






其实吧,这不是个新概念,GAN,全称是生成对抗网络(Generative Adversarial Network),是人工智能领域的一种技术,用来生成和现有数据类似的新数据。在2017年左右那会儿简直火呆了,它的原理可以用一个简单的比喻来解释:
想象有一个艺术家和一个鉴赏家,他们在进行一场比赛。

1.艺术家(生成器,Generator):艺术家的任务是画出尽可能逼真的画作,让人觉得它们是真实的。刚开始的时候,这个艺术家的技术很一般,画出来的画作并不真实。
2. 鉴赏家(判别器,Discriminator):鉴赏家的任务是区分哪些画是真实的(来自真实世界的数据),哪些画是艺术家画的(生成的数据)。鉴赏家也是刚开始的时候水平很一般,很容易被欺骗。
比赛的过程
1. 初始阶段:艺术家和鉴赏家水平都不高。艺术家画的画不真实,鉴赏家也很容易被欺骗。
2. 逐步提升:通过不断的比赛,艺术家和鉴赏家互相促进。每当鉴赏家成功识别出假的画作,艺术家就会调整自己的画法,让下一次的画作更逼真。同样,每当鉴赏家无法识别出假的画作,他也会改进自己的鉴别技巧。
3. 最终阶段:经过多次训练后,艺术家的画作变得非常逼真,几乎可以以假乱真。而鉴赏家的鉴别能力也变得非常强,能识别出最细微的伪造痕迹。
关键点
生成器(艺术家):学习如何生成逼真的数据。
判别器(鉴赏家):学习如何区分真实数据和生成数据。
在实际的人工智能应用中,生成器和判别器是两个神经网络。生成器的目标是生成看起来像真实数据的数据,而判别器的目标是区分真实数据和生成数据。通过这两个网络的对抗训练,生成器可以生成非常逼真的图像、音频等数据。
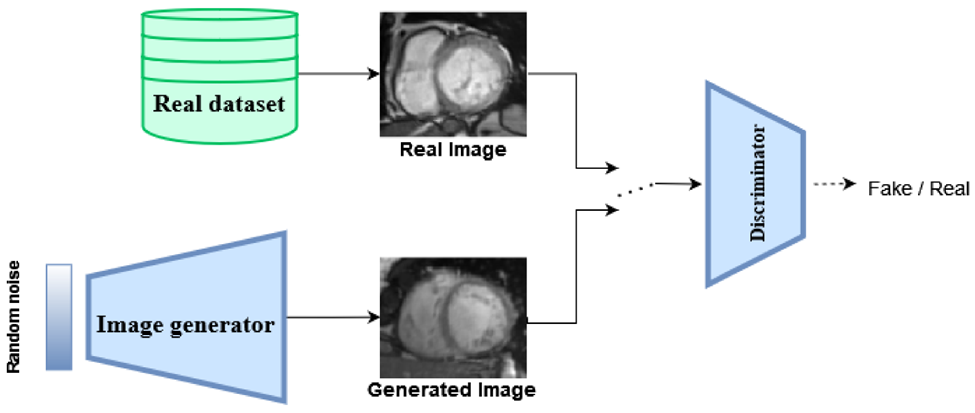
例如,GAN 可以用来生成超现实的图像、改善图像质量、图像修复以及图像风格转换、生成特定目标的分子结构等任务。
当然生成对抗网络(GAN)在药物发现中的应用也展示了其强大的生成能力,特别是在生成具有特定和多重生物活性的分子方面。通过结合先进的神经网络架构、多目标优化技术和化学约束条件,GAN可以生成具有潜在药物活性的化合物,加速药物发现过程,降低研发成本。随着技术的不断进步,GAN在制药领域的应用前景将更加广阔。
GAN自从由Ian Goodfellow等人于2014年提出以来,已经发展出许多变种…真的是许多变种和改进版本。这些变种旨在解决原始GAN模型的一些缺点,改进训练稳定性、生成质量以及应用范围。以下是一些…大概也就是60个常见的GAN变种及其特点:
1. DCGAN (Deep Convolutional GAN)
特点:DCGAN是将卷积神经网络(CNN)应用于GAN的一种变种。生成器和判别器都使用深层卷积网络来处理图像数据。
优点:通过使用卷积层,DCGAN能够更好地捕捉图像的空间特性,提高生成图像的质量和分辨率。
应用:DCGAN广泛应用于图像生成和图像修复等任务中。
引用:Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv preprint arXiv:1511.06434.
2. LSGAN (Least Squares GAN)
特点:LSGAN使用均方误差(MSE)代替传统GAN中的交叉熵损失函数。生成器和判别器的损失函数分别为:
判别器损失:( L_D = \frac{1}{2} \mathbb{E}{x \sim p{data}(x)} [(D(x) - 1)^2] + \frac{1}{2} \mathbb{E}{z \sim p{z}(z)} [D(G(z))^2] )
生成器损失:( L_G = \frac{1}{2} \mathbb{E}{z \sim p{z}(z)} [(D(G(z)) - 1)^2] )
优点:通过使用均方误差,LSGAN能够减少训练不稳定性和模式崩溃现象,提高生成样本的质量。
应用:LSGAN适用于图像生成、图像到图像的转换等任务。
引用:Mao, X., Li, Q., Xie, H., Lau, R. Y., Wang, Z., & Smolley, S. P. (2016). Least Squares Generative Adversarial Networks. arXiv preprint arXiv:1611.04076.
