







各位小伙伴们,对于KMP难以理解请跳转字符串匹配——KMP算法-CSDN博客
7-1 字符串模式匹配(KMP)
给定一个字符串 text 和一个模式串 pattern,求 pattern 在text 中的出现次数。text 和 pattern 中的字符均为英语大写字母或小写字母。text中不同位置出现的pattern 可重叠。
输入格式:
输入共两行,分别是字符串text 和模式串pattern。
输出格式:
输出一个整数,表示 pattern 在 text 中的出现次数。
输入样例1:
zyzyzyz
zyz
输出样例1:
3
输入样例2:
AABAACAADAABAABA
AABA
输出样例2:
3
数据范围与提示:
1≤text, pattern 的长度 ≤106, text、pattern 仅包含大小写字母。
#include<stdio.h>
#include<string.h>
int main()
{
char a[1000010],b[1000010];
int next[1000010];
int i,j=0;
scanf("%s %s",a+1,b+1);
int n=strlen(a+1),m=strlen(b+1);
for(i=2;i<=m;i++)
{
while(j&&b[i]!=b[j+1])
j=next[j];
if(b[i]==b[j+1])
j++;
next[i]=j;
}
int count=0;
j=0;
for(i=1;i<=n;i++)
{
while(j&&a[i]!=b[j+1])
j=next[j];
if(a[i]==b[j+1])
j++;
if(j==m)
{
count++;
j=next[j];
}
}
printf("%d",count);
return 0;
}7-2 【模板】KMP字符串匹配
给出两个字符串text和pattern,其中pattern为text的子串,求出pattern在text中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
输入格式:
第一行为一个字符串,即为text。
第二行为一个字符串,即为pattern。
输出格式:
若干行,每行包含一个整数,表示pattern在text中出现的位置。
接下来1行,包括length(pattern)个整数,表示前缀数组next[i]的值,数据间以一个空格分隔,行尾无多余空格。
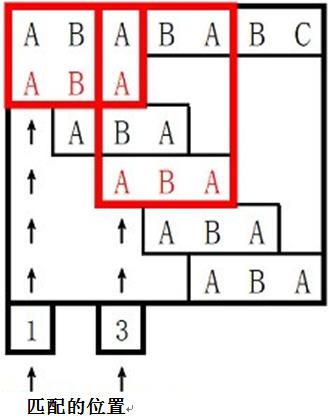
输入样例:
ABABABC
ABA
输出样例:
1
3
0 0 1
样例说明:
#include<stdio.h>
#include<string.h>
int main()
{
char a[1000010],b[1000010];
int next[1000010];
scanf("%s %s",a+1,b+1);
int i,j=0;
int n=strlen(a+1),m=strlen(b+1);
for(i=2;i<=m;i++)
{
while(j&&b[i]!=b[j+1])
j=next[j];
if(b[i]==b[j+1])
j++;
next[i]=j;
}
j=0;
for(i=1;i<=n;i++)
{
while(j&&a[i]!=b[j+1])
j=next[j];
if(a[i]==b[j+1])
j++;
if(j==m)
{
printf("%d\n",i-m+1);
j=next[j];
}
}
for(i=1;i<=m;i++)
{
if(i==m)
printf("%d",next[i]);
else
printf("%d ",next[i]);
}
return 0;
}7-3 判断对称矩阵
将矩阵的行列互换得到的新矩阵称为转置矩阵。
把m×n矩阵
A=⎣⎡a11a21⋅⋅⋅am1a12a22⋅⋅⋅am2⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅a1na2n⋅⋅⋅amn⎦⎤
的行列互换之后得到的矩阵,称为 A 的转置矩阵,记作 AT ,
即
AT=⎣⎡a11a12⋅⋅⋅a1na21a22⋅⋅⋅a2n⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅am1am2⋅⋅⋅amn⎦⎤
由定义可知, A 为m×n 矩阵,则 AT 为 n×m 矩阵。例如,
A=[1−20123]
,
AT=⎣⎡102−213⎦⎤.
