



虽然Android平台使用Java语音来开发应用程序,但Android程序却不是运行在Java虚拟机上的。可能是为了解决移动设备上软件运行效率的问题,也可能是为了规避与Oracle公司的版权纠纷。Google为Android平台专门设计了一套虚拟机来运行Android程序,它就是Dalvik Virtual Machine(Dalvik虚拟机)。
Dalvik虚拟机特点
Dalvik虚拟机作为Android平台的核心组件,拥有如下几个特点:
- 体积小,占用内存空间小;
- 专有的DEX可执行文件格式,体积更小,执行速度更快;
- 常量池采用32为索引值,寻址类方法名、字段名、常量更快;
- 基于寄存器架构,并拥有一套完成的指令系统;
- 提供了对象生命周期管理、堆栈管理、线程管理、安全和异常管理以及垃圾回收等重要功能;
- 所有的Android程序都运行在Android系统进程里,每个进程对应着一个Dalvik虚拟机实例;
Dalvik虚拟机与Java虚拟机的区别
Dalvik虚拟机与传统的Java虚拟机有着许多不同点,两者并不兼容,它们显著的不同点主要表现在以下几个方面:
1. Java虚拟机运行的是Java字节码,Dalvik虚拟机运行的是Dalvik字节码
传统的Java程序经过编译,生成Java字节码保存在class文件中,Java虚拟机通过解析class文件中的内容来运行程序。而Dalvik虚拟机运行的是Dalvik字节码,所有的Dalvik字节码由Java字节码转换而来,并被打包到一个DEX可执行文件中,Dalvik虚拟机通过解析DEX文件来执行这些字节码。
2. Dalvik可执行文件体积更小
Android SDK中有一个叫dx的工具负责将Java字节码转为Dalvik字节码码。dx工具将Java类文件重新排列,消除在类文件中出现的所有冗余信息,避免虚拟机在初始化时出现重复的文件加载与解析过程。一般情况下,Java类文件中包含多个不同的方法签名,如果其中的类文件引用该类文件中的方法签名,方法签名也会被复制到基类文件中,也就是说,多个不同的类会同时包含相同的方法签名,同样地,大量的字符串常量在多个类文件中也被重复使用,这些冗余信息直接增加文件的体积,同时也会严重影响虚拟机解析文件的效率。dx工具针对这个问题专门做了处理,它将所有的Java类文件中的常量池进行分机,消除其中的冗余信息,重新组合形成一个常量池,所有的类文件共享同一个一个常量池。dx工具的转换过程如下图所示:
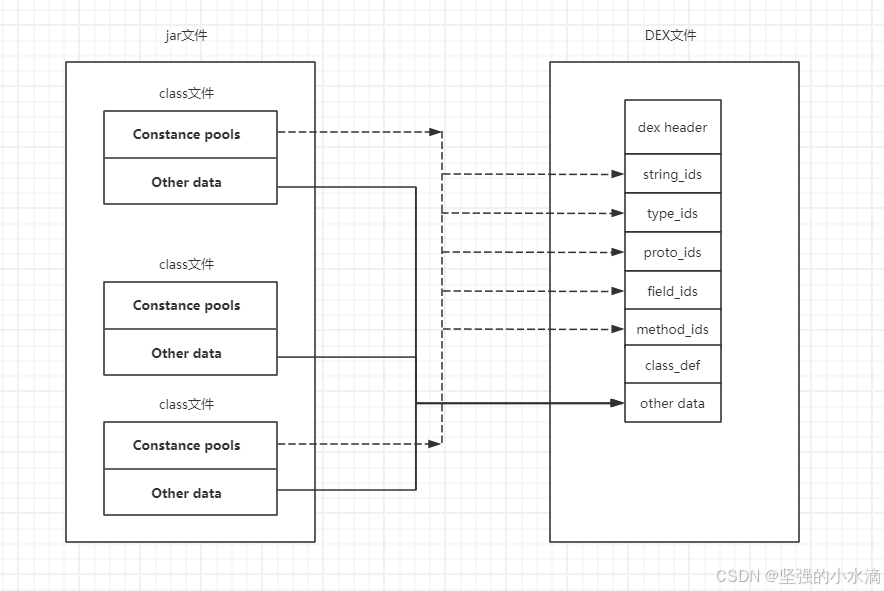
