







20230220更新:维特比算法直接看:https://zhuanlan.zhihu.com/p/28274845
这篇笔记可能是这么多篇笔记里最难写的了,网上找了很多相关的博客,看了一圈,越看越懵,每个人都在从不同的角度讲CRF,要不是一堆公式,要不是一上来就是解码问题、计算问题,也许当你对CRF有了一定的了解再回头去看那些高赞的文章会觉得特别棒,但对一个刚接触这个知识点的同学来说,友好入门才是最关键的。
于是无意找到了李宏毅老师讲解HMM和CRF视频,看了一下,讲的很好,于是下面的内容基于李宏毅老师的教学展开。(李老师总是能把一个别人讲的很晦涩的知识点讲的很通透,的确是一个宝藏老师)
从序列标注开始说起
首先我们引出一个思考,对于Sequence Labeling而言,我们要做的事情是输入一个X然后输出个Y,只不过有一个基本的设定是说输入与输出的长度是一样的。这样的问题我们应该如何实现呢?
我们可以很容易的想到用RNN这样的模型来做,但是还有没有其他的办法呢?我们带着这样的问题继续向下深入。
我们以具体的词性标注任务来延展上面的问题,假设我们现在要标记一个句子中每一个词的词性,我们可以怎么做,有人提出来我们可以写一个hash table,利用查表的方式来进行输出,但是这样会有一个明显的问题,那就是遇到多义词怎么办?(如下面的例子)所以说我们在做词性标注的时候必须考虑到词语的上下文信息。