n×n矩阵称之为 n阶方阵,
如果 n 阶方阵和它的转置相等,即 AT=A ,则称矩阵 A 为对称矩阵。
输入格式:
在第一行内给出n值(1<n<100)。
从第二行以后给出n阶矩阵所有行的元素值。
输出格式:
当输入的n阶矩阵是对称矩阵,输出“Yes”,否则输出“No”。
输入样例:
3
1 0 2
-2 1 3
4 3 2
输出样例:
No
输入样例:
3
1 -2 4
-2 1 3
4 3 2
输出样例:
Yes
#include<stdio.h>
int main()
{
int n,i,j;
int f=1;
scanf("%d",&n);
int a[100][100];
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
{
scanf("%d",&a[i][j]);
}
}
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
{
if(a[i][j]!=a[j][i])
{
f=0;
break;
}
}
}
if(f==0)
printf("No");
else
printf("Yes");
return 0;
}7-4 三元组顺序表表示的稀疏矩阵转置运算Ⅰ
三元组顺序表表示的稀疏矩阵转置。
输入格式:
输入第1行为矩阵行数m、列数n及非零元素个数t。
按行优先顺序依次输入t行,每行3个数,分别表示非零元素的行标、列标和值。
输出格式:
输出转置后的三元组顺序表结果,每行输出非零元素的行标、列标和值,行标、列标和值之间用空格分隔,共t行。
输入样例1:
3 4 3
0 1 -5
1 0 1
2 2 2
输出样例1:
0 1 1
1 0 -5
2 2 2#include<stdio.h>
int main()
{
int m,n,t,h,l,z;
int a[101][101]={0};
int b[101][101]={0};
scanf("%d %d %d",&m,&n,&t);
for(int i=0;i<t;i++)
{
scanf("%d %d %d",&h,&l,&z);//行列值
a[h][l]=z;
}
for(int i=0;i<m;i++)
{
for(int j=0;j<n;j++)
{
b[j][i]=a[i][j];
}
}
int k=0;
int h2[10],l2[10],z2[10];
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
if(b[i][j]!=0)
{
h2[k]=i;
l2[k]=j;
z2[k]=b[i][j];
k++;
}
}
}
for(int i=0;i<k;i++)
{
printf("%d %d %d\n",h2[i],l2[i],z2[i]);
}
return 0;
}7-5 三元组顺序表表示的稀疏矩阵加法
三元组顺序表表示的稀疏矩阵加法。
输入格式:
输入第1行为两个同型矩阵的行数m、列数n,矩阵A的非零元素个数t1,矩阵B的非零元素个数t2。
按行优先顺序依次输入矩阵A三元组数据,共t1行,每行3个数,分别表示非零元素的行标、列标和值。
按行优先顺序依次输入矩阵B三元组数据,共t2行,每行3个数,分别表示非零元素的行标、列标和值。
输出格式:
输出第1行为相加后矩阵行数m、列数n及非零元素个数t。
输出t行相加后的三元组顺序表结果,每行输出非零元素的行标、列标和值,每行数据之间用空格分隔。
输入样例1:
4 4 3 4
0 1 -5
1 3 1
2 2 1
0 1 3
1 3 -1
3 0 5
3 3 7
输出样例1:
4 4 4
0 1 -2
2 2 1
3 0 5
3 3 7#include<stdio.h>
int main()
{
int a[101][101],b[101][101],sum[101][101]={0};
int m,n,t1,t2,i,j;
int count=0;
scanf("%d %d %d %d",&m,&n,&t1,&t2);
int h1,l1,z1;
for(i=0;i<t1;i++)
{
scanf("%d %d %d",&h1,&l1,&z1);
a[h1][l1]=z1;
}
int h2,l2,z2;
for(j=0;j<t2;j++)
{
scanf("%d %d %d",&h2,&l2,&z2);
b[h2][l2]=z2;
}
for(i=0;i<m;i++)
{
for(j=0;j<n;j++)
{
sum[i][j]=a[i][j]+b[i][j];
}
}
for(i=0;i<m;i++)
{
for(j=0;j<n;j++)
{
if(sum[i][j]!=0)
count++;
}
}
printf("%d %d %d\n",m,n,count);
