






 本文深入探讨了MongoDB与SQL在设计上的差异,包括一对一、一对多关系的处理。MongoDB提倡使用内嵌文档和引用,而SQL则依赖于表间关系。在一对一场景下,MongoDB内嵌方式更胜一筹;一对多场景中,根据业务需求选择内嵌、内嵌id、父级引用或混合型设计。设计时需综合考虑查询效率、修改频率和文档大小等因素。
本文深入探讨了MongoDB与SQL在设计上的差异,包括一对一、一对多关系的处理。MongoDB提倡使用内嵌文档和引用,而SQL则依赖于表间关系。在一对一场景下,MongoDB内嵌方式更胜一筹;一对多场景中,根据业务需求选择内嵌、内嵌id、父级引用或混合型设计。设计时需综合考虑查询效率、修改频率和文档大小等因素。
原创文章,如果转载请标明出处、作者。 https://www.cnblogs.com/alunchen/p/9762233.html
1 前言
MongoDB作为现今流行的非关系型文档数据库,已经有很多关于它的资料与介绍。
写这篇文章时,MongoDB已经更新到4.0版本,支持事务型操作。还末在生产环境中使用事务型的MongoDB,因为功能还未完善。
好啦,说正题了。本文是总结本人使用MongoDB多年的经验,有不同见解之处,请多多关照。
说明:
1)关系型SQL的表在MongoDB上称为集合。为了好对比,这里MongoDB上说的表也是集合的意思。
2)这里mongodb与关系型SQL的对比之中设计上的,其它底层等对比这里不做任何的阐述。
2 对比
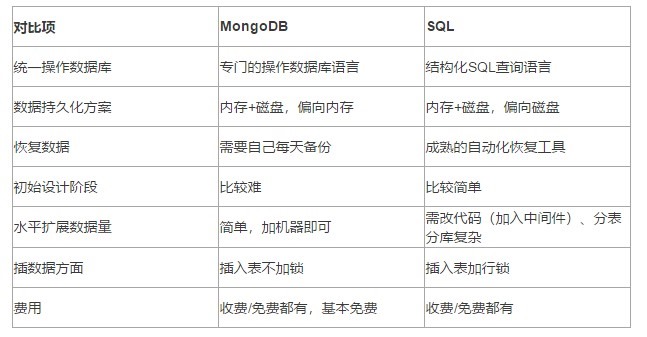
MongoDB与SQL的对比(对比的MongoDB都在使用WiredTiger存储引擎为前提)
3 设计
从设计来说,相信很多人都是使用过SQL设计表。
题外话:在以前,甚至是现在,很多架构设计都是从设计表开始,设计完表再开始写代码。现在呢?推崇代码优先方案,或者实体优先方案。先设计实体,然后实体导入到数据库中。这是典型的DDD模式。
下文中,为了更好理解,首先从SQL方面是怎么设计的,然后再看看MongoDB是怎么设计的,有什么难点。
3.1 设计:一对一的情况
前提:两张表的一对一。
场景:键盘与主机的关系。一台主机有一个键盘,一个键盘有一台主机。
主机字段:id、CPU核数、内存大小、显卡大小。
键盘字段:id、主机的id、键盘类型(机械/非机械)、颜色、牌子。
3.1.1 关系型SQL
设计:会有两张表,一张为主机表,一张为键盘表。当然你可以合成一张表,合成一张表就没有讨论的价值了。如下图:

查询时:
查询主机与键盘数据时,即两张表数据时,需要关联两张表查询。性能比较慢。
查询主机数据时,只需要单个表查询。
更新时:
都是更新一张或两张表数据。会锁表行。
增加时:
增加一张或两张表数据。
3.1.2 MongoDB
在MongoDB来说,是属于文档型数据库,在一对一关系来说一般使用内嵌方式,因为性能体现在'以空间换取时间'。
抛弃设计,在一对一来说,可以使用内嵌,又可以使用关系型SQL的两张表关联。但是使用两张表的关联显得累赘。
所以,如果使用关系型SQL的两张表关联,没有什么对比性,并且MongoDB不推荐这样的做法。这里只介绍内嵌。
设计:一对一,内嵌。
保存在MongoDB如下json:

