







《解决目标检测中的小目标问题》
目标检测的前身是滑窗 + 图像分类,如果想要对图像进行鲁棒的分类,首先特征要能够覆盖整幅图像,而且编码的前景信息要比噪声背景信息更加显著。这对于小目标来说比较难做到,所以小目标检测一直是目标检测中的一个难点,2015年的一篇论文 Deep Proposal 中对浅层语义特征和深层语义特征在目标检测中的作用做了分析,结论是深层语义特征能够以较高的查全率找到感兴趣的对象,浅层语义特征可以更好地定位感兴趣的对象,但召回率降低。从感受野来说,浅层语义的感受野可能存在无法覆盖整个目标的特征导致无法准确的进行分类。而理论上小目标只存在于浅层语义中,所以小目标的召回就会存在问题。本文根据自身的经验以及参考一些大神的帖子记录一下目标检测中小目标问题的解决方案。
Key Words:小目标、深层语义特征、浅层语义特征、特征融合、数据增强
Beijing, 2021.02
作者:RaySue
Code:
小目标的定义
-
相对尺度定义,根据国际组织 SPIE 的定义,小目标为在 256 × 256 256×256 256×256 的图像中目标面积小于 80 80 80 个像素,即小于 256 × 256 256×256 256×256 的 0.12 0.12% 0.12 就为小目标,此为相对尺寸的定义。
-
绝对尺寸定义,根据COCO数据集定义 ,尺寸小于 32 ∗ 32 32 * 32 32∗32 像素的目标即可认为是小目标。
数据维度
- Oversampling
一个最直接的方法是对包含小目标的图像样本进行重采样,因为小目标出现的样本还是占少数的,可以通过重采样来增加带有小目标的图像样本。
- DataAugmentation
论文 Augmentation for small object detection 大致原理就是将小目标 matting 出来,然后随机的融合在背景区域,从而增加小目标出现的频数。在实际中使用的时候可以利用 泊松融合 ,先将小目标抠出来,然后可以任意的融合到不同样本的背景上。
增强规则:将目标粘贴到新位置之前,我们对其进行随机变换。目标缩放范围为 ± 20 ±20% ±20,旋转范围为 ± 15 ° ±15° ±15°。复制时我们只考虑无遮挡的目标,泊松融合 能够让融合的结果非常真实。粘贴时确保新粘贴的目标不会与任何现有的对象发生重叠,并且距离图像边界至少有 5 5 5 个像素。