3. WGAN (Wasserstein GAN)
特点:WGAN引入了Wasserstein距离(又称地球移动距离)来度量生成分布与真实分布之间的差异,替代了传统的JS散度。WGAN引入了权重裁剪技术来保持1-Lipschitz连续性。
优点:WGAN显著提高了GAN的训练稳定性,减少了模式崩溃现象。
应用:WGAN广泛应用于图像生成、文本生成等任务。
引用:Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN. arXiv preprint arXiv:1701.07875.
4. WGAN-GP (WGAN with Gradient Penalty)
特点:WGAN-GP改进了WGAN中的权重裁剪方法,采用梯度惩罚技术来保证1-Lipschitz连续性。
优点:通过梯度惩罚,WGAN-GP进一步提高了训练稳定性和生成样本的质量,避免了权重裁剪带来的问题。
应用:WGAN-GP广泛应用于高质量图像生成、视频生成等任务。
引用:Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., & Courville, A. (2017). Improved Training of Wasserstein GANs. arXiv preprint arXiv:1704.00028.
5. ACGAN (Auxiliary Classifier GAN)
特点:ACGAN通过在生成器和判别器中加入辅助分类器,使得生成器不仅生成逼真的样本,还能生成具有特定类别标签的样本。判别器不仅判断样本真假,还要预测样本的类别。
优点:通过加入辅助分类器,ACGAN可以生成具有明确类别标签的样本,提高了生成样本的多样性和质量。
应用:ACGAN广泛应用于图像生成、数据增强等任务,尤其适用于需要生成具有特定类别的样本场景。
引用:Odena, A., Olah, C., & Shlens, J. (2017). Conditional Image Synthesis with Auxiliary Classifier GANs. arXiv preprint arXiv:1610.09585.
6. CycleGAN
特点:CycleGAN用于无监督的图像到图像的转换任务。通过引入循环一致性损失(cycle consistency loss),CycleGAN能够在没有成对训练数据的情况下进行图像风格转换。
优点:CycleGAN不需要成对的训练数据,可以在两种图像域之间进行高质量的转换,如将白天的照片转换为夜晚的照片,或将马的照片转换为斑马的照片。
应用:CycleGAN广泛应用于图像风格转换、图像修复、图像增强等任务。
引用:Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv preprint arXiv:1703.10593.
7. BigGAN
特点:BigGAN通过增加模型规模和训练数据量,显著提高了生成图像的质量。BigGAN在生成器和判别器中使用了更多的卷积层和更大的模型容量。
优点:通过使用更大的模型和更多的数据,BigGAN可以生成高分辨率、高质量的图像,达到了目前最好的生成效果之一。
应用:BigGAN广泛应用于高质量图像生成、大规模数据增强等任务。
引用:Brock, A., Donahue, J., & Simonyan, K. (2018). Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv preprint arXiv:1809.11096.
8. StyleGAN
特点:StyleGAN通过引入样式转移技术,将生成器的输入分为样式(style)和随机噪声,从而实现对生成图像风格的细粒度控制。StyleGAN还引入了渐进式生长技术(progressive growing),逐步增加生成图像的分辨率。
优点:StyleGAN能够生成具有细致风格控制的高质量图像,解决了传统GAN在风格和细节控制方面的不足。
应用:StyleGAN广泛应用于高质量图像生成、面部图像生成、风格迁移等任务。其生成的图像在细节和风格方面具有高度的可控性和真实性。
引用:Karras, T., Laine, S., & Aila, T. (2018). A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv preprint arXiv:1812.04948.
9. SAGAN (Self-Attention GAN)
特点:SAGAN引入了自注意力机制(self-attention mechanism)和谱归一化(spectral normalization)技术,使生成器和判别器能够更好地捕捉长距离依赖关系和全局特征。
优点:通过自注意力机制,SAGAN可以生成更加一致和协调的图像细节,提高图像生成质量,特别是在大尺度图像生成方面表现突出。
应用:SAGAN适用于高分辨率图像生成、视频生成等需要捕捉全局特征的任务。
引用:Zhang, H., Goodfellow, I., Metaxas, D., & Odena, A. (2018). Self-Attention Generative Adversarial Networks. arXiv preprint arXiv:1805.08318.
10. PGGAN (Progressive Growing of GANs)
特点:PGGAN采用渐进式生长技术,从低分辨率开始训练生成器和判别器,逐步增加图像的分辨率。这样可以显著提高训练的稳定性和生成图像的质量。
优点:通过渐进式生长,PGGAN可以生成高分辨率、高质量的图像,避免了直接训练高分辨率图像时的训练不稳定性问题。
应用:PGGAN广泛应用于高分辨率图像生成、数据增强等任务。
引用:Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017). Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv preprint arXiv:1710.10196.
