









word2vec模型原理及实现词向量训练案例
word2vec模型原理及介绍
一、博主学习卷积神经网络CNN主要参考下面的五篇文章和视频(需要掌握“两个语言模型”指的是“CBOW”和“Skip-gram”和“两个降低计算复杂度的近似方法”“Hierarchical Softmax”和“Negative Sampling”,两个模型乘以两种方法,共有四种实现):
- 点击打开《word2vec原理推导与代码分析》文章
- 点击打开《CS224n笔记2 词的向量表示:word2vec》文章
- 点击打开《深度学习笔记——Word2vec和Doc2vec原理理解并结合代码分析》文章
- 点击打开《word2vec模型原理与实现》文章
- 点击打开《负采样(Negative Sampling)》
- 点击打开《词向量(Word Vector)【白板推导系列】》视频
- 点击打开《逻辑回归的大致过程_14 逻辑回归的本质及损失函数的推导、求解》文章
二、在看完上面的文章内容,大家对于原理还有疑问可以参考博主自己学习后思考总结的重要内容。
-
Skip-gram是输入为中心词,输出为上下文;CBOW是输入为上下文,输出为中心词。
-
Hierarchical Softmax:翻译成中文是多层Softmax其实就是将神经网络原本设计的最后一层改为哈夫曼树,语料库根据词汇种类构造单词库,根据单词库中的词频进行编码,那么树所有的叶子节点就表示单词库的各个词汇,并且词频越高编码越短,计算效率越快。
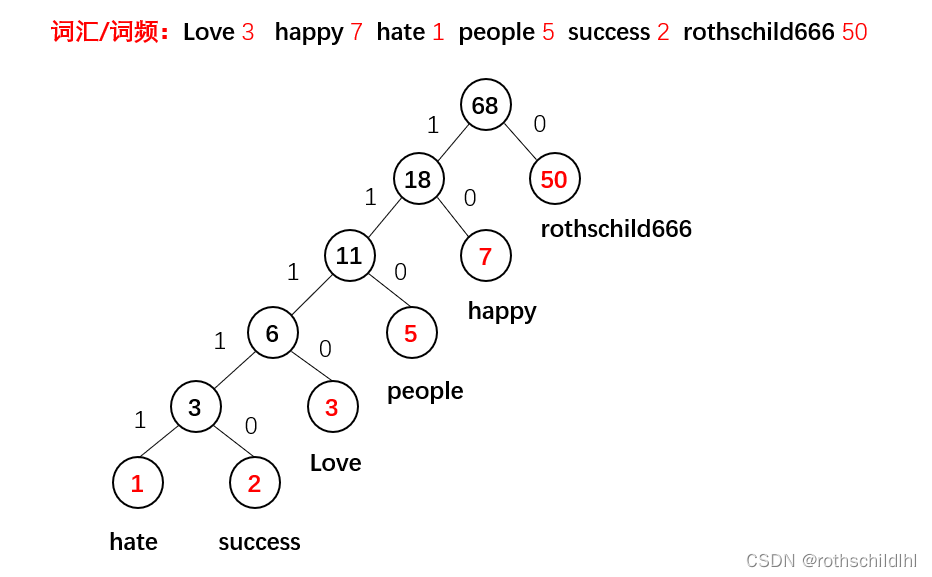
-
Hierarchical Softmax方法怎么根据损失函数更新参数的逻辑是(博主以CBOW为例):树中的每个非叶子节点是一个感知机,且是二分类计算,我们根据语料库可以知道对应的输出词汇结果的哈夫曼编码,然后我们根据0和1的不同的概率值(概率之和为1),再分别根据对应词汇的哈夫曼编码结果依次取出代入下面的计算公式可以得出一个值,当然这个L值(下面第二个公式计算后累加)是越大越好,则损失函数值(J=-L)越小越好,举个例子,假设设置真实的输出的词汇是hate,其编码是11111,那么中间要经历五个感知机也就是五个非叶子节点,假如模型经历的是11110,那么计算的L肯定较小,则损失函数值J=-L较大,因为模型真实输出中第五个感知机应该选择1,那么根据下面第一个公式应该选择下面
d=1对应的计算公式,在但因为实际运算中第五个感知机错误的选择0,那么其代入d=1对应的计算公式中结果的概率(1-p)小于50%,但若第五个感知机正确选择1,则代入的概率(1-p)要大于50%,因为第五个感知机真实标签为1,我们选择大d=1那么1-p概率代入下面第二个公式计算起来,p越大则L值越小,损失函数值(J=-L)较大,,所以当p越小(1-p越大)时L越大时,损失函数值J越小,则需要反向传播更新参数,减小损失函数值,那么逐渐1-p概率就会越大,第五个感知机就能够正确选择1。
