以多个一起使用。
在正则表达式中,匹配模式常用的有两种形式:
g :global缩写,代表全局匹配,匹配出所有满足条件的结果,不加g第一次匹配成功后,正则对象就停止向下匹配;
i :ignore缩写,代表忽略大小写,匹配时,会自动忽略字符串的大小写
语法:
var reg = /正则表达式/匹配模式;
var regex = new RegExp('正则表达式','匹配模式');
2.3正则对象的方法
test(str) : 判断字符串中是否有指定模式的子串,返回bool
exec(str) : 返回字符串中指定模式的子串,一次只能获取一个与之匹配的结果
<body>
<input type="text" id='inp'>
<button id='btn'>匹配</button>
</body>
<script>
var btn = document.getElementById('btn');
btn.onclick = function(){
var str = document.querySelector('#inp').value;
var reg = /\d\d\d/;
console.log(reg.test(str)); //是否匹配成功
console.log(reg.exec(str)); //返回匹配后的结果,若失败返回null
}
</script>2.4 String对象的方法
search(reg) :与indexOf非常类似,返回指定模式的子串在字符串首次出现的位置
match(reg) :以数组的形式返回指定模式的字符串,可以返回所有匹配的结果
replace(reg,’替换后的字符’) :把指定模式的子串进行替换操作
split(reg) :以指定模式分割字符串,返回结果为数组
<body>
<input type="text" id='inp'>
<button id='btn'>匹配</button>
</body>
<script>
var btn = document.getElementById('btn');
btn.onclick = function(){
var str = document.querySelector('#inp').value;
var reg = /\d\d\d/;
console.log(str.search(reg)); //返回首次出现的位置
console.log(str.match(reg)); //返回所有匹配后的结果
console.log(str.replace(reg,'***')); //替换符合规则的字符串,并返回
console.log(str.split(reg)); //分割字符串
}
</script>三、几个重要概念
字表达式:
在正则表达式中,通过一对圆括号括起来的内容,我们就称之为“子表达式”。如:
var reg = /\d(\d)\d/gi;
捕获:
在正则表达式中,子表达式匹配到相应的内容时,系统会自动捕获这个行为,
然后将子表达式匹配到的内容放入系统的缓存区中。我们把这个过程就称之为“捕获”。
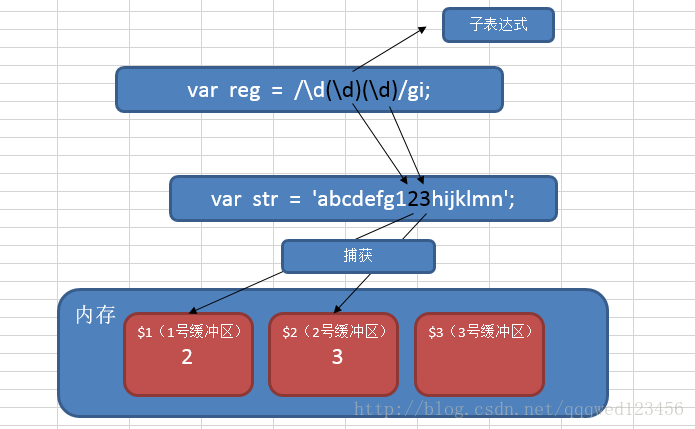
反向引用
就是在正则表达式中使用\n(n>0,正整数,代表系统中的缓冲区编号)来获取缓冲区中的内容,
我们把这个过程就称之为“反向引用”。
例:查找连续的相同的四个数字,如:1111、6666
var str = 'gh2396666j98889';
// 1:子表达式匹配数组
// 2:发生捕获行为,把子表达式匹配的结果放入缓存区
// 3:使用反向引用获取缓存中的结果进行匹配