11. Conditional GAN (cGAN)
特点:cGAN通过在生成器和判别器中引入条件信息(如类别标签),使得生成器能够生成具有特定属性的样本。生成器和判别器都接受附加的条件输入,条件输入可以是图像标签、文本描述等。
优点:cGAN可以生成具有特定属性或标签的样本,增强了生成的可控性和多样性。
应用:cGAN广泛应用于图像生成、图像修复、图像到图像的转换等任务。
引用:Mirza, M., & Osindero, S. (2014). Conditional Generative Adversarial Nets. arXiv preprint arXiv:1411.1784.
12. InfoGAN
特点:InfoGAN通过最大化生成样本与潜在变量之间的互信息,增强生成样本的可解释性和多样性。InfoGAN在生成器中引入了潜在变量,并通过互信息正则化来控制生成样本的特性。
优点:InfoGAN能够生成具有明确可控特性的样本,提高生成样本的多样性和可解释性。
应用:InfoGAN适用于需要控制生成样本特性的任务,如图像生成、数据增强和特征学习等。
引用:Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv preprint arXiv:1606.03657.
13. SRGAN (Super-Resolution GAN)
特点:SRGAN专门用于图像超分辨率任务,通过生成高分辨率图像从低分辨率图像中恢复细节。SRGAN引入了感知损失(perceptual loss),包括内容损失和对抗损失,来提高生成图像的视觉质量。
优点:SRGAN能够生成高质量的超分辨率图像,显著提高了低分辨率图像的清晰度和细节。
应用:SRGAN广泛应用于图像超分辨率、图像增强和图像修复等任务。
引用:Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., ... & Shi, W. (2017). Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. arXiv preprint arXiv:1609.04802.
14. StackGAN
特点:StackGAN通过分阶段生成图像,第一阶段生成粗略的低分辨率图像,第二阶段根据低分辨率图像生成高分辨率图像。StackGAN还引入了文本条件来生成具有特定描述的图像。
优点:通过分阶段生成,StackGAN能够生成高分辨率、细节丰富的图像,同时通过文本条件控制图像内容。
应用:StackGAN适用于文本到图像生成、图像增强等任务。
引用:Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., & Metaxas, D. (2017). StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. arXiv preprint arXiv:1612.03242.
15. StarGAN
特点:StarGAN是一种多域图像到图像翻译模型,能够在多个图像域之间进行转换。StarGAN通过一个统一的生成器和判别器架构实现多个域的图像转换,并使用域标签来控制目标域。
优点:StarGAN能够在多个图像域之间进行高质量的图像转换,避免了为每个转换任务训练单独的模型。
应用:StarGAN广泛应用于面部属性编辑、图像风格转换等任务。
引用:Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2018). StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. arXiv preprint arXiv:1711.09020.
16. pix2pix
特点:pix2pix是一种条件GAN,用于成对图像到图像的转换任务。pix2pix在生成器和判别器中引入条件图像,使得生成器能够从输入图像生成目标图像。
优点:pix2pix能够在成对图像数据上进行高质量的图像到图像转换任务,如图像修复、图像着色、图像去噪等。
应用:pix2pix广泛应用于图像到图像的转换任务,包括图像修复、图像着色、图像去噪和风格转换等。
引用:Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-Image Translation with Conditional Adversarial Networks. arXiv preprint arXiv:1611.07004.
17. TGAN (Temporal GAN)
特点:TGAN针对视频生成任务,通过结合时间序列信息生成连续的帧。TGAN使用递归神经网络(RNN)或长短期记忆网络(LSTM)来处理时间序列数据。
优点:TGAN能够生成连续的、高质量的视频帧,捕捉时间序列中的动态变化。
应用:TGAN广泛应用于视频生成、动作预测和时间序列数据的生成等任务。
引用:Saito, M., Matsumoto, E., & Saito, S. (2017). Temporal Generative Adversarial Nets with Singular Value Clipping. arXiv preprint arXiv:1611.06624.
18. Text-to-Image GAN
特点:Text-to-Image GAN专注于从文本描述生成图像。通过在生成器中结合文本嵌入向量,Text-to-Image GAN能够生成与描述相符的图像。
优点:Text-to-Image GAN可以根据自然语言描述生成逼真的图像,增强了生成模型的可控性。
应用:Text-to-Image GAN广泛应用于文本到图像生成、艺术创作和数据增强等任务。
引用:Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., & Lee, H. (2016). Generative Adversarial Text to Image Synthesis. arXiv preprint arXiv:1605.05396.