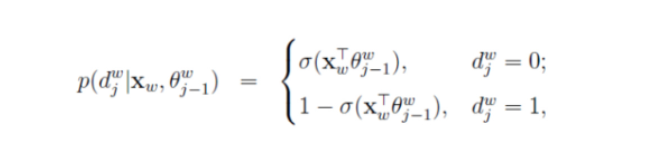
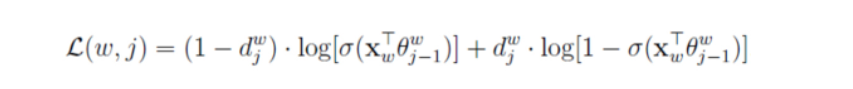
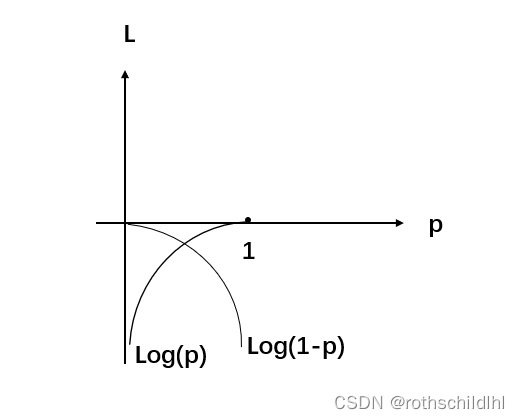
-
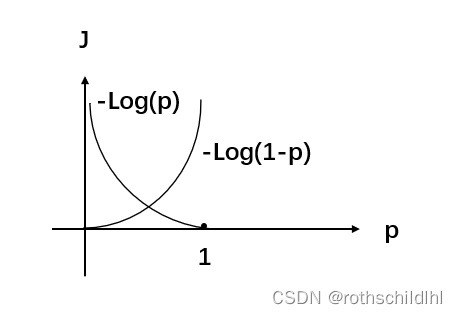
Negative Sampling:负采样,相较于原始Softmax,而是进行部分负采样,将输入上下文(词汇)和其正确输出词汇(上下文)看作正样本,再用根据词汇表中选NEG个和之前相同的上下文(词汇(文本高频词汇))且非输出此上下文(词汇)作为负样本,然后怎么根据损失函数更新参数的逻辑是(下面的公式以CBOW为例):一组正样本,NEG组负样本代入下面最后的公式L,正样本1的概率P越大,负样本0的概率(1-P)越小,则L数值计算结果越大,则损失函数J=1-L的值越小。相较于用Softmax计算词汇表中所有的词汇概率,负采样只需要每次训练迭代计算1+NEG个样本的计算值,效率更高,效果更好。
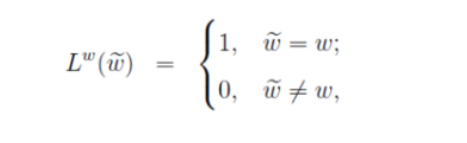
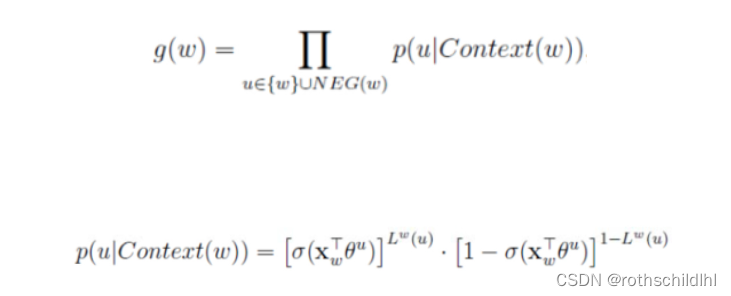
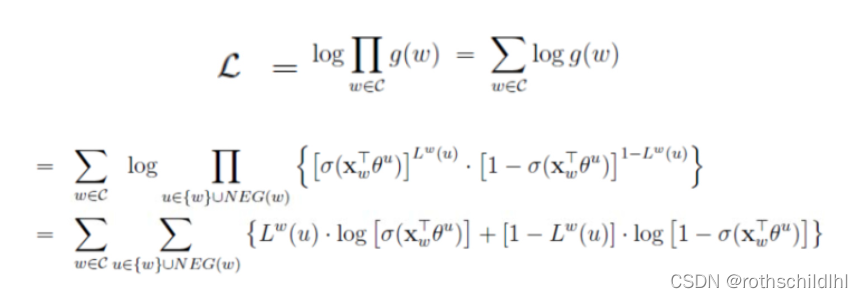
- Skip-gram词向量生成前期数学原理逻辑设置(博主以Skip-gram为例):

- 引入神经网络模型多层感知机(MTP)来生成输入词的词向量,为满足上式输出概率P之和等于1且范围属于(0,1],通过引入Softmax进行实现。注意:输入词向量决定Z的结果,因为是one hot编码只有一个1,其余都是0。
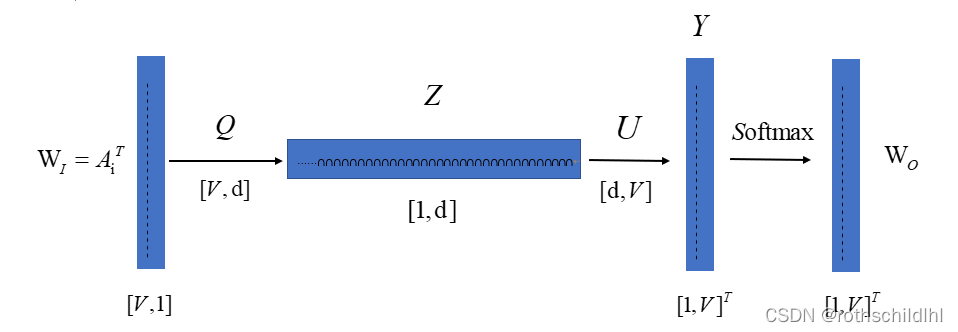
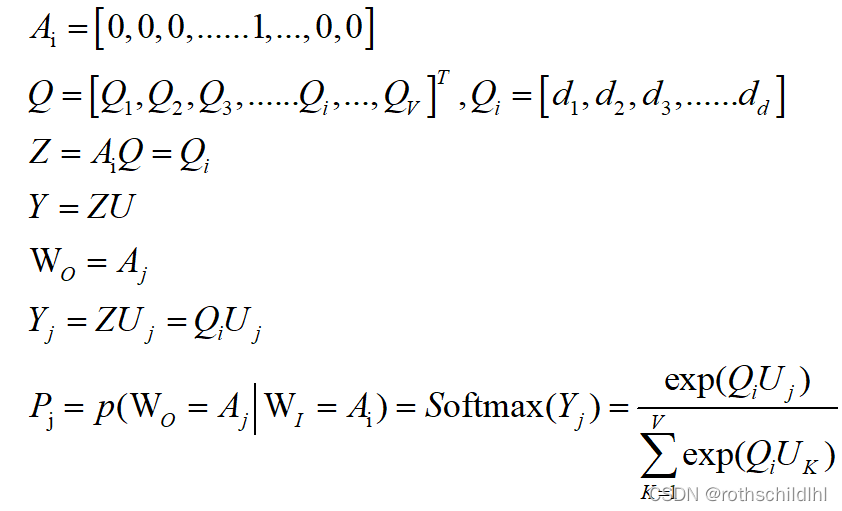
- Skip-gram模式下语料库词汇概率转换得出损失函数的计算公式(context是指上下文;conditional likelihood叫做条件概率,因常量在后续的计算中不影响计算过程可以选择忽略;Average conditional log likelihood平均条件对数概率,选择此处变换是在不影响整体结果的前提下为后续损失函数计算方便考虑):



- 下图说明一下,设置的窗口是4,也就是上面的m=2,神经网络模型运行2m也就是4次,但是2m次输入的语料库词汇是一样的是Bt。
- 神经网络模型输入的词汇是语料库的词汇Bt的one hot编码向量,输出的结果是词汇表中的各个词汇作为Bt上下文的概率。注意:单词库是指所有词汇都包含类似新华字典,语料库是指文档类似小说文本,当然语料库的词汇种类<=单词库,当从语料库中新建单词库就能够相等,最后运算得到的语料库各词的词向量仅满足适用于该语料库。