再POS tagging问题中,还会出现一些隐性的问题,比如我们在看第一个"saw"的时候他更可能是一个动词,而第二个"saw"则更加可能是一个名词,因为它的前面是一个限定词。所以考虑到基本的语法规则,不同词在不同的上下文中充当不同词性角色的可能性是不一样的,这个“可能性”我们用机器能听得懂的语言描述就是概率。这也就是我们接下来要引出概率(概率图模型)的一个重要原因。
HMM
在介绍HMM模型的开始,我们先来思考这样一个问题:如何生成一个句子?
我们可以分两步走:
- 按照语法规则生成一个POS的序列
- 根据生成的POS序列,翻开词典,把每一个POS的槽位填充上对应词性的词
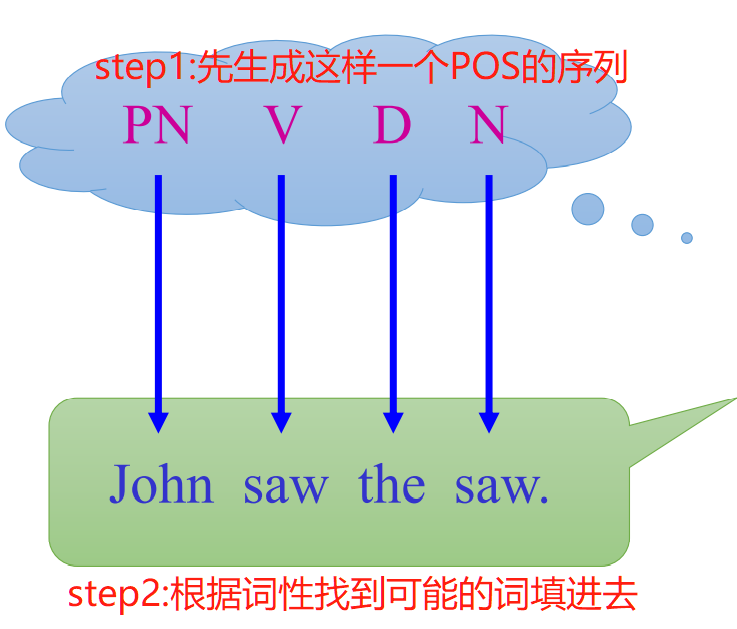
那么我们如何凭空就能得到John saw the saw这样一句话呢?按照上面的步骤我们来看,凭空生成这样一句话的可能性是多大。首先我们得有一个语法关系的图,类似下面这样,我们得知道凭空开始选出第一个词性PN的概率多大,然后继续探究走到第一步(选中了PN)之后走第二步(选V)、走第三步(选D)、第四步(选N)、第五步(结束句子,选end)的概率是多大。