19. MUNIT (Multimodal Unsupervised Image-to-Image Translation)
特点:MUNIT能够在没有成对训练数据的情况下进行多模态图像到图像的转换。通过分离内容和风格编码,MUNIT实现了图像风格和内容的独立控制。
优点:MUNIT在没有成对数据的情况下,实现了多模态和高质量的图像转换,增强了生成的灵活性和多样性。
应用:MUNIT广泛应用于图像风格转换、图像增强和无监督图像到图像转换等任务。
引用:Huang, X., Liu, M. Y., Belongie, S., & Kautz, J. (2018). Multimodal Unsupervised Image-to-Image Translation. arXiv preprint arXiv:1804.04732.
20. GauGAN
特点:GauGAN通过引入基于生成对抗网络的绘画工具,使用户能够通过草图和标签生成逼真的图像。GauGAN结合了条件生成和图像编辑技术,允许用户进行交互式图像生成。
优点:GauGAN提供了高效的图像生成和编辑工具,使用户能够直观地创建和修改图像内容。
应用:GauGAN广泛应用于图像创作、虚拟环境生成、数据增强和图像编辑等任务。它特别适用于需要快速生成逼真图像的场景,比如游戏开发和电影制作。
引用:Park, T., Liu, M. Y., Wang, T. C., & Zhu, J. Y. (2019). Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
21. ProGAN (Progressive Growing of GANs)
特点:ProGAN采用逐步增加生成图像分辨率的训练方式,从低分辨率开始,逐步增加到高分辨率。这样的方法提高了训练的稳定性和生成图像的质量。
优点:通过渐进式生长,ProGAN能够生成高分辨率且质量非常高的图像,解决了传统GAN在高分辨率图像生成时的训练不稳定性问题。
应用:ProGAN广泛应用于高分辨率图像生成、数据增强和图像修复等任务。
引用:Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017). Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv preprint arXiv:1710.10196.
22. MSG-GAN (Multi-Scale Gradient GAN)
特点:MSG-GAN通过多尺度梯度约束来提高生成图像的质量和训练的稳定性。生成器和判别器在不同尺度上进行交互,增强了生成图像的细节和全局一致性。
优点:MSG-GAN能够生成高质量、细节丰富的图像,并显著提高了训练的稳定性。
应用:MSG-GAN适用于高分辨率图像生成、图像修复和图像增强等任务。
引用:Karnewar, A., & Wang, O. (2020). MSG-GAN: Multi-Scale Gradient GAN for Stable Image Synthesis. arXiv preprint arXiv:2003.03696.
23. FID-GAN (Fréchet Inception Distance GAN)
特点:FID-GAN通过引入Fréchet Inception Distance (FID)作为评价标准,来衡量生成图像的质量和多样性。FID结合了生成图像和真实图像的特征分布,为GAN的训练提供了更可靠的评价指标。
优点:通过使用FID-GAN,可以获得更高质量和多样性的生成图像,同时优化了GAN的训练过程。
应用:FID-GAN广泛应用于图像生成、质量评价和生成模型的优化等任务。
引用:Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., & Hochreiter, S. (2017). GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems (NeurIPS).
24. EBGAN (Energy-Based GAN)
特点:EBGAN将判别器视为一个能量函数,通过最小化生成样本的能量来优化生成器。EBGAN采用能量函数来度量生成样本和真实样本之间的差异。
优点:通过能量函数,EBGAN提供了一种新的度量生成样本质量的方法,增强了训练的稳定性。
应用:EBGAN适用于图像生成、数据增强和无监督学习等任务。
引用:Zhao, J., Mathieu, M., & LeCun, Y. (2016). Energy-based Generative Adversarial Network. arXiv preprint arXiv:1609.03126.
25. AdaGAN (Adaptive GAN)
特点:AdaGAN通过自适应地调整生成器和判别器的训练速率和更新频率,来提高训练的稳定性和生成图像的质量。AdaGAN动态调整训练参数,以适应不同的训练阶段和数据分布。
优点:AdaGAN通过自适应调整训练参数,提高了GAN训练的稳定性和生成样本的质量,适应了不同训练阶段的需求。
应用:AdaGAN广泛应用于图像生成、图像修复和数据增强等任务。
引用:Tolstikhin, I. O., Gelly, S., Bousquet, O., & Schoelkopf, B. (2017). Adagan: Boosting generative models. In Advances in Neural Information Processing Systems (NeurIPS).
26. MoCoGAN (Motion and Content GAN)
特点:MoCoGAN将视频生成任务分解为内容生成和运动生成,通过独立的网络生成视频的内容和运动信息。MoCoGAN使用递归神经网络(RNN)来捕捉视频帧之间的时间相关性。
优点:MoCoGAN能够生成具有连贯时间序列的高质量视频,捕捉视频中的动态变化。
应用:MoCoGAN广泛应用于视频生成、动作预测和时间序列数据的生成等任务。
引用:Tulyakov, S., Liu, M. Y., Yang, X., & Kautz, J. (2018). MoCoGAN: Decomposing Motion and Content for Video Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
27. VAE-GAN (Variational Autoencoder GAN)
特点:VAE-GAN结合了变分自编码器(VAE)和GAN的优点,通过VAE的编码器生成潜在变量,并通过GAN的生成器生成样本。VAE-GAN利用VAE的重构损失和GAN的对抗损失,提高生成样本的质量和多样性。
优点:VAE-GAN结合了VAE的稳定性和GAN的生成能力,能够生成高质量和多样性的样本。
应用:VAE-GAN广泛应用于图像生成、数据增强和无监督学习等任务。
引用:Larsen, A. B. L., Sønderby, S. K., Larochelle, H., & Winther, O. (2015). Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300.