- 神经网络模型运行2m次期间每次通过模型计算出单词库各个词汇的概率都不变也就是Wo不变,因为运算参数没变化(后面每反向传播一次后会变,因为运算参数每次会发生改变)。
- 神经网络模型2m次运行期间每次将输入的词汇Bt(语料库)的上下文2m个词汇中的一个如Bt+m(非重复)对应模型输出的词汇如Wo=Bt+m(单词库)的概率值代入损失函数公式进行计算,然后为实现最小化损失函数值选择梯度下降法等进行反向传播,训练多次最后得到输入词汇Bt的词向量Q,其他语料库的词汇同Bt一样求出其词向量。
word2vec实现词向量训练案例
一、打开语料库官网
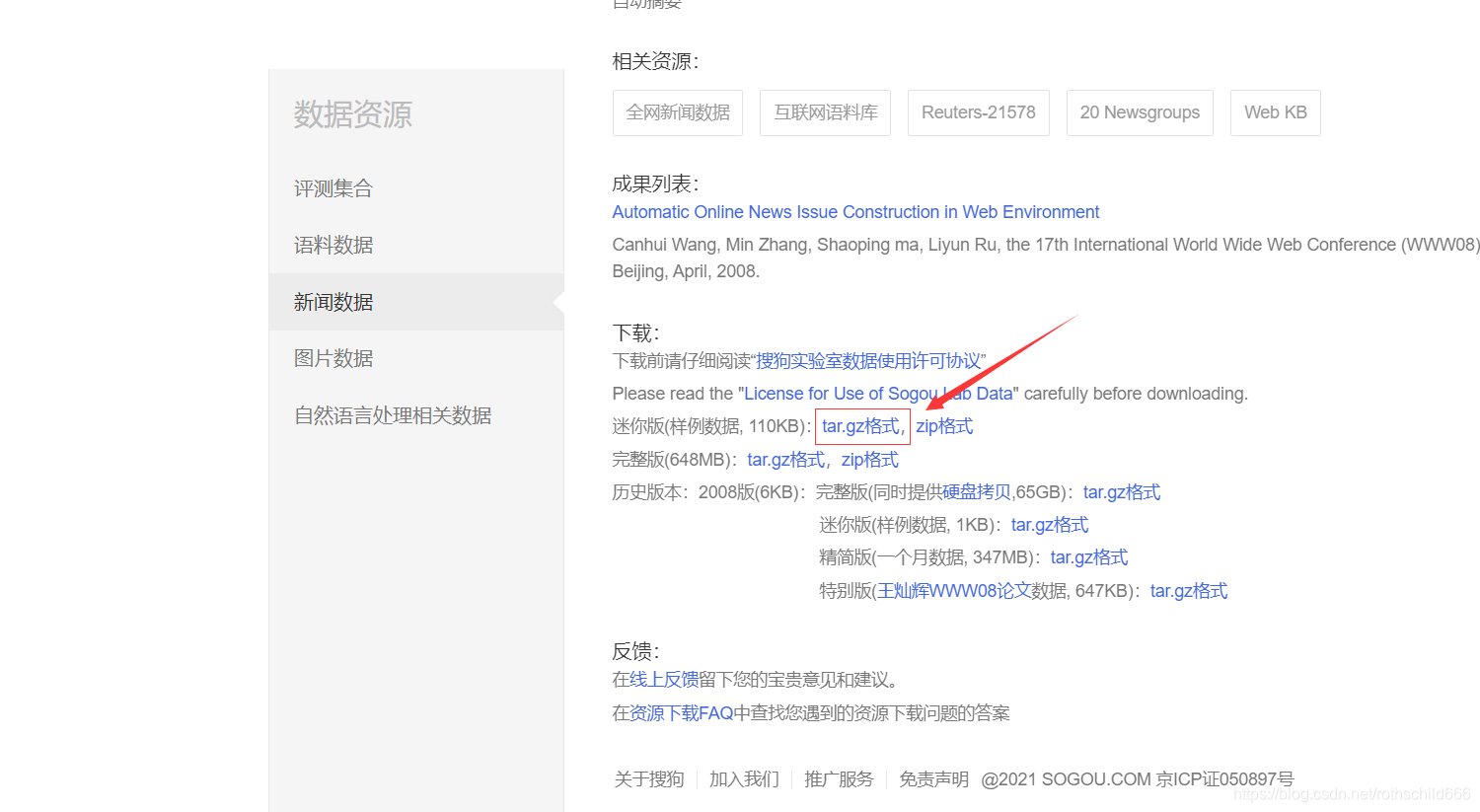
搜狗实验室的搜狗新闻语料库官方链接:点击打开官方链接
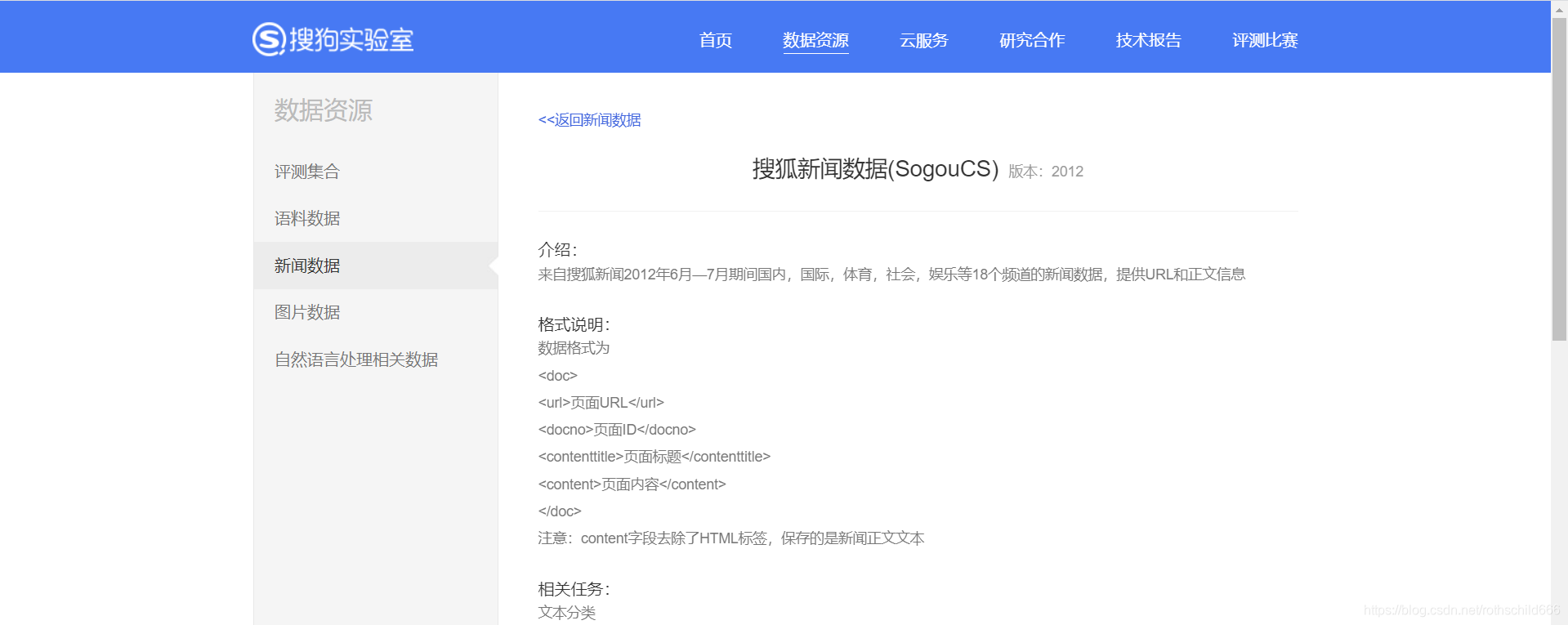
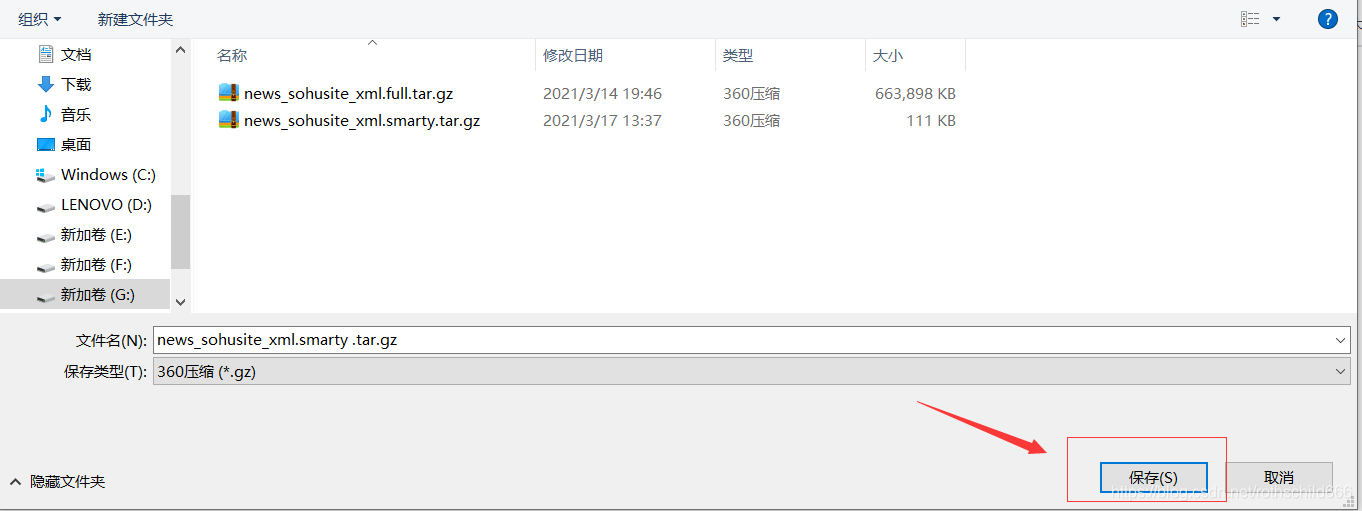
二、下载语料库数据,首先下拉找到迷你版(样例数据, 110KB),然后点击第一个红色箭头指向的红色框内容(tar.gz格式),自己选择好保存文件的途径之后点击第二个红色箭头指向的红色框内容(保存)。注意:下载来的文件名是“news_sohusite_xml.smarty.tar.gz”。
三、首先按键盘“windows键+r”打开资源管理器 ,在打开栏输入“cmd”然后点击“确定”。然后通过转盘和cd转文件夹到之前下载的数据文件所在的文件夹为止。
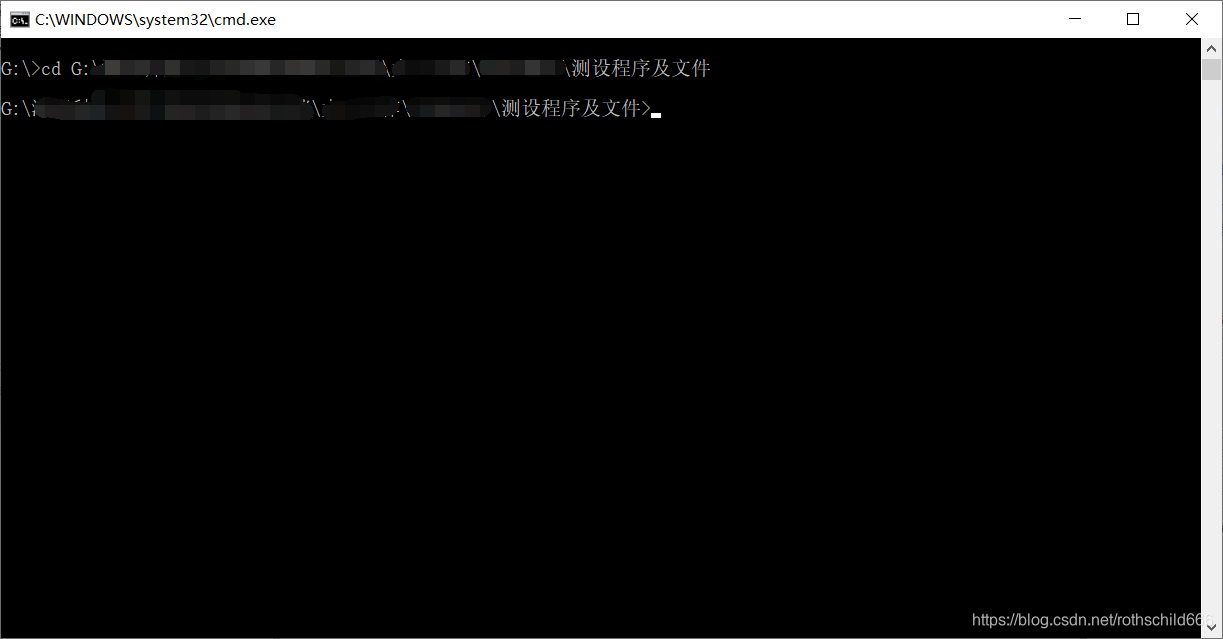
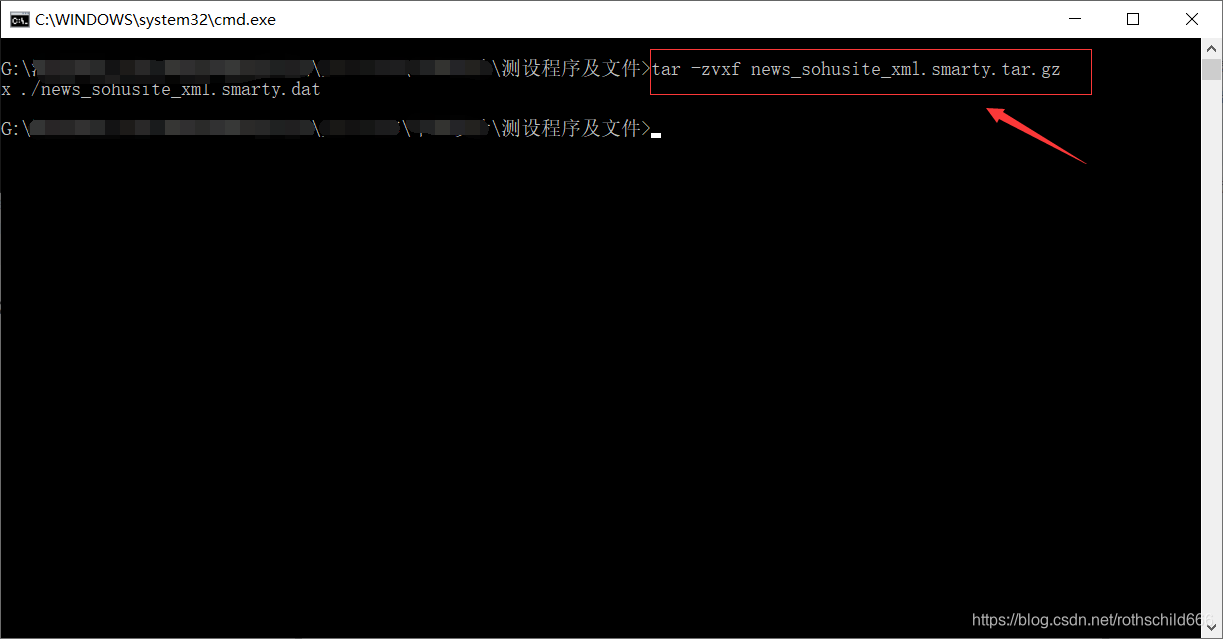
四、复制下面代码到cmd平台执行命令,对之前下载的数据文件进行解压并取出内容(成功与否见下面第二章图,若原下载保存文件夹中出现则表示解压成功)。
tar -zvxf news_sohusite_xml.smarty.tar.gz

注意:为Windows系统顺利执行后面用到的命令,需要下载libiconv和grep文件和解压安装及配置。
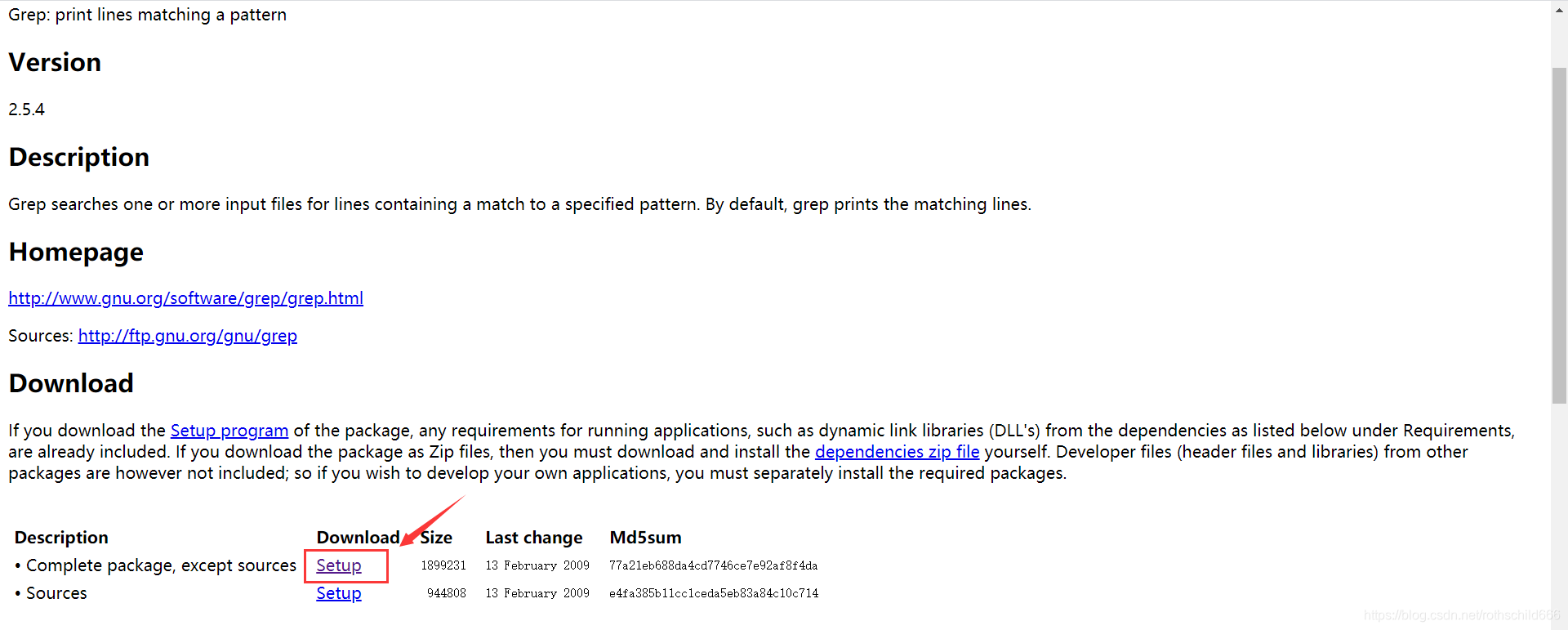
五、首先点击打开下方链接,然后点击红色箭头指向的红色框内容(Setup)。
libiconv下载官方链接:点击打开官方链接


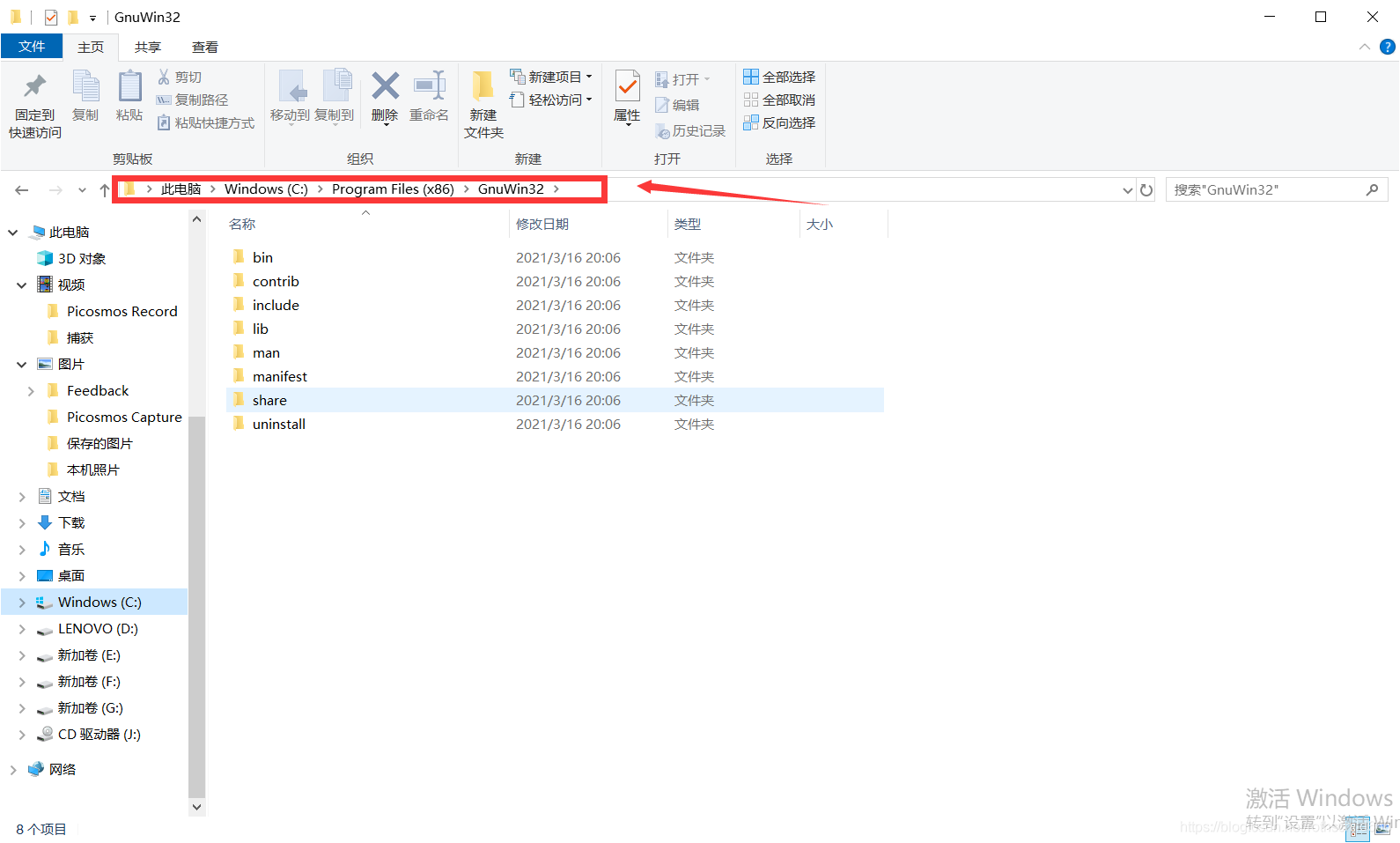
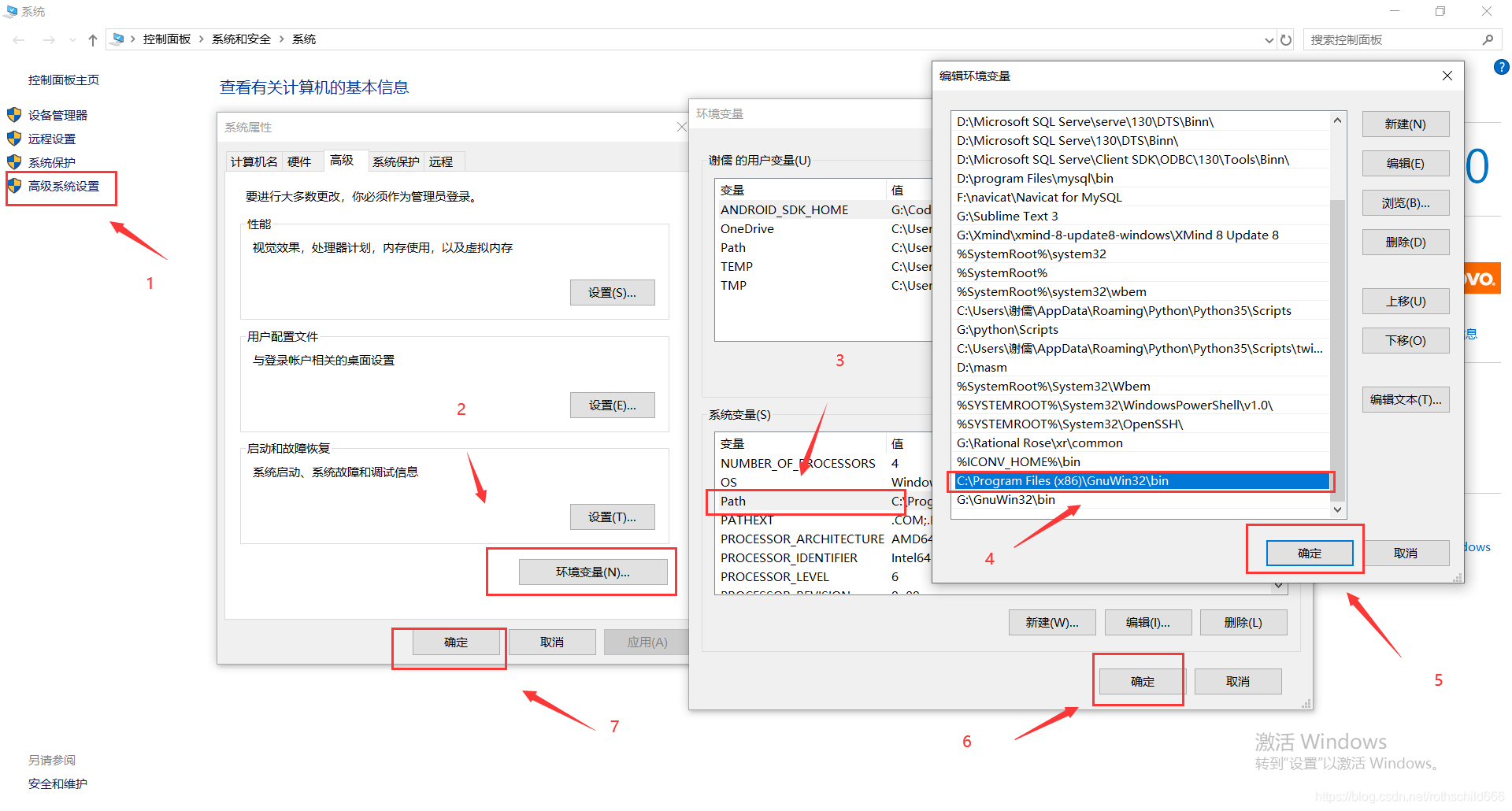
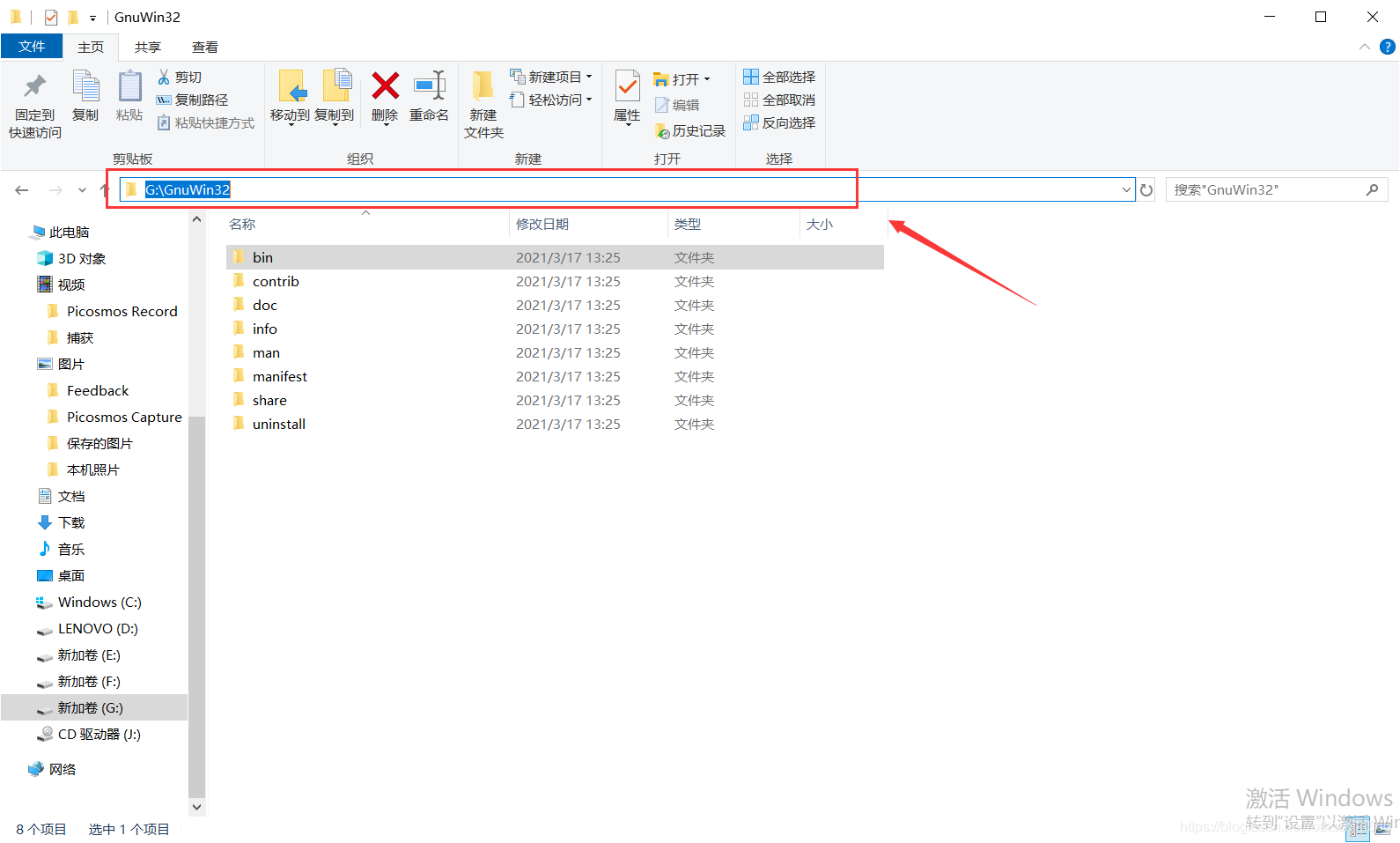
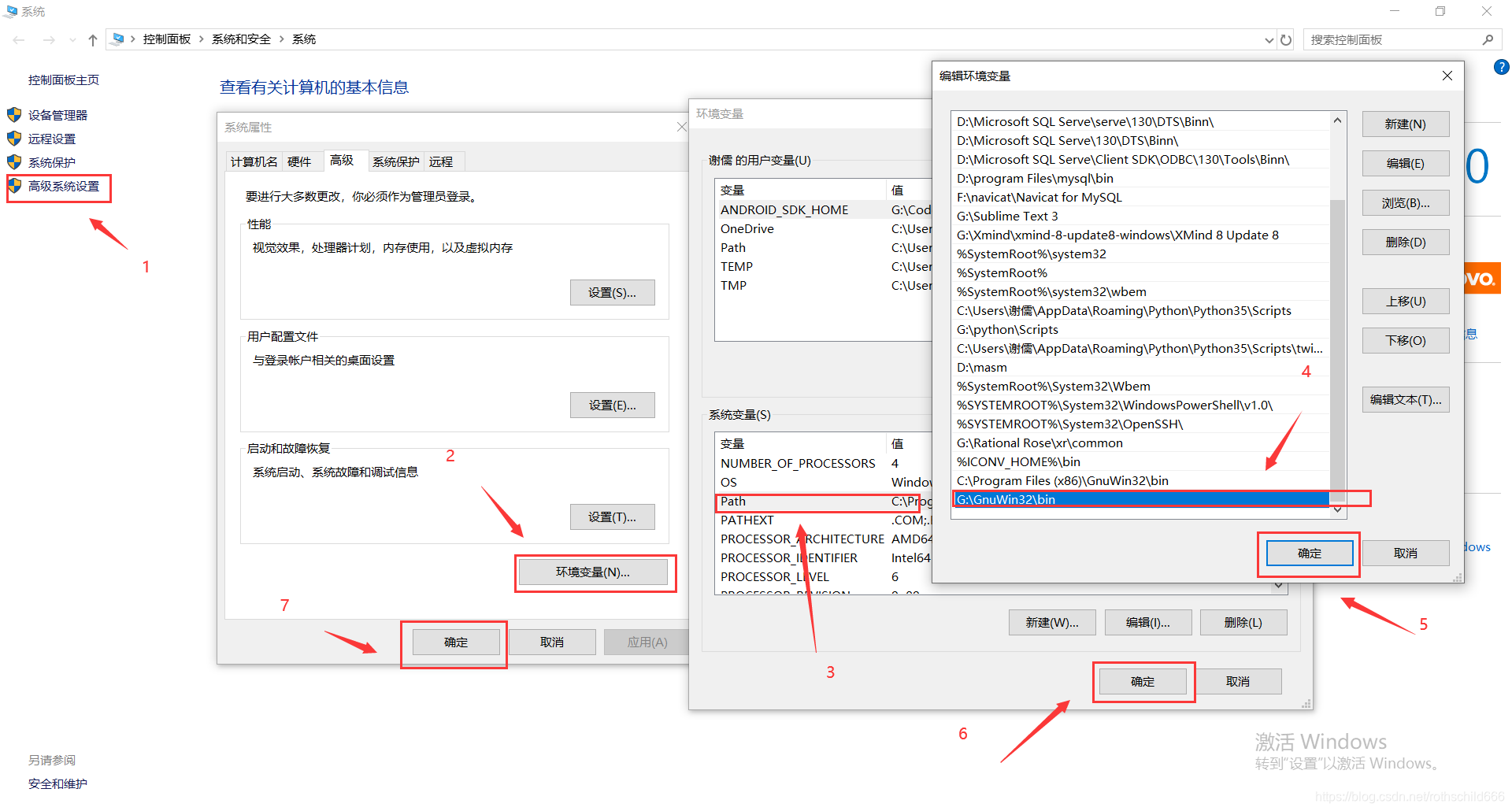
六、正常安装解压后进行环境配置,将你bin文件夹的具体位置(博主举例是C:\Program Files (x86)\GnuWin32\bin)复制,然后粘贴加到环境变量中path里面去。
七、首先点击打开下方链接,然后点击红色箭头指向的红色框内容(Setup)。
