







内容来自Andrew老师课程Machine Learning的第三章内容的Logistic Regression Model部分。
一、Cost Function(代价函数)
有m个样本的训练集:
{
(
x
(
1
)
,
y
(
1
)
)
,
(
x
(
2
)
,
y
(
2
)
)
,
.
.
.
.
,
(
x
(
m
)
,
y
(
m
)
)
}
\{(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), ...., (x^{(m)}, y^{(m)})\}
{(x(1),y(1)),(x(2),y(2)),....,(x(m),y(m))},
X
=
[
x
0
x
1
.
.
.
x
n
]
∈
R
n
+
1
X=\begin{bmatrix} x_0\\ x_1\\ .\\ .\\ .\\ x_n \end{bmatrix} \in R^{n+1}
X=⎣⎢⎢⎢⎢⎢⎢⎡x0x1...xn⎦⎥⎥⎥⎥⎥⎥⎤∈Rn+1,
x
0
=
1
,
y
∈
{
0
,
1
}
x_0=1, y \in \{0,1\}
x0=1,y∈{0,1}.
在上篇博文中提到假设函数
h
θ
(
x
)
:
h
θ
(
x
)
=
1
1
+
e
−
θ
T
x
h_\theta(x):h_\theta(x)=\frac{1}{1 + e^{-\theta^Tx}}
hθ(x):hθ(x)=1+e−θTx1。
那么,我们如何选择参数theta呢?
在线性回归模型中, J ( θ ) = 1 m ∑ i = 1 m 1 2 ( h θ ( x ( i ) − y ( i ) ) 2 J(\theta)=\frac{1}{m}\sum_{i=1}^m\frac{1}{2}(h_\theta(x^{(i)}-y^{(i)})^2 J(θ)=m1∑i=1m21(hθ(x(i)−y(i))2,令 1 2 ( h θ ( x ( i ) − y ( i ) ) 2 = c o s t ( h θ ( x ( i ) ) , y ( i ) ) \frac{1}{2}(h_\theta(x^{(i)}-y^{(i)})^2=cost(h_\theta(x^{(i)}), y^{(i)}) 21(hθ(x(i)−y(i))2=cost(hθ(x(i)),y(i)),为方便记录,将此等式记为: c o s t ( h θ ( x ) , y ) = 1 2 ( h θ ( x ) − y ) 2 cost(h_\theta(x), y)=\frac{1}{2}(h_\theta(x)-y)^2 cost(hθ(x),y)=21(hθ(x)−y)2,
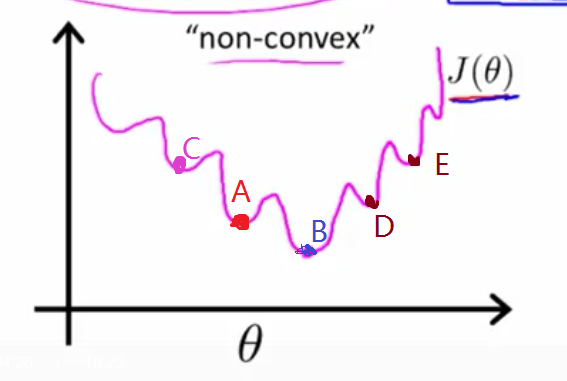
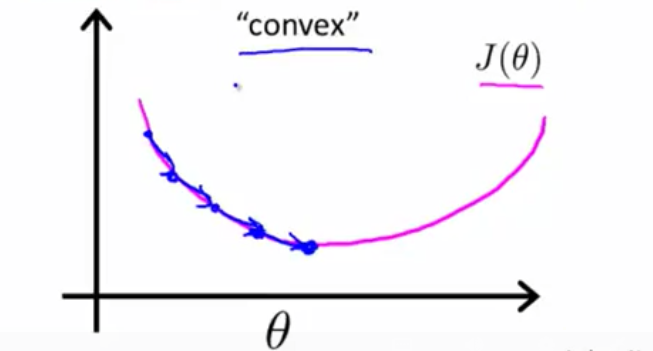
因为 h θ ( x ) = 1 1 + e − θ T x h_\theta(x)=\frac{1}{1 + e^{-\theta^Tx}} hθ(x)=1+e−θTx1是非线性的,故 c o s t ( h θ ( x ) , y ) cost(h_\theta(x), y) cost(hθ(x),y)也是非线性的,将其代入J(theta),则J(theta)曲线图很有可能出现下列情况,如下左图:
J
(
θ
)
J(\theta)
J(θ) 在这种情况下,不收敛。
即:J存在多个局部最小值(A,B,C,D,E等都是)。但是使用梯度下降法不一定能找到最优值,比如在梯度下降算法走到A点,再往下走发现B点的J值比A点的J值大了,因此算法停止搜索并断定A是最小值点,此时便没有找到最小值。
而我们希望出现的右图所示的情况,梯度下降算法能一步一步往下走,直到找到最小值。
产生这种情况的原因是因为 h θ ( x ) = 1 1 + e − θ T x h_\theta(x)=\frac{1}{1 + e^{-\theta^Tx}} hθ(x)=1+e−θTx1中含有平方,故使用线性回归的代价函数来用于logsitic模型是不合适的,因此我们用一个新函数来定义logistic的cost函数:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
{
−
l
o
g
(
h
θ
(
x
)
)
y
=
1
−
l
o
g
(
1
−
h
θ
(
x
)
)
y
=
0
Cost(h_\theta(x),y) = \left\{\begin{matrix} -log(h_\theta(x)) & y=1 \\ -log(1-h_\theta(x))& y=0 \end{matrix}\right.
Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))y=1y=0
(1)当y=1时,Cost函数图如下所示:
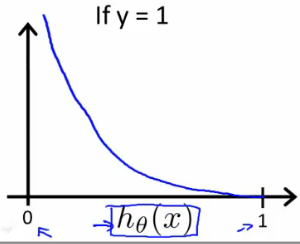
由图可知:
当
h
θ
(
x
)
=
1
h_\theta(x) =1
hθ(x)=1时,
c
o
s
t
=
0
cost=0
cost=0;
当
h
θ
(
x
)
→
0
h_\theta(x) \rightarrow 0
