







紧接着上一篇,批量处理完的txt文本后的数据,填充到Excel表中,下面是处理步骤
- 读取Excel表格
- 把数据转换成numpy的矩阵
- 提取需要的数据填充到准备好的矩阵中
- 循环显示图片,总共有205+140张图片
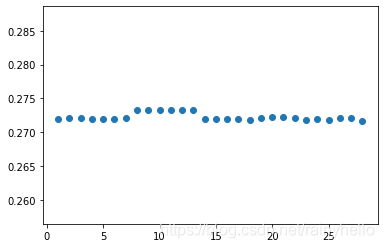
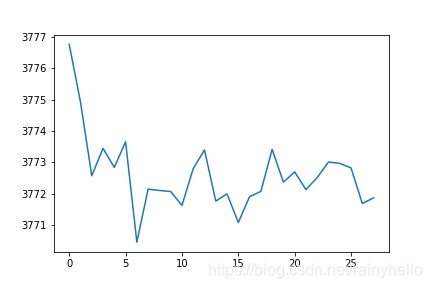
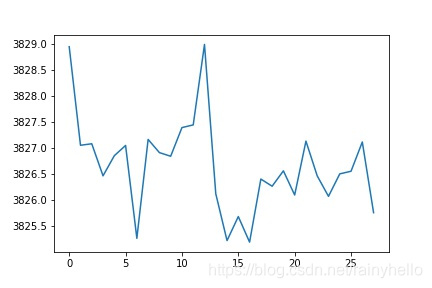
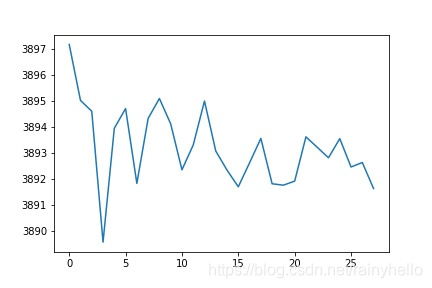
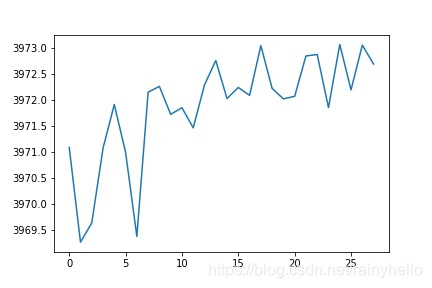
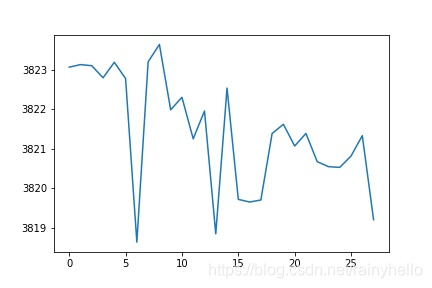
- 第一行图是一个板卡的某个电容在28个通道之间测试的值发现2做激励通道时候值比其他通道要大0.001左右。
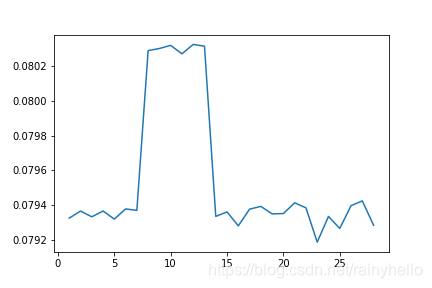
- 第二行图真实想法是横坐标是21-1430fF的真是电容值,纵坐标是测量值,右边的图是去除最大电容值后情况
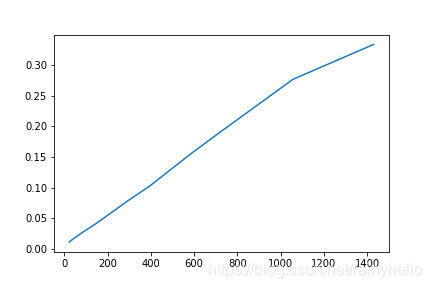
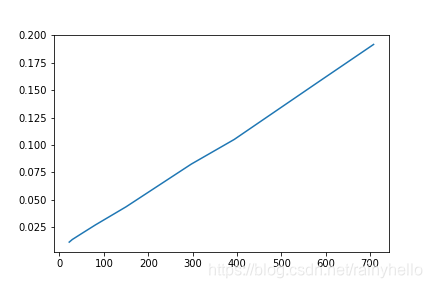
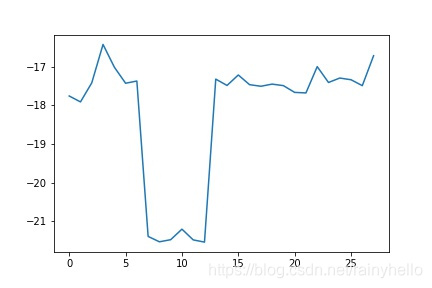
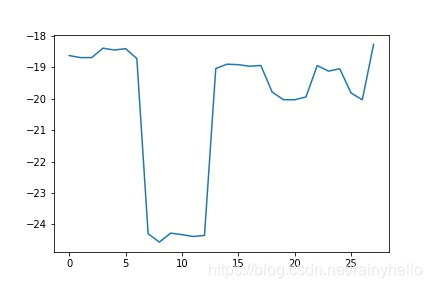
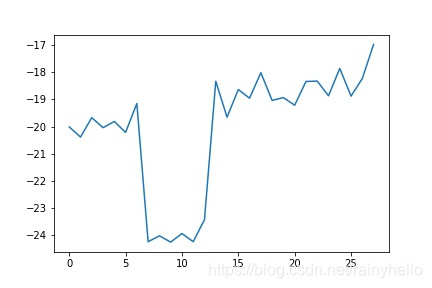
- 后面的图是一个板卡内的28通道的10个电容数据进行线性拟合,得到28个斜率和偏移量
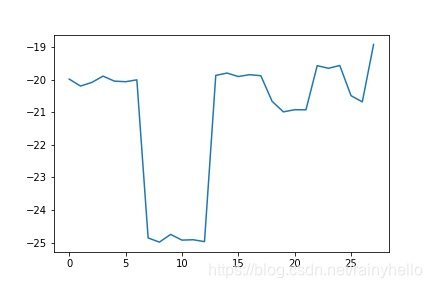
- 发现同一个板卡的斜率相差不大,不同板卡之间的斜率相差200以上,偏移量在-21附近

# -*- coding: utf-8 -*-
"""
Created on Sat Jan 11 16:54:52 2020
@author: Tsinghua
下面是成图算法
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#from scipy.optimize import curve_fit
excel = 'D:/log/data_process.xlsx'
save_path='D:/log/picture/'
df = pd.read_excel(excel)
#a=['21','29','51','81','150','297','394','583','708','1057','1430']
d=np.array([22,29,51,81,150,297,394,583,708,1057,1430])
b=list(range(1,12))
c=list(range(1,29))
#da = pd.DataFrame(columns=a,index=b)
#da = pd.DataFrame(columns=b,index=a)
for j in range(0,5):