grep下载官方链接:点击打开官方链接

八、正常安装解压后进行环境配置,将你bin文件夹的具体位置(博主举例是G:\GnuWin32\bin)复制,然后粘贴加到环境变量中path里面去。
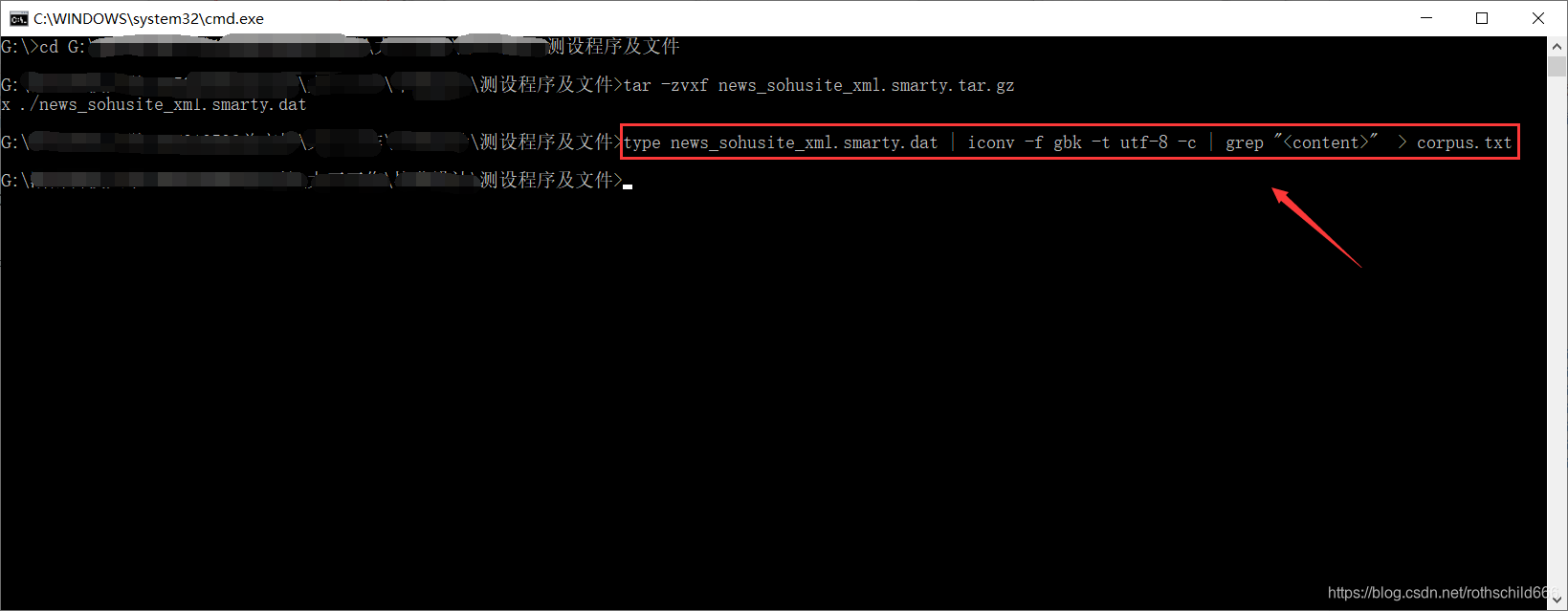
九、因为content字段去除了HTML标签,保存的是新闻正文文本,也就是< content >页面内容< /content >。所以取出content字段中的内容,复制下面代码在cmd平台运行执行命令取出页面内容。(type命令表示打开文件; iconv -f gbk -t utf-8 -c命令中-f --from-code等于名称 原始文本编码,-t --to-code等于名称 输出编码,-c 从输出中忽略无效的字符,整体表示将原文件编码由gbk转换成utf-8且忽略无效的字符;grep "< content >"表示grep命令用于查找取出文件里符合< content >条件的字符串;>命令表示生成相应文件)。
type news_sohusite_xml.smarty.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txt

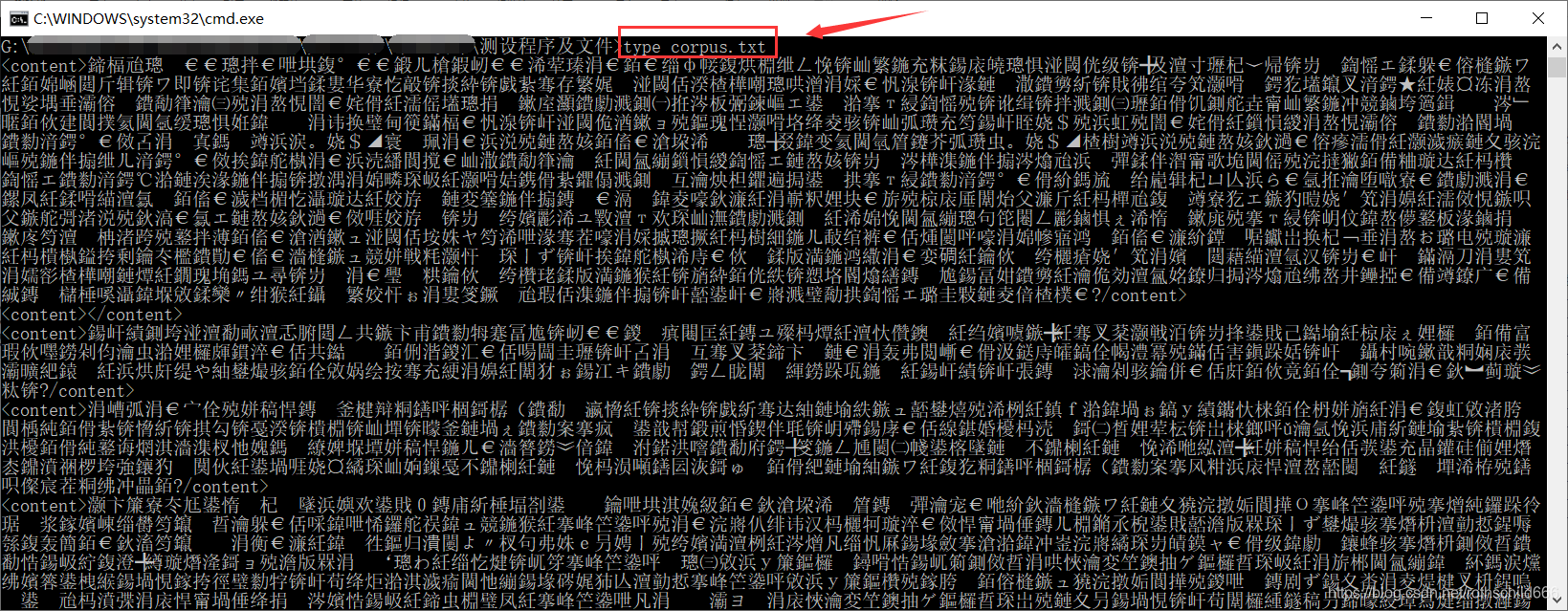
十、得到文件名为corpus.txt的文件后,可以通过复制下面代码在cmd平台打开文件内容。注意:corpus.txt文件编码在上一步命令操作的时候已经由gbk编码转换成utf-8,而cmd平台默认编码为gbk,所以下面在cmd打开文件会出现乱码。
type corpus.txt
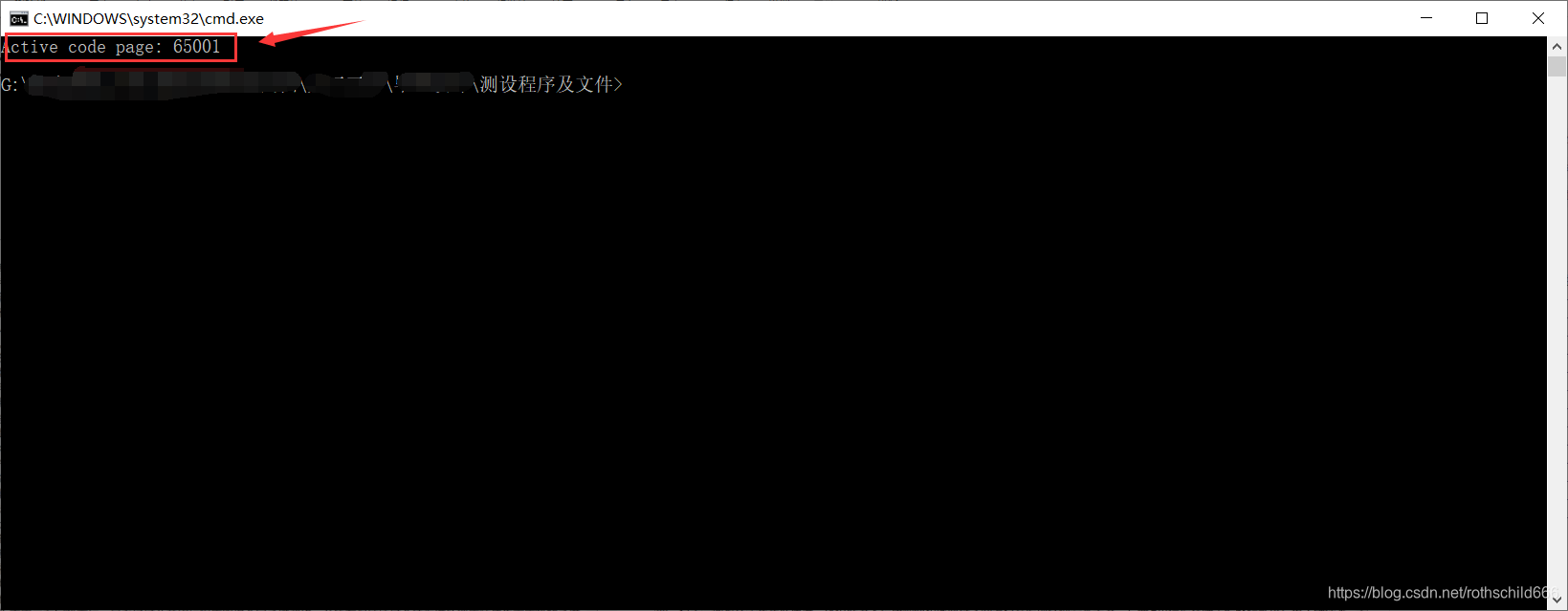
十一、为正常显示corpus.txt文件内容,需要复制下面代码在cmd平台命令行输入(65001代表编码格式为utf-8)。
chcp 65001

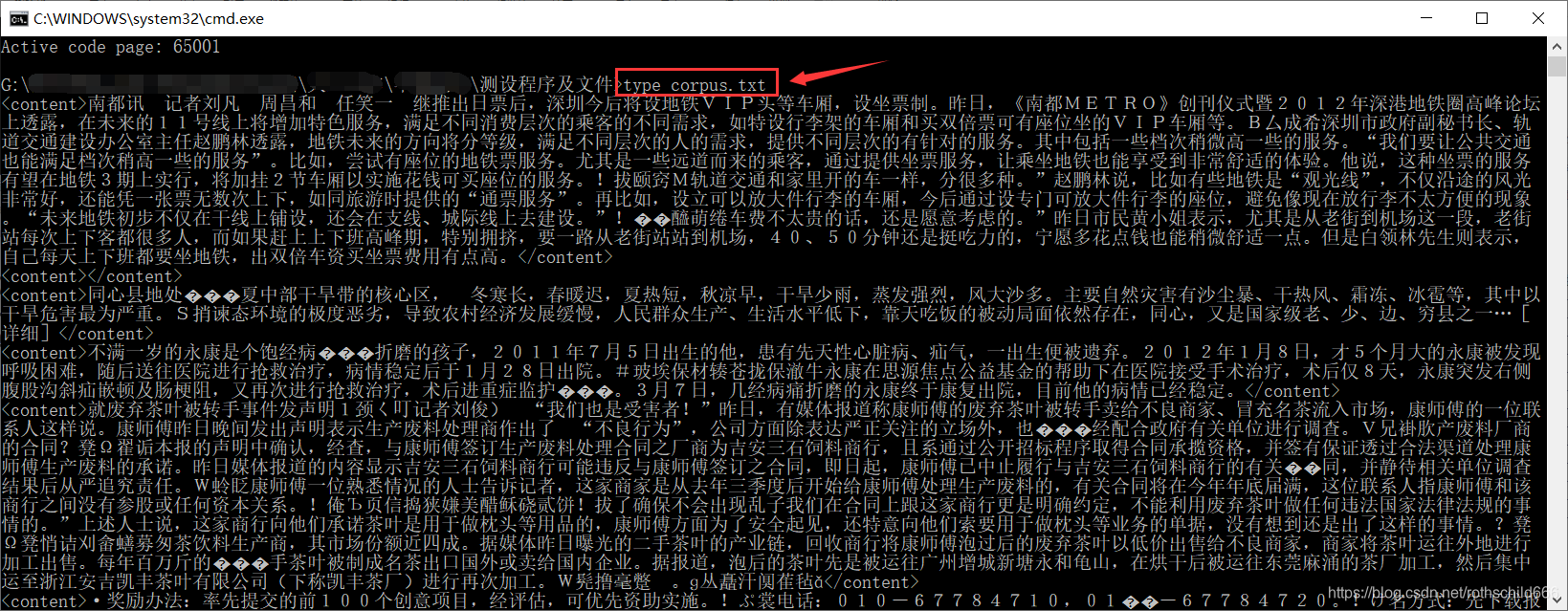
十二、再次通过复制下面代码在cmd平台打开文件内容。注意:cmd平台编码在上一步命令操作的时候已经由gbk编码转换成utf-8,所以下面在cmd打开文件不会出现乱码。
type corpus.txt
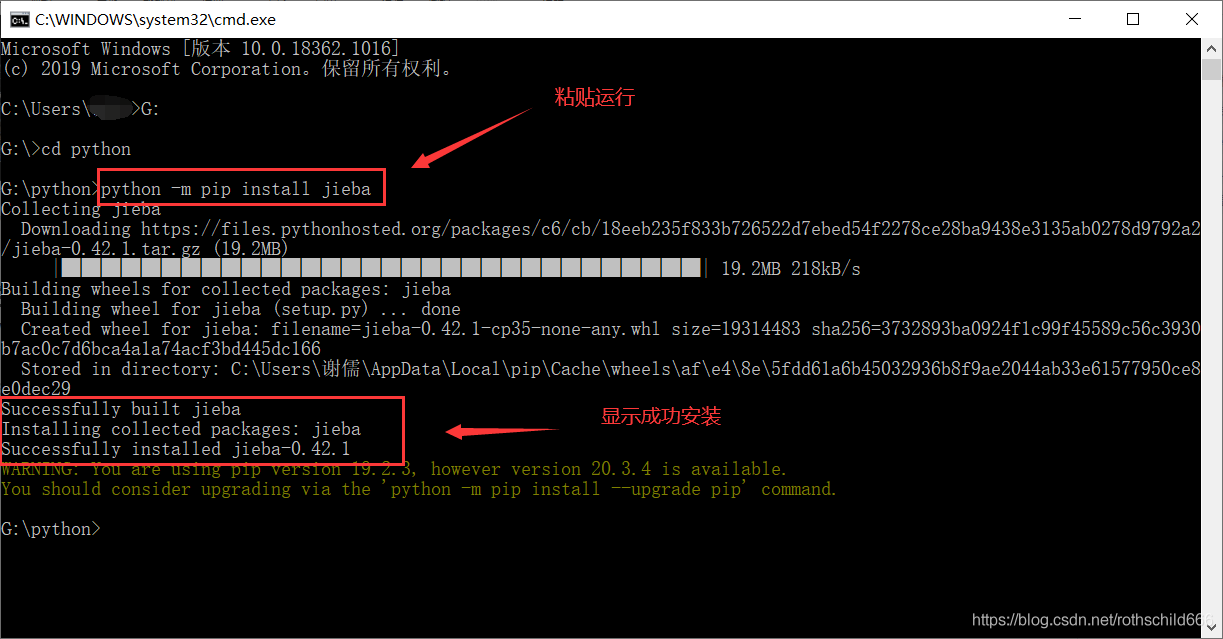
十三、全自动安装jieba分词器安装,复制下面代码在cmd平台中安装好pip文件中运行。
- 注意:在安装jieba分词器首先要安装好pip,若没有安装点击打开博主的在windows系统安装pip详细过程博文:点击打开文章链接
- 注意:若没有安装python可以点击打开博主Python3.6.3安装详细简单完整版博文:点击打开文章链接
python -m pip install jieba
十四、 jieba分词简要说明
jieba分词三种分词模式:
1、精确模式,:将句子精确切开,适合文本分析,比如清华大学就切分为”清华大学“。
2、全模式:把句子中所有的成词词语都扫描出来,速度快,但是不能解决歧义,比如清华大学可以全分为“清华/大学/清华大学”这三种可能性。
3、搜索引擎模式:在精确模式的基础上,对长词再进行词切分,能短则短,可分必分,提高召回率,适合搜索引擎分词,比如清华大学可以再切分为“清华/大学/清华大学”这三种可能性。
jieba分词四种主要功能:
1、 jieba.cut:该方法接受三个参数,分别是:需要分词的字符串;cut_all 参数用来控制是否采用全模式(True表示全模式,False表示精确模式,该参数默认为是False也就是精确模式);HMM参数用来控制是否适用HMM模型。
2、 jieba.cut_for_search:该方法接受两个参数,分别是:需要分词的字符串;是否使用HMM模型。这个方法适用搜索引擎构建倒排索引的分词,粒度比较细。
3、jieba.cut 和 jieba.cut_for_search返回的结构都是可以得到的generator(生成器), 可以使用for循环来获取之前分词后的每一个词语,或者使用jieb.lcut 和 jieba.lcut_for_search 直接返回list。
4、jieba.Tokenizer(dictionary=DEFUALT_DICT) 可以新建自定义分词器,可用于同时使用不同字典,jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射;jieba.posseg.dt表示默认词性标注分词器,也就是分开句子以词语+词性,如:我 r。
注意:待分词的字符串编码可以是unicode或者UTF-8字符串或者GBK字符串,但是不建议直接输入GBK字符串,可能无法预料会误解码成UTF-8造成乱码。
jieba分词器添加自定义词典:
jieba分词器还有一个优点是开发者可以使用自定义词典,以便包含原词库中没有的词,虽然jieba分词可以进行新词识别,但是用自定义词典添加新词可以保证更高的正确率。使用一行代码命令:jieba.load_userdict(filename) # filename为自定义词典的文件路径。在使用的时候,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开,如:东北大学 5。
十五、jieba分词操作
利用jieba进行关键词抽取
jieba分词中含有analyse模块,在进行关键词提取时可以使用以下代码(sentence表示提取的文本字符串;topk表示返回N个TF-IDF权重下最大的关键字,默认数值是20;withWeight表示是否选择返回关键值对应的权重值,默认为False不返回;,allowPos表示筛选包含指定性的词,默认值为空也就是不筛选;idf_path表示IDF频率文件):
import jieba.analyse
