







http://blog.csdn.net/v_july_v/article/details/6403777#comments
题目描述:
给你上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据。
分析:上千万或上亿的数据,现在的机器的内存应该能存下(也许可以,也许不可以)。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了。当然,也可以堆实现。
ok,此题与上题类似,最好的方法是用hash_map统计出现的次数,然后再借用堆找出出现次数最多的N个数据。不过,上一题统计搜索引擎最热门的查询已经采用过hash表统计单词出现的次数,特此,本题咱们改用红黑树取代之前的用hash表,来完成最初的统计,然后用堆更新,找出出现次数最多的前N个数据。
同时,正好个人此前用c && c++ 语言实现过红黑树,那么,代码能借用就借用吧。
完整代码:
- //copyright@ zhouzhenren &&July
- //July、updated,2011.05.08.
- //题目描述:
- //上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据
- //解决方案:
- //1、采用红黑树(本程序中有关红黑树的实现代码来源于@July)来进行统计次数。
- //2、然后遍历整棵树,同时采用最小堆更新前N个出现次数最多的数据。
- //声明:版权所有,引用必须注明出处。
- #define PARENT(i) (i)/2
- #define LEFT(i) 2*(i)
- #define RIGHT(i) 2*(i)+1
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- typedef enum rb_color{ RED, BLACK }RB_COLOR;
- typedef struct rb_node
- {
- int key;
- int data;
- RB_COLOR color;
- struct rb_node* left;
- struct rb_node* right;
- struct rb_node* parent;
- }RB_NODE;
- RB_NODE* RB_CreatNode(int key, int data)
- {
- RB_NODE* node = (RB_NODE*)malloc(sizeof(RB_NODE));
- if (NULL == node)
- {
- printf("malloc error!");
- exit(-1);
- }
- node->key = key;
- node->data = data;
- node->color = RED;
- node->left = NULL;
- node->right = NULL;
- node->parent = NULL;
- return node;
- }
- /**
- * 左旋
- *
- * node right
- * / / ==> / /
- * a right node y
- * / / / /
- * b y a b
- */
- RB_NODE* RB_RotateLeft(RB_NODE* node, RB_NODE* root)
- {
- RB_NODE* right = node->right; // 指定指针指向 right<--node->right
- if ((node->right = right->left))
- right->left->parent = node; // 好比上面的注释图,node成为b的父母
- right->left = node; // node成为right的左孩子
- if ((right->parent = node->parent))
- {
- if (node == node->parent->right)
- node->parent->right = right;
- else
- node->parent->left = right;
- }
- else
- root = right;
- node->parent = right; //right成为node的父母
- return root;
- }
- /**
- * 右旋
- *
- * node left
- * / / / /
- * left y ==> a node
- * / / / /
- * a b b y
- */
- RB_NODE* RB_RotateRight(RB_NODE* node, RB_NODE* root)
- {
- RB_NODE* left = node->left;
- if ((node->left = left->right))
- left->right->parent = node;
- left->right = node;
- if ((left->parent = node->parent))
- {
- if (node == node->parent->right)
- node->parent->right = left;
- else
- node->parent->left = left;
- }
- else
- root = left;
- node->parent = left;
- return root;
- }
- /**
- * 红黑树的3种插入情况
- * 用z表示当前结点, p[z]表示父母、p[p[z]]表示祖父, y表示叔叔.