28. D2GAN (Dual Discriminator GAN)
特点:D2GAN使用两个判别器来评估生成样本的质量,一个判别器评估生成样本的真实度,另一个判别器评估生成样本的多样性。通过双判别器的反馈,D2GAN能够生成高质量和多样性的样本。
优点:D2GAN通过双判别器机制,提高了生成样本的质量和多样性,增强了训练的稳定性。
应用:D2GAN广泛应用于图像生成、数据增强和多样性评估等任务
引用:Nguyen, T., Le, T., Vu, H., & Phung, D. (2017). Dual Discriminator Generative Adversarial Nets. arXiv preprint arXiv:1709.03831.
29. MolGAN
特点:MolGAN使用生成对抗网络生成分子图结构,并结合了强化学习的策略,以优化生成分子的特定性质(如药物活性、毒性等)。该模型生成的分子图结构包含节点(原子)和边(化学键),并使用强化学习来指导生成过程,使生成的分子具有所需的特性。
优点:MolGAN能够生成结构有效且具有特定性质的分子,适用于药物发现和材料设计等领域。
应用:MolGAN广泛应用于药物设计、材料科学、新分子发现等任务。
引用:De Cao, N., & Kipf, T. (2018). MolGAN: An implicit generative model for small molecular graphs. arXiv preprint arXiv:1805.11973.
30. CycleGAN
特点:CycleGAN通过循环一致性损失(cycle-consistency loss)进行无监督图像到图像的转换。CycleGAN不需要成对的训练数据,通过在两个域之间的循环转换实现高质量的图像转换。
优点:CycleGAN能够在没有成对数据的情况下,实现两个域之间的高质量图像转换,广泛应用于风格转换、图像增强等任务。
应用:CycleGAN广泛应用于无监督图像到图像转换、艺术风格转换、图像增强等任务。
引用:Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
31. StyleGAN2
特点:StyleGAN2是StyleGAN的改进版本,通过重新设计生成器架构,消除特定的伪影(artifact)并提高图像质量。StyleGAN2引入了正则化技术和更先进的网络设计,进一步提升了生成的稳定性和图像质量。
优点:StyleGAN2在生成图像的细节和质量上有显著提升,能够生成更加逼真和高分辨率的图像。
应用:StyleGAN2广泛应用于高质量图像生成、面部图像生成、艺术创作等任务。
引用:Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2020). Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
32. SNGAN (Spectral Normalization GAN)
特点:SNGAN通过引入谱归一化(spectral normalization)技术来稳定GAN的训练过程。谱归一化用于约束判别器的权重,防止梯度爆炸和消失问题。
优点:SNGAN提高了训练的稳定性,能够生成高质量的图像,适用于各种图像生成任务。
应用:SNGAN广泛应用于图像生成、数据增强、无监督学习等任务。
引用:Miyato, T., Kataoka, T., Koyama, M., & Yoshida, Y. (2018). Spectral
Normalization for Generative Adversarial Networks. In International Conference on Learning Representations (ICLR).
33. SAGAN (Self-Attention GAN)
特点:SAGAN通过引入自注意力机制(self-attention mechanism)来捕捉图像中的长距离依赖关系。这种机制使得生成器能够更好地理解和生成全局一致的图像细节。
优点:SAGAN能够生成更具全局一致性和细节丰富的图像,特别适用于复杂场景的图像生成。
应用:SAGAN广泛应用于高质量图像生成、图像细节增强和复杂场景的图像生成等任务。
引用:Zhang, H., Goodfellow, I., Metaxas, D., & Odena, A. (2019). Self-Attention Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning (ICML).
34. PGGAN (Progressive Growing of GANs)
特点:PGGAN通过逐步增加生成图像的分辨率来稳定训练过程,从低分辨率开始,逐步增加到高分辨率。PGGAN的方法提高了训练的稳定性和生成图像的质量。
优点:通过渐进式生长,PGGAN能够生成高分辨率且质量非常高的图像,解决了传统GAN在高分辨率图像生成时的训练不稳定性问题。
应用:PGGAN广泛应用于高分辨率图像生成、数据增强和图像修复等任务。
引用:Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017). Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv preprint arXiv:1710.10196.
35. CT-GAN (Conditional Temporal GAN)
特点:CT-GAN用于生成基于时间序列数据的样本,通过结合条件生成和时间序列信息来生成与特定条件相符的时间序列数据。CT-GAN使用递归神经网络(RNN)来处理时间序列数据。
优点:CT-GAN能够生成具有时间序列特征的高质量数据,适用于各种时间序列生成任务。
应用:CT-GAN广泛应用于时间序列数据生成、动作预测、金融数据模拟等任务。
引用:Mogren, O. (2016). C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv preprint arXiv:1611.09904.