由于dex工具对常量池的压缩,使得相同的字符串、常量在DEX文件中只出现一次,从而减少了文件的体积。
3. Java 虚拟机与Dalvik虚拟机架构不同
Java虚拟机基于栈架构。程序在运行时虚拟机需要频繁的从栈上读取或写入数据,这个过程需要更多的指令分派与内存访问次数,会消耗不少的CPU时间,对于像手机设备资源有限的设备来说,这是相当大的一笔开销。
Dalvik虚拟机基于寄存器架构。数据的访问通过寄存器直接传递,这样的访问方式比基于栈方式要快很多。
下面通过一个实例来对比一下Java字节码与Dalvik字节码,测试代码如下:
public class Hello {
public int foo(int a,int b){
return (a + b) * (a - b);
}
public static void main(String[] args) {
Hello hello = new Hello();
System.out.println(hello.foo(5,3));
}
}
将以上内容保存为Hello.java。打开命令提示符,执行命令“javac Hello.java”编译生成Hello.class文件。然后执行命令“dx --dex --output=Hello.dex Hello.class”生成dex文件。接着使用javap反编译Hello.class 查看foo()函数的Java字节码,执行命令如下:
javap -c -classpath . Hello
命令执行后得到如下代码(部分代码):
public int foo(int, int);
Code:
0: iload_1
1: iload_2
2: iadd
3: iload_1
4: iload_2
5: isub
6: imul
7: ireturn
使用dexdump.exe(位于Android SDK 的build-tools目录中)查看foo()函数的Dalvik字节码,执行以下命令:
dexdump -d Hello.dex
可以得到如下代码(部分代码):
[000198] Hello.foo:(II)I
0000: add-int v0, v3, v4
0002: sub-int v1, v3, v4
0004: mul-int/2addr v0, v1
0005: return v0