- */
- RB_NODE* RB_Insert_Rebalance(RB_NODE* node, RB_NODE* root)
- {
- RB_NODE *parent, *gparent, *uncle, *tmp; //父母p[z]、祖父p[p[z]]、叔叔y、临时结点*tmp
- while ((parent = node->parent) && parent->color == RED)
- { // parent 为node的父母,且当父母的颜色为红时
- gparent = parent->parent; // gparent为祖父
- if (parent == gparent->left) // 当祖父的左孩子即为父母时,其实上述几行语句,无非就是理顺孩子、父母、祖父的关系。
- {
- uncle = gparent->right; // 定义叔叔的概念,叔叔y就是父母的右孩子。
- if (uncle && uncle->color == RED) // 情况1:z的叔叔y是红色的
- {
- uncle->color = BLACK; // 将叔叔结点y着为黑色
- parent->color = BLACK; // z的父母p[z]也着为黑色。解决z,p[z]都是红色的问题。
- gparent->color = RED;
- node = gparent; // 将祖父当做新增结点z,指针z上移俩层,且着为红色。
- // 上述情况1中,只考虑了z作为父母的右孩子的情况。
- }
- else // 情况2:z的叔叔y是黑色的,
- {
- if (parent->right == node) // 且z为右孩子
- {
- root = RB_RotateLeft(parent, root); // 左旋[结点z,与父母结点]
- tmp = parent;
- parent = node;
- node = tmp; // parent与node 互换角色
- }
- // 情况3:z的叔叔y是黑色的,此时z成为了左孩子。
- // 注意,1:情况3是由上述情况2变化而来的。
- // ......2:z的叔叔总是黑色的,否则就是情况1了。
- parent->color = BLACK; // z的父母p[z]着为黑色
- gparent->color = RED; // 原祖父结点着为红色
- root = RB_RotateRight(gparent, root); // 右旋[结点z,与祖父结点]
- }
- }
- else
- {
- // 这部分是特别为情况1中,z作为左孩子情况,而写的。
- uncle = gparent->left; // 祖父的左孩子作为叔叔结点。[原理还是与上部分一样的]
- if (uncle && uncle->color == RED) // 情况1:z的叔叔y是红色的
- {
- uncle->color = BLACK;
- parent->color = BLACK;
- gparent->color = RED;
- node = gparent; // 同上
- }
- else // 情况2:z的叔叔y是黑色的,
- {
- if (parent->left == node) // 且z为左孩子
- {
- root = RB_RotateRight(parent, root); // 以结点parent、root右旋
- tmp = parent;
- parent = node;
- node = tmp; // parent与node 互换角色
- }
- // 经过情况2的变化,成为了情况3.
- parent->color = BLACK;
- gparent->color = RED;
- root = RB_RotateLeft(gparent, root); // 以结点gparent和root左旋
- }
- }
- }
- root->color = BLACK; // 根结点,不论怎样,都得置为黑色。
- return root; // 返回根结点。
- }
- /**
- * 红黑树查找结点
- * rb_search_auxiliary:查找
- * rb_node_t* rb_search:返回找到的结点
- */
- RB_NODE* RB_SearchAuxiliary(int key, RB_NODE* root, RB_NODE** save)
- {
- RB_NODE* node = root;
- RB_NODE* parent = NULL;
- int ret;
- while (node)
- {
- parent = node;
- ret = node->key - key;
- if (0 < ret)
- node = node->left;
- else if (0 > ret)
- node = node->right;
- else
- return node;
- }
- if (save)
- *save = parent;
- return NULL;
- }
- /**
- * 返回上述rb_search_auxiliary查找结果
- */
- RB_NODE* RB_Search(int key, RB_NODE* root)
- {
- return RB_SearchAuxiliary(key, root, NULL);
- }
- /**
- * 红黑树的插入
- */
- RB_NODE* RB_Insert(int key, int data, RB_NODE* root)
- {
- RB_NODE* parent = NULL;
- RB_NODE* node = NULL;
- parent = NULL;
- if ((node = RB_SearchAuxiliary(key, root, &parent))) // 调用RB_SearchAuxiliary找到插入结点的地方
- {
- node->data++; // 节点已经存在data值加1