36. VQ-VAE-2 (Vector Quantized Variational Autoencoder 2)
特点:VQ-VAE-2结合了变分自编码器(VAE)和向量量化技术,通过分层架构生成高质量的图像。VQ-VAE-2使用离散潜在空间来提高生成的稳定性和图像质量。
优点:VQ-VAE-2能够生成高分辨率、细节丰富的图像,适用于各种图像生成任务。
应用:VQ-VAE-2广泛应用于高质量图像生成、数据压缩、图像修复等任务。
引用:Razavi, A., van den Oord, A., & Vinyals, O. (2019). Generating Diverse High-Fidelity Images with VQ-VAE-2. In Advances in Neural Information Processing Systems (VQ-VAE-2). arXiv preprint arXiv:1906.00446.
37. U-GAT-IT (Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation)
特点:U-GAT-IT通过引入自适应层-实例归一化(Adaptive Layer-Instance Normalization, AdaLIN)和自注意力机制,来提高图像到图像转换任务的性能。U-GAT-IT能够在无监督的情况下进行高质量的图像转换。
优点:U-GAT-IT在处理图像风格转换和图像增强任务时,能够生成具有细节和一致性的高质量图像。
应用:U-GAT-IT广泛应用于图像风格转换、图像增强和无监督图像到图像转换等任务。
引用:Kim, J., Kim, M., Kang, H., & Lee, K. (2019). U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. In International Conference on Learning Representations (ICLR).
38. FUNIT (Few-Shot Unsupervised Image-to-Image Translation)
特点:FUNIT能够在少量示例下进行图像到图像的转换。通过少量目标域图像示例,FUNIT能够生成与目标域一致的图像。FUNIT使用少样本学习技术来实现高效的图像转换。
优点:FUNIT在少样本情况下,能够进行高质量的图像转换,增强了模型的泛化能力。
应用:FUNIT广泛应用于少样本图像风格转换、图像增强和数据扩充等任务。
引用:Liu, M. Y., Huang, X., Mallya, A., Karras, T., Aila, T., Lehtinen, J., & Kautz, J. (2019). Few-Shot Unsupervised Image-to-Image Translation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
39. StarGAN
特点:StarGAN能够同时进行多域图像到图像的转换,通过一个生成器和一个判别器来处理多个域之间的转换。StarGAN使用条件生成技术来实现多域图像转换。
优点:StarGAN在处理多域图像转换任务时,能够生成高质量的图像,并且模型结构相对简单。
应用:StarGAN广泛应用于多域图像风格转换、图像增强和多任务学习等任务。
引用:Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2018). StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
40. StyleGAN3
特点:StyleGAN3是StyleGAN2的改进版本,通过引入新型网络架构和正则化技术,进一步提升了生成图像的质量和一致性。StyleGAN3解决了一些在StyleGAN2中存在的结构性伪影问题。
优点:StyleGAN3能够生成更高质量、更一致的图像,特别是在处理复杂场景和细节方面表现出色。
应用:StyleGAN3广泛应用于高分辨率图像生成、面部生成、艺术创作、虚拟现实等任务。
引用:Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J., & Aila, T. (2021). Alias-Free Generative Adversarial Networks. In Advances in Neural Information Processing Systems (NeurIPS).
41. SEGAN (Speech Enhancement GAN)
特点:SEGAN是一种用于语音增强的生成对抗网络,通过学习去噪过程来提高语音质量。SEGAN使用一个生成器来去噪语音样本,一个判别器来评估去噪效果。
优点:SEGAN能够显著提高受噪声污染的语音样本的质量,特别适用于实时语音增强任务。
应用:SEGAN广泛应用于语音去噪、语音增强、语音识别前处理等任务。
引用:Pascual, S., Bonafonte, A., & Serrà, J. (2017). SEGAN: Speech Enhancement Generative Adversarial Network. In Interspeech.
42. AttnGAN (Attentional GAN)
特点:AttnGAN通过引入注意力机制来生成基于文本描述的高质量图像。该模型能够逐步生成细节丰富的图像,确保生成的图像与输入文本描述高度一致。
优点:AttnGAN在文本到图像生成任务中表现出色,能够生成与文本描述高度一致的高质量图像。
应用:AttnGAN广泛应用于文本到图像生成、图像描述生成、艺术创作等任务。
引用:Xu, T., Zhang, P., Huang, Q., Zhang, H., Gan, Z., Huang, X., & He, X. (2018). AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
43. Text2Art (文本到艺术生成)
特点:Text2Art通过生成对抗网络将文本描述转换为艺术风格的图像。该模型结合了文本嵌入和艺术风格转换技术,生成具有艺术感和风格化的图像。
优点:Text2Art能够将文本描述转换为具有艺术风格的图像,适用于艺术创作和广告设计等领域。
应用:Text2Art广泛应用于艺术创作、广告设计、个性化图像生成等任务。
引用:Elgammal, A., Liu, B., Elhoseiny, M., & Mazzone, M. (2017). CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms. In ICCC.
