






Excel催化剂在2018年开始,陆续写出了230+篇高质量原创性文章,将Excel催化剂插件的开发过程及使用方法全方位地通过文字的方式给广大网友们分享了。
电子书下载方式
同样地,为了减少大家过多繁琐的资料下载途径,电子书的下载路径和之前插件的下载路径不变,在公众号后台回复【插件下载】即可找到下载链接。
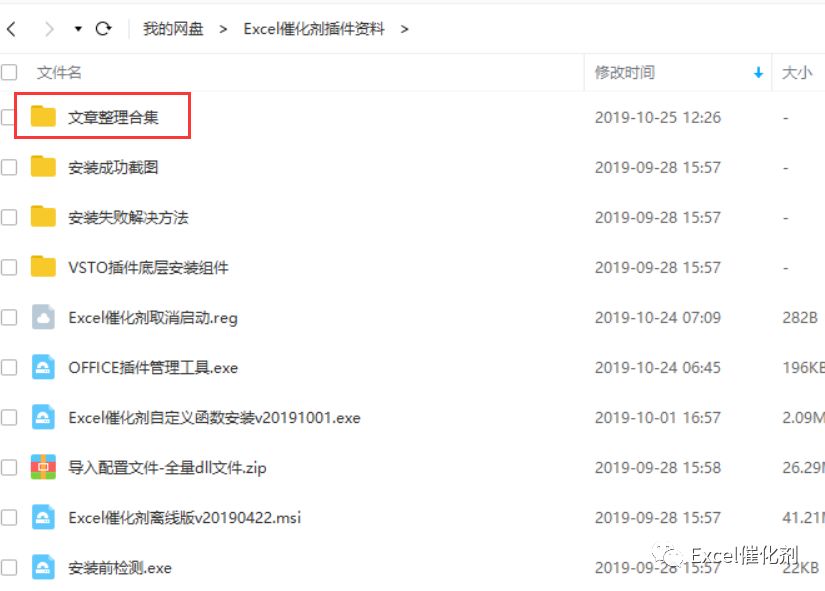
电子书做了PDF版和WORD版本,在PDF版本中,阅读体验更佳,在WORD版本中编辑和查找体验更佳,大家按各自所需下载即可。
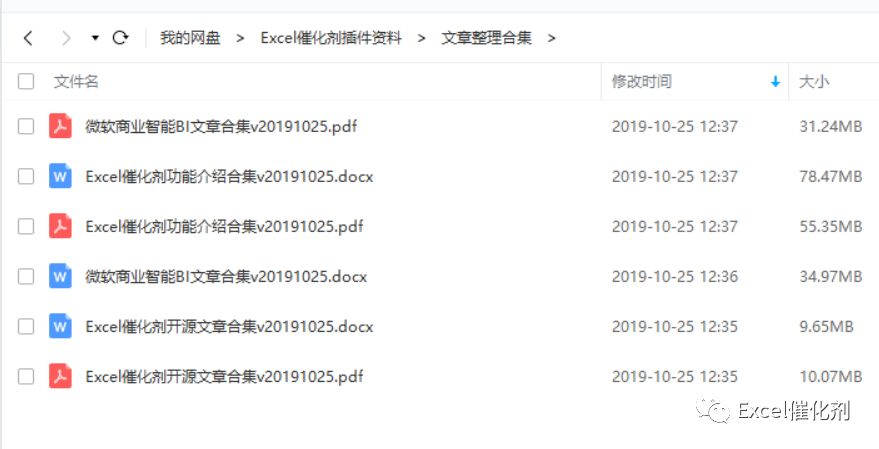
授之以鱼不如授之以渔
相信广大读者们,对制作电子书的整个过程也是有兴趣的,按Excel催化剂的一贯作风,无保留所有制作技术细节给大家作一分享,希望可以带给大家更多的授之以渔的喜悦。
看过前面的推文的朋友们,应该对之前介绍的方法还有所印象吧,有兴趣的不妨回翻一下。
[技术实现]一口气整理整个专集网页为一本电子书方法 - 简书 https://www.jianshu.com/p/aa7ae413136a
但非常遗憾地是,用之前的方法套在Excel催化剂的230+篇文章的合并汇总时,总是难以实现所需的效果。
一路的技术实现挫折之旅
用selenium下载网页下来,通过wkhtmltopdf工具转成的pdf,仍然是图片显示不出来,没有图片的方案绝对不是一个最终的方案。
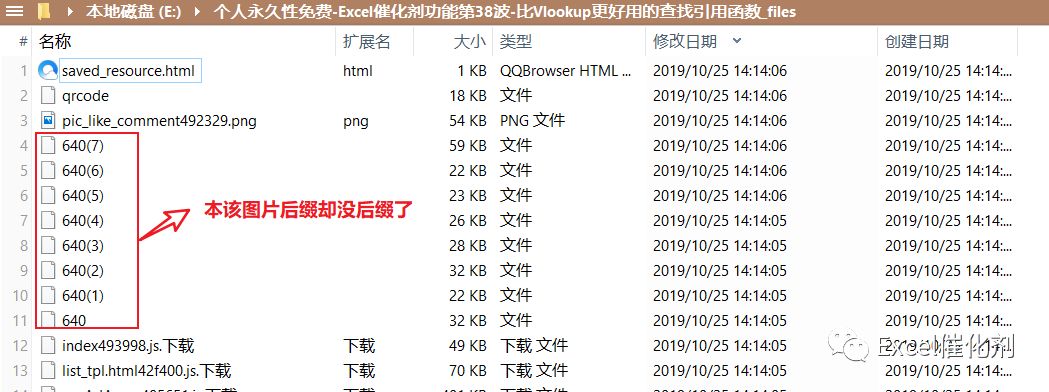
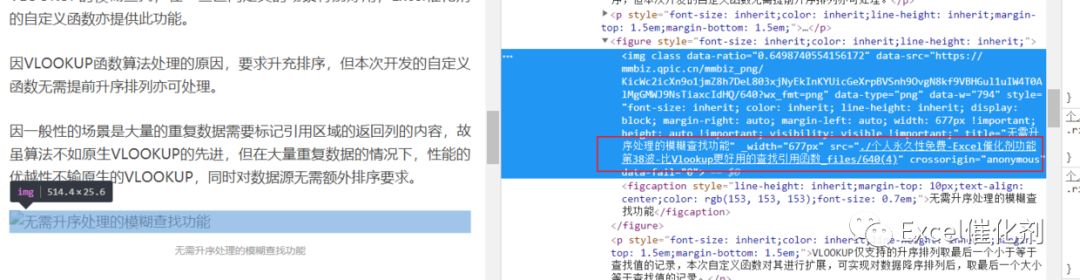
而下载文章从简书平台上来到微信公众号的文章,同样下载后,一样是图片问题不能显示,微信公众号网页下载后,图片文件被省略了后缀名,没法在html页面上重新渲染出来。