jieba.analyse.extract_tags(sentence,topk=N,withWeight=False,allowPos=())
jieba.analyse.TFIDF(idf_path=None)
或者使用基于TextRank算法的关键词抽取,代码如下;
import jieba.analyse
jieba.analyse.textrank(sentence,topk=N,withWeight=False,allowPos=())
jieba.analyse.TextRank()
注意:可以使用for循环显示打印。
jieba分词进行并行运行分词
jieba分词器如果是对于大的文本进行分词会慢,因此可以使用jieba自带的并行分词功能进行分词,其采用的原理是将目标文本按照每行分开后,把各行文本分配到多个Python进程并行分词,然后归并结果,从而获得分词速度的提升。该过程需要基于python自带的multiprocessing模块。注意:目前暂时不支持windows.。
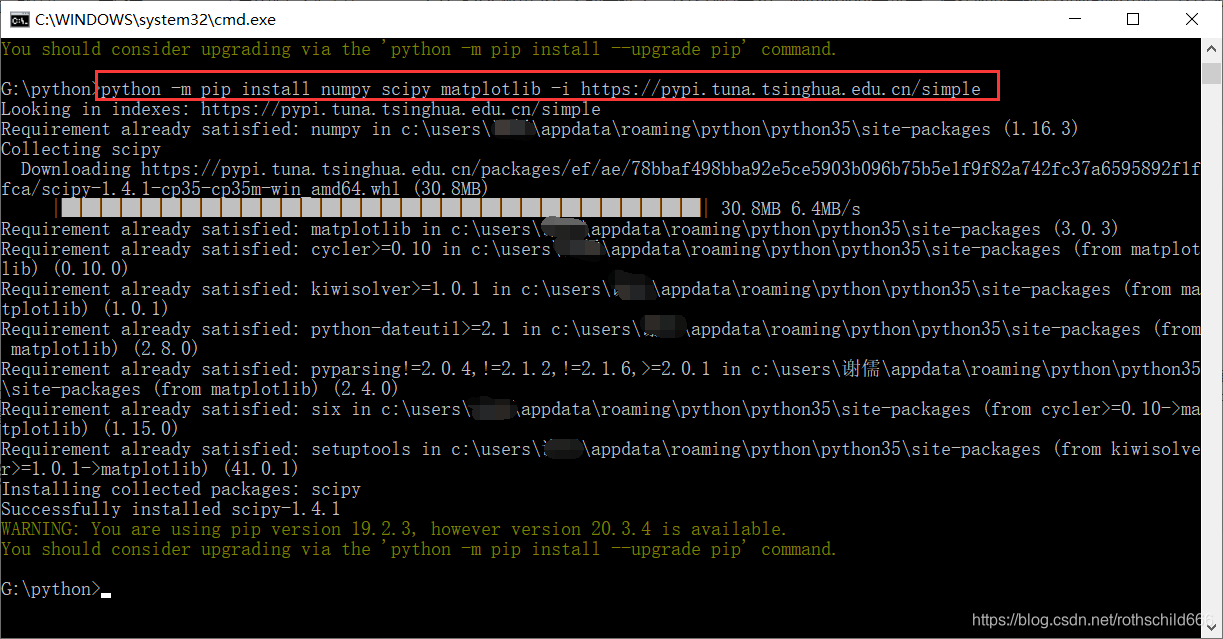
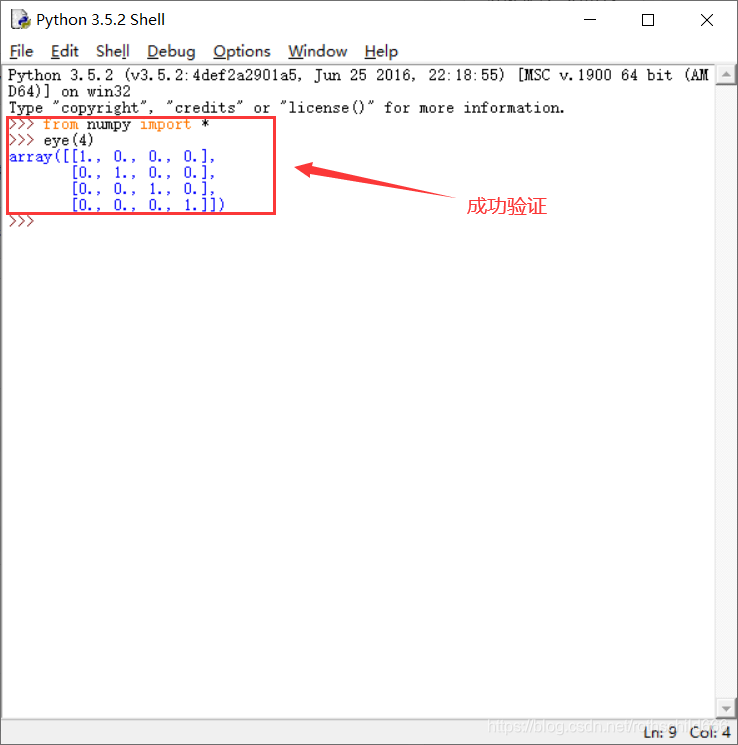
十六、全自动安装 NumPy,首先复制下面代码在cmd平台中安装好pip文件中运行,最后成功验证NumPy安装成功(from numpy import * ,表示导入 numpy 库;eye(4) ,表示生成对角矩阵)。
python -m pip install numpy scipy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
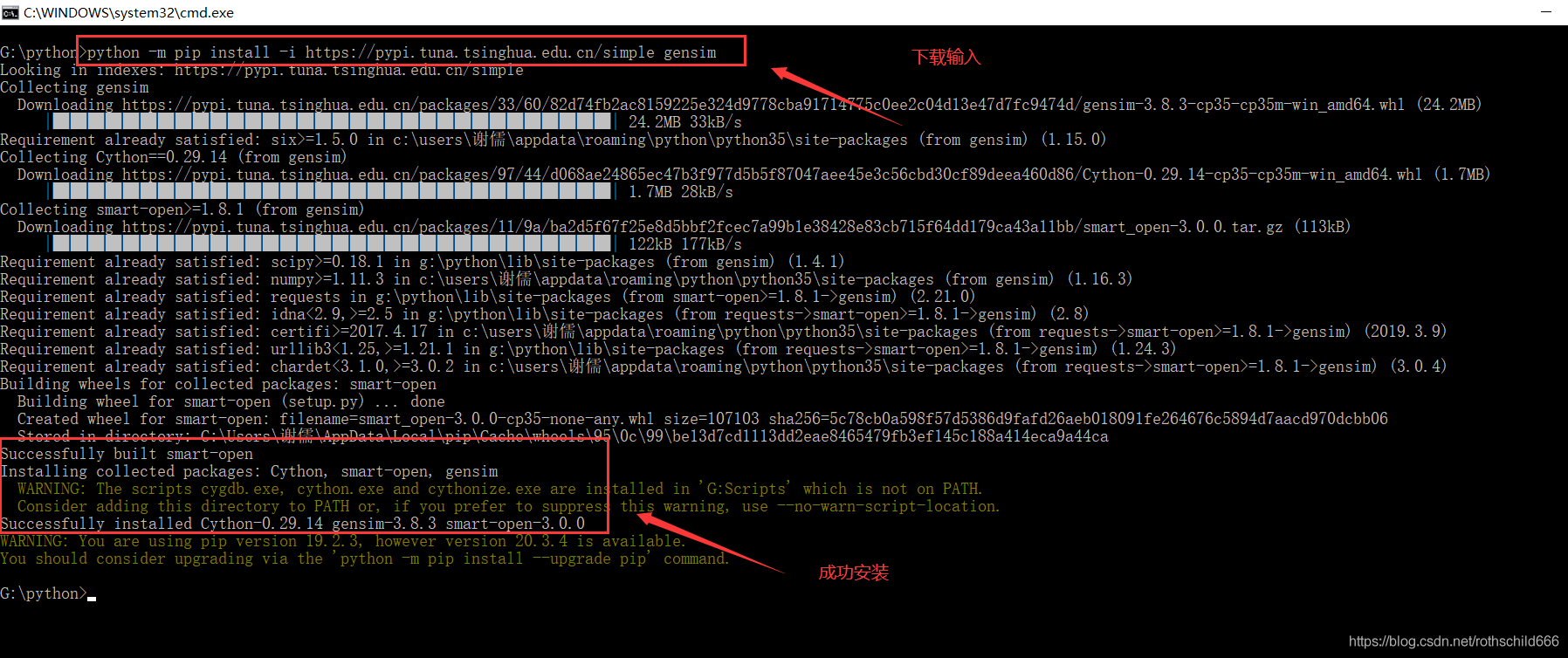
十七、全自动安装gensim,首先复制下面代码在cmd平台中安装好pip文件中运行。
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
十八、复制下面源代码程序运行进行分词和训练操作。
"""
由原始文本进行分词后保存到新的文件
"""
import jieba
import numpy as np
filePath='G:/python/wordvec/corpus.txt' # 存储的文件位置
fileSegWordDonePath ='corpusSegDone.txt'
print('fenciqian')
# 打印中文列表
def PrintListChinese(list):
for i in range(len(list)):
print (list[i])
# 读取文件内容到列表
fileTrainRead = []
with open(filePath,'r',encoding='UTF-8') as fileTrainRaw:
for line in fileTrainRaw: # 按规定行读取文件
fileTrainRead.append(line)
