







1. 介绍
C++程序编译很慢,特别是大型工程,你都可以趁着编译的功夫喝杯咖啡。这里面既有天灾也有人祸。
天灾请看此文,本文探讨怎么避免人祸。
2. 编译过程
后文需要,我们先了解C++源代码的编译过程

为叙述方便,图中各文件类型称呼如下:
- .h 头文件
- .cc 源文件
- .o 目标文件
本文不探讨链接过程,只考虑编译和预处理。
预处理
经过预处理后,头文件就消失了。因为 #include 预处理指令将其展开在源文件中,编译阶段是不需要头文件的。常见的预处理指令还有 #if, #elif, #end, #ifndef, #define 等。
#include 其实非常简单,就是把文件在当前位置展开,没有任何多余的功能和限制。所以你不仅能 #include 头文件,还可以 #include .cc文件, 甚至任何文件。
编译
经过预处理后,只剩下源文件了,编译就是把每个源文件转换成目标文件。记住,源文件和目标文件是一一对应的。
编译的实质,是根据源文件生成目标文件的代码段和数据段。这一点对于理解前向声明非常重要。
图解说
假设我们有4个源文件和4个头文件,include关系如下
// A.h A.cc
#include "B.h" #include "A.h"
----------------------------------------------------
// B.h B.cc
#include "C.h" #include "B.h"
----------------------------------------------------
// C.h C.cc
#include nothing #include "C.h"
----------------------------------------------------
// D.h D.cc
#include "A.h" #include "D.h"
#include "C.h" 我们可以用一张图来表示这8个文件的预处理和编译两个阶段
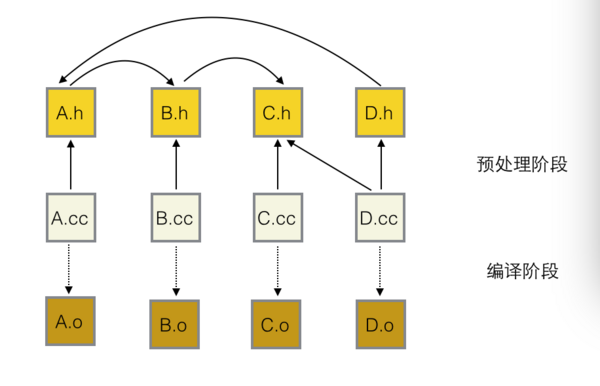
虚箭头表示编译,是一对一的,没什么好说的。实箭头表示 #incude 关系。如果一个文件有修改,那么所有直接或间接依赖它的源文件都要重新编译。下面我们就根据此图讲解C++工程中的代码依赖问题。
3. 重复include
D.cc两次包含C.h,一次直接包含,一次通过间接包含。这会引起重定义错误,有两种方法解决。
经典的 ifndef
// A.h
#ifndef A_H
#define A_H
// class definition
#endif
或者 pragma once
// A.h
#pragma once
// class defnition4. 循环依赖
一旦代码中有循环依赖,编译将失败。上文的8个文件没有循环依赖,图中找不到有向循环路径。
万一你的代码出现循环依赖,请将导致循环依赖的代码提出来,放到新文件中。
5. 前向声明
前两个问题关乎对错,跟编译速度关系不大。现在开始,我们探讨怎么加快代码编译速度。
我们向文件中加点东西
// A.h A.cc
#include "B.h" #include "A.h"
class A { ....
public:
void f1(B* b); void A::f1(B* b) {
b->f3();
void f2(); }
};
----------------------------------------------------
// B.h B.cc
#include "C.h" #include "B.h"
class B {
public:
void f3();
};
----------------------------------------------------
// C.h C.cc
#include nothing #include "C.h"
----------------------------------------------------
// D.h D.cc
#include "A.h" #include "D.h"
#include "C.h"
class D {
public:
private:
A a;
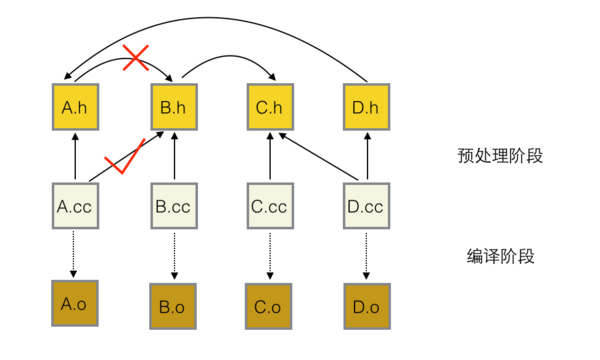
};根据前文的依赖图,如果 B.h 修改,那么 A.cc 和 D.cc 都要重新编译。但是, D.cc 不应该重新编译,因为 class D 只受 class A 内存布局的影响,而 class A 的内存布局与 class B 没有关系,只是f1需要一个class B指针的参数而已。
于是C++允许 A.h 不包含 B.h ,只需声明 class B 即可,告诉编译器 B 这丫是个类名哈。A.h用前向声明替代include,但是 A.cc 中利用了 class B 的实现,所以 A.cc 要加一条 include(放心,源文件中的include不会传染,很少有 include 源文件的)
// A.h A.cc
class B; #include "A.h"
#include "B.h"
class A { ....
