









一、协同过滤算法描述
推荐系统应用数据分析技术,找出用户最可能喜欢的东西推荐给用户,现在很多电子商务网站都有这个应用。目前用的比较多、比较成熟的推荐算法是协同过滤(Collaborative Filtering,简称CF)推荐算法,CF的基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
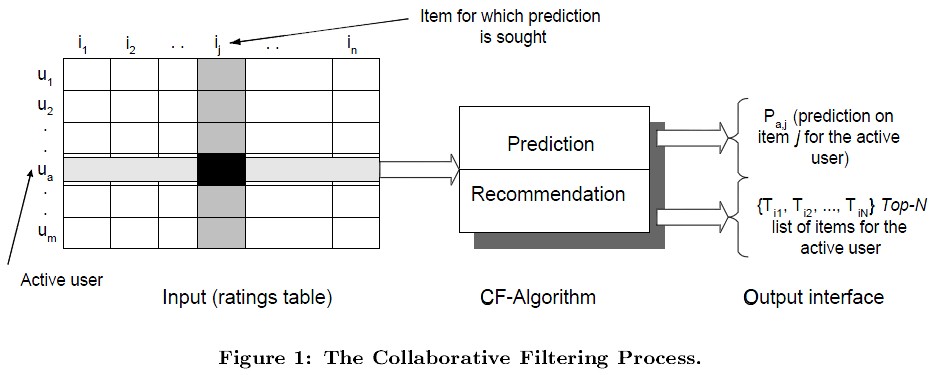
如图1所示,在CF中,用m×n的矩阵表示用户对物品的喜好情况,一般用打分表示用户对物品的喜好程度,分数越高表示越喜欢这个物品,0表示没有买过该物品。图中行表示一个用户,列表示一个物品,Uij表示用户i对物品j的打分情况。CF分为两个过程,一个为预测过程,另一个为推荐过程。预测过程是预测用户对没有购买过的物品的可能打分值,推荐是根据预测阶段的结果推荐用户最可能喜欢的一个或Top-N个物品。
二、User-based算法与Item-based算法对比
CF算法分为两大类,一类为基于memory的(Memory-based),另一类为基于Model的(Model-based),User-based和Item-based算法均属于Memory-based类型,具体细分类可以参考wikipedia的说明。
User-based的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
User-based算法存在两个重大问题:
1. 数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
2. 算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
Iterm-based的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。还是以之前的例子为例,可以知道物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。
因为物品直接的相似性相对比较固定,所以可以预先在线下计算好不同物品之间的相似度,把结果存在表中,当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题。
三、Item-based算法详细过程
(1)相似度计算
Item-based算法首选计算物品之间的相似度,计算相似度的方法有以下几种:
1. 基于余弦(Cosine-based)的相似度计算,通过计算两个向量之间的夹角余弦值来计算物品之间的相似性,公式如下:

其中分子为两个向量的内积,即两个向量相同位置的数字相乘。
2. 基于关联(Correlation-based)的相似度计算,计算两个向量之间的Pearson-r关联度,公式如下:
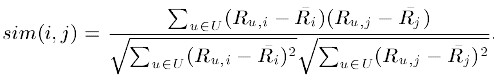
其中![]() 表示用户u对物品i的打分,
表示用户u对物品i的打分,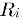 表示第i个物品打分的平均值。
表示第i个物品打分的平均值。
3. 调整的余弦(Adjusted Cosine)相似度计算,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:

其中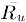 表示用户u打分的平均值。
表示用户u打分的平均值。
(2)预测值计算
根据之前算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法:
1. 加权求和。
用过对用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分,公式如下:
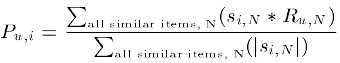
其中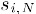 为物品i与物品N的相似度,
为物品i与物品N的相似度,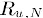 为用户u对物品N的打分。
为用户u对物品N的打分。
2. 回归。
和上面加权求和的方法类似,但回归的方法不直接使用相似物品N的打分值,因为用余弦法或Pearson关联法计算相似度时存在一个误区,即两个打分向量可能相距比较远(欧氏距离),但有可能有很高的相似度。因为不同用户的打分习惯不同,有的偏向打高分,有的偏向打低分。如果两个用户都喜欢一样的物品,因为打分习惯不同,他们的欧式距离可能比较远,但他们应该有较高的相似度。在这种情况下用户原始的相似物品的打分值进行计算会造成糟糕的预测结果。通过用线性回归的方式重新估算一个新的值,运用上面同样的方法进行预测。重新计算的方法如下:

其中物品N是物品i的相似物品, 和
和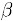 通过对物品N和i的打分向量进行线性回归计算得到,
通过对物品N和i的打分向量进行线性回归计算得到, 为回归模型的误差。具体怎么进行线性回归文章里面没有说明,需要查阅另外的相关文献。
为回归模型的误差。具体怎么进行线性回归文章里面没有说明,需要查阅另外的相关文献。
四、结论
作者通过实验对比结果得出结论:1. Item-based算法的预测结果比User-based算法的质量要高一点。2. 由于Item-based算法可以预先计算好物品的相似度,所以在线的预测性能要比User-based算法的高。3. 用物品的一个小部分子集也可以得到高质量的预测结果。

















 3998
3998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