- return root;
- }
- node = RB_CreatNode(key, data); // 分配结点
- node->parent = parent;
- if (parent)
- {
- if (parent->key > key)
- parent->left = node;
- else
- parent->right = node;
- }
- else
- {
- root = node;
- }
- return RB_Insert_Rebalance(node, root); // 插入结点后,调用RB_Insert_Rebalance修复红黑树的性质
- }
- typedef struct rb_heap
- {
- int key;
- int data;
- }RB_HEAP;
- const int heapSize = 10;
- RB_HEAP heap[heapSize+1];
- /**
- * MAX_HEAPIFY函数对堆进行更新,使以i为根的子树成最大堆
- */
- void MIN_HEAPIFY(RB_HEAP* A, const int& size, int i)
- {
- int l = LEFT(i);
- int r = RIGHT(i);
- int smallest = i;
- if (l <= size && A[l].data < A[i].data)
- smallest = l;
- if (r <= size && A[r].data < A[smallest].data)
- smallest = r;
- if (smallest != i)
- {
- RB_HEAP tmp = A[i];
- A[i] = A[smallest];
- A[smallest] = tmp;
- MIN_HEAPIFY(A, size, smallest);
- }
- }
- /**
- * BUILD_MINHEAP函数对数组A中的数据建立最小堆
- */
- void BUILD_MINHEAP(RB_HEAP* A, const int& size)
- {
- for (int i = size/2; i >= 1; --i)
- MIN_HEAPIFY(A, size, i);
- }
- /*
- 3、维护k个元素的最小堆,原理与上述第2个方案一致,
- 即用容量为k的最小堆存储最先在红黑树中遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),
- 然后调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。
- 继续中序遍历红黑树,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(用时logk),否则不更新堆。
- 这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。
- 此方法得益于在堆中,查找等各项操作时间复杂度均为logk)。
- */
- //中序遍历RBTree
- void InOrderTraverse(RB_NODE* node)
- {
- if (node == NULL)
- {
- return;
- }
- else
- {
- InOrderTraverse(node->left);
- if (node->data > heap[1].data) // 当前节点data大于最小堆的最小元素时,更新堆数据
- {
- heap[1].data = node->data;
- heap[1].key = node->key;
- MIN_HEAPIFY(heap, heapSize, 1);
- }
- InOrderTraverse(node->right);
- }
- }
- void RB_Destroy(RB_NODE* node)
- {
- if (NULL == node)
- {
- return;
- }
- else
- {
- RB_Destroy(node->left);
- RB_Destroy(node->right);
- free(node);
- node = NULL;
- }
- }
- int main()
- {
- RB_NODE* root = NULL;
- RB_NODE* node = NULL;
- // 初始化最小堆
- for (int i = 1; i <= 10; ++i)
- {
- heap[i].key = i;
- heap[i].data = -i;
- }
- BUILD_MINHEAP(heap, heapSize);
- FILE* fp = fopen("data.txt", "r");
- int num;
- while (!feof(fp))
- {
- fscanf(fp, "%d", &num);
- root = RB_Insert(num, 1, root);
- }
- fclose(fp);
- InOrderTraverse(root); //递归遍历红黑树
- RB_Destroy(root);
- for (i = 1; i <= 10; ++i)
- {
- printf("%d/t%d/n", heap[i].key, heap[i].data);
- }
- return 0;
- }
程序测试:咱们来对下面这个小文件进行测试:
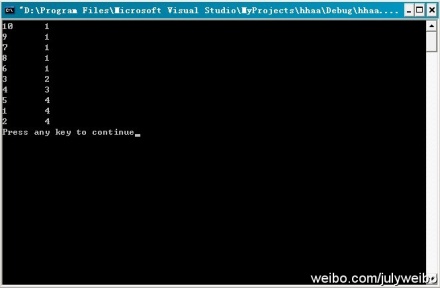
运行结果:如下图所示,
问题补遗:
ok,由于在遍历红黑树采用的是递归方式比较耗内存,下面给出一个非递归遍历的程序(下述代码若要运行,需贴到上述程序之后,因为其它的代码未变,只是在遍历红黑树的时候,采取非递归遍历而已,同时,主函数的编写也要稍微修改下):
- //copyright@ zhouzhenren
- //July、updated,2011.05.08.
