







动态采样(Oracle Dynamic sampling)
1.1首先回顾下动态采样(dynamic sampling)的相关知识点
这个特性,使数据库随机的扫描表中少量的block,用来增强数据库的统计信息。
1.1.1 目的
动态采样增加了那些丢失的或者不足的优化器统计信息。使用动态采样可以让优化器更好的选择谓词。动态采样能够补充类似表中block个数,相关的索引block个数,表的集势(ronded个数),相关的连接列的统计信息(提供extendedstatistics的功能)。
1.1.2 动态采样概念
动态采样默认为启动状态,可以设置 OPTIMIZER_DYNAMIC_SAMPLING=0来禁用掉这一特性。
OPTIMIZER_DYNAMIC_SAMPLING也是和动态采样最重要的参数,它控制着动态采样级别。
1.1.3 OPTIMIZER_DYNAMIC_SAMPLING动态参数说明
OPTIMIZER_DYNAMIC_SAMPLING
| Property |
Description |
| Parameter type |
Integer |
| Default value |
If If If |
| Modifiable |
|
| Range of values |
|
Dynamic Sampling Levels
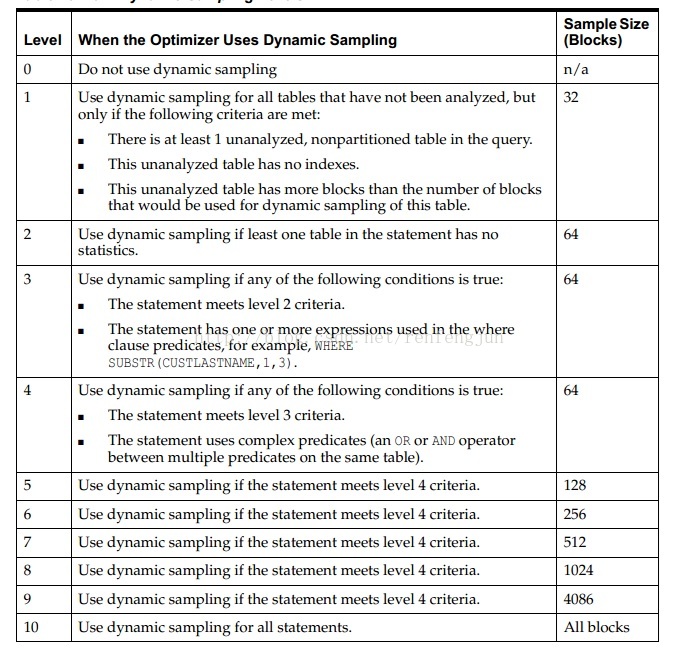
10g以上oracle database 的OPTIMIZER_DYNAMIC_SAMPLING参数默认值为2。
1.2 应用场景
下面列举3个动态采样的典型应用场景
1.2.1 缺失统计信息
当查询中的一个或者多个表没有统计信息,那么优化器就会收集关于表的基本信息用来执行优化操作。
1.创建表
dexter@DAVID> create table tuning8_tab1nologging as
2 select level as id , 'name'|| level as name
3 from dual
4 connect by level <= 10000 ;
Table created.
2.创建索引
_dexter@DAVID> create indexidx_tuning8_tab1_id on tuning8_tab1(id) ;
Index created.
3.查询测试
先看一下参数的设置
_dexter@DAVID> show parameter samp
NAME TYPE VALUE
----------------------------------------------- ------------------------------
optimizer_dynamic_sampling integer 2
_dexter@DAVID> select * from tuning8_tab1where id=2 ;
ID NAME
---------- --------------------------------------------
2 name2
Execution Plan
----------------------------------------------------------
Plan hash value: 3712969662
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 37 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID|TUNING8_TAB1 | 1 | 37 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TUNING8_TAB1_ID | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operationid):
---------------------------------------------------
2 -access("ID"=2)
Note
-----
-dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
3 physical reads
0 redo size
596 bytes sent via SQL*Net toclient
523 bytes received via SQL*Netfrom client
2 SQL*Net roundtrips to/fromclient
0 sorts (memory)
0 sorts (disk)
1 rows processed
动态采样已经起作用了。
1.2.2 缺失extendedstatistics
oracle提供相关性统计信息,这里简单演示了一种情况,说明动态采样可以使oracle数据库更加智能的选择查询计划,进而提升性能。(其实使用dbms_stats设置特定的参数一样可以达到这种目的)
1. 基于all_objects视图创建表
create table tect9_tab2 nologging
as select decode( mod(rownum,2), 0, 'D', 'R' )col1,
decode( mod(rownum,2), 0, 'R', 'D' ) col2, t.*
from all_objects t
2. 创建复合索引
create index idx_comp_tect9_tab2_col1_col2 ontect9_tab2(col1,col2) ;
3. 收集统计信息
execdbms_stats.gather_table_stats(user,'tect9_tab2',method_opt=>'for all indexedcolumns size 254' );
dexter@STARTREK> execdbms_stats.gather_table_stats(user,'tect9_tab2',method_opt=>'for all indexedcolumns size 254' );
PL/SQL procedure successfully completed.
4. 查询测试
数据总量为72566
dexter@STARTREK> select count(*) fromtect9_tab2 ;
COUNT(*)
----------
72566
已经收集了统计信息,所以常规的查询都可以得到正确的执行计划。
dexter@STARTREK> select * from tect9_tab2where col1='D' ;
Execution Plan
----------------------------------------------------------
Plan hash value: 32623
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