# jieba分词后保存在列表中
fileTrainSeg=[]
for i in range(len(fileTrainRead)):
fileTrainSeg.append([' '.join(list(jieba.cut(fileTrainRead[i][9:-11],cut_all=False)))]) # 精确模式分词
if i % 100 == 0:
print(i)
# 保存分词结果到文件中
with open(fileSegWordDonePath,'w',encoding='utf-8') as fW: # 把分词列表写入fileSegWordDonePath路径中的corpusSegDone.txt文件
for i in range(len(fileTrainSeg)):
fW.write(fileTrainSeg[i][0])
fW.write('\n')
print('fencihou')
"""
gensim word2vec获取词向量
"""
import warnings
import logging
import os.path
import sys
import multiprocessing
import gensim
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
# 忽略警告
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') # 警告扰人,手动封存
if __name__ == '__main__':
program = os.path.basename(sys.argv[0]) # 读取当前文件的文件名,返回path最后的文件名,若path以/或\结尾,那么就会返回空值。
# sys.argv[0]:一个从程序外部获取参数的桥梁,外部参数与程序本身没有任何数据联系,sys.arg是一个列表,第一个也就是sys.argv[0]表示程序本身,随后才依次是外部给予的参数。
logger = logging.getLogger(program) # 获取日志对象,logging模块中最基础的对象
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s',level=logging.INFO) # format格式:%(asctime)s: 打印日志的时间; %(levelname)s: 打印日志级别名称;%(message)s: 打印日志信息
# level: 设置日志级别,默认为logging.WARNING,程序未按预期运行时使用,但并不是错误;logging.INFO表示程序正常运行时使用
logger.info("running %s" % ' '.join(sys.argv))
# inp为输入语料, outp1为输出模型, outp2为vector格式的模型
inp = 'corpusSegDone.txt'