特征维度
- 特征融合
RFBNet
这篇是 ECCV2018 关于目标检测的文章,提出了RFB Net网络用于目标检测,可以在兼顾速度的同时达到良好的效果。该网络主要在SSD网络中引入 Receptive Field Block (RFB),引入RFB的出发点通过模拟人类视觉的感受野加强网络的特征提取能力,在结构上RFB借鉴了Inception的思想,主要是在Inception的基础上加入了dilated卷积层(dilated convolution),从而有效增大了感受野(receptive field)。整体上因为是基于SSD网络进行改进,所以检测速度还是比较快,同时精度也有一定的保证。
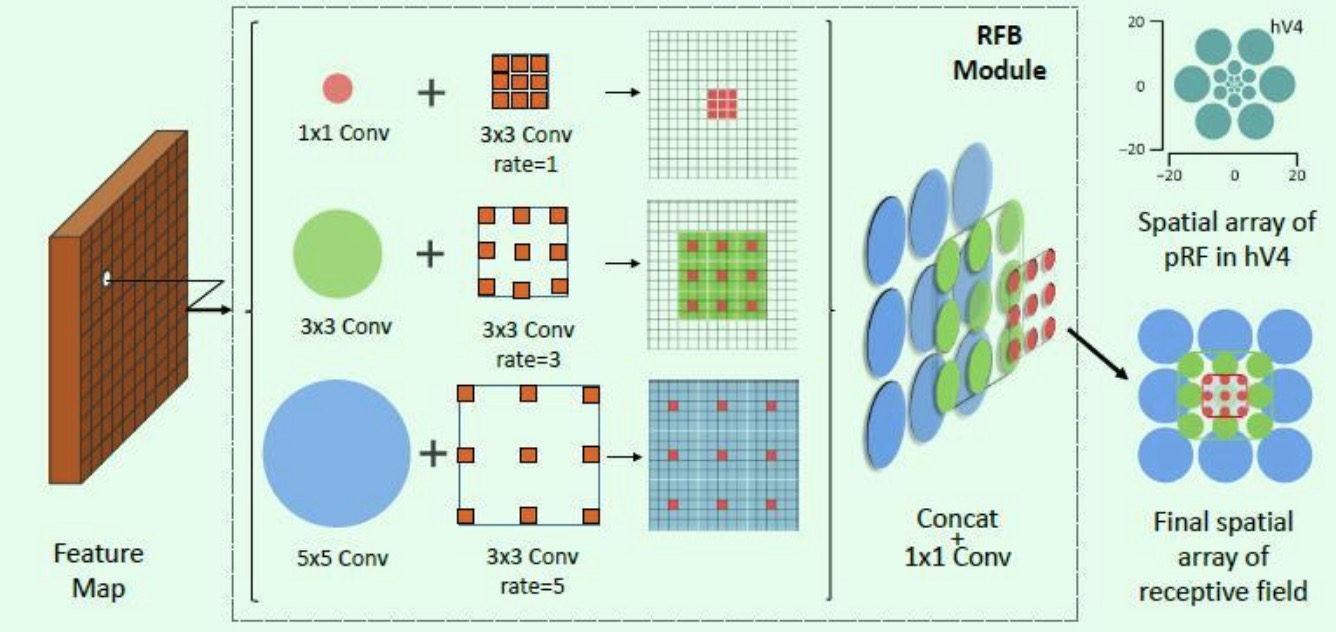
-
利用空洞卷积来增大感受野即在参数量不变的情况下,使得 feature map 获得更多的上下文信息
-
借鉴 Inception 思想
-
最后利用 1x1 Conv 减少了 feature map 的通道数,做通道上的信息融合
FPN
不同阶段的特征图对应的感受野不同,它们表达的信息抽象程度也不一样。浅层的特征图感受野小,比较适合检测小目标(要检测大目标,则其只“看”到了大目标的一部分,有效信息不够);深层的特征图感受野大,适合检测大目标(要检测小目标,则其”看“到了太多的背景噪音,冗余噪音太多)。所以,有人就提出了将不同阶段的特征图,都融合起来,来提升目标检测的性能,这就是特征金字塔网络 FPN(Feature Pyramid Networks for Object Detection[3])。
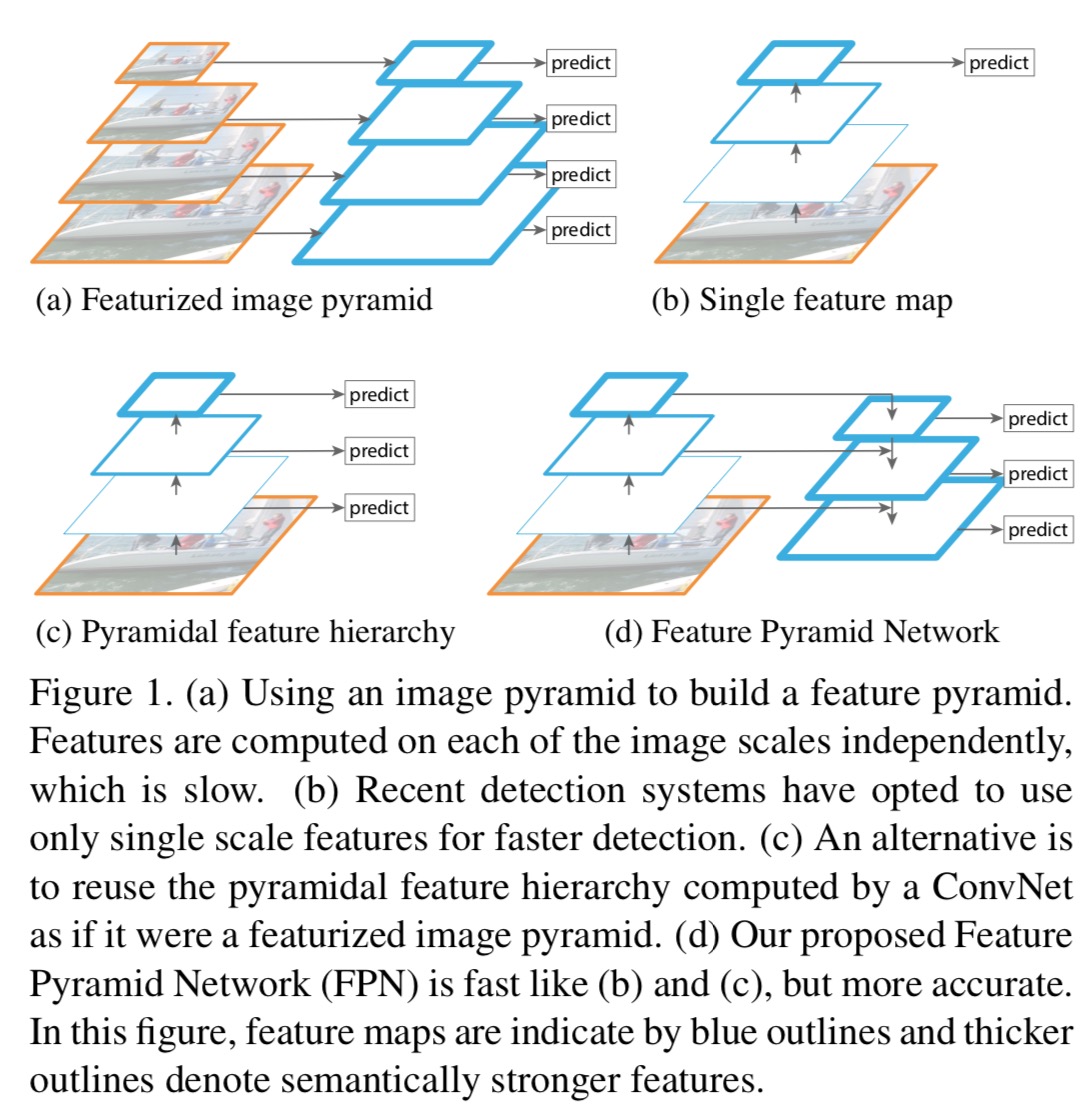
- FPN 多加了一条从 深层语义 到 浅层语音 进行特征融合的路径,让浅层语义特征和深层语义特征进行融合,从而更好的对目标进行分类和回归。
NETNet
小目标检测存在两个问题:
-
小物体容易被遗漏;
-
大物体的突出部分有时被检测为物体。
通过这一观察,作者就提出了一种新的邻域擦除和传输(NET)机制来重新配置金字塔特征和探索尺度感知特征。在NET中,**设计了一个邻域擦除模块(NEM),用于擦除大目标的显著特征,并强调浅层小目标的特征。引入了一个邻域传输模块(NTM)来传输被擦除的特征,并在深层突出显示大目标。**利用这种机制,构建了一个名为 NETNet 的 Single-shot 网络,用于感知尺度的对象检测。