44. DiscoGAN (Discover Cross-Domain Relations with GAN)
特点:DiscoGAN通过发现不同域之间的关系,实现跨域图像转换。该模型在无监督的情况下学习不同域之间的映射关系,实现图像的风格转换和内容迁移。
优点:DiscoGAN在跨域图像转换任务中表现出色,能够生成高质量的跨域图像。
应用:DiscoGAN广泛应用于跨域图像风格转换、内容迁移、无监督学习等任务。
引用:Kim, T., Cha, M., Kim, H., Lee, J. K., & Kim, J. (2017 ). Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning (ICML).
45. MUNIT (Multimodal Unsupervised Image-to-Image Translation)
特点:MUNIT通过引入多模态的表示方式,实现无监督的图像到图像转换。该模型将图像分解为内容编码和风格编码,从而实现多模态的图像生成。
优点:MUNIT能够生成多种风格的图像,适用于多模态图像转换任务,具有较强的灵活性和多样性。
应用:MUNIT广泛应用于无监督图像风格转换、多模态图像生成、艺术创作等任务。
引用:Huang, X., Liu, M. Y., Belongie, S., & Kautz, J. (2018). Multimodal Unsupervised Image-to-Image Translation. In European Conference on Computer Vision (ECCV).
46. GauGAN
特点:GauGAN通过使用生成对抗网络实现基于草图的图像生成。用户可以通过绘制简单的草图和选择相应的图像样式,生成高质量的图像。
优点:GauGAN使得用户能够通过简单的草图创建复杂的图像,生成过程直观且高效。
应用:GauGAN广泛应用于艺术创作、建筑设计、虚拟现实内容生成等任务。
引用:Park, T., Liu, M. Y., Wang, T. C., & Zhu, J. Y. (2019). Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
47. GANomaly
特点:GANomaly是一种用于异常检测的生成对抗网络。通过学习正常数据的分布,GANomaly能够检测出与正常数据分布不一致的异常样本。
优点:GANomaly在无监督的情况下能够进行高效的异常检测,适用于各种异常检测任务。
应用:GANomaly广泛应用于工业检测、医疗图像分析、网络安全等领域的异常检测任务。
引用:Akcay, S., Atapour-Abarghouei, A., & Breckon, T. P. (2018). GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training. In Asian Conference on Computer Vision (ACCV).
48. Image2Image (Pix2Pix)
特点:Pix2Pix是一种基于条件生成对抗网络的图像到图像转换方法。通过成对的图像数据训练模型,实现高质量的图像转换。
优点:Pix2Pix能够在有监督的情况下生成高质量的图像,适用于多种图像转换任务。
应用:Pix2Pix广泛应用于图像修复、图像去噪、风格转换等任务。
引用:Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
49. ESRGAN (Enhanced Super-Resolution GAN)
特点:ESRGAN通过引入改进的生成对抗网络架构,实现高质量的图像超分辨率重建。ESRGAN使用残差块和对抗学习技术,显著提高了图像超分辨率重建的效果。
优点:ESRGAN能够生成细节丰富、质量较高的超分辨率图像,适用于各种图像增强和细节恢复任务。
应用:ESRGAN广泛应用于图像超分辨率重建、图像增强、细节恢复等任务。
引用:Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., ... & Tang, X. (2018). ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops.
50. TecoGAN (Temporally Coherent GAN)
特点:TecoGAN通过引入时间一致性损失,实现视频超分辨率重建。该模型在生成高分辨率视频帧时,能够保持帧间的时间一致性,避免闪烁等伪影。
优点:TecoGAN能够生成时间一致性好的高分辨率视频,适用于视频超分辨率重建和视频增强任务。
应用:TecoGAN广泛应用于视频超分辨率重建、视频增强、视频修复等任务。
引用:Chu, M., Xie, H., Mayer, J., Vetter, T., & Dai, D. (2018). Temporally Coherent GANs for Video Super-Resolution (TecoGAN). arXiv preprint arXiv:1811.09393.