public:
void f1(B* b); void A::f1(B* b) {
b->f3();
void f2(); }
};依赖线一增一减,数量虽然没变,但是效果改善不少啊
6. Pimpl idiom
是不是有点儿累了,先歇会儿,然后再来看另外一个削减依赖的重磅武器 Piml(pointer to implementation)。
pimpl idiom主要运用在库的接口设计中。如果团队人数达100,有一个维护基础库的小组。原则上除了接口升级,基础库的任何升级都不应该触发应用层模块的重编译。
我们假设 A.h 是基础库的接口,B.cc 是应用层源文件。
// A.h A.cc
#include "xx.h"
#include "yy.h"
#include "zz.h"
class A {
public:
A(); A() { ... }
~A(); ~A() { ... }
void f1(); void A::f1() { ... }
void f2(); void A::f2() { ... }
private:
XX x;
YY y;
ZZ z;
};
-----------------------------------------------------
// B.cc
#include "A.h"
class B {
public:
private:
A a;
};依赖图如下
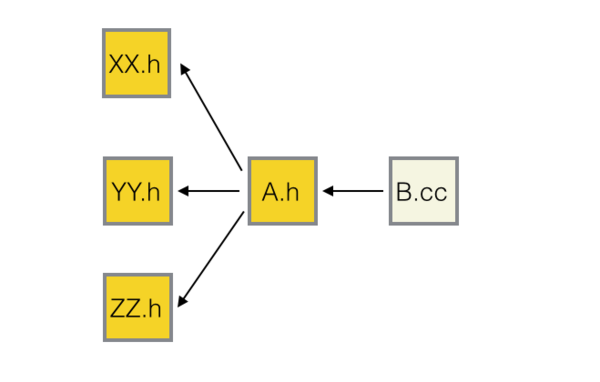
从依赖图明显看出这种代码组织方式有缺陷,XX.h, YY.h, ZZ.h 任何一个文件的修改都会触发 B.cc 重编译。那三个文件都是库内部的文件,原则上是与B.cc无关的,并且这三个头文件很可能包含别的头文件,导致程序库最深处的修改都能轻易触发应用层代码重编译。
这时候该Pimpl显身手了,我们把 A.h, A.cc 改造如下
// A.h A.cc
class A { #include "A.h"
public: #include "XX.h"
A(); #include "YY.h"
~A(); #include "ZZ.h"
void f1();
void f2(); class A::Impl {
private: public:
class Impl; Impl() { ... }
Impl* impl_; ~Impl() { ... }
}; void f1() { ... }
void f2() { ... }
private:
XX x;
YY y;
ZZ z;
};
A::A() : impl_(new A::Impl()) {}
A::~A() { delete impl_; }
void A::f1() {
impl_->f1();
}
void A::f2() {
impl_->f2();
}
把A中所有非接口的东西都移到Impl中去,依赖图变成下面的样子。
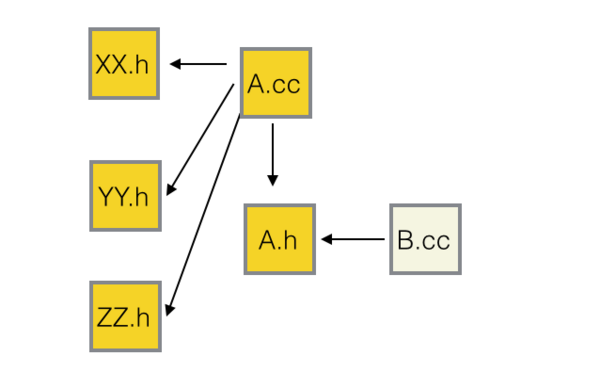
从依赖图看出,只有 A.h 的修改才能触发 B.cc 重编译,而 A.h 中只有库接口,库的接口都变了,应用层当然要重编译咯。
7. 参考资料
1.C++ Compilation Speed
2.Pimpl For Compile-Time Encapsulation (Modern C++)
本文转自:怎样削减C++代码间依赖
作者:wankai
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