hθ(x)→0时,
c
o
s
t
→
∞
cost \rightarrow ∞
cost→∞。
当y=1,
若预测值
h
θ
(
x
)
=
1
h_\theta(x)= 1
hθ(x)=1,则预测值和实际值相同,因此cost=0;
若预测值
h
θ
(
x
)
→
1
h_\theta(x) \rightarrow 1
hθ(x)→1,即
h
θ
(
x
)
=
p
(
y
=
1
∣
x
;
θ
)
→
0
h_\theta(x) =p(y=1|x;\theta) \rightarrow 0
hθ(x)=p(y=1∣x;θ)→0,即预测值为0,因为实际值为1,故代价函数cost为无穷大。
(2)当
y
=
0
y=0
y=0时,Cost函数图如下所示:
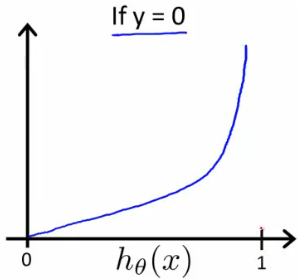
由图可知:
当
h
θ
(
x
)
=
1
h_\theta(x)=1
hθ(x)=1,即预测值为1时,而真实值为0,此时cost->∞;
当
h
θ
(
x
)
=
0
h_\theta(x)=0
hθ(x)=0,即预测值为0,而真实值也为0,此时cost=0。
附上一个例题:
二、Simplified Cost Function and Gradient Descent(简化代价函数和梯度下降)
logsitic回归代价函数为:
J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x ( i ) ) , y ( i ) ) C o s t ( h θ ( x ) , y ) = { − l o g ( h θ ( x ) ) y = 1 − l o g ( 1 − h θ ( x ) ) y = 0 J(\theta) = \frac{1}{m} \sum_{i=1}^mCost(h_\theta(x^{(i)}),y^{(i)}) \\ Cost(h_\theta(x),y) = \left\{\begin{matrix} -log(h_\theta(x)) & y=1 \\ -log(1-h_\theta(x))& y=0 \end{matrix}\right. J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))y=1y=0
Note: y = 0 y=0 y=0 or y = 1 y=1 y=1 always
我们将这个Cost分段函数写成一个函数,则:
C o s t ( h θ ( x ) , y ) = − y l o g ( h θ ( x ) ) + [ − ( 1 − y ) l o g ( 1 − h θ ( x ) ) ] Cost(h_\theta(x), y) = -y log(h_\theta(x)) + [-(1-y)log(1- h_\theta(x))] Cost(hθ(x),y)=−ylog(hθ(x))+[−(1−y)log(1−hθ(x))]
验证一下为什么可以写成这一个式子:
因为y只可能取0或者1:
(1)若
y
=
1
y=1
y=1,代入上式,则
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
l
o
g
h
θ
(
x
)
Cost(h_\theta(x),y)=-logh_\theta(x)
Cost(hθ(x),y)=−loghθ(x)满足分段函数表达式。
(2)若
y
=
0
y=0
y=0,代入上式,则
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
l
o
g
(
1
−
h
θ
(
x
)
)
Cost(h_\theta(x),y)=-log(1-h_\theta(x))
Cost(hθ(x),y)=−log(1−hθ(x))也满足分段函数表达式。
因此这个式子和分段函数表达式是等价式。
(一)J函数
将上述cost函数代入 J ( θ ) J(\theta) J(θ),则
J
(
θ
)
=
1
m
∑
i
=
1
m
c
o
s
t
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
=
−
1
m
[
∑
i
=
1
m
y
(
i
)
l
o
g
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
]
\begin{aligned} J(\theta) &=\frac{1}{m}\sum_{i=1}^{m}{cost(h_\theta(x^{(i)}),y^{(i)})} \\ &=-\frac{1}{m}[\sum_{i=1}^m{y^{(i)}log{h_\theta(x^{(i)})}+(1-y^{(i)})log(1-h_\theta(x^{(i)}))}] \end{aligned}
J(θ)=m1i=1∑mcost(hθ(x(i)),y(i))=−m1[i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
将
J
(
θ
)
J(\theta)
J(θ)函数向量化表示为:
h = g ( X θ ) J ( θ ) = 1 m ( − y T l o g ( h ) − ( 1 − y ) T l o g ( 1 − h ) \begin{aligned} h &=g(X\theta) \\ J(\theta) &=\frac{1}{m}{(-y^Tlog(h)-(1-y)^Tlog(1-h)} \end{aligned} hJ(θ)=g(Xθ)=m1(−yTlog(h)−(1−y)Tlog(1−h)
为了求出
θ
\theta
θ值,我们通过求
m
i
n
J
(
θ
)
minJ(\theta)
minJ(θ)来求,即利用梯度下降算法来求。
预测输出是指:输入x值,输出
h
θ
(
x
)
=
1
1
+
e
−
θ
T
x
h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}
hθ(x)=1+e−θTx1,即
P
(
y
=
1
∣
x
;
θ
)
P(y=1|x;\theta)
P(y=1∣x;θ)。
(二)梯度下降算法:
梯度下降公式:
θ
j
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
)
\begin{aligned} \theta_j &=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta) \end{aligned}
θj=θj−α∂θj∂J(θ)
(注意同步更新)
将偏导数部分代入得:
θ j = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \begin{aligned} \theta_j &=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \end{aligned} θj=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
将梯度下降算法向量表示得:
θ
=
θ
−
α
m
X
T
(
g
(
X
θ
)
−
y
)
\begin{aligned} \theta &=\theta-\frac{\alpha}{m}X^T(g(X\theta)-y) \end{aligned}
θ=θ−mαXT(g(Xθ)−y)
Note:虽然分类回归的梯度下降函数和线性回归的梯度下降函数看起来一样,但是其并不相同,因为在线性回归中
h
θ
(
x
)
=
θ
T
x
h_\theta(x)=\theta^Tx
hθ(x)=θTx,而在分类回归中
h
θ
(
x
)
=
1
1
+
e
−
θ
T
x
h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}
hθ(x)=1+e−θTx1,所以h(x)函数部分不同,导致二者不相同。
三、Advanced Optimization(优化问题)
(1)首先看梯度下降算法,在实现梯度下降算法的过程中,我们需要实现J函数及其偏导数对应的代码:
(2)再来看看除了梯度下降算法之外的其他的优化算法,后三种优化算法性能比较好,但是实现过程比较复杂,理解也比较难(本节不讲述细节):


(3)举例说明如何实现优化算法的调用,代码细节如下图,其中fminunc()用于实现最小代价函数的调用:

(4)如何将这些优化算法应用到logistic回归中呢?如下图,在具体实现时我们只需要填写相应的实现代码:

我们要做的就是不断探索,将高级优化应用于logistic回归和线性回归以提高寻找最小代价函数对应theta值得效率。
四、逻辑回归算法的并行化
如上所示,逻辑回归的偏导数形式为 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} m1∑i=1m(hθ(x(i))−y(i))xj(i),假设数据集共有 K K K类,则:
1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) = 1 m ∑ k = 1 K ∑ i ∈ C k ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \begin{aligned} & \quad \frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \\ &= \frac{1}{m}\sum_{k=1}^{K}\sum_{i \in C_k}^{}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \end{aligned} m1i=1∑m(hθ(x(i))−y(i))xj(i)=m1k=1∑Ki∈Ck∑(hθ(x(i))−y(i))xj(i)
其中, C k C_k Ck是所有类别的一个partition。所以对于logistic回归来讲,并行的地方是每个类别之间的并行化。
参考文章:[链接](http://blog.csdn.net/u012328159/article/details/51077330 "链接")














 2751
2751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