查看上面的Java字节码,发现foo()函数一共占用了8个字节,代码中的每条指令占用1个字节,并且这些指令都没有参数。那么这些指令时如果存取数据的呢?Java虚拟机的指令集被称为领地址形式的指令集,所谓零地址形式,是指指令的源参数与目标参数都是隐含的,它通过Java虚拟机中提供的一种数据结构“求值栈”来传递的。
对于Java程序来说,每个线程在执行时都有一个PC计数器与一个Java栈。PC计数器以字节为单位记录当前运行位置距离方法开头的偏移量,它的作用类似于ARM架构CPU的PC寄存器与x86架构CPU的IP寄存器,不同的是PC计数器只对当前方法有效,Java虚拟机通过它的值来取指令执行。Java栈用于记录Java方法调用的“活动记录”(activation record),Java栈以帧(frame)为单位保存线程的运行状态,每调用一个方法就会分配一个新的栈帧压入Java栈上,每从一个方法返回则弹出并撤销相对应的栈帧。每个栈帧包括局部变量区、求值栈(JVM规范中将其称为“操作数栈”)和其他一些信息。局部变量区用于存放方法的参数与局部变量,其中参数按源码中的从左到右顺序保存在局部变量区开头的几个slot中。求值栈用于保存求值的中间结果和调用别的参数等,JVM运行时它的状态结构图如下:
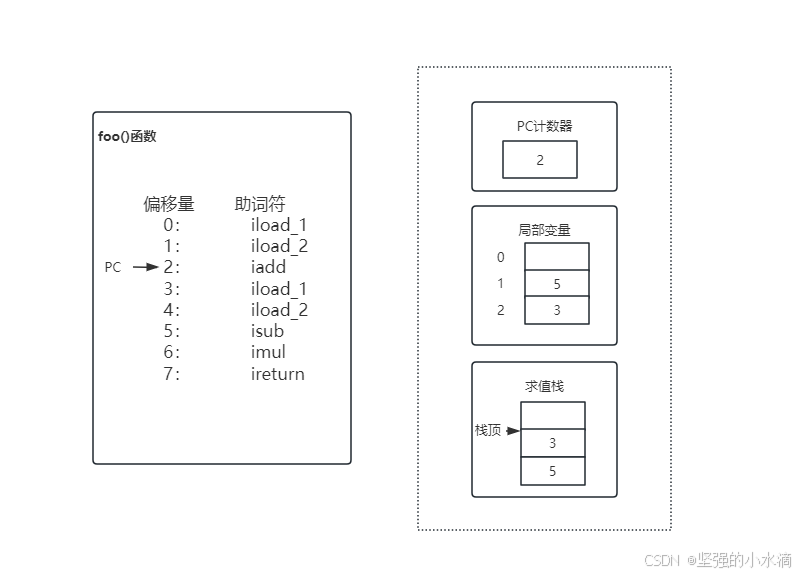
结合代码来理解上面的理论知识。由于每条指令占用一个字节空间,foo()函数Java字节码左边的偏移量就是程序执行到每一行代码时PC的值,并且Java虚拟机最多只支持0xff条指令。第一条指令iload_1可分成两部分:第一部分为下划线左边的iload,它属于JVM指令集中load系列中的一条,i是指令前缀,表示操作类型为int类型,load表示将局部变量存入Java栈,与之类似的有lload、fload、dload分别表示将long、float、double类型的数据进栈;第二部分为下划线右边的数字,表示要操作具体哪个局部变量,索引值从0开始计数,iload_1表示将第二个int类型的局部变量进栈,这里第二个局部变量是存放在局部变量区foo()函数的第一个参数,索引值为0存放的是该对象引用this。同理,第2条指令iload_2取第二个参数。第3条指令iadd从栈顶弹出两个int类型值,将值相加,然后把结果压回栈顶。第4、5条指令分别再次压入第一个参数与第二个参数。第6条指令isub从栈顶弹出两个int类型值,将值相减,然后把结果压回栈顶。这时求值栈上有两个int值了。第7条指令imul从栈顶弹出两个int类型值,将值相乘,然后把结果压回栈顶。第8条指令ireturn函数返回一个int值。到这里foo()函数就执行完了。