接着换了个方案,因为所有的文章都是在简书平台上写出来的,用的是markdown格式来写,前端网页看到的效果是已经渲染过的。所以就考虑了直接下载简书上的markdown格式原文下来。
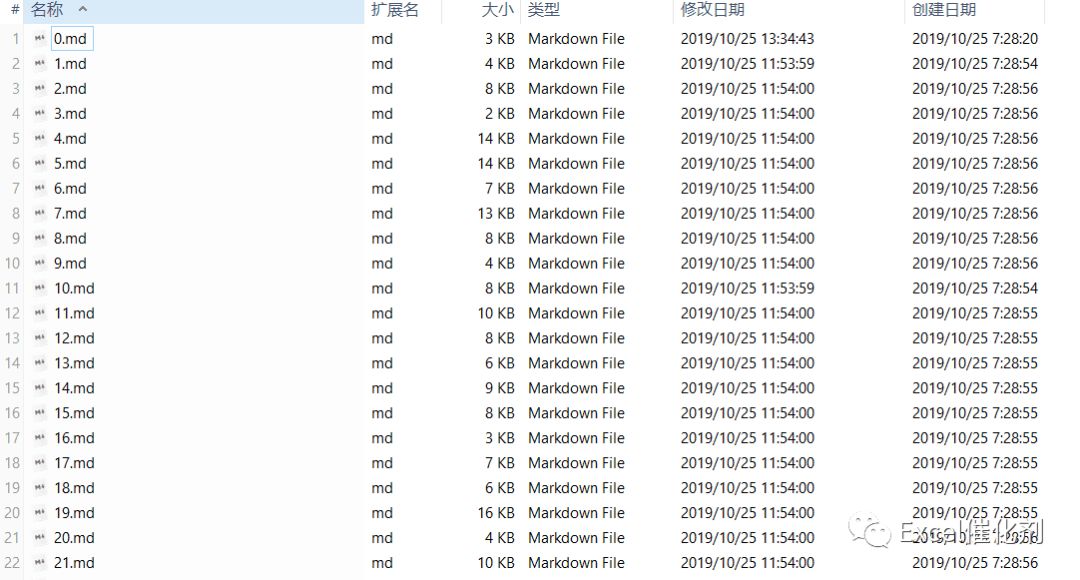
为了防止文件名有不合法字符,用了序号的方式命名,再用映射表来配对。

网络上大量介绍markdown转html或pdf的文章,尝试着去学习了一翻,知道了pandoc这个文档转换神器。
在网络上的教程中,大量的方法是mac和linux系统下的方法,这真难为了普通用户,注定这些方法很难让我们一般人去接触和使用。
最为糟糕地是我们的中文问题,许多教程都指向了需要下载其他组件来应对中文显示不出的问题,而这些文章都只是类同性地出处一致,指向mac和linux系统的实现方式。
最后偶然间看到一篇文章提到,大家所说的pandoc中文问题需要xelatex引擎的事情,只是极个别markdown里带有复杂的公式才需要,若普通的文档,用之前的wkhtmltopdf引擎即可。
就这样,选择比努力重要,方向对了,就没再受中文问题困扰,用wkhtmltopdf引擎少量测试的确成功了。
pandoc "224.md","225.md","226.md","227.md","228.md" --pdf-engine wkhtmltopdf --css test.css -o test.pdf
很不幸的是,在整理好所需转换的文件集后,例如Excel催化剂功能介绍写了100+篇,把所有文件都输出到一个PDF或WORD文件中时,最后的结果是只能转换100多页的数据,20多篇的文章,剩下的就不显示了。
这样的结果,显然不是想要的,一个合集还要分在多个PDF或WORD里,对搜索的体验太差了。
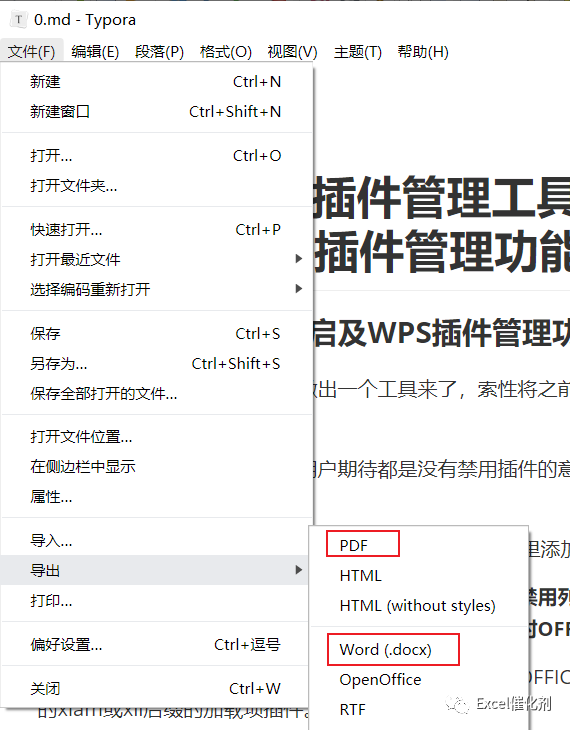
