






随着大型语言模型(LLM)及其相关工具(如嵌入模型)在过去一年中能力显著提升,越来越多的开发者考虑将LLM集成到他们的应用程序中。
由于LLM通常需要专用硬件和大量计算资源,它们通常作为网络服务打包,提供API供访问。这就是OpenAI和Google Gemini等领先LLM的API工作方式;即使是像Ollama这样的自托管LLM工具,也将LLM封装在REST API中以供本地使用。此外,利用LLM的开发者通常还需要补充工具,如向量数据库,这些数据库大多也作为网络服务部署。
换句话说,LLM驱动的应用程序与其他现代云原生应用程序非常相似:它们需要对REST和RPC协议、并发性和性能的出色支持。这正是Go语言擅长的领域,使其成为编写LLM驱动应用程序的理想选择。
这篇博客文章通过一个使用Go构建简单LLM驱动应用程序的示例进行说明。文章首先描述了演示应用程序所解决的问题,然后展示了几种实现相同任务但使用不同包的应用程序变体。所有演示代码均可在线获取。
RAG服务器用于问答
一种常见的LLM驱动应用技术是RAG(检索增强生成)。RAG是为特定领域交互定制LLM知识库最具可扩展性的方法之一。
我们将构建一个RAG服务器,这是一个HTTP服务器,为用户提供
两项操作:
向知识库添加文档
向LLM提问关于该知识库的问题
在典型的现实场景中,用户会向服务器添加一组文档,然后提出问题。例如,一家公司可以将内部文档填充到RAG服务器的知识库中,以便为内部用户提供LLM驱动的问答功能。
以下是展示我们服务器与外部世界交互的图示:
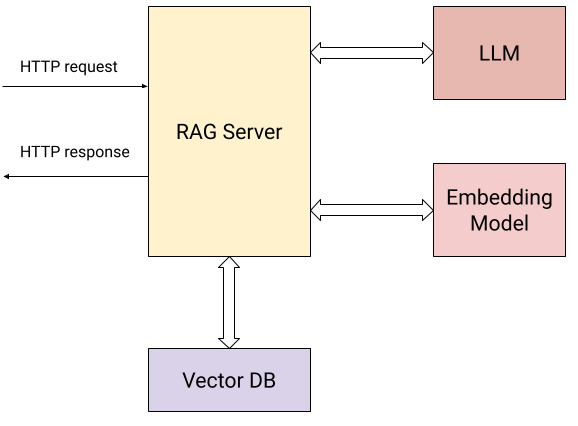
除了用户发送HTTP请求(上述两项操作),服务器还与以下组件进行交互:
嵌入模型,用于计算提交文档和用户问题的向量嵌入。
向量数据库,用于高效存储和检索嵌入。
LLM,根据从知识库收集的上下文提问。
具体来说,服务器向用户公开两个HTTP端点:
/add/: POST {"documents": [{"text": "..."}, {"text": "..."}, ...]}:提交一系列文本文档,以添加到其知识库中。
对于此请求,服务器:
使用嵌入模型计算每个文档的向量嵌入。
将文档及其向量嵌入存储在向量数据库中。
/query/: POST {"content": "..."}:向服务器提交一个问题。对于此请求,服务器:
使用嵌入模型计算问题的向量嵌入。
使用向量数据库的相似性搜索找到与问题最相关的知识库中的文档。
使用简单的提示工程,将步骤(2)中找到的最相关文档作为上下文重新表述问题,并将其发送给LLM,返回答案给用户。
我们演示中使用的服务包括:
Google Gemini API用于LLM和嵌入模型。
Weaviate作为本地托管的向量数据库;Weaviate是用Go实现的开源向量数据库。
用其他等效服务替换这些服务应该非常简单。事实上,这正是服务器第二和第三个变体所涉及的内容!我们将从第一个变体开始,该变体直接使用这些工具。
直接使用Gemini API和Weaviate
Gemini API和Weaviate都有方便的Go SDK(客户端库),我们的第一个服务器变体直接使用这些。该变体的完整代码在此目录中。
我们不会在这篇博客文章中重现整个代码,但在阅读时请注意以下几点:
结构:代码结构对任何编写过Go HTTP服务器的人来说都很熟悉。Gemini和Weaviate的客户端库被初始化,并且客户端存储在传递给HTTP处理程序的状态值中。
路由注册:使用Go 1.22引入的路由增强功能,设置我们服务器的HTTP路由非常简单:
mux := http.NewServeMux()
mux.HandleFunc("POST /add/", server.addDocumentsHandler)