比起Java虚拟机字节码,上面的Dalvik字节码显得简洁很多,只有4条指令就完成了上面的操作。第一条指令add-int将v3与v4寄存器的值相加,然后保存到v0寄存器,整个指令的操作中使用到了三个参数,v3与v4分别代表foo()函数的第一个参数与第二个参数,他们是Dalvik字节码参数表示法之一v命名发,另一种事p命名法。第二条指令sub-int将v3减去v4的值保存到v1寄存器。第三条指令mul-int/2addr将v0乘以v1的值保存到v0寄存器。第四条指令返回v0的值。
Dalvik虚拟机运行时同样为每个线程维护一个PC计数器与调用栈,与Java虚拟机不同的是,这个调用栈维护一份寄存器表,寄存器的数量在方法结构体的register字段中给出,Dalvik虚拟机会根据这个值来创建一份虚拟机的寄存器列表。Dalvik虚拟机运行时的状态图如下:
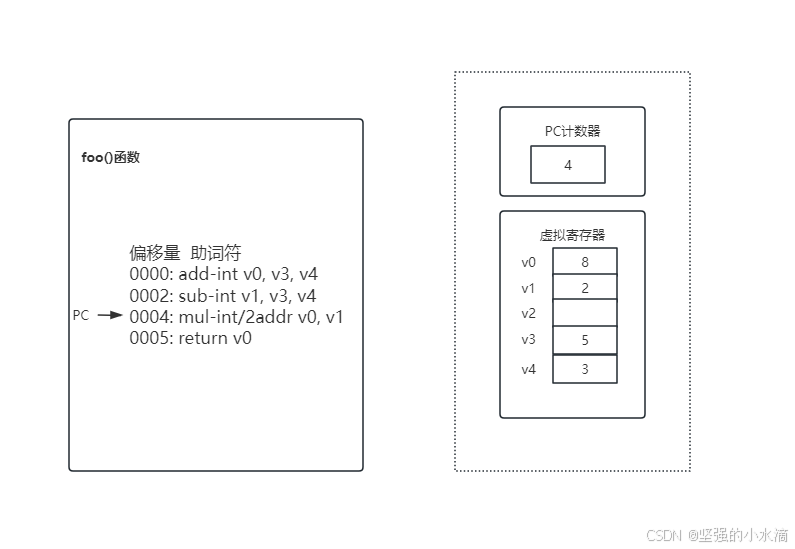
通过上面的分析可以发现,基于寄存器架构的Dalvik虚拟机与基于架构的Java虚拟机相比,由于生成的代码指令减少了,程序执行速度会更快一些。
Dalvik虚拟机是如何执行程序的
Android系统的架构采用分层思想,这样的好处是拥有减少各层之间的依赖性、便于独立分发、容易收敛问题和错误等优点。Android系统有Linux内核、函数库、Android运行时、应用程序框架以及应用程序组成。如下为Android系统架构所示图,Dalvik虚拟机属于Android运行时环境,它与一些核心库共同承担Android应用程序的运行工作。
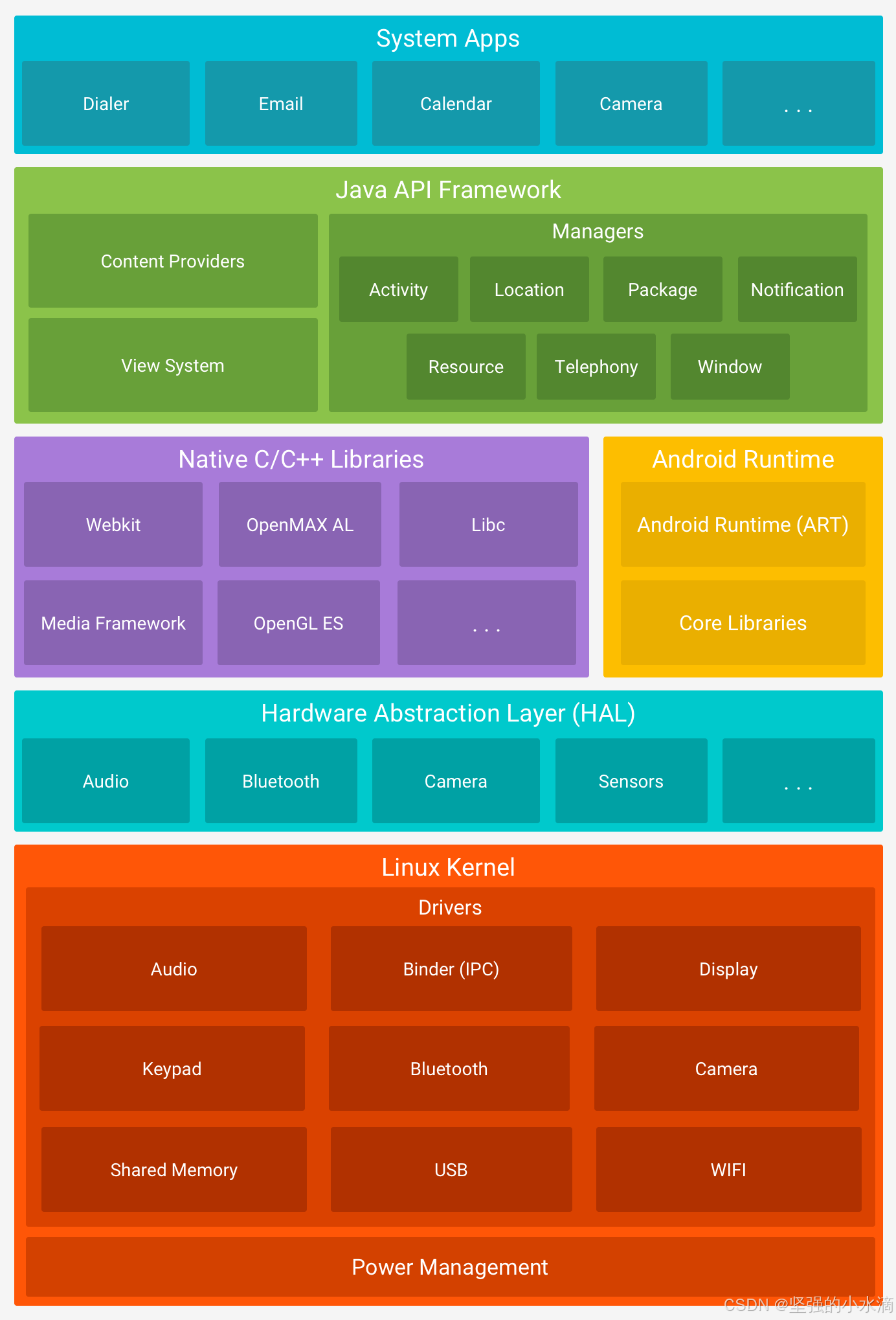
Android系统启动加载完成内核之后,第一个执行的是init进程,init进程首先要做的是设备的初始化工作,然后读取init.rc文件并启动系统中的重要外部程序Zygote。Zygote进程是Android所有进程的孵化器进程,它启动后会首先初始化Dalvik虚拟机,然后启动system_server并进入Zygote模式,通过socket等后命令。当执行一个Android应用程序时,system_server进程通过socket方式发送命令给Zygote,Zygote收到命令后通过fork自身创建一个Dalvik虚拟机的示例来执行应用程序入口函数,这样一个程序就启动完成了。整个流程如下:
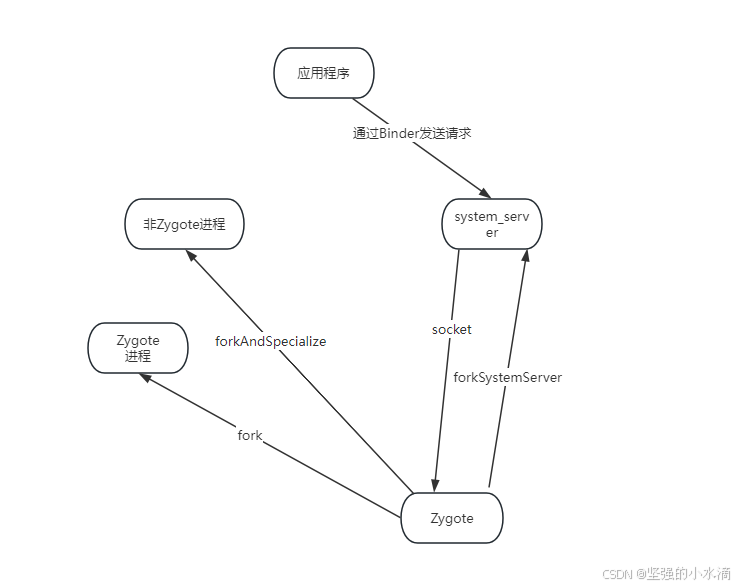