for(i=0;i<m;i++)
{
for(j=0;j<n;j++)
{
if(sum[i][j]!=0)
printf("%d %d %d\n",i,j,sum[i][j]);
}
}
return 0;
}7-6 三元组顺序表表示的稀疏矩阵转置Ⅱ
三元组顺序表表示的稀疏矩阵转置Ⅱ。设a和b为三元组顺序表变量,分别表示矩阵M和T。要求按照a中三元组的次序进行转置,并将转置后的三元组置入b中恰当的位置。
输入格式:
输入第1行为矩阵行数m、列数n及非零元素个数t。
按行优先顺序依次输入t行,每行3个数,分别表示非零元素的行标、列标和值。
输出格式:
按置入b中的顺序输出置入的位置下标,转置后的三元组行标、列标和值,数据之间用空格分隔,共t行。
输入样例1:
3 4 3
0 1 -5
1 0 1
2 2 2
输出样例1:
1 1 0 -5
0 0 1 1
2 2 2 2#include<stdio.h>
typedef struct
{
int i,j,num,y;
}Num;
struct node
{
int m,n,t;
Num data[10086];
}M,T;
int main()
{
int a,b,x=0,y=0;
scanf("%d %d %d",&M.m,&M.n,&M.t);
for(a=0;a<M.t;a++)
{
scanf("%d %d %d",&M.data[a].i,&M.data[a].j,&M.data[a].num);
}
T.m=M.n;
T.n=M.m;
T.t=M.t;
for(a=0;a<M.n;a++)
{
for(b=0;b<M.t;b++)
{
if(a==M.data[b].j)
{
T.data[x].y=x;
T.data[x].i=M.data[b].j;
T.data[x].j=M.data[b].i;
T.data[x].num=M.data[b].num;
x++;
}
}
}
for(a=0;a<M.t;a++)
{
int k=M.data[a].num;
for(b=0;b<M.t;b++)
{
if(T.data[b].num==k)
printf("%d %d %d %d\n",T.data[b].y,T.data[b].i,T.data[b].j,T.data[b].num);
}
}
return 0;
}7-7 最大子矩阵和问题
最大子矩阵和问题。给定m行n列的整数矩阵A,求矩阵A的一个子矩阵,使其元素之和最大。
输入格式:
第一行输入矩阵行数m和列数n(1≤m≤100,1≤n≤100),再依次输入m×n个整数。
输出格式:
输出第一行为最大子矩阵各元素之和,第二行为子矩阵在整个矩阵中行序号范围与列序号范围。
输入样例1:
5 6
60 3 -65 -92 32 -70
-41 14 -38 54 2 29
69 88 54 -77 -46 -49
97 -32 44 29 60 64
49 -48 -96 59 -52 25
输出样例1:
输出第一行321表示子矩阵各元素之和,输出第二行2 4 1 6表示子矩阵的行序号从2到4,列序号从1到6
321
2 4 1 6#include<stdio.h>
int dp[10086][10086];
int main()
{
int m,n,i,j,k,num,z,temp,max=0;
scanf("%d %d",&m,&n);
for(i=1;i<=m;i++)
{
for(j=1;j<=n;j++)
{
scanf("%d",&num);
dp[i][j]=dp[i-1][j]+num;
}
}
int x1,x2,y1,y2;
for(i=1;i<=n;i++)
{
for(j=1;j<=i;j++)
{
temp=0;
z=1;
for(k=1;k<=n;k++)
{
temp=temp+(dp[i][k]-dp[j-1][k]);
if(temp>max)
{
max=temp;
x1=j;
x2=i;
y1=z;
y2=k;
}
if(temp<0)
{
temp=0;
z=k+1;
}
}
}
}
printf("%d\n",max);
printf("%d %d %d %d",x1,x2,y1,y2);
return 0;
}7-8 好中缀
我们称一个字符串S的子串T为好中缀,如果T是去除S中满足如下条件的两个子串p和q后剩余的字符串。
(1)p是S的前缀,q是S的后缀;
(2)p=q;
(3)p和q是满足条件(1)(2)的所有子串中的第二长者。
注意一个字符串不能称为自己的前缀或后缀。好中缀至少为空串,其长度大于等于0,不能为负数。
输入格式:
输入为一个字符串S,包含不超过100000个字母。
输出格式:
输出为一个整数,表示好中缀的长度。
输入样例1:
abcabcxxxabcabc
输出样例1:
9