柳暗花明之使用Typora软件实现markdown转PDF或WORD格式
Typora是一款现成的软件,用于markdown方书写和浏览功能,之前有听朋友介绍过,没有认真去研究过它的所有能力。
同时它也是免费的软件,不必心里老过意不去用盗版软件。
一开始看到有人提到过它可以将markdown格式导出PDF格式,没当回事,毕竟我的场景是多个markdown格式的文件来转。
后来想想,markdown格式就是文本格式文件,文本文件的合并也是很容易的事,在自己作文本清洗的过程中,顺带合并一下很轻松,合并后一试,出人意外的惊喜,完成没卡死,完全显示正常,格式和图片都正常。
转换好的PDF文件,含书签,600多页也非常快就转换完成。
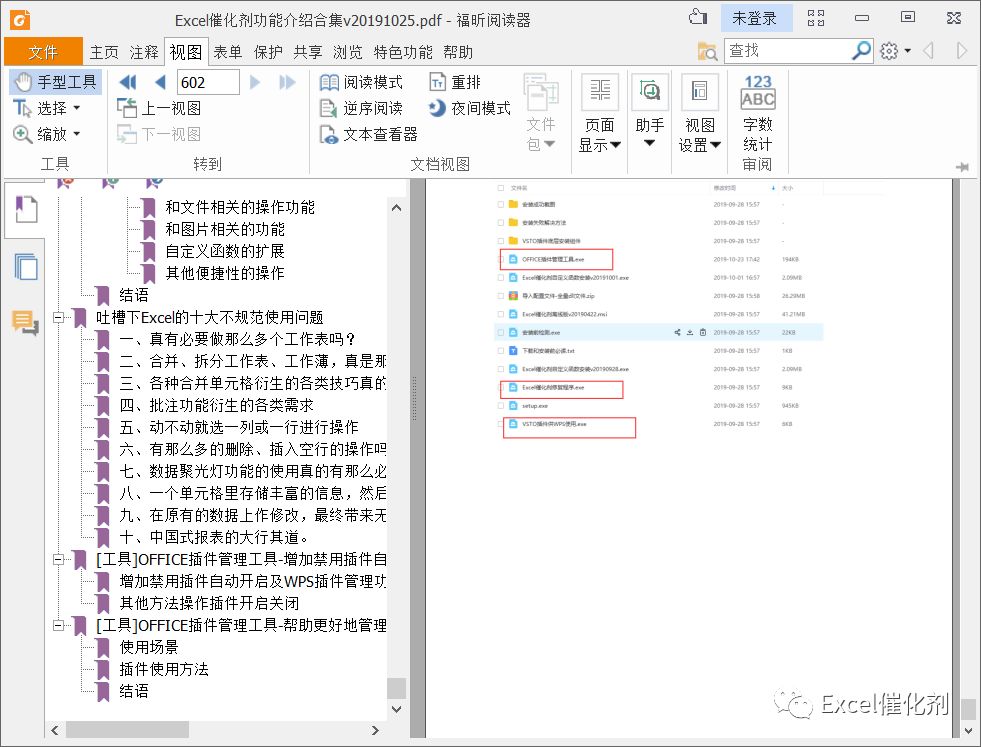
markdown的文本格式文件,比起其他文件来说,处理起来非常流畅,使用了几轮正则替换功能,将之前文章写得不规范和有结尾冗余的自我介绍内容一并清除掉,留下非常清爽的内容。
清理代码如下:
private static void 清洗简书markdown()
{
foreach (var item in Directory.EnumerateFiles(@"E:\简书文章", "*.md"))
{
string content = File.ReadAllText(item);
RegexOptions optionsMultiline = RegexOptions.Multiline;
string result = Regex.Replace(content, @"^#{1,6}(?=[\w])", new MatchEvaluator(s => "\r\n" + s.Value + " "), optionsMultiline);//早期的#写的不规范,没有空一个格子
