 数据处理与整合技巧
数据处理与整合技巧





目录
一、认识数据处理
1、现实世界的数据是“肮脏的”——数据多了,什么问题都会出现
(1)不完整的:缺少属性值,缺少感兴趣的属性,或仅包含聚集数据。 如:e.g., Occupation=“”;
(2)含噪声的:包含错误或者“孤立点”。 e.g.,Salary=“-10”;
(3)不一致的:在编码或者命名上存在差异。E.g.Age=“42” Birthday=“03/07/1997” 如:等级代码 前面“1,2,3”, 后面“A,B, C”。
2、没有高质量的数据,就没有高质量的挖掘结果
高质量的决策必须依赖高质量的数据。
数据处理的主要任务
1、数据集成
集成多个数据库、数据立方体或文件。(本文内容)
2、数据清理
(1)填充缺失值; (2)识别孤立点,去除噪音; (3)修正不一致数据; (4)解决由于数据集成造成的数据冗余问题。
3、数据规约
得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果,包括维规约和数值
规约。
4、数据变换
规范化:将数据按比例缩放,使之落入一个小的特定区间。
5、数据离散化
离散化:数值属性的原始值用区间标签或概念标签替换,或者标称属性转化为数值属性。
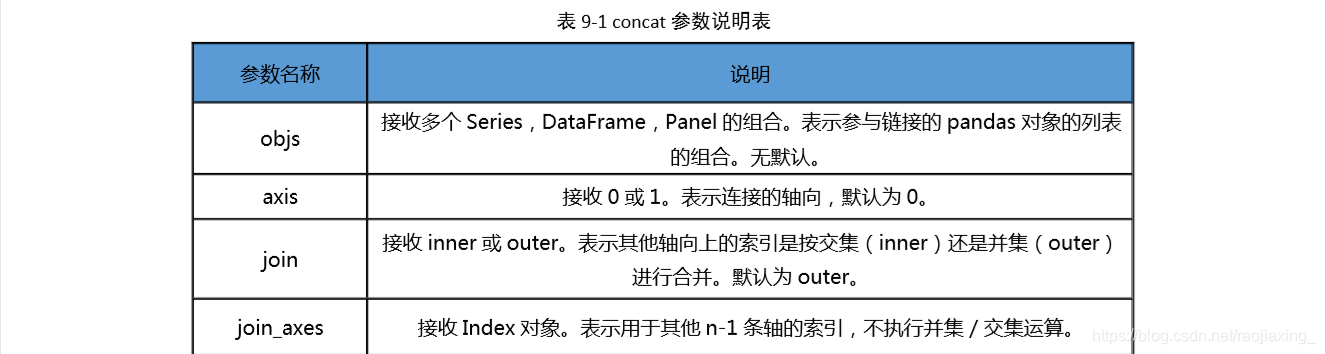
二、数据集成-concat
(一)横向堆叠-concat
横向堆叠,即将两个表在 X 轴向拼接在一起,可以使用 concat 函数完成,concat 函数
的基本语法如下。
pandas.concat(objs,axis=1,join='outer',join_axes=None,ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)

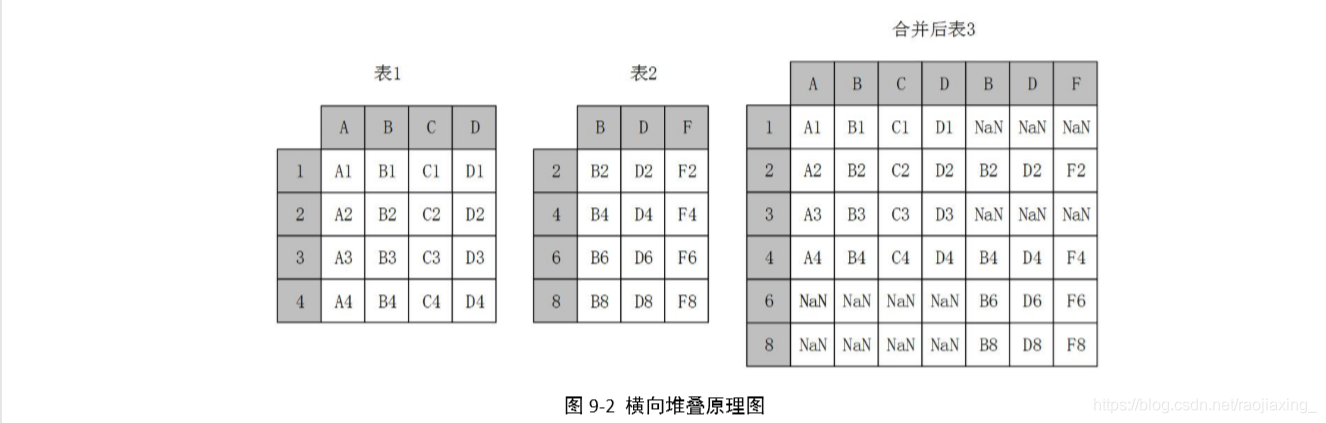
当 axis=1 的时候,concat 做行对齐,然后将不同列名称的两张或多张表合并。
合并的原理图:
代码实现:
import pandas as pd
