







参考: http://blog.csdn.net/qq_18333833/article/details/73381490
通过一段时间对MySQL数据库的学习,并且参考了好多别人的博客,对MySQL性能方面有了一定的学习与理解。大家都知道关于数据库性能优化有多个方面,比如:MySQL服务器硬件(CPU、内存、磁盘、网络)优化、查询速度优化、更新速度优化以及应用层架构优化。另外具体通过合理安排资源,调整系统参数使数据库系统运行更快、节省相应的资源。
MySQL 优化有以下几方面:
一方面找出系统瓶颈,提高数据库整体性能;
另一方面需要合理的结构设计和参数调整,以提高用户操作响应速度;同时还要尽可能节省系统资源,以便系统可以提红更大符合的服务。
例如:通过优化文件系统,提高磁盘I/O的读写;通过优化操作系统调度策略,提高MySql 在高负荷下的负载能力;优化表结构,索引、缓存区等
在MySql 中使用show status 语句查询一些MySql 数据库的性能:
eg:SHOW STATUS LIKE ‘value’
其中value是要查询的参数值,一些常用的性能参数如下:
1,connections:链接mysql服务器的次数
2,uptime:MySql服务器的上线时间
3,Slow_queries:慢查询次数
4,com_select:查询操作的次数
5,com_insert:插入操作的次数
6,com_update:更新操作的次数
7,com_delete:删除操作的次数
SQL 语句优化基本原则:
1)避免全表扫描 ;
2)建立索引;
3)尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理;
4)尽量避免大事务操作,提高系统并发能力 ;
5)使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。尽量避免使用游标,因为游标的效率较差。
一些技巧:
关于where后的条件:
1)应尽量避免在where 字句中使用!=或<>操作符否则引擎将放弃使用索引而进行全表扫描 ;
2)尽量避免在where语句中使用or来连接条件,可以考虑使用union 代替 ;
3)慎用in和not in ,对于连续的数值,能用between 就不要用 in,exists 代替in ;
4) 尽量避免在where字句中对字段进行表达式操作和函数操作。
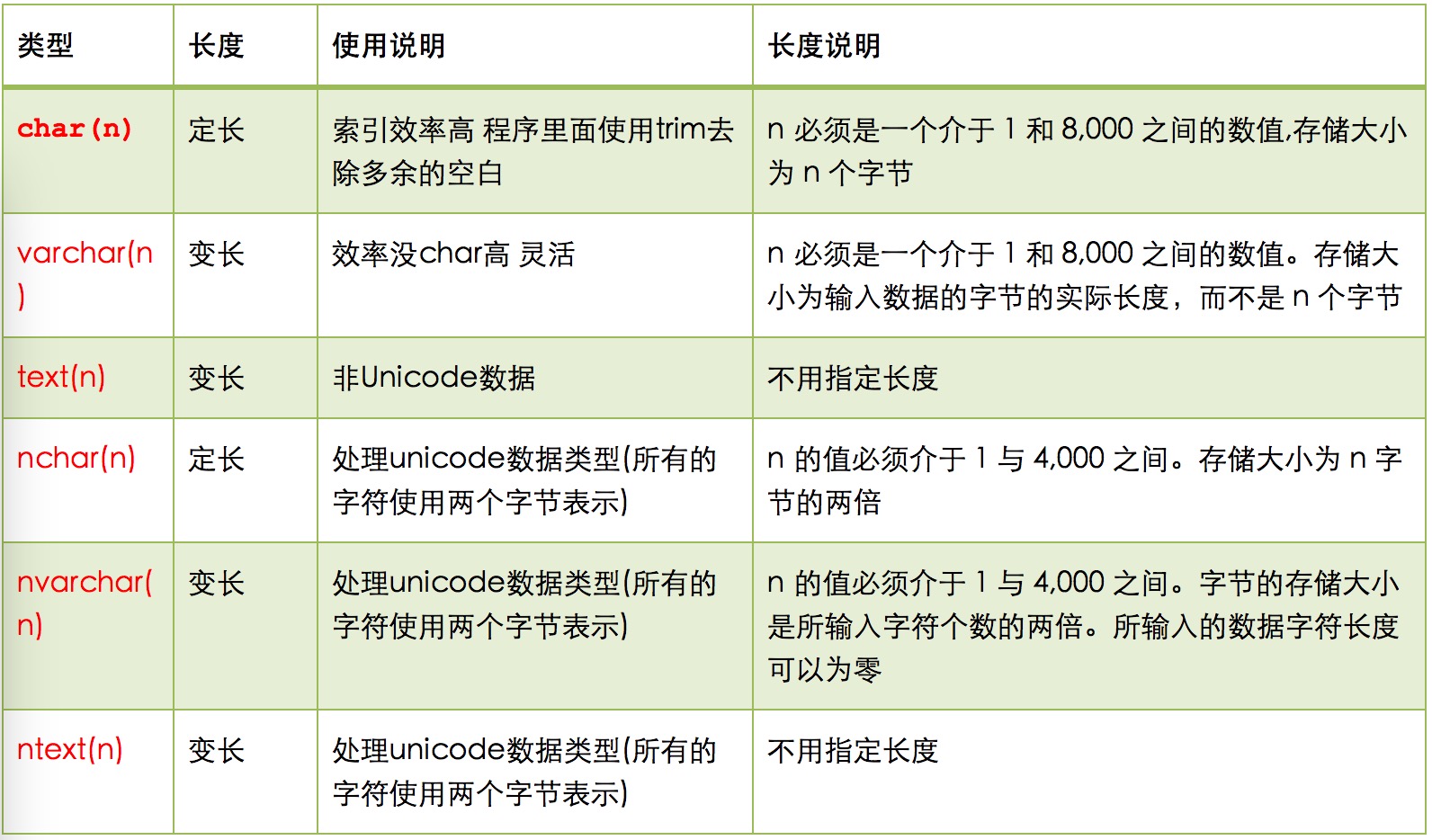
关于数据类型
1)尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销 ;
2)尽可能使用varchar/nvarchar 代替char/ncahr ,因为变长字段存储空间小,对于查询来说,在一个相对较小的字段内搜索效率明显要高些;
3)最好不要给数据库留null,尽可能使用not null 填充.数据库,备注、描述、评论之类的可以设置null,其他的尽量不要使用null ;