{
"主机id":"1",
"CPU核数":"2核",
"内存大小":"16GB",
"显卡大小":"2GB",
"键盘":{
"键盘类型":"机械",
"颜色":"Black",
"牌子":"双飞燕"
}
}
可以看到,键盘去掉了自己的id,并且去掉了关联主机的id。
查询/更新/增加时,一张表查询即可。
小结
所以在一对一来说,MongoDB与关系型SQL没有什么对比性。
硬要说对比性,一对一场景来说,MongoDB更加面向对象。
建议:在MongoDB一对一场景下,建议使用内嵌,不应该使用两张表关联。
3.2 设计:一对多的情况
在一对多中,存在者4种不同的场景,需要都一一介绍。因为最终设计都根据业务需求来的,所以这里举不同的业务场景来说明。
3.2.1 场景1,完整内嵌型一对多
场景:订单与订单项的关系。
网购过的同学都知道,用户支付订单时,有很多个子订单项。比如某宝的下单时,包括不同商铺的不同的订单项。
在订单与订单项关系中,一般查询都是查询整个订单,没有对单个订单项的查询。
想象一下以下场景:
1)查看订单的场景。进入某宝,查看订单时,都是从订单进入,然后查看所有的订单项。
2)支付成功或失败后,修改订单时,都是修改订单,没有修改订单项。
字段:
订单字段:id、订单号、运费、总价格、订单状态。
订单项字段:名称、单价、数量。
MongoDB设计
从上面2个场景,很容易的想到完整内嵌型的一对多非常适合这种需求。
看看如下JSON:
{
"id": "asdg184981651568956",
"订单号": "201809270012598323334",
"运费": 0,
"总价格": 41,
"订单状态": "已经支付",
"订单项": [
{
"名称": "益达口香糖",
"单价": 8,
"数量": 2
},
{
"名称": "大大口香糖",
"单价": 5,
"数量": 1
},
{
"名称": "绿箭口香糖",
"单价": 10,
"数量": 2
}
]
}
查询订单时:
查询订单一条语句即可,就能查询出订单以及订单所有的订单项。也不会需要查询出单个订单项。
修改订单时:
只修改根内容,不会修改订单项(内嵌的)内容。
小结
使用完整内嵌一对多设计时,前提有这几点:
1)内嵌数组大小不宜过大。因为太大会导致整个实体内容大,从而导致网络延迟问题。建议不超过20或30个。具体根据内嵌实体大小而定。
2)如果内嵌实体数组多(一般多于5个),查询时,内嵌实体内容没有作为单独的实体查询。例如不会有单个查询订单项的需求。
3)如果内嵌实体数组多(一般多于5个),修改/删除/插入时,内嵌实体内容没有作为单独的实体修改/删除/插入。
3.2.2 场景2,内嵌id型一对多
场景:公司与员工的关系。一个公司对应个员工,雇佣关系。假设这里的公司最多都是几千位员工。
想象一下以下场景:
1)员工的属性很多。
2)一个公司有很多员工,可能也有很少员工。
3)单独查询员工信息的场景。
4)修改员工信息的场景。
综上场景,使用3.2.1内嵌设计型不符合我们的需求。所以我们可以考虑内嵌id型。
什么是内嵌id型,就是父级引用子级的id,子级作为单独实体(表)存在。即这里的公司有员工id的引用。
实体