result = Regex.Replace(result, @"(\r\n){3}", "\r\n\r\n");//多行空白转一行
result = Regex.Replace(result, @"^#{1,6} 系列文章[\s\S]+?(?=^#)", "", optionsMultiline);//早期插入的系列文章
result = Regex.Replace(result, @"### 系列文章[\s\S]+", "");//后期插入的系列文章,删除系列文章以后的内容
result = Regex.Replace(result, @"#{1,6} 关于Excel催化剂[\s\S]+", "");//删除关于Excel催化剂以后的内容
result = Regex.Replace(result, @"#{1,6} 技术交流QQ群[\s\S]+", "");//删除技术交流QQ群以后的内容
File.WriteAllText(Path.Combine(@"E:\简书文章-已处理", Path.GetFileName(item)), result);
}
}
使用Typora唯一的小遗憾是图片中的图注信息,怎么弄都弄不回来,这个只能在自己日后写markdown文章时,尽量少在图片上写备注图注信息来避免了。
结语
技术的路上,坑很多,很幸运,在自己想做的事情上,最终还是完成了,在网络上教程不全和有不足的方案中,经过自己的组合,最终实现了没有太复杂、高深的技术,也能达成自己想要的最终效果,是一件非常愉悦的事情。
希望Excel催化剂所输出的这一系列内容,也能带给读者们一些些的小收获,避开一些坑,同时收获一些自己将想要的东西实现出来的喜悦。















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









