






BP神经网络是神经网络的基础,其中可用随机梯度下降算法来加快更新权值和偏置,但是随机梯度下降算法总是忘记,下面来好好复习一下:
⼈们已经研究出很多梯度下降的变化形式,包括⼀些更接近真实模拟球体物理运动的变化形 式。这些模拟球体的变化形式有很多优点,但是也有⼀个主要的缺点:它最终必需去计算代价函数C的 ⼆阶偏导,这代价可是⾮常⼤的。为了理解为什么这种做法代价⾼,假设我们想求所有的⼆阶偏导
如果我们有上百万的变量vj,那我们必须要计算数万亿(即百万次的平⽅) 级别的⼆阶偏导4!这会造成很⼤的计算代价。不过也有⼀些避免这类问题的技巧,寻找梯度下 降算法的替代品也是个很活跃的研究领域。但在这里我们将主要⽤梯度下降算法(包括变化形式)使神经⽹络学习。
我们怎么在神经⽹络中⽤梯度下降算法去学习呢?其思想就是利⽤梯度下降算法去寻找能使得⽅程
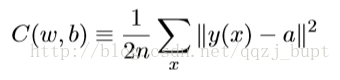
的代价取得最⼩值的权重wk和偏置bl。为了清楚这是如何⼯作的,我们将⽤权重和 偏置代替变量vj。也就是说,现在“位置”变量有两个分量组成:wk和bl,⽽梯度向量∇C则 有相应的分量∂C/∂wk和∂C/∂bl。⽤这些分量来写梯度下降的更新规则,我们得到:
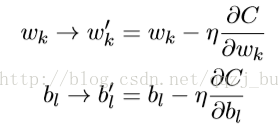
通过重复应⽤这⼀更新规则我们就能“让球体滚下⼭”,并且有望能找到代价函数的最⼩值。 换句话说,这是⼀个能让神经⽹络学习的规则。
应⽤梯度下降规则有很多挑战。我们将在下⼀章深⼊讨论。但是现在只提及⼀个问题。为了理解问题是什么,我们先回顾(6)中的⼆次代价。注意这个代价函数有着这样的形式即
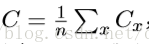
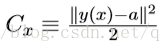
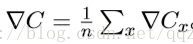
有种叫做随机梯度下降的算法能够加速学习。其思想就是通过随机选取⼩量训练输⼊样本来计算∇Cx,进⽽估算梯度∇C。通过计算少量样本的平均值我们可以快速得到⼀个对于实际梯 度∇C的很好的估算,这有助于加速梯度下降,进⽽加速学习过程。 更准确地说,随机梯度下降通过随机选取⼩量的m个训练输⼊来⼯作。我们将这些随机的训练输⼊标记为X1,X2,...,Xm,并把它们称为⼀个⼩批量数据(mini-batch)。假设样本数量 m⾜够⼤,我们期望∇CXj 的平均值⼤致相等于整个∇Cx的平均值,即:
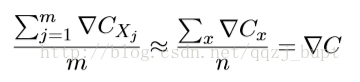
这⾥的第⼆个求和符号是在整个训练数据上进⾏的。交换两边我们得到
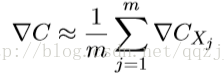
证实了我们可以通过仅仅计算随机选取的⼩批量数据的梯度来估算整体的梯度。
为了将其明确地和神经⽹络的学习联系起来,假设wk和bl表⽰我们神经⽹络中权重和偏置。 随即梯度下降通过随机地选取并训练输⼊的⼩批量数据来⼯作:
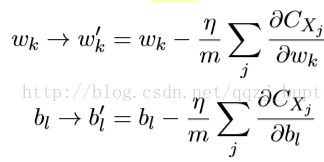
其中两个求和符号是在当前⼩批量数据中的所有训练样本Xj上进⾏的。然后我们再挑选另⼀随机选定的⼩批量数据去训练。直到我们⽤完了所有的训练输⼊,这被称为完成了⼀个训练迭代期(epoch)。然后我们就会开始⼀个新的训练迭代期。
另外值得提⼀下,对于改变代价函数⼤⼩的参数,和⽤于计算权重和偏置的⼩批量数据的更新规则,会有不同的约定。在⽅程(6)中,我们通过因⼦ 1/n来改变整个代价函数的⼤⼩。⼈们有时候忽略1/n,直接取单个训练样本的代价总和,⽽不是取平均值。这对我们不能提前知道训练数据数量的情况下特别有效。例如,这可能发⽣在有更多的训练数据是实时产⽣的情况下。同样,⼩批量数据的更新规则(20)和(21)有时也会舍弃前⾯的 1/m。从概念上这会有⼀点区别,因 为它等价于改变了学习速率η的⼤⼩。但在对不同⼯作进⾏详细对⽐时,需要对它警惕。 我们可以把随机梯度下降想象成⼀次⺠意调查:在⼀个⼩批量数据上采样⽐对⼀个完整数据集进⾏梯度下降分析要容易得多,正如进⾏⼀次⺠意调查⽐举⾏⼀次全⺠选举要更容易。例如,如果我们有⼀个规模为n = 60,000的训练集,就像MNIST,并选取⼩批量数据⼤⼩为m = 10, 这意味着在估算梯度过程中加速了6,000倍!当然,这个估算并不是完美的——存在统计波动 ——但是没必要完美:我们实际关⼼的是在某个⽅向上移动来减少C,⽽这意味着我们不需要梯度的精确计算。在实践中,随机梯度下降是在神经⽹络的学习中被⼴泛使⽤、⼗分有效的技术, 它也是⼤多数学习技术的基础。
参考::http://neuralnetworksanddeeplearning.com/。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