51. DeblurGAN
特点:DeblurGAN通过生成对抗网络实现图像去模糊。该模型使用条件生成对抗网络来学习模糊图像和清晰图像之间的映射关系,从而生成去模糊后的高质量图像。
优点:DeblurGAN能够显著提高模糊图像的清晰度,适用于各种图像去模糊任务。
应用:DeblurGAN广泛应用于图像去模糊、图像增强、图像修复等任务。
引用:Kupyn, O., Budzan, V., Mykhailych, M., Mishkin, D., & Matas, J. (2018). DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
52. GAN-based Image Inpainting
特点:基于GAN的图像修复技术通过生成对抗网络来修复损坏或缺失的图像区域。该模型学习图像的全局结构和局部细节,从而生成自然的修复结果。
优点:基于GAN的图像修复能够生成高质量的修复结果,适用于各种图像修复任务。
应用:广泛应用于图像修复、图像增强、艺术修复等任务。
引用:Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., & Huang, T. S. (2018). Generative Image Inpainting with Contextual Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
53. InGAN (Internal Learning GAN)
特点:InGAN通过内部学习机制,实现图像的自适应生成和编辑。该模型在单张图像内部进行训练,学习图像的内部结构和纹理,从而生成相似风格的图像或进行图像编辑。
优点:InGAN能够在单张图像的基础上进行高质量的生成和编辑,适用于图像放大、图像修复和图像风格迁移等任务。
应用:InGAN广泛应用于图像放大、图像修复、艺术创作和图像编辑等领域。
引用:Shocher, A., Bagon, S., Isola, P., & Irani, M. (2018). "InGAN: Capturing and Retargeting the "DNA" of a Natural Image". In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
54. CycleGAN
特点:CycleGAN通过引入循环一致性损失,实现无监督的图像到图像转换。该模型能够在没有成对数据的情况下,学习两个域之间的映射关系,从而进行图像转换。
优点:CycleGAN在没有成对数据的情况下,能够进行高质量的图像转换,适用于无监督图像转换任务。
应用:CycleGAN广泛应用于图像风格转换、图像增强、图像修复等任务。
引用:Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
55. Recycle-GAN
特点:Recycle-GAN通过引入时间一致性和循环一致性损失,实现视频到视频的无监督转换。该模型能够在没有成对数据的情况下,学习视频域之间的映射关系,从而进行视频转换。
优点:Recycle-GAN能够在无监督的情况下进行高质量的视频转换,保持帧间一致性,适用于视频风格转换和视频增强任务。
应用:Recycle-GAN广泛应用于视频风格转换、视频增强、视频修复等任务。
引用:Bansal, A., Ma, S., Ramanan, D., & Sheikh, Y. (2018). Recycle-GAN: Unsupervised Video Retargeting. In Proceedings of the European Conference on Computer Vision (ECCV).
56. 3D-GAN
特点:3D-GAN通过生成对抗网络生成三维物体模型。该模型使用三维卷积神经网络来生成三维体素网格,能够生成高质量的三维物体。
优点:3D-GAN能够生成细节丰富的三维物体模型,适用于三维建模和虚拟现实等任务。
应用:3D-GAN广泛应用于三维建模、虚拟现实、游戏开发、自动驾驶仿真等领域。
引用:Wu, J., Zhang, C., Xue, T., Freeman, B., & Tenenbaum, J. (2016). Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. In Advances in Neural Information Processing Systems (NeurIPS).
57. InfoGAN
特点:InfoGAN通过引入信息最大化的目标,增强生成对抗网络的解释性。该模型在生成过程中引入了信息约束,使得生成的样本具有更高的可解释性。
优点:InfoGAN能够生成具有明确语义信息的样本,适用于需要高解释性的生成任务ogressive GAN (ProGAN)
特点:ProGAN通过逐步增加生成器和判别器的分辨率,生成高质量的图像。该模型在训练过程中从低分辨率开始,逐步增加分辨率,使得训练过程更加稳定和高效。
优点:ProGAN能够生成高分辨率、高质量的图像,适用于图像生成和图像增强任务。
应用:ProGAN广泛应用于高分辨率图像生成、艺术创作、虚拟现实等领域。
引用:Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017). Progressive Growing of GANs for Improved Quality, Stability, and Variation. In International Conference on Learning Representations (ICLR).
59. BigGAN
特点:BigGAN通过引入更大的模型和更复杂的训练方法,显著提高了生成图像的质量。BigGAN使用更大的批量大小和更长的训练时间,生成了高分辨率、高质量的图像。
优点:BigGAN生成的图像质量极高,适用于需要高质量图像生成的任务。
应用:BigGAN广泛应用于高分辨率图像生成、艺术创作、数据增强等领域。
引用:Brock, A., Donahue, J., & Simonyan, K. (2018). Large Scale GAN Training for High Fidelity Natural Image Synthesis. In International Conference on Learning Representations (ICLR).
60. SinGAN
特点:SinGAN通过在单张图像上进行训练,实现图像生成和编辑。该模型能够生成与输入图像风格一致的新图像,适用于单一图像的学习和生成。
优点:SinGAN在不需要大量数据的情况下,能够生成多样化的图像,适用于图像放大、风格迁移和图像编辑等任务。
应用:SinGAN广泛应用于图像放大、图像修复、艺术创作等领域。
引用:Shaham, T. R., Dekel, T., & Michaeli, T. (2019). SinGAN: Learning a Generative Model from a Single Natural Image. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
这些生成对抗网络(GAN)模型在各自的应用领域中表现出色,推动了图像啊分子结构啊等方面生成、转换和增强等任务的发展,虽然GAN遇到过一些问题,但是在一些专有领域里,还是很好用的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









