



1.培根加密:培根加密(Bacon’s Cipher)是一种替换式隐写密码,由英国哲学家、科学家弗朗西斯・培根(Francis Bacon)在 16 世纪末提出。它的核心特点是通过两种 “符号” 的组合来隐藏信息,且加密后的内容看起来像正常文本,因此兼具 “加密” 和 “隐写” 的双重特性 —— 不仅对信息加密,还隐藏了 “存在加密信息” 这一事实。
2.Base91 是一种用于将二进制数据转换为 ASCII 字符串的编码方案,与 Base64 类似,但效率更高。它通过使用 91 个可打印 ASCII 字符来表示数据,比 Base64 的 64 字符集更紧凑,编码后的数据长度通常比 Base64 短约 14%
3.兔子加密(Rabbit Cipher)是一种高性能流密码算法,由丹麦学者 Martin Boesgaard 等人于 2003 年提出。它通过生成伪随机密钥流与明文异或实现加密,兼具高速与安全性,被广泛应用于实时通信和资源受限设备。
4.Ook! 加密是一种基于二进制编码的简单替代密码,它通过将每个二进制位(0 或 1)映射为特定的三词短语组合来隐藏信息。这种加密方式的核心特点是使用类似自然语言的短语(如 “Ook.”、“Ook?”、“Ook!”)来表示二进制数据,使密文看起来像有意义的文本,从而增加隐蔽性。
5.Base92 编码是一种二进制到文本的编码方式,属于 Base 系列编码的一种,其设计目标是通过更高效的字符映射实现比 Base64 更紧凑的编码结果。其核心特征如下:
字符集:92 个可打印 ASCII 字符
Base92 使用 92 个可打印字符作为编码符号,字符集通常包含:
大写字母(A-Z,26 个)
小写字母(a-z,26 个)
数字(0-9,10 个)
部分标点符号(如!、#、$、%、&、'、(、)、*、+、,、-、.、/、:、;、<、=、>、?、@、[、]、^、_、```、{、|、}、~等,共 30 个左右,具体实现可能略有差异)
6.栅栏密码(Rail Fence Cipher)是一种古典置换密码,核心原理是通过改变明文字符的排列顺序(而非替换字符)来实现加密,因字符排列形似栅栏而得名。
7.一个 ZIP 文件由三个部分组成:
压缩源文件数据区 + 压缩源文件目录区(核心目录记录区) + 压缩源文件目录结束标志(目录记录尾部区)
1.压缩源文件数据区:
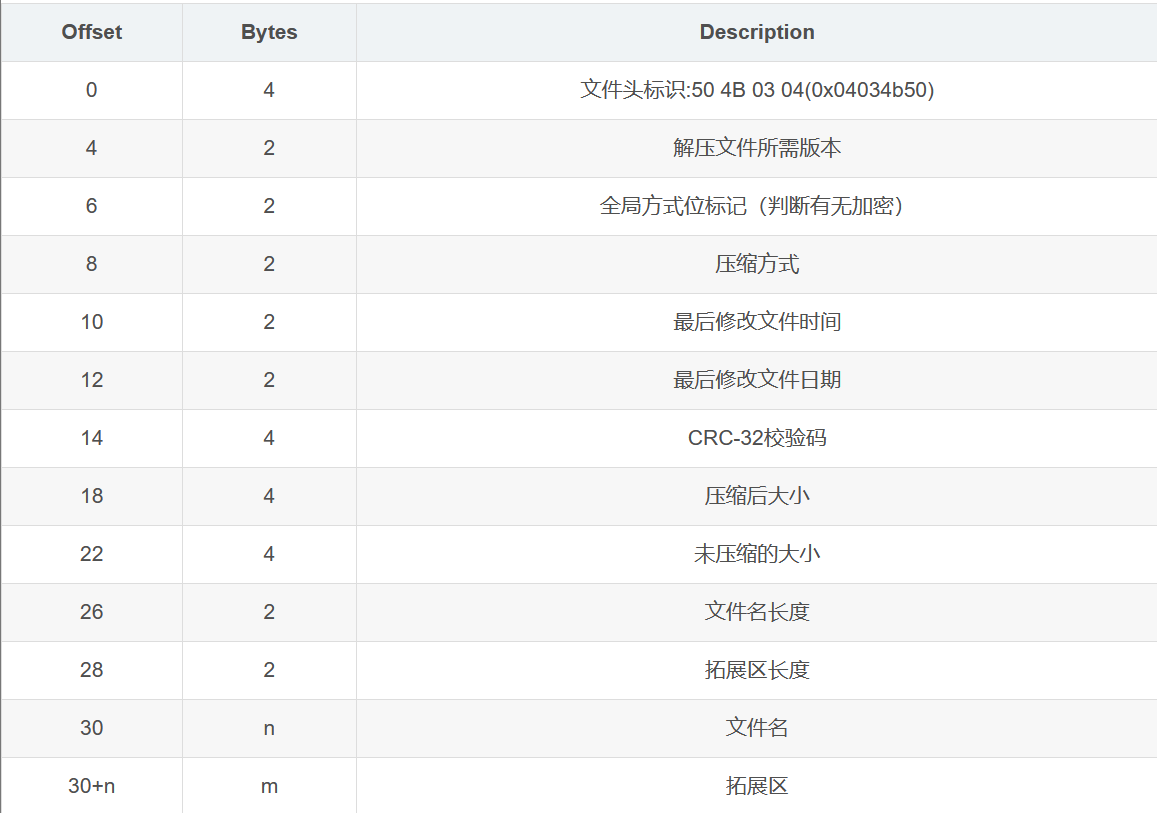
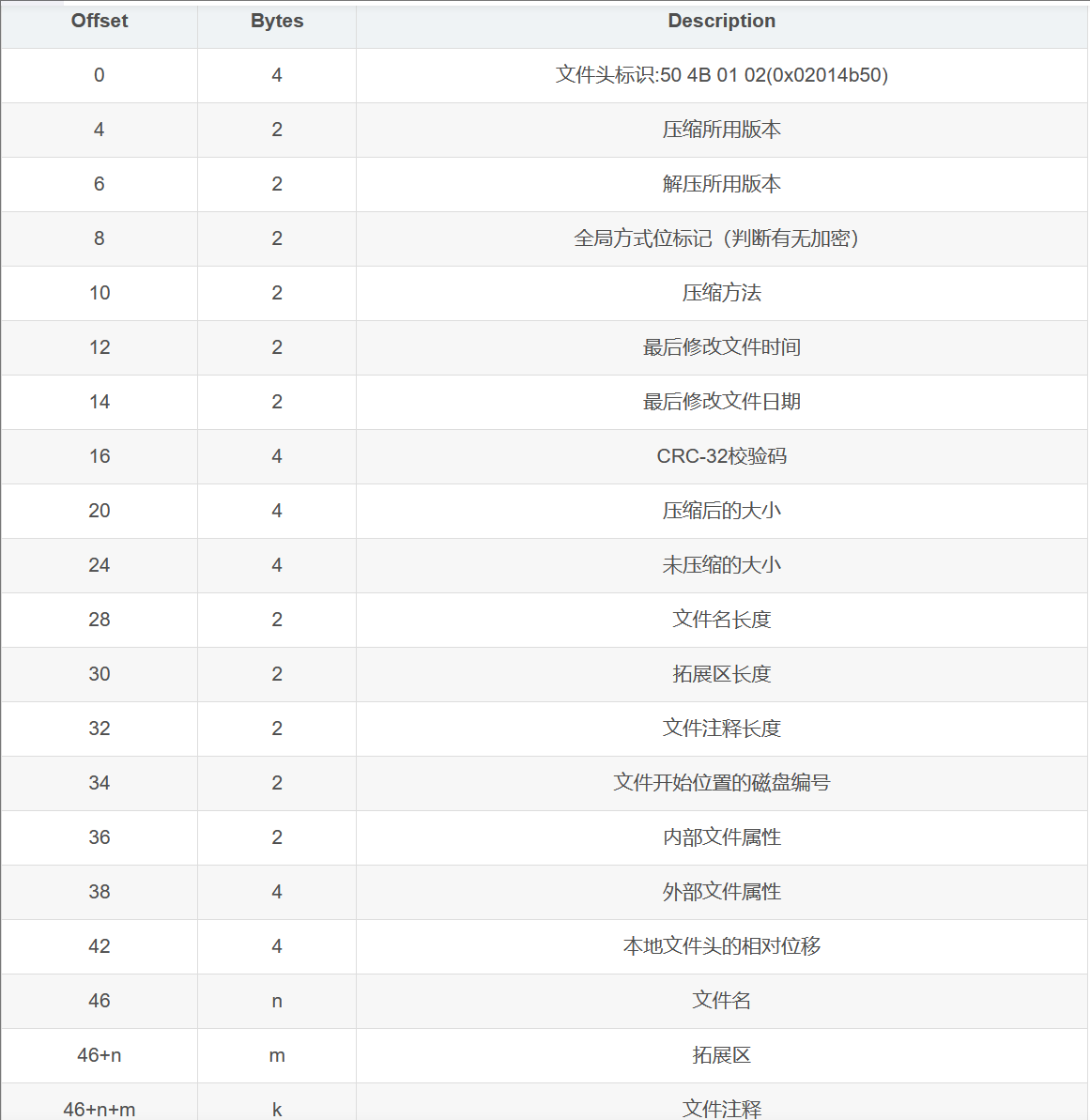