MongoDB设计
公司表
{
"id":"45465516654",
"名称":"千度科技有限公司",
"注册地址":"北京市朝阳区",
"所有人":"张大大",
"注册日期":"2001-9-1",
"员工":[
{ "id":"员工id1" }, { "id":"员工id2" }
]
}
员工表
{
"id":"员工id",
"姓名":"alun",
"入职时间":"2017-8-8",
"身份证号":"441955876632155502",
"职位":"架构师",
"工资":8000,
"入职年限":1,
"头像":"https://www.dr.cn/head/sdfjooc2143.jpg",
"公资金百分比":5,
"得奖数":1,
"体重":"50KG",
"住址":"广东省广州市天河区龙洞",
"下属人数":20,
"年假剩余天数":0,
"评价级别":10
}
在查询时:
查询公司下面有的员工信息,两张表的关联查询。首先查询公司表,然后关联员工表查询员工的信息。
查询单个员工信息时,只需查询员工表,就能取得员工实体信息。
在修改时:
修改单个员工信息时,修改员工的实体即可。
与SQL的对比:
如果是SQL的设计,员工表就多了一个公司表的id做关联。公司表也不会有员工的ids。
在查询公司下有哪些员工时,mongodb与关系型SQL各有秋千。因为mongodb首先查询公司表,得到员工的id后,再关联查询。注意这里的关联查询员工的主键是id,默认加了索引。如果是关系型SQL,那么需要在员工表加入公司表的id做关联,此种查询只需通过查询员工表的公司id即可得出员工的信息。
更深一层说,如果查询公司名称是“百度公司”时,mongodb与关系型SQL都需要联表查询,鉴于mongodb有id的内嵌并且是索引,理论上来说mongodb快很多。
小结
使用内嵌id型一对多设计时,前提有这几点:
1)一对多的多那方数量要多,最好是几十个到几千个不等。
2)如果需要单独把内嵌的实体取出。即单独取出多那方的实体。
这种方案的缺点:
1)查询员工属于哪些公司时,需要跨表查询。
2)内嵌方的数量不能过多。
3.2.3 场景3,内嵌id+查询字段型一对多
继续引用上面公司与员工的场景。
如果有个功能,查询公司下面的员工名字。这个功能是占用查询率70%以上的话,可以考虑使用内嵌id+查询字段型。
即在公司内嵌员工id的同时,加上员工的姓名。如下:
{
"id":"45465516654",
"名称":"千度科技有限公司",
"注册地址":"北京市朝阳区",
"所有人":"张大大",
"注册日期":"2001-9-1",
"员工":[
{ "id":"员工id1", "姓名":"alun" },
{ "id":"员工id2", "姓名":"vivien" }
]
}
在查询时,不需要管理表,直接查询公司表即可。查询效率大大提升。
但是相应地,修改名字的时候需要修改公司表、员工表。需要一次都修改2张表成功。需要原子性的操作。
小结
使用内嵌id+查询字段型一对多设计时,前提有这几点:
1)一对多的多那方数量要多,最好是几十个到几千个不等。
2)内嵌方的属性(字段)不宜过多。
3)查询、修改比高。即查询需求大大大于修改需求。
这种方案的缺点:
1)修改时需要原子性操作。
2)文档内容加大了,即产生了多余字段。如上面的【姓名】。
3)需要特殊场景需求。
3.2.4 场景4,父级引用型一对多
列举了上面的公司与员工的场景,如果有种需求,多那方是大量的话,那怎么办呢?
场景:某宝/某东 与商铺的关系。据不完全统计,某宝商铺有几万到几十万,甚至几百万不等。
上面这么大量的数据,显然使用内嵌型有些力不从心。因为文档大小也有限制,如果太大的话,不禁mongodb报错,还可能导致网络延迟。因为一次查询的数据量过大。
所以这里就使用父级引用。什么是父级引用,即子级引用父级id。如商铺引用某宝id。
实体:

MongoDB设计
某宝/某东表
{
"id":"hijgio19089popik",
"名称":"某宝",
"注册地址":"杭州市",
"所有人":"某某某",
"注册日期":"2005-1-1"
}
商铺表
{
"id":"84948654",
"名称":"alun的商铺",
"创建时间":"2018-2-1",
"过期时间":"2019-2-1",
"是否合法":true,
"商品品质级别":"高",
"是否个人商铺":true,
"营业执照":"https://yyzz.tb.cn/kg/145/84948654.jpg",
"持有人身份证号":"441922365587444468",
"持有人身份证图片":"https://yyzz.tb.cn/kg/966/441922365587444468.jpg",
"某宝/某东id":"hijgio19089popik"
}
查询时:
查询属于某宝的商铺时,在商铺表通过某宝/某东id查出所有的商铺。几万商铺以上。
修改时:
修改商铺、修改某东/某宝表的属性都是单个表修改。
从上面可以看出,一的那方不需要做关联,只需要多的那方有一的那方的id即可。这种设计完全是套用关系型SQL的用法。很多关系型SQL都这样使用。所以对比关系型SQL,这种用法在MongoDB来说没有什么优点。
小结
使用父级引用型一对多设计时,前提有这几点:
1)一对多的多那方数量很多,上万以上。
2)对性能要求不高。
这种方案的缺点:
1)性能不高。
2)与关系型SQL相比,没有什么优点。
3.2.5 场景5,内嵌id+父级引用混合型一对多
我们再针对某宝分析吧,比如一个商铺,有很多个商品。
场景:商铺与商品的关系。一个商铺对应很多个商品(几百、几千、上万个不等)。
想象一下以下场景:
1)商品的属性很多。
2)一个商铺下面的商品很多。
3)查询时,查询到商铺按类别查询、按销量查询的需求。
4)查询时,查询商铺的所有商品。此查询率比较高,进入商铺就需要用到。
5)修改时,单独修改商品的规格、价格等等。
6)修改商品信息较少发生。
综上场景,使用3.2.1内嵌设计型不符合我们的需求。
3.2.2 内嵌id型,好像可以满足我们的现在需求。但是目前有个需求的查询率比较高,就是第4点。再加上商铺是几百到上万不等,所以需要再考虑。
3.2.3 内嵌id+查询字段型也不符合我们的需求,因为通过商铺查询某些商品属性的场景不存在。
3.2.4 父级引用好像蛮合适的。但是效率有点低,暂时不考虑。不如使用关系型SQL。
总结一下上面的不同方案,好像内嵌id型与父级引用都蛮适合的,但是各有优劣,那么我们怎么办呢?混合试试?
实体:

如果有上面的实体,想象一下自己怎么设计呢?对,使用内嵌id型一对多。
什么是内嵌id型一对多呢?父级只引用子级对象的id。我们看看下面的mongoDB的JSON格式。
首先是商铺表:
{
"id":"3455-2dp4x-xderd0",
"名称":"alun的商铺",
"类型":"药材专卖店",
"所有人":"alun",
"创建日期":"2018-9-1",
"商品":[
{ "id":"商品id1" },
{ "id":"商品id2" }
]
}
然后是商品表:
{
"id":"商品id1",
"名称":"枸杞",
"类型":"中药补血",
"是否上架":"是",
"创建日期":"2018-9-15",
"商品详情":"农民枸杞直销,价格原厂,不经过加工。",
"商品编码":"878866554234",
"规格":"1kg",
"运费":0,
"重量":11,
"标签":"中药材枸杞",
"销售量":0,
"销售价":20,
"原价":40,
"商铺id":"3455-2dp4x-xderd0"
}
查询时:
查询到商铺按类别查询、按销量查询的需求。查询商品表即可。
查询商铺的所有商品。查询商铺表的商品,再通过商品id查询所有的商品表。所以要关联查询。
修改时:
如果要修改商品与商铺的关系,需要原子性删除,两张表做操作。但是这种操作在需求上来很少见。上面需求也列明了,所以这方面性能暂时不考虑。
小结
使用内嵌id+父级引用混合型一对多设计时,前提有这几点:
1)一对多的多方数量中等,最好是几百到上万即可。
2)一对多的多方数量存在严重的不确定性。
这种方案的缺点:
1)混合模式,折中方案,没有太大的优势。
总结
通过上面的内容,可以了解到,在项目设计时,mongodb需要考虑的方面实在太多了,相对的关系型SQL考虑的方面少很多。所以在设计mongodb之前,需要考虑数据的关系,使用的场景,对应业务的需求量。比如查询与修改率、是否内嵌。
好的设计,都离不开对业务的整体、细致的理解。mongodb让我们对数据更加细致的理解,更加面向对象。
所以,尽可能的去尝试mongodb吧,大家有什么分享或者不同意见的请不含蓄地提出,共同学习才是最好的成长!















 3057
3057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









