






论文来自2017年的ACL。
Abstract
现有的问答方法从知识库或原始文本推断答案。虽然知识库 (KB) 方法擅长回答组成问题,但它们的性能往往受到 KB 的不完整性的影响。相反,网络文本包含数百万在 KB 中不存在的事实,但是以非结构化的形式。通用模式可以支持对结构化 KB 和非结构化文本的联合进行推理,方法是将它们对齐在公共嵌入空间中。在本文中,我们将通用模式扩展到自然语言问答,利用记忆网络来处理文本和知识库组合中的大量事实。我们的模型可以在问答对上以端到端的方式进行训练。 SPADES 填空问答数据集的评估结果表明,利用通用模式进行问答比单独使用 KB 或文本更好。该模型还比当前最先进的模型高 8.5 F1 分.
1 Introduction
问答 (QA) 一直是自然语言处理的长期目标。解决这个问题的两个主要范式:1)在知识库上回答问题; 2) 使用文字回答问题。
知识库 (KB) 包含以固定模式表示的事实,有助于组合推理。这些从计算机科学的早期就吸引了研究,例如棒球(Green Jr et al., 1961)。这个问题已经成熟到从并行问题和逻辑形式对(Zelle 和 Mooney,1996;Zettlemoyer 和 Collins,2005)学习语义解析器,到最近使用问答对处理非常大的 KB 的方法(如 Freebase)(Berant 等等人,2013)。然而,这种范式的一个主要缺点是 KB 高度不完整(Dong et al., 2014)。知识库关系结构是否足以表达世界知识也是一个悬而未决的问题(Stanovsky et al., 2014; Gardner and Krishnamurthy, 2017)
利用文本提出问题的范式始于 1990 年代初(Kupiec,1993)。随着网络的出现,对文本资源的访问变得丰富而廉价。像 TREC QA 竞赛这样的举措有助于推广这种范式(V oorhees 等,1999)。随着深度学习的最新进展和大型公共数据集的可用性,在很短的时间内出现了研究爆炸式增长(Rajpurkar 等人,2016;Trischler 等人,2016;Nguyen 等人,2016;Wang 和姜,2016;Lee 等人,2016;Xiong 等人,2016;Seo 等人,2016;Choi 等人,2016)。尽管如此,文本表示是非结构化的,并且不允许结构化知识库支持的组合推理。
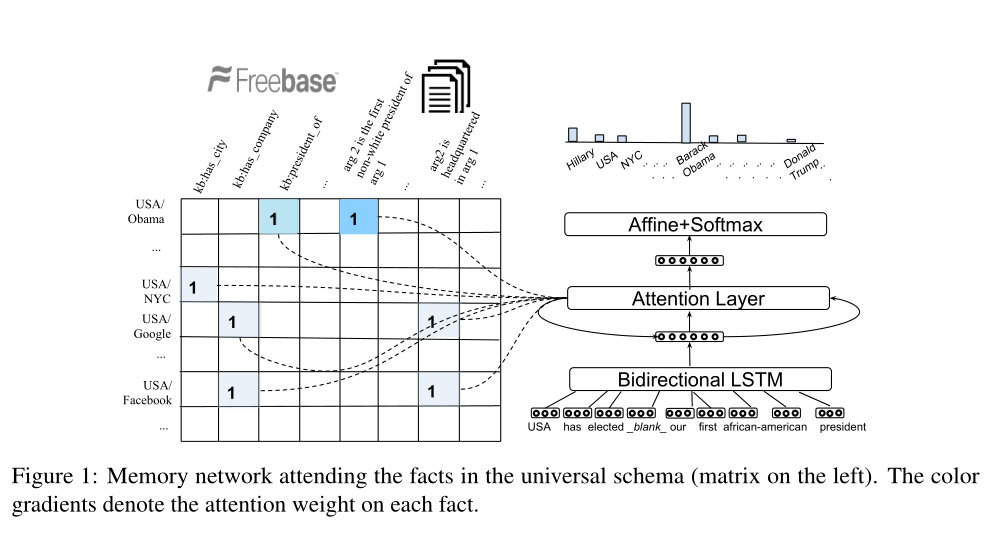
一个重要但未被充分探索的 QA 范式是知识库和文本一起被利用(Ferrucci et al., 2010)。这种组合很有吸引力,因为文本包含数百万不存在于 KB 中的事实,并且 KB 的生成能力代表了文本中从未见过的无限数量的事实。然而,由于 KB 的结构不均匀性和 QA 对这种组合的推断具有挑战性文本。远程监督方法(Bunescu 和 Mooney,2007;Mintz 等人,2009;Riedel 等人,2010;Yao 等人,2010;Zeng 等人,2015)通过将文本模式与 KB 对齐来部分解决这个问题.但是语言的丰富和模棱两可的性质允许以这些模型无法捕捉的许多不同形式表达一个事实。通用模式 (Riedel et al., 2013) 通过将知识库事实和文本联合嵌入到一个统一的结构中来避免对齐问题表示,允许信息的交错传播。图 1 显示了一个通用模式矩阵,该矩阵将实体对作为行,将 Freebase 和文本关系作为列。尽管通用模式已被广泛用于关系提取,但本文展示了它对 QA 的适用性。考虑美国选举了空白的问题,我们的第一位非裔美国总统及其答案是巴拉克奥巴马。虽然 Freebase 有一个代表美国总统的谓词,但它没有一个代表“非裔美国人”总统的谓词。而在文本中,我们发现许多句子同时描述了巴拉克奥巴马的总统职位和他的种族。与仅依赖其中一个资源相比,利用知识库和文本可以相对容易地回答这个问题。