var reg = /(\d)\1\1\1/;
console.log(str.match(reg)); 例2:查找数字,如:1221,3443
var reg = /(\d)(\d)\2\1/gi;
例3:查找字符,如:AABB,TTMM
(提示:在正则表达式中,通过[A-Z]匹配A-Z中的任一字符)
var reg = /([A-Z])\1( [A-Z])\2/g;
例4:查找连续相同的四个数字或四个字符
(提示:在正则表达式中,通过[0-9a-z])
var reg = /([0-9a-z])\1\1\1/gi;
四、编写正则表达式
4.1 正则表达式组成
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
正则表达式三步走
① 查什么(匹配符)
② 查多少(限定符)
③ 从哪查(定位符)
4.2 查什么(匹配符)
在正则表达式中,通过一对中括号括起来的内容,我们就称之为“字符簇”
| 字符簇 | 含义 |
|---|---|
| [a-z] | 匹配字符a到字符z之间的任一字符 |
| [A-Z] | 匹配字符A到字符Z之间的任一字符 |
| [0-9] | 匹配数字0到9之间的任一数字 |
| [0-9a-z] | 匹配数字0到9或字符a到字符z之间的任一字符 |
| [0-9a-zA-Z] | 匹配数字0到9或字符a到字符z或字符A到字符Z之间的任一字符 |
| [abcd] | 匹配字符a或字符b或字符c或字符d |
| [1234] | 匹配数字1或数字2或数字3或数字4 |
在字符簇中,通过一个^(脱字符)来表示取反的含义。
| 字符簇 | 含义 |
|---|---|
| [^a-z] | 匹配除字符a到字符z以外的任一字符 |
| [^0-9] | 匹配除数字0到9以外的任一字符 |
| [^abcd] | 匹配除a、b、c、d以外的任一字符 |
几个比较特殊的匹配符(常用)
| 字符簇 | 含义 |
|---|---|
| \d | 匹配一个数字字符,与使用[0-9]等价 |
| \D | 匹配一个非数字字符,还可以使用[^0-9] |
| \w | 匹配包括下划线的任何数字字母下划线字符,还可以使用[0-9a-zA-Z_] |
| \W | 匹配任何非字母数字下划线字符,还可以使用[^\w] |
| \s | 匹配任何空白字符 |
| \S | 匹配任何非空白字符,还可以使用[^\s] |
| .(我是一个点号) | 匹配除 “\n” (回车)之外的任何单个字符 |
| [\u4e00-\u9fa5] | 匹配中文字符中的任一字符 |
4.3 查多少(限定符)
什么是限定符?
限定符可以指定正则表达式的一个给定字符必须要出现多少次才能满足匹配。
? :匹配前面的表达式零次或一次,0或1
+ :匹配前面的表达式一次或多次,1到多
* :匹配前面的表达式零次或多次,0到多
{n} :匹配确定的 n 次
{n,} :至少匹配n 次
{n,m} :最少匹配 n 次且最多匹配 m 次对QQ号码进行校验要求5-13位,不能以0开头只能是数字
var str = '我的QQ20869921366666666666,nsd你的是6726832618吗?';
var reg = /[1-9]\d{4,12}/g;
console.log(str.match(reg));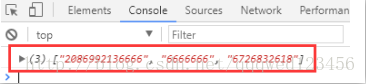
我们会发现以上代码运行结果中,默认优先配到 13 位,在对后面的进行匹配;
为什么不是优先匹配 5 位后,在对后面的进行匹配呢?
