









一. 简介
FastText(Bag of Tricks for Efficient Text Classification)是Facebook AI Research提出的一种神经网络结构,它是一个简单而又高效的线性分类模型,能够在很短的时间内实现海量文本分类,支持亿万数据量。
并且,facebook已经用C++优雅实现了fasttext,内置了很多tricks,一些情况下,它甚至能够超过一些调参复杂的深度神经网络。工业生产中,高效易用性使得它能够作为文本分类任务的基线使用。
实际上,从深度学习和人工智能的发展历程来看,简易性、准确性、高效性,解决其中任何一个难题的算法,都有可能引发革命的,是难能可贵的。简易型,例如jieba的易用性使得其成为python最受欢迎最广泛使用的分词器,又如近来火热的手机神经网络模型(moblie network),关键就在于减少模型参数,keras和pytorch的崛起,也说明了这一点;准确性,这个就不用说了,准确性,这正是我们所永恒追求的,例子特别多,bert的流行,CNN在图像领域的称霸;高效性,就是说速度快,这个也十分重要,速度就是生命,transfmer、attention的崛起伴随着rnn的衰落,fasttext、word2vec的应用。
所以,尽管FastTest看起来很简单,只有一层神经网络结构,但是也不容小觑。各种tricks尤其多。
FastText分类代码github地址:https://github.com/yongzhuo/Keras-TextClassification/tree/master/keras_textclassification
二. FastText网络
FastText的重点主要包括三个部分: N-gram特征、层次softmax、模型网络(fasttext model)
2.1 FastText模型图
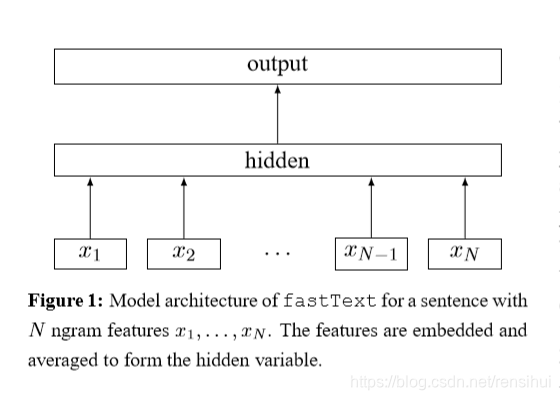
其实,就是一个简单的线性分类器,y=softmax(Wx+b)。其中,fasttext的文本表征,特征,也就是输入,和word2vec词向量工具的连续词袋(CBOW)很像。对N条短文本进行分类,使用符号为f的softmax函数分类,那么优化的目标函数就是下图的负对数似然。

上图中的符号的意思: Xn是第n个数据预处理后文本样本的特征,Yn是对应的label类别,A 、B是权重矩阵。
2.2 层次softmax
层次softmax也叫分层softmax,是为了解决softmax分类计算量大的问题。例如,知乎看山杯文本多标签分类比赛中有L(1999)个类,每个样本都计算L(1999)个类的概率,d是文本的表征维度,那么这时候的计算复杂度就是O(dL)=300*1999。
为了解决这个计算量大问题,有两种方法,一个是负采样(Negative Sampling,NEG(Noise Contrastive Estimation)的简化版),就是从L-1个类中取k(5-20、2-5)个样本比较就好,这样计算复杂度变成了O(dk)=300*5,但是会带来一定的计算损失。
另外一种方法就是层序softmax(Hierarchical Softmax),也就是将label按照出现的频率构建一棵Huffman树(这时候权重和最小,即最优二叉树),这时候复杂度变成O(d*log2(k)),k是树的深度。
推荐霍夫曼编码,应该看得懂:https://www.cnblogs.com/kubixuesheng/p/4397798.html
2.3 N-gram
N-gram特征应该不难提取,也容易懂,就是提取文本中所有的n个连续词。例如样本为['我',‘喜', '欢’, '你'],n=2,提取出来就是[('我',‘喜'), (‘喜', '欢’), ( '欢’, '你')]。
三.代码实现
3.1 代码实现起来也不难,就一层嘛,就是n-gram、hierarchical-softmax复杂些,不过网上也有很多资料啦。
3.2 github代码地址: https://github.com/yongzhuo/Keras-TextClassification/tree/master/keras_textclassification
代码中没有实现n-gram和hierarchical-softmax,不过应该也不难。
或者直接用facebook开源的fasttext工具就好,简单而且还优化得很好,比自己写的效果好多了。
3.3 关键代码:
def create_model(self, hyper_parameters):
"""
构建神经网络
:param hyper_parameters:json, hyper parameters of network
:return: tensor, moedl
"""
super().create_model(hyper_parameters)
embedding = self.word_embedding.output
x = GlobalMaxPooling1D()(embedding)
output = Dense(self.label, activation=self.activate_classify)(x)
self.model = Model(inputs=self.word_embedding.input, outputs=output)
self.model.summary(120)希望对你有所帮助!














 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