Zygote 提供了三种创建进程的方法:
- fork():创建一个Zygote进程;
- forkAndSpecialize():创建一个非Zygote进程;
- forkSystemServer():创建一个系统服务进程;
其中Zygote进程可以再fork()出其他进程,非Zygote进程则不能fork其他进程,而系统服务进程在终止后它的子进程也必须终止。
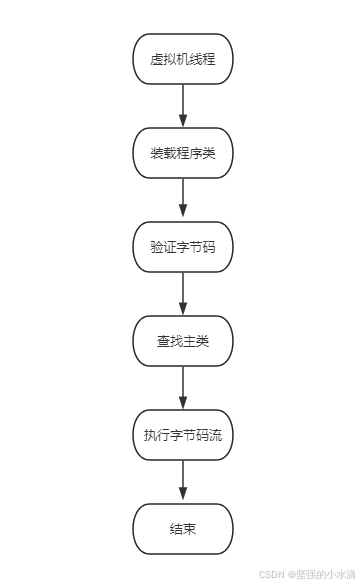
当进程fork成功后,执行的工作就交给了Dalvik虚拟机。Dalvik虚拟机首先通过loadClassFromDex()函数完成类的装载工作,每个类被成功解析后都护拥有一个ClassObject类型的数据结构存储在运行时环境中,虚拟机使用gDvm.loadedClasses全局哈希表来存储与查找所有装载进来的类,随后,字节码验证器使用dvmVerifyCodeFlow()函数对装入的代码进行效验,接着虚拟机调用findClass()函数查找并装载main方法类,随后调用dvmInterpret()函数初始化解释器并执行字节码流。整个过程如下:
关于Dalvik虚拟机JIT(即时编译)
JIT(Just-in-time Compilation,即时编译),又称为动态编译,是一种通过在运行时将字节码翻译为机器码的技术,使得程序的执行速度更快。Android2.2版本系统的Dalvik虚拟机引入JIT技术,官方宣称新版的Dalvik虚拟机比以往执行速度快3~6倍。
主流的JIT包含两种字节码编译方式:
- method方式:以函数或方法为单位进行编译;
- trace方式:以trace为单位进行编译;
method方式很好理解,那什么事trace方式呢?在函数中一般很少是顺序执行代码的,多数的代码都是分成好几条执行路径,其中函数的有些路径在实际运行过程中是很少被执行的,这部分路径被称为“冷路径”,而执行比较频繁的路径被称为“热路径”。采用传统的method方式会编译整个方法的代码,这会使得在“冷路径”上浪费很多编译时间,并且耗费更多的内存;trace方式编译则能够快速地获取“热路径”代码,使用更短的时间与更少的内存来编译代码。
目前,Dalvik虚拟机默认采用trace方式编译代码,同时也支持采用method方式来编译。

















 4606
4606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