2.压缩源文件目录区(也称核心目录记录区 ):
一条核心目录记录对应数据区中的一个 压缩文件记录
Offset Bytes Description
8.&# 开头的是html实体编码
9.图片的 CRC(循环冗余校验码,Cyclic Redundancy Check)是一种用于检测图片文件数据完整性的校验机制。它通过特定的算法对图片数据进行计算,生成一个唯一的校验码,用于验证数据在传输、存储或处理过程中是否发生错误或损坏。
10.一、ZIP文件组成部分
压缩源文件数据区:
50 4B 03 04:这是头文件标记(0x04034b50)
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密)
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
00 00:扩展记录长度
压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记(0x02014b50)
3F 00:压缩使用的 pkware 版本
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密,这个更改这里进行伪加密,改为09 00打开就会提示有密码了)
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
24 00:扩展字段长度
00 00:文件注释长度
00 00:磁盘开始号
00 00:内部文件属性
20 00 00 00:外部文件属性
00 00 00 00:局部头部偏移量
压缩源文件目录结束标志:
50 4B 05 06:目录结束标记
00 00:当前磁盘编号
00 00:目录区开始磁盘编号
01 00:本磁盘上纪录总数
01 00:目录区中纪录总数
59 00 00 00:目录区尺寸大小
3E 00 00 00:目录区对第一张磁盘的偏移量
00 00:ZIP 文件注释长度
二、识别真假加密
无加密
压缩源文件数据区的全局加密应当为 00 00
且压缩源文件目录区的全局方式位标记应当为 00 00
假加密
压缩源文件数据区的全局加密应当为 00 00
且压缩源文件目录区的全局方式位标记应当为 09 00
真加密
压缩源文件数据区的全局加密应当为 09 00
且压缩源文件目录区的全局方式位标记应当为 09 00


















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