mux.HandleFunc("POST /query/", server.queryHandler)并发性:我们服务器的HTTP处理程序会通过网络与其他服务进行交互,并等待响应。这对Go来说不是问题,因为每个HTTP处理程序都在自己的goroutine中并发运行。这个RAG服务器可以处理大量并发请求,每个处理程序的代码都是线性和同步的。
批量API:由于/add/请求可能提供大量要添加到知识库中的文档,因此服务器利用批量API来提高效率,包括嵌入(embModel.BatchEmbedContents)和Weaviate数据库(rs.wvClient.Batch)。
使用LangChain for Go
我们的第二个RAG服务器变体使用LangChainGo来完成相同任务。LangChain是一个流行的Python框架,用于构建LLM驱动应用程序。LangChainGo是其Go版本。该框架有一些工具,可以将应用程序构建为模块化组件,并支持许多LLM提供商和向量数据库,提供统一API。这使得开发者可以编写适用于任何提供商且能够轻松更换提供商的代码。
该变体的完整代码在此目录中。阅读代码时你会注意到两点:
首先,它比前一个变体短一些。LangChainGo负责将向量数据库完整API封装为通用接口,因此初始化和处理Weaviate所需的代码更少。
其次,LangChainGo API使得更换提供商相对容易。假设我们想用另一个向量数据库替换Weaviate;在前一个变体中,我们必须重写所有与向量数据库接口相关的代码以使用新的API。而有了像LangChainGo这样的框架,我们不再需要这样做。只要LangChainGo支持我们感兴趣的新向量数据库,我们应该能够在我们的服务器中仅替换几行代码,因为所有数据库都实现了通用接口:
type VectorStore interface {
AddDocuments(ctx context.Context, docs []schema.Document, options ...Option) ([]string, error)
SimilaritySearch(ctx context.Context, query string, numDocuments int, options ...Option) ([]schema.Document, error)使用Genkit for Go
今年早些时候,谷歌推出了Genkit for Go——一个用于构建LLM驱动应用的新开源框架。Genkit与LangChain有一些相似之处,但在其他方面有所不同。
像LangChain一样,它提供可以由不同提供商(作为插件)实现的通用接口,从而简化了从一个到另一个提供商之间切换。然而,它并不试图规定不同LLM组件如何交互;相反,它专注于生产特性,如提示管理和工程,以及集成开发工具进行部署。
我们的第三个RAG服务器变体使用Genkit for Go来完成相同任务。它的完整代码在此目录中。
这个变体与LangChainGo相似——使用通用接口而不是直接提供商API,使得从一个切换到另一个更容易。此外,使用Genkit将LLM驱动应用程序部署到生产环境要容易得多;我们在这个变体中没有实现这一点,但如果你感兴趣,可以查看文档。
总结 - Go用于LLM驱动应用程序
本文中的示例仅展示了在Go中构建LLM驱动应用程序的一部分可能性。它展示了如何用相对较少的代码构建强大的RAG服务器;最重要的是,由于某些基本Go特性,这些示例具有显著程度的生产就绪性。
与LLM服务一起工作通常意味着发送REST或RPC请求到网络服务,等待响应,然后根据响应发送新请求到其他服务等等。Go在这些方面表现出色,为管理并发性和处理网络服务复杂性提供了极好的工具。
此外,作为云原生语言,Go出色的性能和可靠性使其成为实现LLM生态系统更基本构建块的自然选择。一些示例项目包括Ollama、LocalAI、Weaviate或Milvus。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