因为在正则表达式中,默认情况下,能匹配多的就不匹配少的,
我们把这种匹配模式就称之为 贪婪匹配,也叫做 贪婪模式
所有的正则表达式,默认情况下采用的都是贪婪匹配原则。
如果在限定符的后面添加一个问号?,
那我们的贪婪匹配原则就会转化为非贪婪匹配原则,优先匹配少的,也叫惰性匹配;
var str = '我的QQ20869921366666666666,nsd你的是6726832618吗?';
//非贪婪模式匹配,
var reg = /[1-9]\d{4,12}?/g;
console.log(str.match(reg));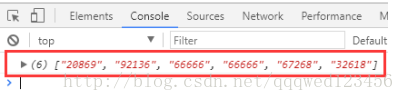
4.4 从哪查(定位符)
定位符可以将一个正则表达式固定在一行的开始或结束。
也可以创建只在单词内或只在单词的开始或结尾处出现的正则表达式。
^ (脱字符):匹配输入字符串的开始位置
$ :匹配输入字符串的结束位置
\b :匹配一个单词边界
\B :匹配非单词边界注意: ^ 放在字符簇中是取反的意思,放在整个表达式中是开始位置
var str = 'lsd15309873475';
var reg = /^1[34578]\d{9}$/;
console.log(reg.test(str));//falsevar str = 'i am zhangsan';
//an必须是一个完整的单词
var reg = /\ban\b/;
console.log(str.match(reg));
//an不能是单词的开始,只能是单词的结束
var reg = /\Ban\b/;
console.log(str.match(reg));4.5 转义字符
因为在正则表达式中 .(点) + \ 等是属于表达式的一部分,但是我们在匹配时,字符串中也需要匹配
这些特殊字符,所以,我们必须使用 反斜杠 对某些特殊字符进行转义;
需要转义的字符:
点号.
小括号()
中括号[]
左斜杠/
右斜杠\
选择匹配符|使用正则表达式验证邮箱是否合法
var str = 'qq@qq.com';
var reg = /\w+@[0-9a-z]+(\.[0-9a-z]{2,6})+/;
console.log(str.match(reg)); 4.6 或者的用法
查找所有属于苹果旗下的产品
var str = 'ipad,iphone,imac,ipod,iamsorry';
var reg = /\bi(pad|phone|mac|pod)\b/g;
console.log(str.match(reg)); //Array["ipad","iphone","imac","ipod"];4.7 预查
简单来说就是上个表达式查找到一个符合的结果后,向前方看看是否符合后面预查的要求,符合就返回
(?=)正向预查、正预测、前瞻、先行断言
请把ing结尾的单词的词根部分(即不含ing部分)找出来
var str = 'hello ,when i am working , don not coming';
\b只是找到了ing 结尾的单词,但并不是词根部分
// var reg = /\b\w+ing\b/g;
var reg = /\b\w+(?=ing\b)/g; //正向预查、正预测、前瞻
console.log(str.match(reg));(?!)负向预查、负预测、前瞻、现行否定
把不是ing结尾的单词找出来
var str = 'hello ,when i am working , don not coming';
//这里注意,判断是不是ing结尾的,必须最少有3位,才能查到,否则不够进行判断,就已经结束了
var reg = /\b\w+(?!ing)\w{3}\b/g; //负向预查、负预测、前瞻
console.log(str.match(reg)); (?:) :输出内容但不捕获
var str = ‘helloPHP,helloJavaScript’;
想要分别输出helloPHP ,helloJavaScript 如何做?
<script>
var str = 'hellophp,hellojavascript';
var reg = /hello(php|javascript)/gi;
var rs;
while(rs = reg.exec(str)){
document.write(rs+'<hr/>');
}
</script>运行结果:
特别说明:在正则表达式中,如果子表达式遇到了exec就会产生上面的结果。其返回结果是一个数组。
第一组元素,索引为0的数据hellophp,代表正则匹配到的结果
索引为1的数据php,代表是第一个子表达式匹配到的结果
第二组元素,索引为0的数据hellojavascript,代表正则表达式匹配到的结果
索引为1的数据javascript,代表是第一个子表达式匹配到的结果
如何解决以上问题呢?答:可以使用(?:)的形式,让正则表达式中的子表达式只输出内容,但不捕获。
前面说到()中的内容就是子表达式,子表达式匹配到数据就会捕获
解决方案:
<script>
var str = 'hellophp,hellojavascript';
var reg = /hello(?:php|javascript)/gi;
var rs;
while(rs = reg.exec(str)){
document.write(rs+'<hr/>');
}
</script>运行结果:














 1324
1324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