记忆网络 (MemNN; Weston et al. 2015) 是一类神经模型,具有用于编码短期和长期上下文的外部记忆组件。在这项工作中,我们将记忆组件定义为通用模式矩阵的观察单元,并在问答对上训练端到端 QA 模型。
论文的贡献如下(a)我们表明,通用模式表示比单独的 KB 或文本是更好的 QA 知识源,(b)在包含真实世界的 SPADES 数据集(Bisk et al., 2016)上在填空题中,我们以 8.5 F1 分超越了最先进的语义解析基线。 (c) 我们的分析显示了单个数据源如何帮助填补另一个数据源的弱点,从而提高整体性能。
2 Background
问题定义给定一个带有单词w1、w2、…、wn的问题q,其中这些单词包含一个空格和至少一个实体,我们的目标是使用知识库K和文本T用答案实体qa填充此空格。表2中给出了几个问题答案对示例。
Universal Schema 传统的通用模式是在知识库人口背景下用于关系提取的。模式中的行由实体对(如USA、NYC)组成,列表示它们之间的关系。关系可以是KB关系,也可以是大型语料库中这两个实体之间存在的文本模式。实体和关系类型的嵌入是通过低秩矩阵分解技术学习的。Riedel等人(2013年)将文本模式视为静态符号,而V erga等人(2016年)最近的工作将其替换为RNN获得的句子的分布式表示。使用分布式表示可以对意义相似但表面形式不同的句子进行推理。我们也使用这种变体来编码文本关系。
Memory Networks MemNNs是具有外部和可微记忆的神经注意模型。MemNN将内存组件与网络解耦,从而允许它存储外部信息。此前,这些方法已成功应用于知识库的问答,其中内存中充满了知识库三元组的分布式表示(Bordes等人,2015),或用于阅读理解(Sukhbaatar等人,2015;Hill等人,2016),其中内存由理解中句子的分布式表示组成。最近,引入了键值MemNN(Miller et al.,2016),其中每个内存插槽由一个键和值组成。注意力权重仅通过将问题与关键记忆进行比较来计算,而该值用于计算上下文表示以预测答案。我们将此MemNN变体用于我们的模型。Miller等人(2016年)在他们的实验中,将KB三元组或句子存储为记忆,但他们没有像我们一样明确建模包含不同数据源的多个记忆。
3 Model
我们的模型是一个内存为通用模式的MemNN。图1显示了模型体系结构。
Memory:我们的内存M由来自通用模式的KB和文本三元组组成。每个存储单元都以键值对的形式存在。让(s,r,o)∈ K表示一个KB三元组。我们用由主题实体s和关系r的嵌入s和r串联而成的分布式密钥k来表示这个事实。对象实体o的嵌入o被视为其值v。
让(s,[w1,…,arg1,……,arg2,wn],o)∈ T表示文本事实,其中arg1和arg2对应于实体的“s”和“o”的位置。我们将密钥表示为通过将arg1替换为“s”,将arg2替换为特殊的“blank”标记而形成的序列,即k=[w1,…,s,…,blank,wn],而value只是实体“o”。我们使用双向LSTM将k转换为分布式表示(Hochreiter和Schmidhuber,1997;Graves和Schmikhuber,2005),其中k∈ 由前向和后向LSTM的最后状态串联而成,即k=
。值v是对象实体o的嵌入。将知识库和文本事实投影到R2d中提供了一个统一的知识视图来进行推理。在图1中,矩阵中的每个单元格表示一个内存,其中包含其键和值的分布式表示。
Question Encoder:双向LSTM还用于将输入问题q编码为分布式表示q∈ R2d类似于上面的密钥编码步骤。
Attention over cells:我们计算记忆细胞的注意力权重,方法是将其键k与上下文向量c的点积相加,上下文向量c编码当前迭代中最重要的上下文。在第一次迭代中,上下文向量是问题本身。我们只考虑问题中至少包含一个实体的存储单元。例如,对于图1中的输入问题,我们只考虑包含USA的记忆单元。使用记忆单元的注意权重和值,我们计算下一次迭代t的上下文向量ct,如下所示:
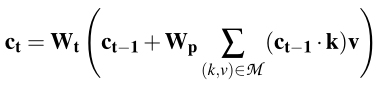
其中,c0是用问题嵌入q初始化的,Wp是一个投影矩阵,Wt表示权重矩阵,它根据重要性(注意权重)考虑上一跳中的上下文和当前迭代中的值。这种多重迭代上下文选择允许多跳推理,而无需显式地要求符号查询表示。
Answer Entity Selection:最终上下文向量ct用于选择答案实体qa(在数据集中的所有1.8M实体中),它具有最高的内积。
4 Experiments
4.1 Evaluation Dataset
我们使用Freebase(Bollacker等人,2008)作为知识库,使用ClueWeb(Gabrilovich等人,2013)作为文本源来构建通用模式。对于评估,文献提供了两种选择:1)基于文本的问答任务的数据集,如答案句子选择和阅读理解;和2)知识库问答数据集。
尽管基于文本的问答数据集规模很大,例如SQuAD(Rajpurkar等人,2016)有超过10万个问题,但这些问题的答案通常不是实体,而是句子,不是我们工作的重点。此外,这些文本可能根本不包含Freebase实体,使得这些实体严重偏向文本。谈到替代选项,WebQuestions(Berant等人,2013)广泛用于Freebase上的QA。该数据集经过整理,所有问题都可以在Freebases上单独回答。但是,由于我们的目标是探索通用模式的影响,因此在KB上完全负责的数据集上进行测试并不理想。WikiMovies数据集(Miller等人,2016)也具有类似的属性。Gardner和Krishnamurthy(2017)创建了一个动机与我们相似的数据集,但在提交期间并未公开发布。
相反,我们使用SPADES(Bisk et al.,2016)作为我们的评估数据,其中包含从ClueWeb创建的填空完形填空式问题。这个数据集非常适合测试我们的假设,原因如下:1)它很大,有93K个句子和1.8M个实体;2)因为这些句子是从网络上收集的,所以大多数句子都是自然的。该数据集的一个局限性是,它只包含由Freebase中至少一个关系连接的实体的句子,这使得它向Freebases倾斜,正如我们将看到的那样(§4.4)。我们使用标准的训练、开发和测试分割进行实验。对于通用图式的文本部分,我们使用训练集中的句子。
4.2 Models
我们评估以下模型,以衡量不同知识来源对QA的影响。
ONLYKB:在这个模型中,MemNN内存只包含来自KB的事实。对于每个KB三元组(e1、r、e2),我们有两个内存插槽,一个用于(e1,r,e2)而另一个用于其逆(e2,ri,e1)。
ONLYTEXT:SPADES包含带空格的句子。我们用答案实体替换空白标记,以从训练集中创建文本事实。使用每对实体,我们创建一个类似于通用模式中的存储单元。
ENSEMBLE这是上述两个模型的集合。我们使用一个线性模型来组合来自的分数,并使用集合来组合来自各个模型的证据。
UNISCHEMA 这是我们的主要模型,它使用通用模式作为内存,也就是说,它包含对应于KB和文本事实的内存槽。


4.3 Implementation Details
单词、实体和关系嵌入以及LSTM状态的维度设置为d=50。单词和实体嵌入是用word2vec(Mikolov等人,2013)初始化的,该单词和实体嵌入式是在750万个ClueWeb句子中训练的,这些句子包含SPADES的Freebase子集中的实体。使用Xavier初始化初始化网络权重(Gloot和Bengio,2010)。对于一个问题,我们最多考虑了5k KB的事实和2.5k的文本事实。我们使用Adam(Kingma and Ba,2015)和默认超参数(学习率=1e3,β1=0.9,β2=0.999,ε=1e-8)进行优化。为了克服爆炸性梯度,我们将梯度的'2范数的大小限制为5。训练期间的批量大小设置为32。