- #define STACK_SIZE 1000
- typedef struct
- { // 栈的结点定义
- RB_NODE** top;
- RB_NODE** base;
- }*PStack, Stack;
- bool InitStack(PStack& st) // 初始化栈
- {
- st->base = (RB_NODE**)malloc(sizeof(RB_NODE*) * STACK_SIZE);
- if (!st->base)
- {
- printf("InitStack error!");
- exit(1);
- }
- st->top = st->base;
- return true;
- }
- bool Push(PStack& st, RB_NODE*& e) // 入栈
- {
- if (st->top - st->base >= STACK_SIZE)
- return false;
- *st->top = e;
- st->top++;
- return true;
- }
- bool Pop(PStack& st, RB_NODE*& e) // 出栈
- {
- if (st->top == st->base)
- {
- e = NULL;
- return false;
- }
- e = *--st->top;
- return true;
- }
- bool StackEmpty(PStack& st) // 栈是否为空
- {
- if (st->base == st->top)
- return true;
- else
- return false;
- }
- bool InOrderTraverse_Stack(RB_NODE*& T) // 中序遍历
- {
- PStack S = (PStack)malloc(sizeof(Stack));
- RB_NODE* P = T;
- InitStack(S);
- while (P != NULL || !StackEmpty(S))
- {
- if (P != NULL)
- {
- Push(S, P);
- P = P->left;
- }
- else
- {
- Pop(S, P);
- if (P->data > heap[1].data) // 当前节点data大于最小堆的最小元素时,更新堆数据
- {
- heap[1].data = P->data;
- heap[1].key = P->key;
- MIN_HEAPIFY(heap, heapSize, 1);
- }
- P = P->right;
- }
- }
- free(S->base);
- S->base = NULL;
- free(S);
- S = NULL;
- return true;
- }
- bool PostOrderTraverse_Stack(RB_NODE*& T) //后序遍历
- {
- PStack S = (PStack)malloc(sizeof(Stack));
- RB_NODE* P = T;
- RB_NODE* Pre = NULL;
- InitStack(S);
- while (P != NULL || !StackEmpty(S))
- {
- if (P != NULL) // 非空直接入栈
- {
- Push(S, P);
- P = P->left;
- }
- else
- {
- Pop(S, P); // 弹出栈顶元素赋值给P
- if (P->right == NULL || P->right == Pre) // P的右子树空或是右子树是刚访问过的
- { // 节点,则释放当前节点内存
- free(P);
- Pre = P;
- P = NULL;
- }
- else // 反之,当前节点重新入栈,接着判断右子树
- {
- Push(S, P);
- P = P->right;
- }
- }
- }
- free(S->base);
- S->base = NULL;
- free(S);
- S = NULL;
- return true;
- }
- //主函数稍微修改如下:
- int main()
- {
- RB_NODE* root = NULL;
- RB_NODE* node = NULL;
- // 初始化最小堆
- for (int i = 1; i <= 10; ++i)
- {
- heap[i].key = i;
- heap[i].data = -i;
- }
- BUILD_MINHEAP(heap, heapSize);
- FILE* fp = fopen("data.txt", "r");
- int num;
- while (!feof(fp))
- {
- fscanf(fp, "%d", &num);
- root = RB_Insert(num, 1, root);
- }
- fclose(fp);
- //若上面的程序后面加上了上述的非递归遍历红黑树的代码,那么以下几行代码,就得修改如下:
- //InOrderTraverse(root); //此句去掉(递归遍历树)
- InOrderTraverse_Stack(root); // 非递归遍历树
- //RB_Destroy(root); //此句去掉(通过递归释放内存)
- PostOrderTraverse_Stack(root); // 非递归释放内存
- for (i = 1; i <= 10; ++i)
- {
- printf("%d/t%d/n", heap[i].key, heap[i].data);
- }
- return 0;
- }
updated:
后来,我们狂想曲创作组中的3又用hash+堆实现了上题,很明显比采用上面的红黑树,整个实现简洁了不少,其完整源码如下:
完整源码:
- //Author: zhouzhenren
- //Description: 上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据
- //Algorithm: 采用hash_map来进行统计次数+堆(找出Top K)。
- //July,2011.05.12。纪念汶川地震三周年,默哀三秒。
- #define PARENT(i) (i)/2
- #define LEFT(i) 2*(i)
- #define RIGHT(i) 2*(i)+1
- #define HASHTABLESIZE 2807303
- #define HEAPSIZE 10
