






title: HttpGet请求数据乱码的原因
date: 2022-04-29 00:23:00
categories:
- 后端开发技术
tags: - http
- get
- 乱码
今天面试,过程中被问到了get乱码的原因以及解决方案,当时脑子当中直接卡机,心想怎么会被问到这问题,貌似最近一段时间的开发都没有碰到get乱码的问题了,本着学习还是网上搜索了解了一下。
乱码的由来
当使用地址栏提交查询参数时,如果不编码,非英文字符会按照操作系统的字符集进行编码提交到服务器,服务器会按照配置的字符集进行解码,所以如果编码时使用的编码字符集和解码使用的解码字符集不一致,就会导致乱码。
解决方法
针对这种情况,可以连续使用两次encodeURI在客户端(主要指浏览器)对非英文字符进行编码,然后在服务端使用java.net.URLDecoder.decode(s,"UTF-8")解码,即可得到正确的中文。
如果只进行一次encodeURI,得到的是UTF-8形式的URL,服务器端通过request.getParameter()解码查询参数(通常是iso-8859-1)就会得到乱码。(这里有关request.getParameter()的解码,后面会解释)。
如果进行两次encodeURI,第一次编码得到的是UTF-8形式的URL,第二次编码得到的依然是UTF-8形式的URL,但是在效果上相当于首先进行了一次UTF-8编码(此时已经全部转换为ASCII字符),再进行了一次iso-8859-1编码,因为对英文字符来说UTF-8编码和ISO-8859-1编码的效果相同。在服务器端,首先通过request.getParameter()自动进行第一次解码(可能是gb2312,gbk,utf-8,iso-8859-1等字符集,对结果无影响)得到ascii字符,然后再使用UTF-8进行第二次解码,通常使用java.net.URLDecoder("","UTF-8")方法。
两次编码两次解码的过程为:UTF-8编码->UTF-8(iso-8859-1)编码->iso-8859-1解码->UTF-8解码,编码和解码的过程是对称的,所以不会出现乱码。
encodeURL函数主要是来对URI来做转码,它默认是采用的UTF-8的编码。
UTF-8编码的格式:一个汉字来三个字节构成,每一个字节会转换成16进制的编码,同时添加上%号。
图解
以服务器端的两次URLEncoder.encode()为例,jsp页面的两次encodeURI()原理一致:

由图解就可以清楚的了解到,只要第一次encode和第四次decode的字符集一致,那么不管中间的第二次和第三次的字符集是什么,都可以正常的解析出中文,这也就是为什么两次encode可以屏蔽不同浏览器编码方式不一样所导致的中文乱码问题了。
注意事项
解释一下,为什么当我们手动在url地址框中拼接中文时,只需要讲汉字一次encode就可以了,但是明明图解时要encode两次才可以啊?因为当我们使用浏览器来发送请求时,他会自动给你加一次encode。所以我们只需要把汉字中的第一次encode得到的%E4%B8%AD来代替“中”就好了。
我已必应搜索给你们演示一下浏览器的主动encode,当我们搜索汉字“中”时,他发送的url其实把中进行了编码:
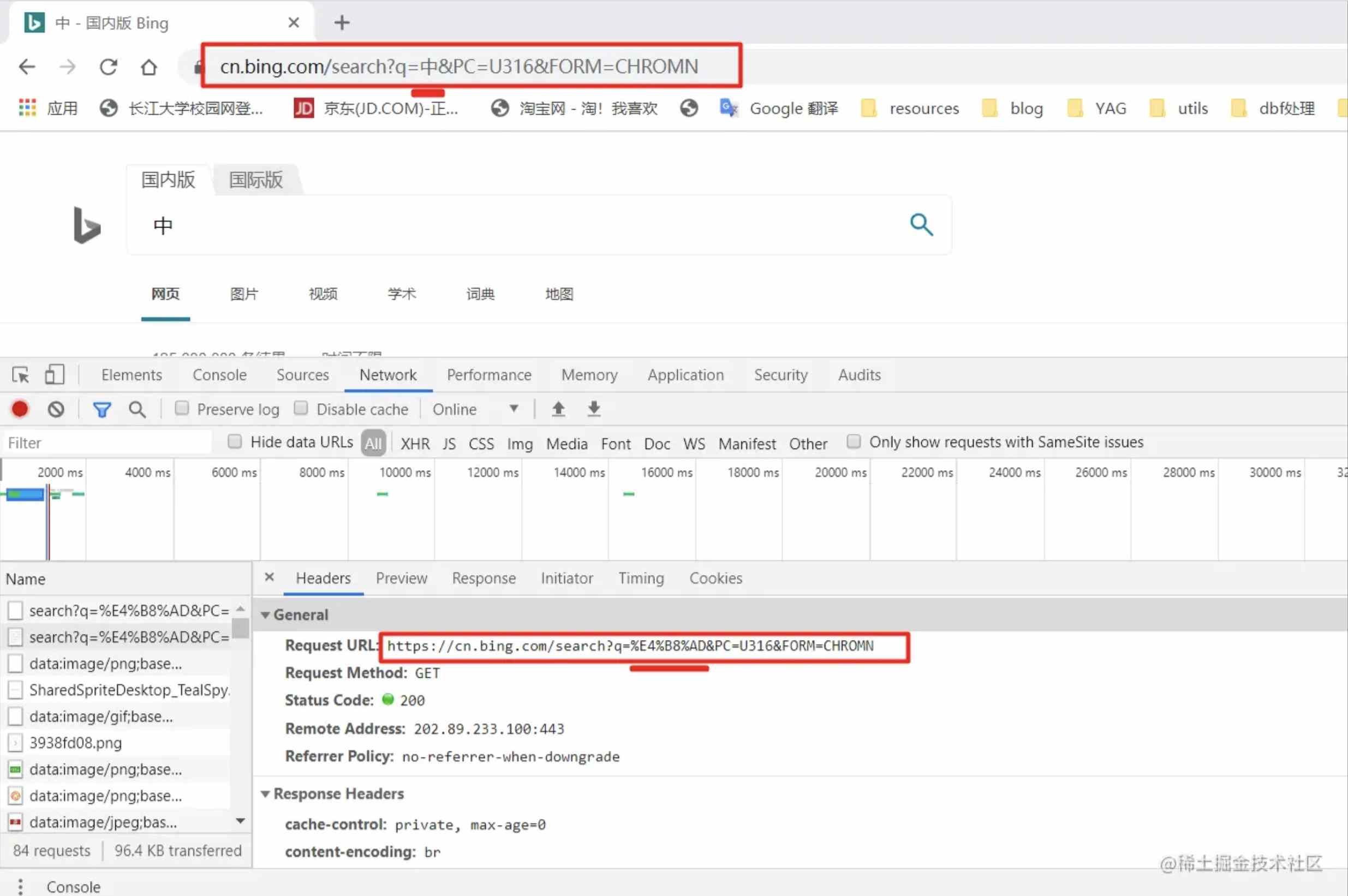
当我们搜索%E4%B8%AD时,他会对%E4%B8%AD再次编码:

所以,只要是通过浏览器地址栏发送的请求,浏览器都会进行一次主动encode,所以如果我们手动在地址栏拼接中文,就只需要一次encode,另一次encode交给浏览器自己就好了,实质上还是两次encode。
而当我们用window.location.href=encodeURI(encodeURI('<%=basePath%>info/getProject?schoolName=' + name));或者return"redirect:/info/getProject?schoolName=" + encodeTwice;的时候,这个时候我们两次编码得到的参数是什么样就是什么样,浏览器不会再重复进行一次编码,所以这个时候需要手动写两次encode。
对于使用框架,比如Struts和springmvc来说,request.getParameter()就不需要手动来写了。当框架为我们封装参数时,已经做了这一步,所以在使用框架的时候,直接把封装好了的参数进行decode就好了。实质上还是进行了两次decode`。
完
阅读原文:https://juejin.cn/post/6844904089197740046
https://www.jsnds.cn/2022/04/29/002300.html















 5109
5109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









