









前言
llama-Factory尝试使用Ollama本地安装的大模型。
一、在Ollama中安装QWen
安装qwen:0.5b

安装完成了:

同理安装qwen2.5:0.5b

安装完毕后,再用ollama list进行查看:

我们在chatbox中进行查看:

说明这两个大模型,已经通过Ollama安装到了本地。
二、试图在llama-Factory中挂接Ollama中的大模型
Llama-Factory起初启动的页面是这样,这两个框中是空的:
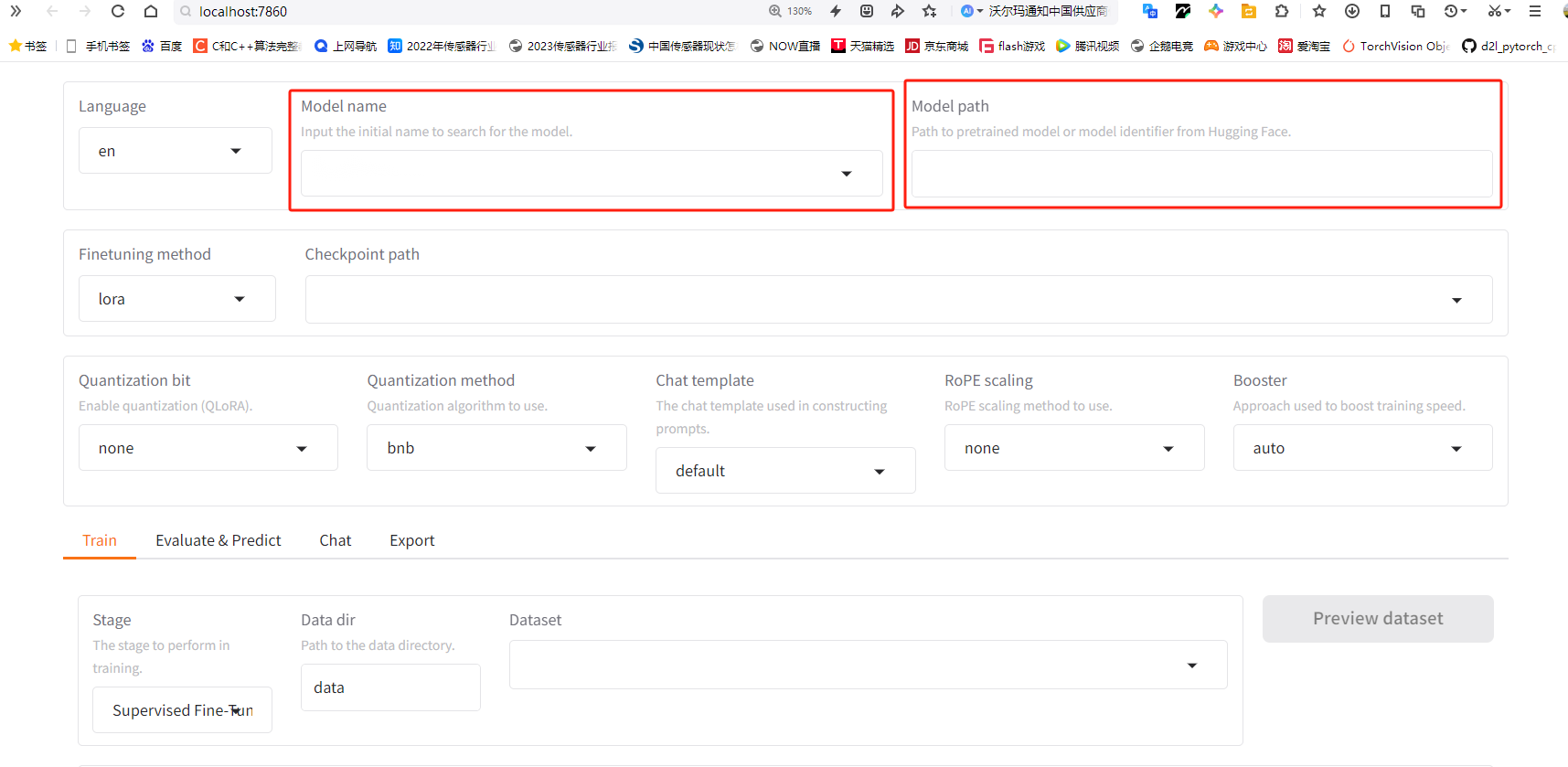
我们可以在Model Path当中填入Ollama中models的路径,具体如下:
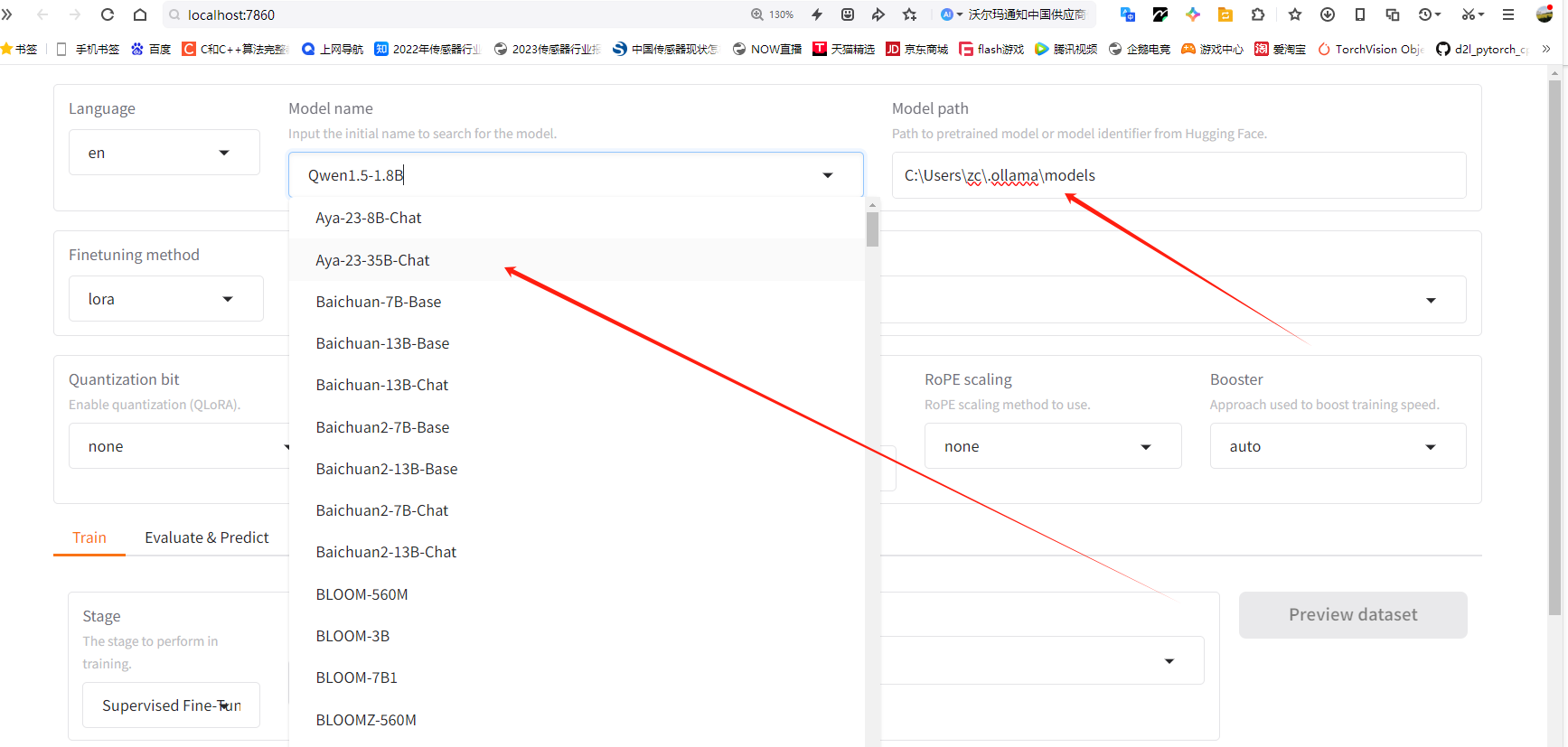
如上图,我们惊奇的发现,随着有些models路径的填入,左侧模型下拉列表也出现了,