out_model = 'corpusSegDone.model'
out_vector = 'corpusSegDone.vector'
print('chushi')
# 训练skip-gram模型
model = Word2Vec(LineSentence(inp), size=50, window=5, min_count=5,
workers=multiprocessing.cpu_count()) # 将原始的训练语料转化成一个sentence的迭代器,每一次迭代返回的sentence是一个word(utf8格式)的列表。
# sentences:可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或lineSentence构建。
# size:是指特征向量的维度,默认为100。
# window:窗口大小,表示当前词与预测词在一个句子中的最大距离是多少。
# min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉也就是不会生成词向量, 默认值为5。
# workers:用于控制训练的并行数,multiprocessing.cpu_count()获取计算机CPU数量
# 保存模型
print('xunci')
model.save(out_model)
# 保存词向量
model.wv.save_word2vec_format(out_vector, binary=False)
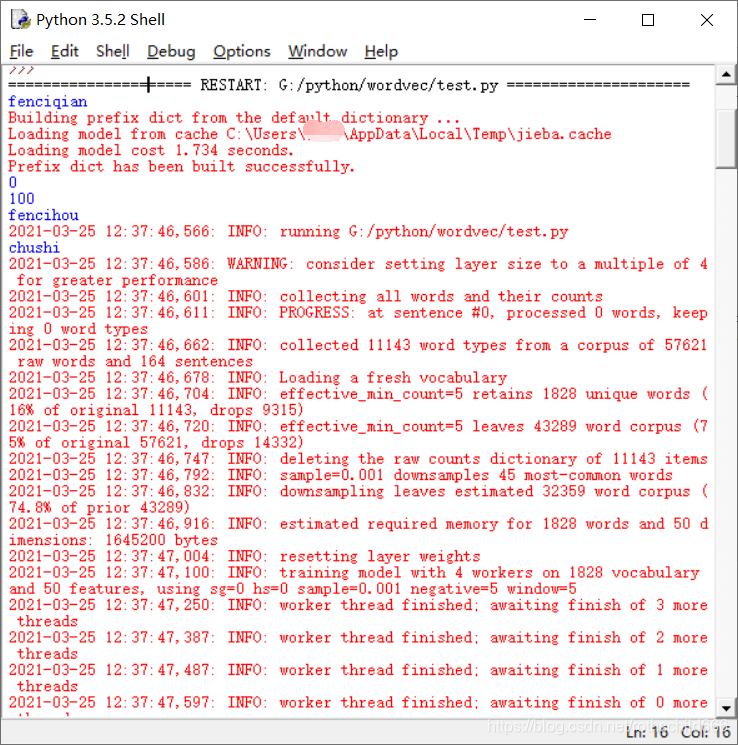
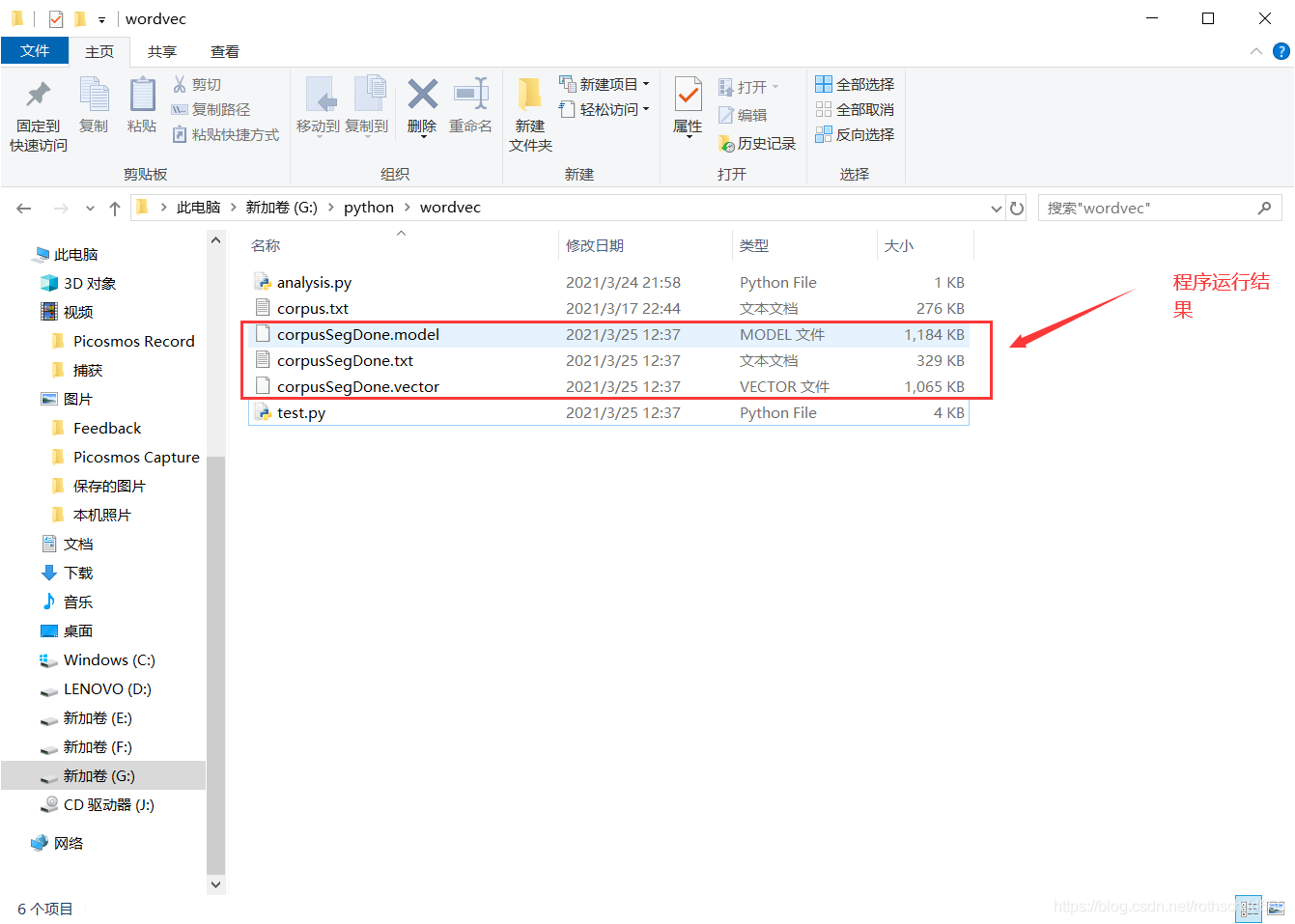
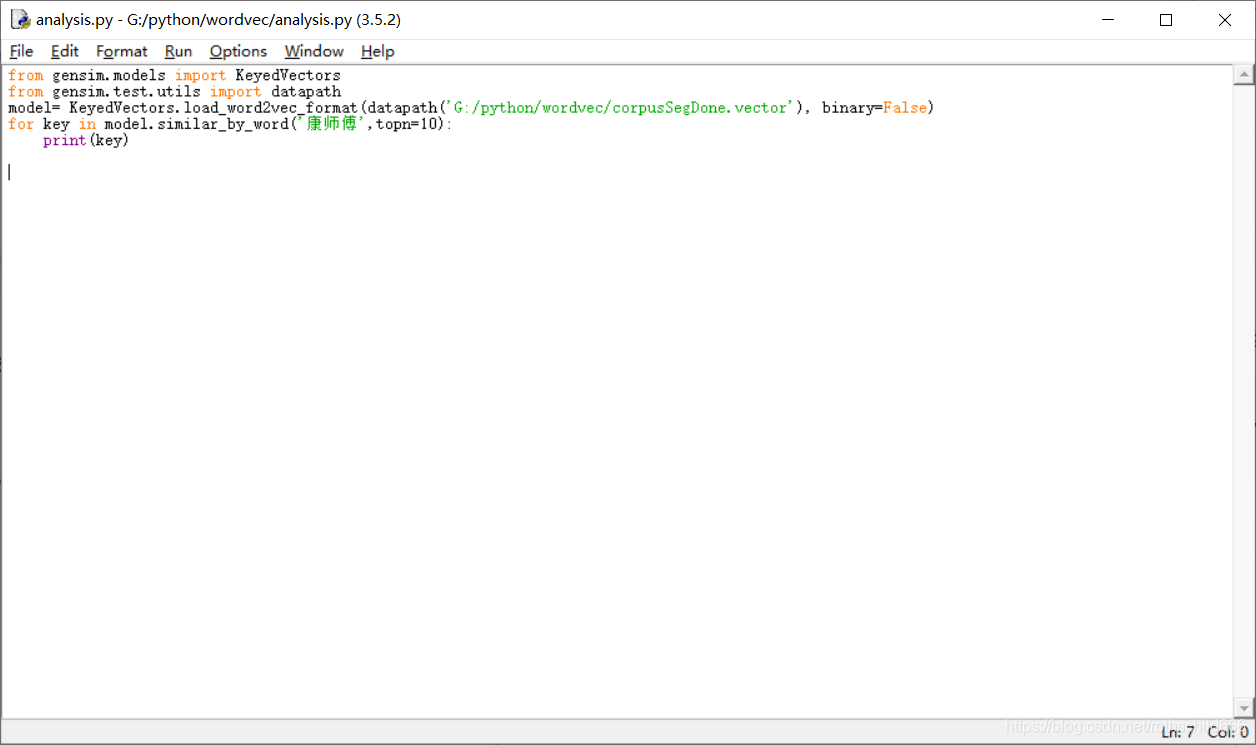
十九、复制下面源代码程序运行进行文本词向量计算分析。(博主只是举例说明,大家可以进行修改扩展功能操作分析!)
from gensim.models import KeyedVectors
from gensim.test.utils import datapath
model= KeyedVectors.load_word2vec_format(datapath('G:/python/wordvec/corpusSegDone.vector'), binary=False)
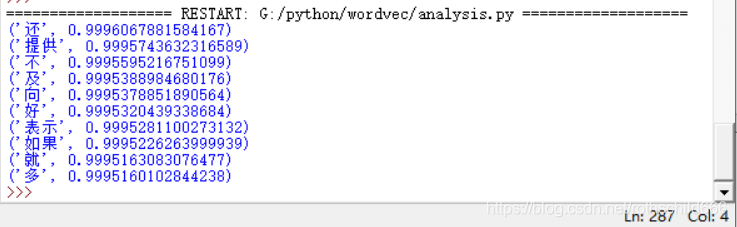
for key in model.similar_by_word('康师傅',topn=10): #注意分词时有的词语被筛选没有形成词向量,就会导致无法找到自然就无法计算分析
print(key)















 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