这中间涉及到一个很重要的东西:马尔科夫链。具体的过程大家可以自行百度,通俗说来就是,一个序列s1,s2,s3……,某一时刻的状态s(t)只与其前一时刻的状态s(t-1)有关,与其他时刻的状态无关。这也是我们下面进行计算的基础,也是这套方法为啥叫隐马尔可夫模型的原因。
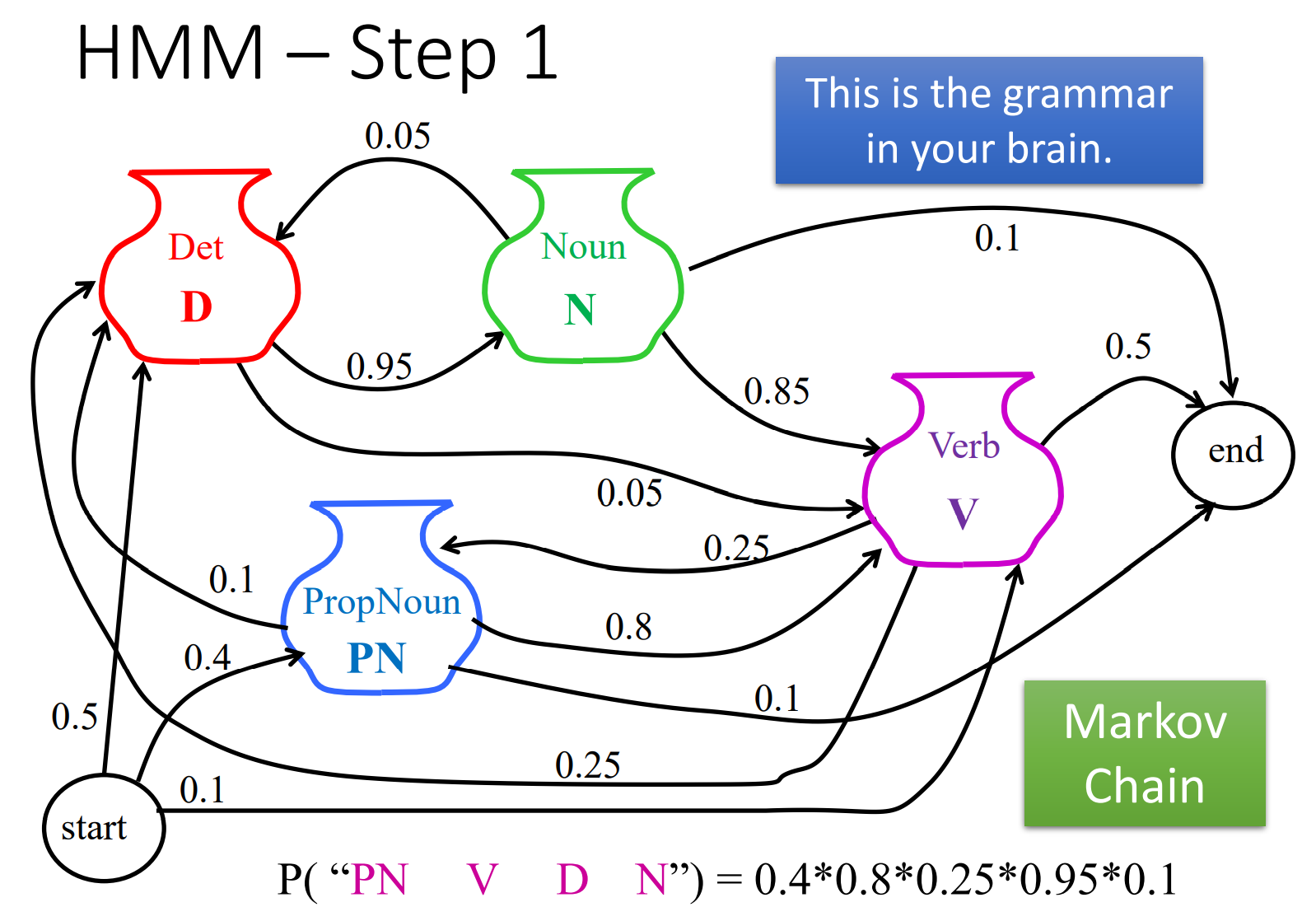
通过上面图中跳转的关系,以及每两个节点之间跳转的概率值(有向有权的边)我们可以知道:
P("PN V D N") = 0.4 x 0.8 x 0.25 x 0.95 x 0.1
再看第二步:
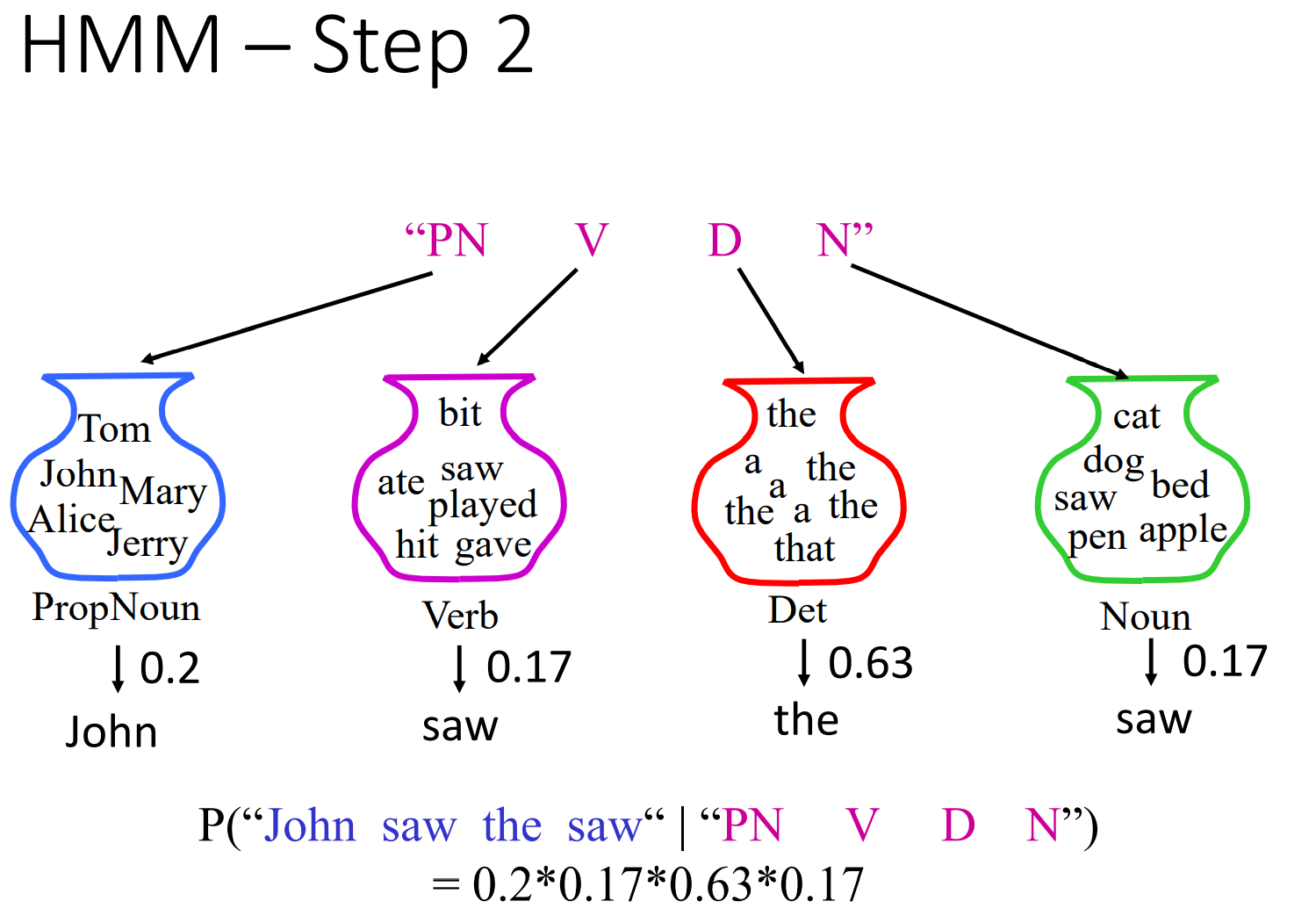
我们依然可以得到图中的一个条件概率。这样我们就能得到一个x和y同时满足的概率,也就是联合概率:
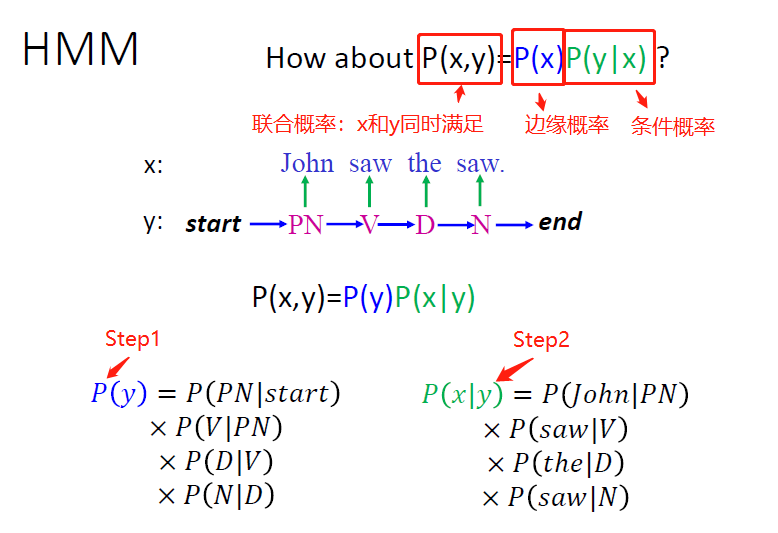
我们将上面的过程归纳成更加一般化的形式可以得到下面两个公式:

偷偷插一句:这个上帝掷骰子的过程很像LDA选主题选单词凑句子的过程啊。
所以现在上面的问题就转换为了怎么求上面两个概率(转移概率、发射概率。。。这个名字要适应)的事了,怎么求呢,我们用到统计的方法来解决,也就是跑到训练数据里去数频次:

这个方法是不是很熟悉,我们的n-gram语言模型是不是就是这么套路搞的。
到此我们暂停一下,做一个小思考:上面的目标是要求凭空生成John saw the saw这句话的可能性。那跟我们的词性标注POS-tagging有啥关系呢?试想一下,上面的求解过程中,每一个单词的词性我们是知道的,这样我们才能做Step2中根据已知词性选词的操作。但是POS-tagging要做的是我不知道这个词的词性是啥,我要标注出来这个词性,那么我们应该怎么做?
直觉告诉我们要反着推。感觉就像先告诉你1+1=2,再问你2是由1加几得到的一样,但这个直觉对不对呢?我们来一起试一下。
现在POS-tagging的任务变成了已知
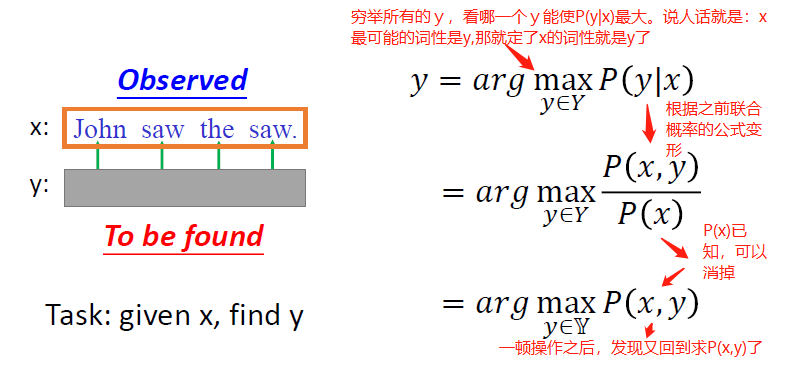
理一下思路,明确一下目标,目标就是求能使P(x,y)最大的y,怎么求啊?直觉告诉我们穷举所有的(word,tag)组合就可以,假设序列长度为L,即有L个word,假设一共有|S|种tag可供选择,那么穷举完的计算复杂度是多少?是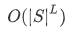 ,有没有更加优化的算法来降低复杂度呢?有,那就是Viterbi算法,通过动态规划思想,时间复杂度可以降到
,有没有更加优化的算法来降低复杂度呢?有,那就是Viterbi算法,通过动态规划思想,时间复杂度可以降到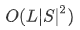 ,具体Viterbi算法的细节,为了避免思路打断,我们这里暂不讨论,只需要知道他是一种计算P(x,y)的优化算法就够了。至此,我们其实已经能够知道我们要求的词性序列y了,一句话那就是求P(x,y)。
,具体Viterbi算法的细节,为了避免思路打断,我们这里暂不讨论,只需要知道他是一种计算P(x,y)的优化算法就够了。至此,我们其实已经能够知道我们要求的词性序列y了,一句话那就是求P(x,y)。
到这里我们已经看过很多了,前面铺垫了很多,这个时候我们需要再次回顾一下整个过程:

有没有稍微有点豁然开朗的感觉,有的话我们继续。没有的话可以再多看几遍。
但是在上述过程中会有一个问题,那就是HMM会自行“脑补”它没见过的数据,这样我们可能会得到我们不想要的结果,比如它会给训练数据里从来没有出现过的数据很高的概率:
假设现在有9条 N → V → c 的数据,9条 P → V → a 的数据以及1条 N → D → a 的数据。现在计算上一个词性为N, 下一个输出词为a的概率。
P(a|V)P(V|N) = 1/2 x 9/10 = 9/20
P(a|D)P(D|N) = 1 x 1/10 = 1/10
尽管数据中已经有 N → D → a ,但HMM会认为从没出现的N → V → a概率更大。
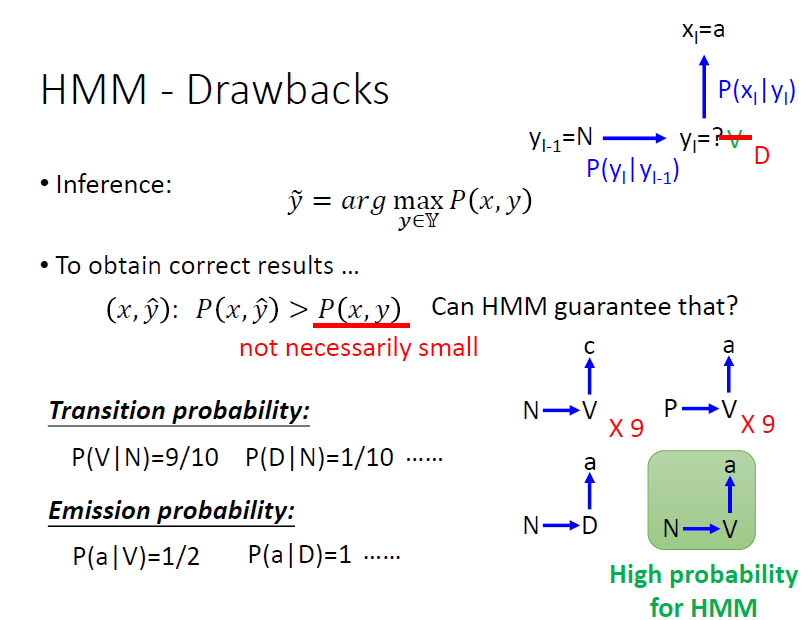
李老师提出:这个HMM的特点真的就是缺点吗?不尽然,当训练数据较少的时候,HMM的这种能力反而会让他表现得更好。那它为什么会有这样的特点呢?是因为它的转移概率和发射概率是分开model的,是独立性的。那有没有办法能解决HMM的这个问题呢?我们来看CRF是怎么做的。
CRF
CRF一开始是想用另外一种方式来描述P(x , y),如下:

但是这样一看,CRF就跟HMM真的很不一样了吗?并不是,它俩其实是和谐统一的。来看看:

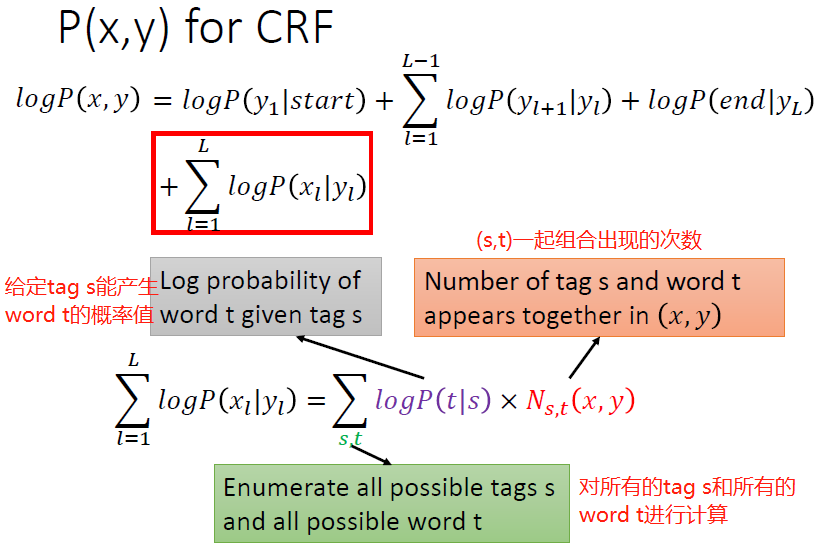
我们来看一个具体的例子:
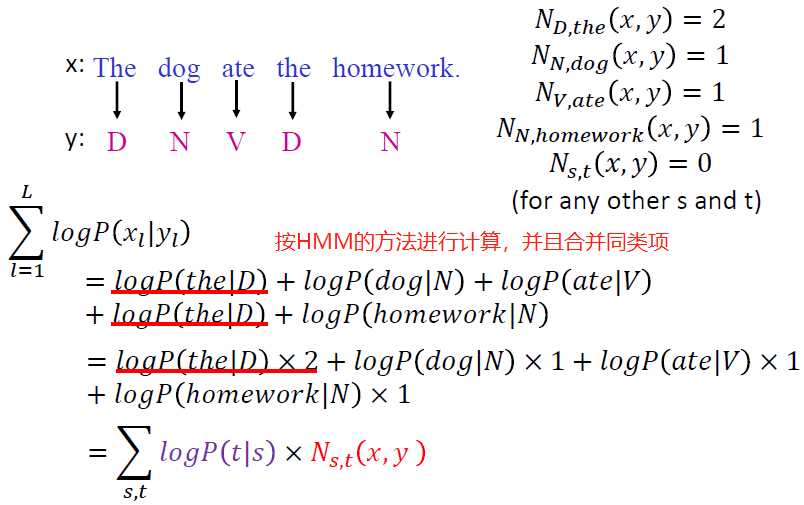
更加抽象一点可以看到:


然后你再看,HMM和CRF就这么统一起来了:

上图说明了CRF与HMM的一个联系:W矩阵的每一个元素做指数运算后都能得到HMM中的相应的概率值。
接下来我们看CRF具体计算:


维度上需要注意由于存在Start\End,故需要加上2|S|的维度。

我们再来看我们如何训练数据,我们的目标函数是什么:

然后我们利用梯度上升来最大化目标函数:
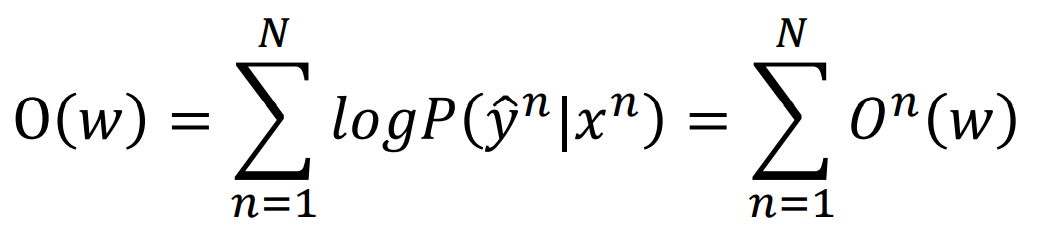
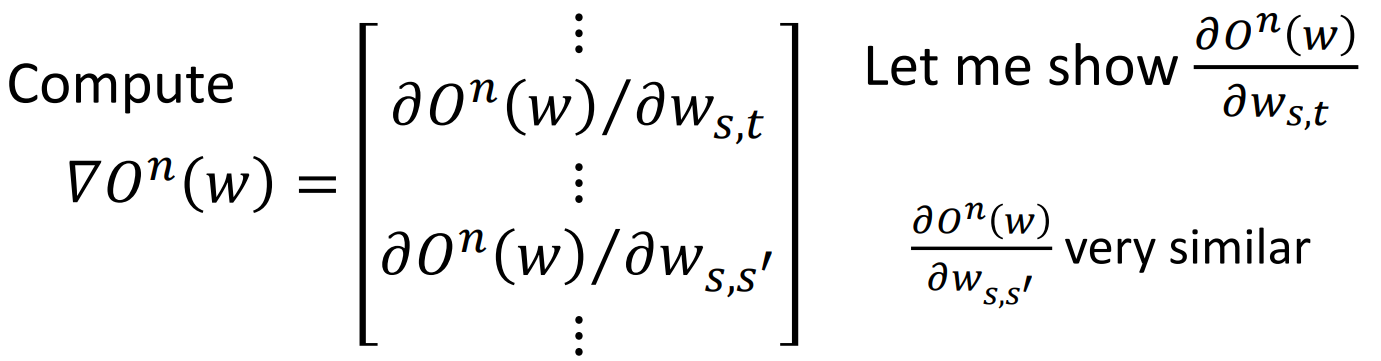
公式看不懂也没关系,咱就知道最后成下面这样了,然后后面那项依然可以用Viterbi算法来计算:

然后下面有两句话可以用人话来翻译一下:意思是在正确答案中出现的次数比较多,就增大w;在其他的(x,y)中出现也多的话就要抑制它,让w减小。
一张图总结一下上面的过程就是:

HMM与CRF对比
先来看一个重要的区别就是:HMM没有抑制没见过的那些情况的概率,会脑补。而CRF不会。

再来看另外一个区别,若有以下的情况:

我们看a取不同值的时候HMM和CRF的表现:
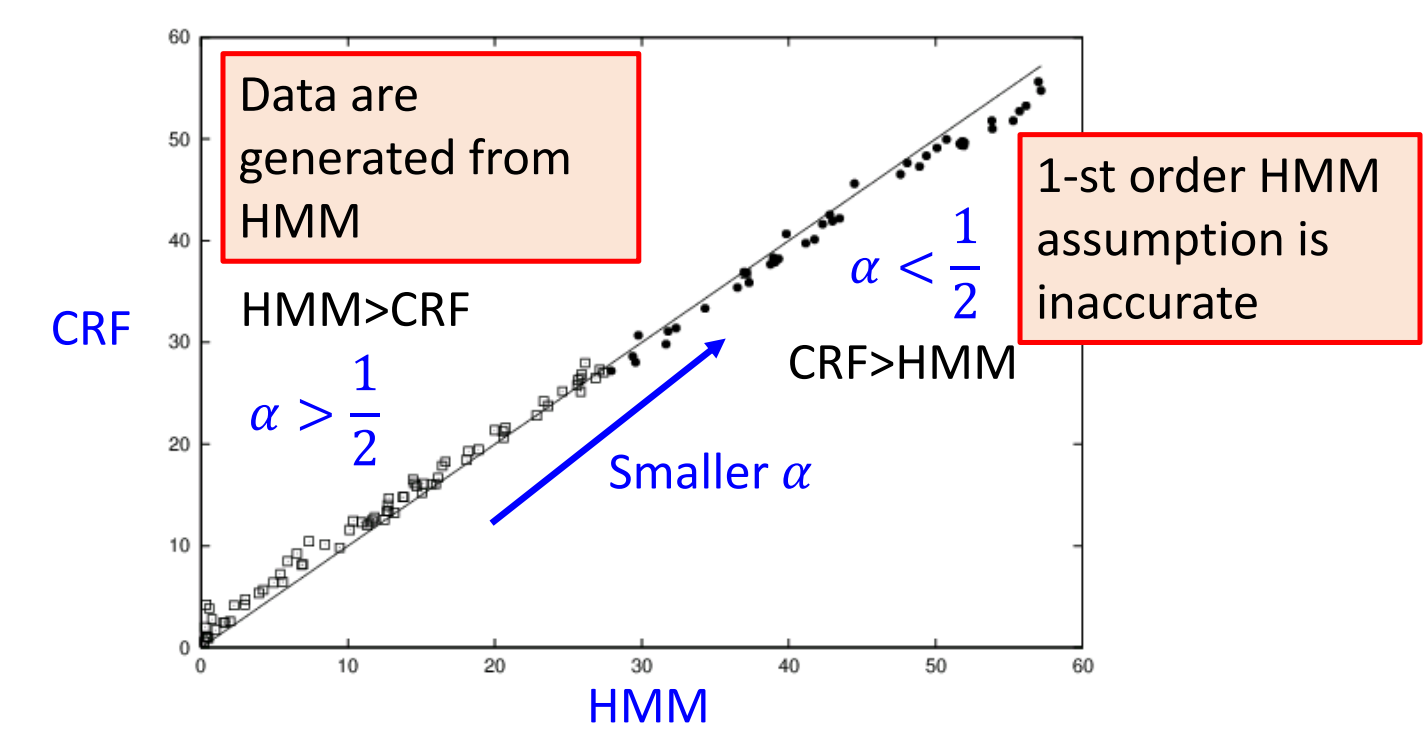
也就是说,a>1/2时,HMM表现要好于CRF,这是当数据更加符合HMM/CRF 的假设时;a<1/2时,CRF的表现要好于HMM,这也就是当数据不太符合HMM/CRF的假设的时候。
这也就是李宏毅老师讲的大致内容的,可以时常翻出来看一下,再结合其他文章食用,胃口更佳。
今天先到这,在20210408的Z37次火车上,列车员开始拉窗帘,我也要睡觉了,明天要面对人生中新的艰难时刻,要加油。不要忘记学习,不要忘记微笑,要爱周围的人,爱家人,加油,一切都会好起来的!
参考文章:














 3283
3283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









