







Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
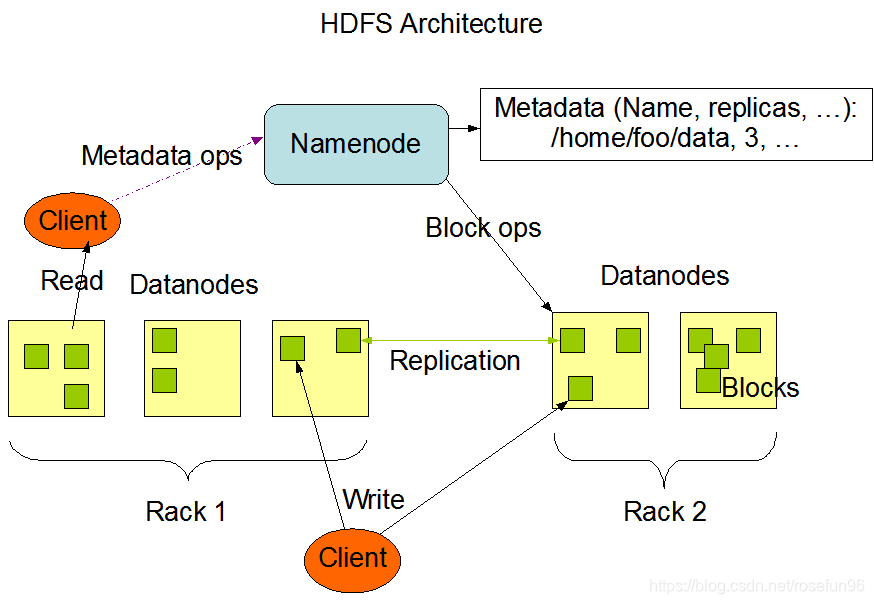
文件系统的名字空间 (namespace)
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。当前,HDFS不支持用户磁盘配额和访问权限控制,也不支持硬链接和软链接。但是HDFS架构并不妨碍实现这些特性。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来。应用程序可以设置HDFS保存的文件的副本数目。文件副本的数目称为文件的副本系数,这个信息也是由Namenode保存的。
健壮性
HDFS的主要目标就是即使在出错的情况下也要保证数据存储的可靠性。常见的三种出错情况是:Namenode出错, Datanode出错和网络割裂(network partitions)。
磁盘数据错误,心跳检测和重新复制:
每个Datanode节点周期性地向Namenode发送心跳信号。网络割裂可能导致一部分Datanode跟Namenode失去联系。Namenode通过心跳信号的缺失来检测这一情况,并将这些近期不再发送心跳信号Datanode标记为宕机,不会再将新的IO请求发给它们。任何存储在宕机Datanode上的数据将不再有效。Datanode的宕机可能会引起一些数据块的副本系数低于指定值,Namenode不断地检测这些需要复制的数据块,一旦发现就启动复制操作。在下列情况下,可能需要重新复制:某个Datanode节点失效,某个副本遭到损坏,Datanode上的硬盘错误,或者文件的副本系数增大。
集群均衡
数据完整性:
具体就是检测到DataNode的数据不完整时,从其他的数据节点进行复制。
参考:















 7052
7052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