我们可以选择模型了。
于是,我选择了Qwen2.5:0.5B,如下图:
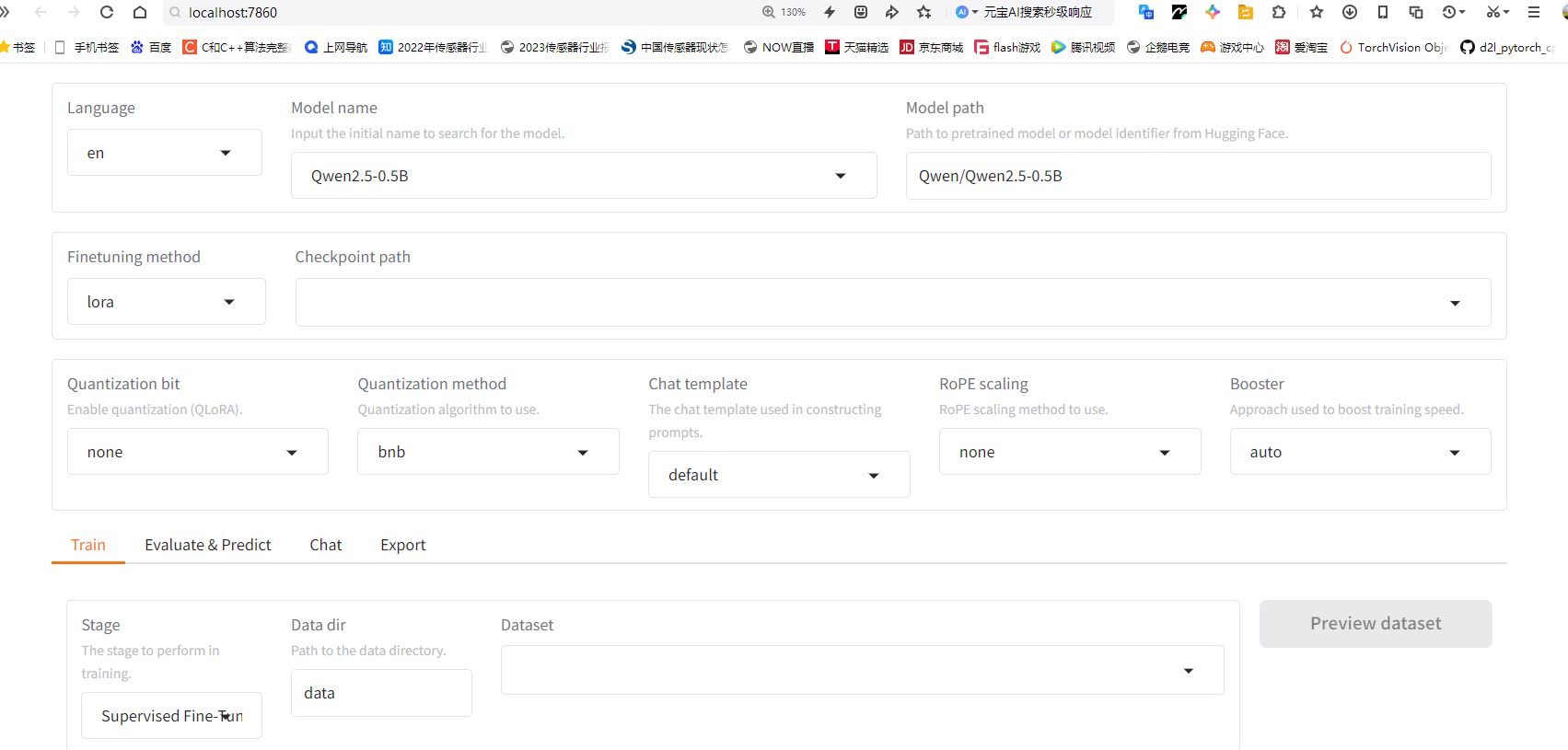
选择自带的数据集尝试微调:
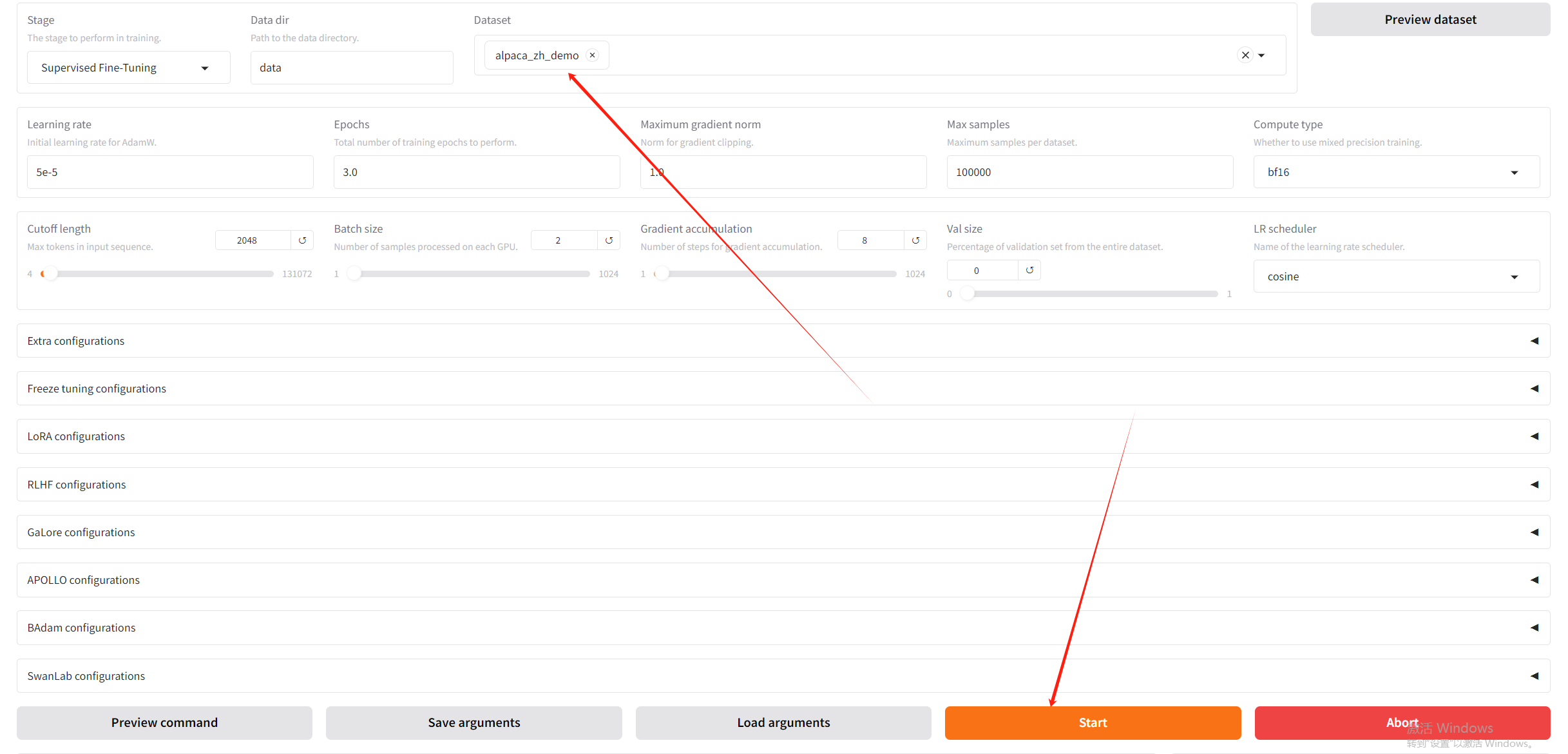
会发现一堆错误,模型Load失败,如下图:
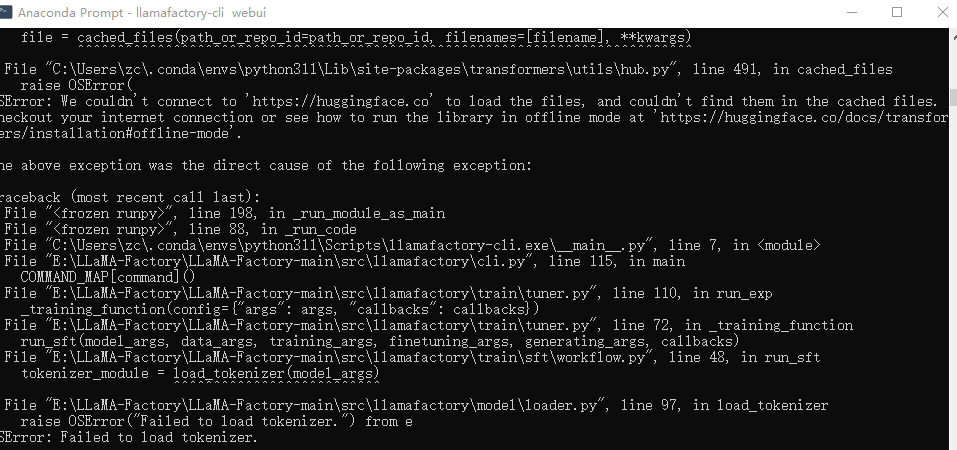
难道是llama-factory不适合从Ollama上加载模型么?
(或者说Ollama已经加载了模型,再用llama-factory来加载,是否造成了冲突)
错误的原因主要是:llama-Factory加载的模型需要是huggingface的,从魔搭社区下载比较合适。



















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