# 横向堆叠 --->在列的方向上进行拼接合并
# --->沿着x轴的方向进行拼接合并
# --->水平方向的进行拼接合并
# 加载数据
df1 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=0)
df2 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=1)
print('df1:\n', df1)
print('df2:\n', df2)
# 横向堆叠 ---给数据堆叠新的属性
# axis = 1 --->横向堆叠
# outer --外连接 --求并集
# 在横向,直接堆叠, 在行的方向,求所有行的并集,如果出现没有的值,用NaN补齐
res1 = pd.concat((df1, df2), axis=1, join='outer')
print('res1:\n', res1)
# 在横向,直接堆叠,在行的方向,求所有行的交集
res2 = pd.concat((df1, df2), axis=1, join='inner')
print('res2:\n', res2)
(二)纵向堆叠-concat
当 axis=0 的时候,concat 做列对齐,然后将不同列名称的两张或多张表合并。
合并的原理图: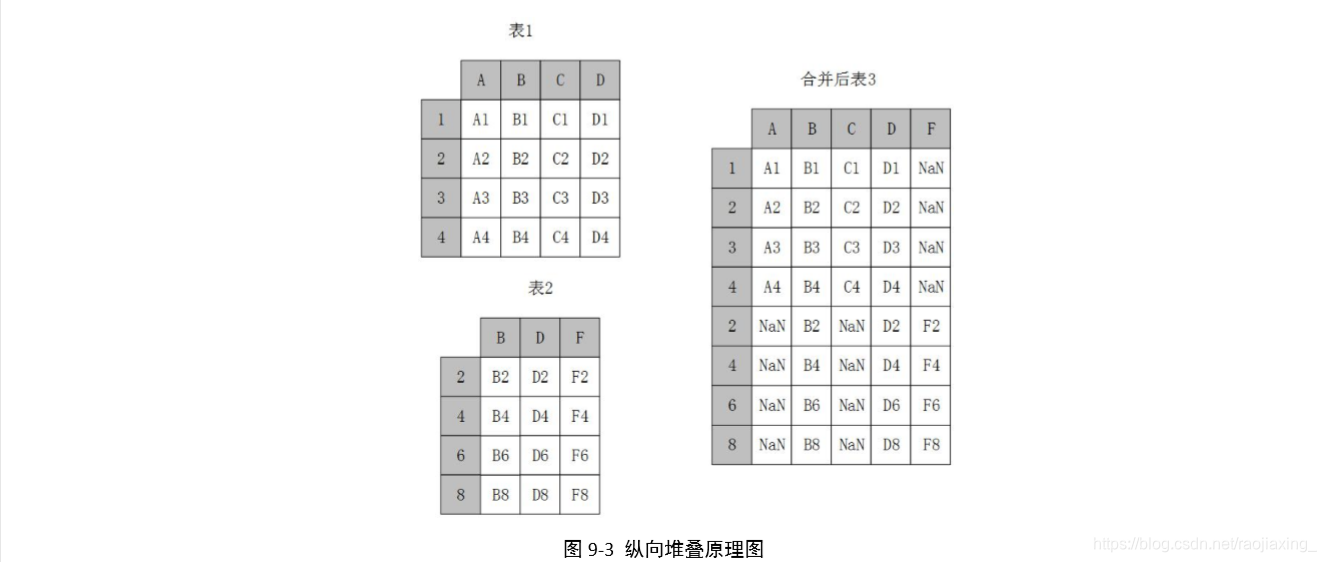
代码实现:
import pandas as pd
# # 加载数据
# df1 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=0)
# df2 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=1)
#
# print('df1:\n', df1)
# print('df2:\n', df2)
# 纵向堆叠---在行的 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2416
2416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