ss = np.zeros([28,0])
#取出Excel中某些行
for i in range(0,11):
#dd = pd.DataFrame(df.ix[4+i,2:30],dtype=np.float)
dd = pd.DataFrame(df.ix[4+j*11+i,2:30],dtype=np.float)
# ds = dd.values
ss = np.append(ss,dd.values,1)
#ss = np.transpose(ss)#矩阵转置
# 每个电容的28通道图
for i in range(0,11):
plt.plot(c,ss[:,i])
plt.savefig(save_path+'板卡'+str(j)+'电容'+str(i)+'.png')
# plt.show()
plt.clf()
# 每个通道的散点图前面10个点
for i in range(0,28):
plt.plot(d[:],ss[i,:])
plt.savefig(save_path+'板卡'+str(j)+'通道'+str(i)+'.png')
# plt.show()
plt.clf()
for i in range(0,28):
plt.plot(d[:9],ss[i,:9])
plt.savefig(save_path+'无'+str(j)+'通道'+str(i)+'.png')
# plt.show()
plt.clf()
pp = np.array([])
pp1 = np.zeros(shape=(28,1))
pp2 = np.zeros(shape=(28,1))
for i in range(0,28):
ploy = np.polyfit(ss[i,0:10],d[0:10],deg=1)#只拟合前面10个电容,1430fF电容不参与拟合
pp = np.append(pp,ploy,0)#得到拟合方程的两个参数,前面是斜率,后面的偏移量
# plt.plot(e,np.polyval(ploy,e))
# plt.plot(list(range(0,28)),pp)
for i in range(0,28):
pp1[i] = pp[2*i] #这个是斜率
pp2[i] = pp[2*i+1] #偏移量
plt.plot(list(range(0,28)),pp1) #斜率成图
plt.savefig(save_path+'EMB'+str(j)+'斜率'+'.jpg')
# plt.show()
plt.clf()
plt.plot(list(range(0,28)),pp2) #偏移量成图
plt.savefig(save_path+'EMB'+str(j)+'偏移'+'.jpg')
# plt.show()
plt.clf()
#保存的时候遇到过保存空白图像的问题,
#是因为将plt.savefig('D:/log/picture/i+5.png')放到了plt.show()之后,
#只要先保存在显示就可以正常保存了。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