输入样例2:
xacbacba
输出样例2:
8
输入样例3:
aaa
输出样例3:
1
#include<stdio.h>
#include<string.h>
int main()
{
char b[1000010];
int m;
int next[1000010];
scanf("%s",b+1);
m=strlen(b+1);
int j=0,i;
for(i=2;i<=m;i++) //对本串构造出next数组,这边注意不能把next[0]赋值为-1;
{
while(j&&b[i]!=b[j+1])
j=next[j];
if(b[i]==b[j+1])
j++;
next[i]=j;
}
int x=m-2*next[next[m]]; //不明白可以写一下,第二长的前缀
if(x>=0) printf("%d",x);
else printf("0");
return 0;
}
7-9 病毒变种
病毒DNA可以表示成由一些字母组成的字符串序列,且病毒的DNA序列是环状的。例如,假设病毒的DNA序列为baa,则该病毒的DNA序列有三种变种:baa,aab,aba。试编写一程序,对给定的病毒DNA序列,输出该病毒所有可能的DNA序列(假设变种不会重复)。
输入格式:
输入第一行中给出1个整数i(1≤i≤11),表示待检测的病毒DNA。 输入i行串序列,每行一个字符串,代表病毒的DNA序列,病毒的DNA序列长度不超过500。
输出格式:
依次逐行输出每个病毒DNA所有变种,各变种之间用空格分隔。
输入样例1:
1
baa
输出样例1:
baa aab aba
输入样例2:
2
abc
baac
输出样例2:
abc bca cab
baac aacb acba cbaa #include <stdio.h>
#include <string.h>
void DNA(char *str)
{
int n,i,j;
n=strlen(str);
printf("%s ",str);
for(i=1;i<n;i++)
{
str[n]=str[0];
for(j=1;j<=n;j++)
{
str[j-1]=str[j];
}
str[j-1]='\0';
printf("%s ",str);
}
}
int main()
{
int m,i;
char a[510];
scanf("%d",&m);
for(i=0;i<m;i++)
{
scanf("%s",a);
DNA(a);
printf("\n");
}
return 0;
}7-10 统计子串
编写算法,统计子串t在主串s中出现的次数。
输入格式:
首先输入一个整数T,表示测试数据的组数,然后是T组测试数据。每组测试数据在第一行中输入主串s,在第二行中输入子串t,s和t中不包含空格。
输出格式:
对于每组测试,若子串t在主串s中出现,则输出t在s中的子串位置和出现总次数,否则输出0 0。
输入样例:
2
abbbbcdebb
bb
abcde
bb
输出样例:
2 4
0 0#include <stdio.h>
#include <string.h>
void kmp(char *s, char *t, int *next) {
int n = strlen(s);
int m = strlen(t);
int j = 0;
int count = 0;
for (int i = 0; i < n; i++) {
while (j > 0 && s[i] != t[j]) {
j = next[j - 1];
}
if (s[i] == t[j]) {
j++;
if (j == m) {
count++;
j = next[j - 1];
}
}
}
if (count == 0) {
printf("0 0\n");
} else {
printf("%d %d\n", j - m + 1, count);
}
}
int main() {
int T;
scanf("%d", &T);
while (T--) {
char s[1000010], t[1000010];
scanf("%s", s);
scanf("%s", t);
int m = strlen(t);
int next[m];
next[0] = 0;
for (int i = 1, j = 0; i < m; i++) {
while (j > 0 && t[i] != t[j]) {
j = next[j - 1];
}
if (t[i] == t[j]) {
j++;
}
next[i] = j;
}
kmp(s, t, next);
}
return 0;
}














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