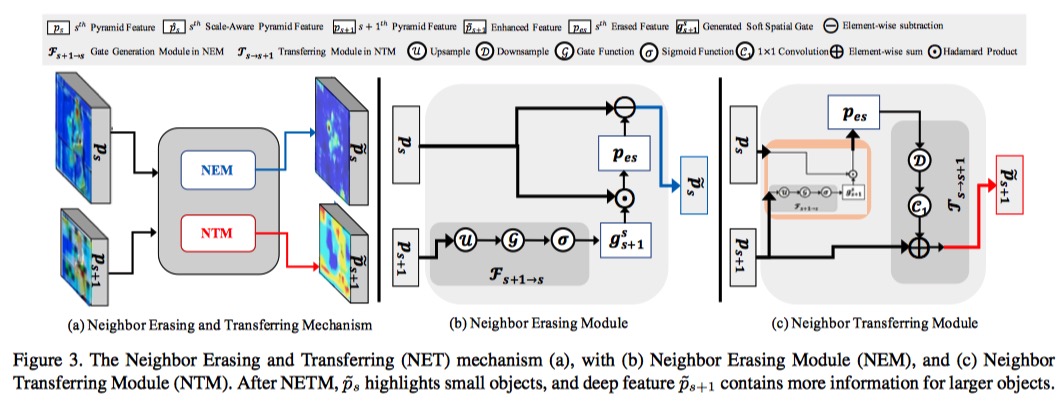
邻域擦除模块(NEM)的步骤:
1. 浅层语义既有小目标特征又有大目标特征,而深层语义只包含大目标的特征
2. 将深层语义上采样到和浅层语义特征一样的大小(只包含大目标的特征)
3. 将上采样的深层语义特征结果减去浅层语义特征的结果,这样小目标就更加明显了
邻域传输模块(NTM)的步骤:
1. 将 NEM 得到的特征进行下采样得到特征 f
2. 将 f 利用 1x1 Conv 进行特征提取
3. 再和上面提到的深层语义特征做 element wise sum
利用上下文信息
SSH 模块
SSH中的上下文模块也是特征融合的的一种。上下文网络模块的作用是用于增大感受野,SSH通过单层卷积层的方法对上下文(context)信息进行了合并,其结构图如下图所示:

-
通过2个3x3的卷积层和3个3x3的卷积层并联,从而增大了卷积层的感受野,并作为各检测模块的目标尺寸。
-
通过该方法构造的上下文的检测模块比候选框生成的方法具有更少的参数量,并且上下文模块可以在 WIDER FACE 数据集上的AP提升0.5个百分点 。
通过目标关系建立联系
小目标,特别是像人脸这样的目标,不会单独地出现在图片中(想想单独一个脸出现在图片中,而没有头、肩膀和身体也是很恐怖的)。像[PyramidBox](PyramidBox: A Context-assisted Single Shot Face Detector[4])方法,加上一些头、肩膀这样的上下文Context信息,那么目标就相当于变大了一些,上下文信息加上检测也就更容易了。利用小目标周围的信息来加强小目标的召回。
超分辨率重建
超分也是做小目标的一个思路,利用GAN网络对小目标的细节进行重建,然后得到更为丰富的特征是利于目标检测的。
小目标特殊场景
比如小目标比较多,那么这种场景可以使用关键点估计的算法来解决。即对每个小目标标注一个点,然后以这个点为中心做一个高斯分布,类似于 CenterNet,然后用MSE loss来训练就可以。














 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