4)任何地方都不要使用select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
count():两个作用,
其一、统计某个列值的数量,
其二、是统计行数。统计列值时,要求列值非空,它不会统计null.如果确定括号中表达式不为null,实际就是在统计行数,即count(*).如果不需要完全进准的count 值,可以使用explain
关联查询优化:在大数据场景下,表和表之间通过一个冗余字段来关联,要比使用join 有更好的性能。如果确实需要关联查询,需要注意:
1,确保ON 和USING 语句的列上有索引,在创建索引的时候就要考虑到关联的顺序
2,确保任何的GROUP BY 和ORDER BY 中的表达式只涉及到一个表的列,这样MySql 才有可能使用索引来优化
LIMIT 分页优化:
当需要分页操作时,通常会使用limit 加上偏移量的办法实现,同时加上合适的order by 字句。如果有对应的索引,通常效率会不错。否则MySql 需要做大量的文件排序操作。
如果偏移量很大,如limit 10000,20 ,前面的10000条都将被抛弃,这样的代价非常高。
优化方式可以使用覆盖索引扫描,而不是查询所有列,然后根据需要做一次关联查询再返回所有的列。对于偏移量很大时,这样做的效率提升非常大
如:
select film_id,description from film order by title limit 10000,20改为:
select film.film_id,film.description from film inner join(
select film_id,description from film order by title limit 10000,20 )AS tmp using (film_id)
select id from t limit 10000,10
改为
select id from t where id>10000 limit 10- 1
关于临时表
1)避免频繁创建和删除临时表,以减少系统表资源的消耗;
2)在新建临时表的,如果一次性插入数据量很大,那么可以使用select into 代替create table,避免造成大量log,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert ;
3)如果使用到了临时表,在最后将所有的临时表显式删除时,先truncate table,然后drop table,这样可以避免系统表的较长时间锁定。
关于索引
1)应先考虑在where 及order by 涉及的列上建立索引 ;
2)在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引字段的第一个字段作为条件时,才能保证系统使用该索引,否则该索引不会被使用,并且尽可能让字段顺序与索引顺序相一致;