为了训练UNISCHEMA模型,我们从经过训练的ONLYKB模型初始化参数。我们发现,这对UNISCHEMA发挥作用至关重要。另一个警告是需要使用类似于批量规范化的技巧(Ioffe和Szegedy,2015)。对于每个小批次,我们规范化文本事实的平均值和方差,然后缩放和移位以匹配KB内存事实的平均数和方差。从经验上讲,这稳定了训练,提高了最后的表现。
4.4 Results and Discussions
表1显示了SPADES的主要结果。UNISCHEMA优于我们所有的模型,验证了我们的假设,即利用通用模式进行QA比单独使用KB或文本要好。尽管SPADES的创建过程对Freebase很友好,但利用文本仍然可以提供显著的改进。表2显示了UNISCHEMA回答的一些问题,但只有ONLYKB没有回答。这些关系可以大致分为(a)Freebase中没有表达的关系(例如,第1句中的非洲裔美国总统);(b) 蓄意事实,因为精心策划的数据库只代表具体的事实,而不是意图(例如,在第2句中威胁要离开);(c) 比较谓词,如第一、第二、最大、最小(如句子3和4);以及(d)提供额外的类型约束(例如,在第5句中,Freebase与父亲没有特殊关系。可以使用关系父母和类型约束来表示答案是男性性别)。
我们还分析了UNISCHEMA关注的性质。在58.7%的案例中,注意力倾向于知识库事实而非文本。这与预期相符,因为知识库的事实比文本更具体、更准确。在34.8%的情况下,即使事实已经存在于知识库中,记忆还是倾向于阅读文本。对于其余的人(6.5%),记忆平均分配注意力权重,这表明对于一些问题,部分证据来自文本,部分来自KB。表3对三种模型进行了更详细的定量分析,并进行了相互比较。
为了了解UNISCHEMA的可靠性,我们逐渐增加了知识库的覆盖范围,只允许每个实体使用固定数量的随机选择的知识库事实。如图2所示,当知识库覆盖率低于每个实体16个事实时,UNISCHEMA的表现远远优于ONLYKB,这表明即使在资源稀缺的情况下,UNISCHEMA也很稳健,而ONLYK对覆盖率非常敏感。UNISCHEMA的表现也优于ENSEMBLE,表明在单个模型上,联合建模优于整体建模。我们还以8.5 F1积分的差距达到了最先进的水平。Bisk等人使用图形匹配技术将自然语言转换为Freebase查询,而即使没有显式的查询表示,我们的性能也优于它们。
5 Related Work
大多数侧重于利用知识库和文本的QA文献要么改进了使用基于文本的特征对知识库的推断(Krishnamurthy和Mitchell,2012;Reddy等人,2014;Joshi等人,2014年;Yao和V an Durme,2014;Yih等人,2015年;Neelakantan等人,2015b;Guu等人,2015;Xu等人,2016b;Choi等人,2015,Savenkov和Agichtein,2016年),要么改进了关于知识库的推理文本使用KB(Sun等人,2015)。
联合利用文本和知识库进行问答的工作有限。Gardner和Krishnamurthy(2017)与我们最接近,他们生成了一个开放词汇逻辑形式,并根据在Freebase和文本中出现这种逻辑形式的可能性对候选答案进行排名。我们的模型在较弱的监督信号上进行训练,而不需要对逻辑形式进行注释。
一些QA方法推断了结合OpenIE三元组的精选数据库(Fader等人,2014;Yahya等人,2016;Xu等人,2016a)。我们的工作在两个方面与他们不同:1)我们不需要显式数据库查询来检索答案(Neelakantan等人,2015a;Andreas等人,2016);与OpenIE三元组不同,我们基于文本的事实保留了完整的句子上下文(Banko等人,2007;Carlson等人,2010)。
6 Conclusions
在这项工作中,我们展示了通用模式比单独使用知识库或文本更有希望成为QA的知识源。我们的结果表明,虽然当KB包含感兴趣的事实时,KB比文本更受欢迎,但大部分查询仍然关注文本,这表明文本和KB的混合比单独使用KB要好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