- #define A 0.6180339887
- #define M 16384 //m=2^14
- #include <stdio.h>
- #include <stdlib.h>
- typedef struct hash_node
- {
- int data;
- int count;
- struct hash_node* next;
- }HASH_NODE;
- HASH_NODE* hash_table[HASHTABLESIZE];
- HASH_NODE* creat_node(int& data)
- {
- HASH_NODE* node = (HASH_NODE*)malloc(sizeof(HASH_NODE));
- if (NULL == node)
- {
- printf("malloc node failed!/n");
- exit(EXIT_FAILURE);
- }
- node->data = data;
- node->count = 1;
- node->next = NULL;
- return node;
- }
- /**
- * hash函数采用乘法散列法
- * h(k)=int(m*(A*k mod 1))
- */
- int hash_function(int& key)
- {
- double result = A * key;
- return (int)(M * (result - (int)result));
- }
- void insert(int& data)
- {
- int index = hash_function(data);
- HASH_NODE* pnode = hash_table[index];
- while (NULL != pnode)
- { // 以存在data,则count++
- if (pnode->data == data)
- {
- pnode->count += 1;
- return;
- }
- pnode = pnode->next;
- }
- // 建立一个新的节点,在表头插入
- pnode = creat_node(data);
- pnode->next = hash_table[index];
- hash_table[index] = pnode;
- }
- /**
- * destroy_node释放创建节点产生的所有内存
- */
- void destroy_node()
- {
- HASH_NODE* p = NULL;
- HASH_NODE* tmp = NULL;
- for (int i = 0; i < HASHTABLESIZE; ++i)
- {
- p = hash_table[i];
- while (NULL != p)
- {
- tmp = p;
- p = p->next;
- free(tmp);
- tmp = NULL;
- }
- }
- }
- typedef struct min_heap
- {
- int count;
- int data;
- }MIN_HEAP;
- MIN_HEAP heap[HEAPSIZE + 1];
- /**
- * min_heapify函数对堆进行更新,使以i为跟的子树成最大堆
- */
- void min_heapify(MIN_HEAP* H, const int& size, int i)
- {
- int l = LEFT(i);
- int r = RIGHT(i);
- int smallest = i;
- if (l <= size && H[l].count < H[i].count)
- smallest = l;
- if (r <= size && H[r].count < H[smallest].count)
- smallest = r;
- if (smallest != i)
- {
- MIN_HEAP tmp = H[i];
- H[i] = H[smallest];
- H[smallest] = tmp;
- min_heapify(H, size, smallest);
- }
- }
- /**
- * build_min_heap函数对数组A中的数据建立最小堆
- */
- void build_min_heap(MIN_HEAP* H, const int& size)
- {
- for (int i = size/2; i >= 1; --i)
- min_heapify(H, size, i);
- }
- /**
- * traverse_hashtale函数遍历整个hashtable,更新最小堆
- */
- void traverse_hashtale()
- {
- HASH_NODE* p = NULL;
- for (int i = 0; i < HASHTABLESIZE; ++i)
- {
- p = hash_table[i];
- while (NULL != p)
- { // 如果当前节点的数量大于最小堆的最小值,则更新堆
- if (p->count > heap[1].count)
- {
- heap[1].count = p->count;
- heap[1].data = p->data;
- min_heapify(heap, HEAPSIZE, 1);
- }
- p = p->next;
- }
- }
- }
- int main()
- {
- // 初始化最小堆
- for (int i = 1; i <= 10; ++i)
- {
- heap[i].count = -i;
- heap[i].data = i;
- }
- build_min_heap(heap, HEAPSIZE);
- FILE* fp = fopen("data.txt", "r");
- int num;
- while (!feof(fp))
- {
- fscanf(fp, "%d", &num);
- insert(num);
- }
- fclose(fp);
- traverse_hashtale();
- for (i = 1; i <= 10; ++i)
- {
- printf("%d/t%d/n", heap[i].data, heap[i].count);
- }
- return 0;
- }















 2933
2933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