3)索引不是越多越好,索引固然可以提高相应的select 的效率,同时也降低了insert 和update的效率,因为insert 或update 时有可能会重建索引。所以视具体情况而定,一个表的索引数最好不要超过7个,若太多则应考虑一些不常使用的列上建立的索引是否必要。
架构的调优
1)分区分表
2)业务分库
3)主从同步与读写分离
4)数据缓存
5)主从热备与HA 双活
关于索引
建立索引的原则:
1)定义主键的数据列一定要建立索引。(一般数据库都会给主键自动建立索引)
2)定义有外键的数据列一定要建立索引
3)对于经常查询的数据列最好建立索引
4)对于需要在指定范围内快速或频繁查询的数据列
5)经常用在where 字句中的数据列
6)经常出现在关键字order by、group by、distinct后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被 使用
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit 的数据类型的列不要建立索引
9)限制表上的索引数目。对于存在大量更新操作的表,所建立的索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作
10)对于符合索引,按照字段在查询条件中的频度建立索引。在复合索引中,记录首先按照第一个字段排序,对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能的使用此索引,发挥索引的作用
一些常见的索引:
1)BTREE 索引-mysql 中主要的索引类型
2)RTREE索引-只有MyISAM支持,用于GIS
3)HASH索引-MEMORY,NDB支持
4)BITMAP 索引-MYSQL 不支持
5)FULLTEXT 索引-MyISAM,Innodb(MySql 5.6以上支持)
索引的分类:
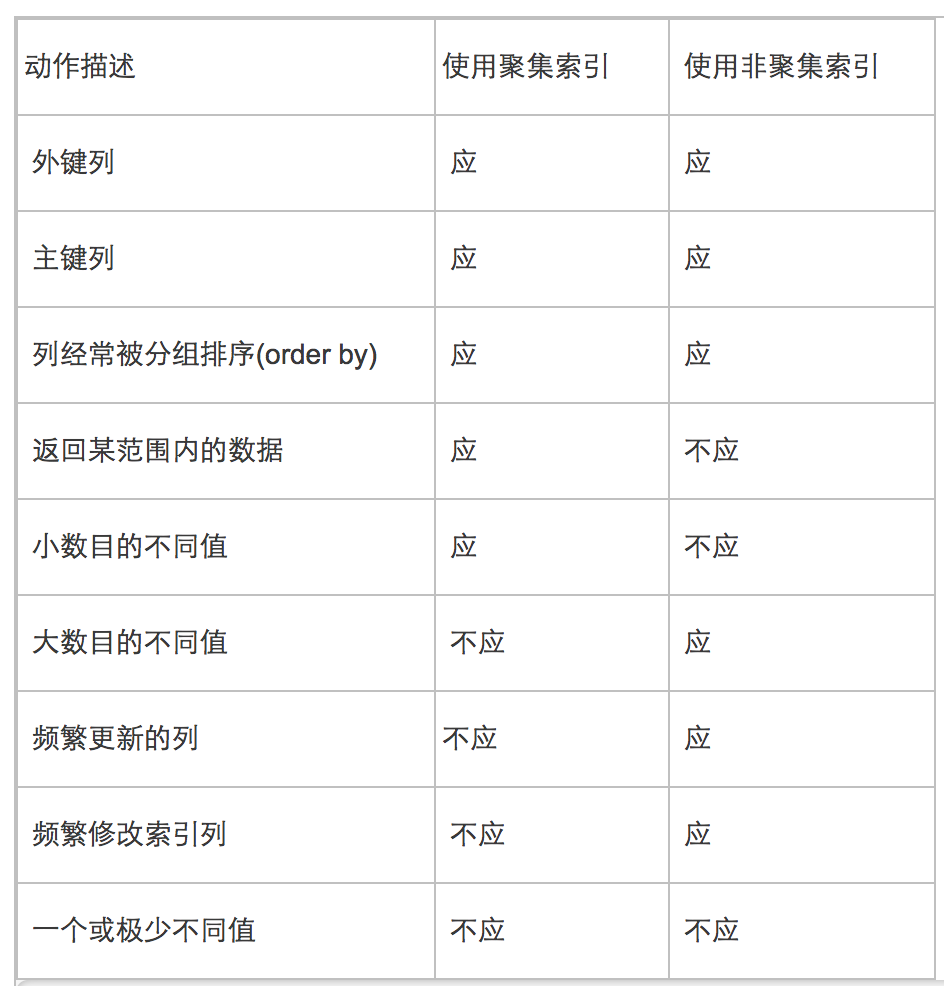
SQL 中的索引分为两种:一种为聚焦索引,另一种非聚焦索引
1)聚集索引:
可以理解为顺序排列。如:如过想要查找第100条,那么直接第一条数据的地址交上100 即为第一百条的地址,一次就能查询出来。
在mysql中,不能自己创建聚集索引,主键即为聚集索引,如果没有创建主键,那么默认非空的列为聚集索引,如果没有非空的列那么会自动生成一个隐藏列为聚集索引。
所以一般在mysql 中,创建的主键即为聚集索引,数据是按照我们的主键顺序进行排列。所以在根据主键查询时会非常快
2)非聚集索引
可以理解为有序目录,是一种空间换时间的方法:
eg:user表,有id_num 字段,这些数据在存储的时候都是无序的。
此时如果想要查找id_num 为56的人,那么只能一条条遍历,n条就需要查询n次,时间复杂度为o(n),非常耗费性能
如果为id_num 增加非聚集索引,添加非聚集索引后,会给id_num 进行排序(内部使用结构为B+树),并且排序后,我只需要查询此目录(即查询B+树),就能得到该条数据在数据库的位置,而不需要去遍历表中所有的数据。
所以,在非聚集索引中,不重复的数据越多,那么索引的效率越高。
在mysql 中可以分为以下几种索引:
1,普通索引:index(MyIASM 中默认的BTREE类型索引,也是最长用到的索引)
2,唯一索引:unique index
与普通索引类似,不同的是:索引的值必须唯一,但允许有空值(和主键不同)
3,全文索引(FULLTEXT)
仅可用于MyISAM 表
4,单列索引、多列索引
5,组合索引(最左前缀)
ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))
相当于建立了 title,time 和title 两个索引。
索引的操作
1,创建索引
1.1:创建普通索引
create index 索引名 on 表名 (列名1,列名2…)
修改表:
alter table 表名 add index 索引名(列名1,列名2…)
创建表时指定:
create table 表名([…],index 索引名(列名1,列名2…))
1.2 创建唯一索引
创建索引
create unique index 索引名 on 表名(列…)
在表上增加索引:
alter table 表名 add unique 索引名(列…)
创建表时指定:
create table 表名([…],unique 索引名(列…))
unique:唯一索引
CLUSTERED:聚集索引
NONCLUSTERED:非聚集索引
2,删除索引:
drop index 索引名 on 表名
alter table 表名 drop index 索引名
3,查看索引:
show index from 表名
返回字段:
table:表名
non_unique:是否不唯一,0唯一,1不唯一
key_name:索引的名称
seq_in_index:索引中的列序列号,从1 开始
column_name:列名称
Collation:列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。
Cardinality:索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
Packed:指示关键字如何被压缩。如果没有被压缩,则为NULL。
Null:如果列含有NULL,则含有YES。如果没有,则该列含有NO。
Index_type:用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
Comment:更多评注。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









