






使用OpenAI
示例视频:
创建一个客户端:
api_key = "xxx"
client = OpenAI(api_key=api_key)进行视频理解需要使用具有视觉能力的模型,通过读取视频的帧来实现。
读取视频的帧:
video = cv2.VideoCapture("TesseractOCR图片文字识别效果.mp4")
base64Frames = []
while video.isOpened():
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
video.release()
print(len(base64Frames), "frames read.")提示词中不需要包含所有图片,可以隔一个60帧来一张:
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
"这些是视频的画面。生成一段旁白。",
*map(lambda x: {"image": x, "resize": 768}, base64Frames[0::60]),
],
},
]
params = {
"model": "gpt-4o",
"messages": PROMPT_MESSAGES,
"max_tokens": 500,
}
result = client.chat.completions.create(**params)
print(result.choices[0].message.content)效果:
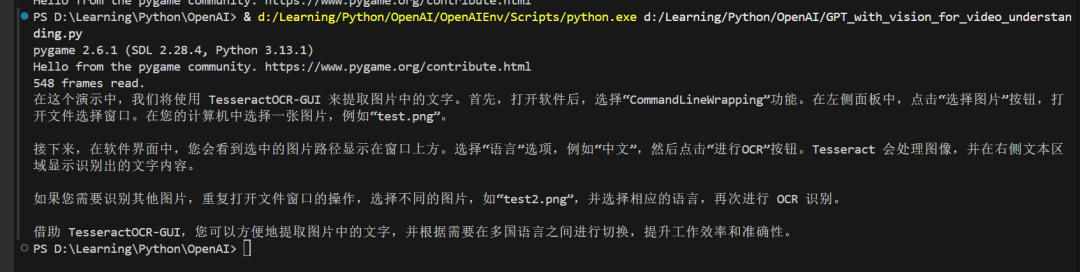
然后使用TTS模型进行文本转语言,再使用pygame直接播放:
response = requests.post(
"https://api.openai.com/v1/audio/speech",
headers={
"Authorization": f"Bearer {api_key}",
},
json={
"model": "tts-1-1106",
"input": result.choices[0].message.content,
"voice": "onyx",
},
)
audio = b""
for chunk in response.iter_content(chunk_size=1024 * 1024):
audio += chunk
# 将音频数据保存到一个文件中
with open("output9.mp3", "wb") as f:
f.write(audio)
# 初始化 pygame 混音器
pygame.mixer.init()
pygame.mixer.music.load(io.BytesIO(audio))
# 播放音频
pygame.mixer.music.play()
# 等待音频播放完成
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)效果:
使用SiliconCloud
在国内使用OpenAI模型确实有一点不方便,实现这个,也可以使用硅基流动提供的模型,现在输入邀请码有14元的额度,这个额度不会过期,感兴趣可以试试,邀请链接:https://cloud.siliconflow.cn/i/Ia3zOSCU。
和上面的步骤一样,只是写法有点不一样,选一个具有视觉能力的模型:
api_key = "xxx"
client = OpenAI(api_key=api_key, base_url="https://api.siliconflow.cn/v1")
video = cv2.VideoCapture("TesseractOCR图片文字识别效果.mp4")
base64Frames = []
while video.isOpened():
success, frame = video.read()
ifnot success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
video.release()
print(len(base64Frames), "frames read.")
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
{"type": "text", "text": "这些是视频的画面。生成一段旁白。"},
] + [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image}", "detail": "low"}}
for image in base64Frames[0::60]
],
},
]
params = {
"model": "Qwen/Qwen2-VL-72B-Instruct",
"messages": PROMPT_MESSAGES,
"max_tokens": 500,
}
result = client.chat.completions.create(**params)
text = result.choices[0].message.content
print(text)效果:

再使用一个TTS模型生成语言,这里也是使用pygame直接播放:
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B", # 支持 fishaudio / GPT-SoVITS / CosyVoice2-0.5B 系列模型
voice="FunAudioLLM/CosyVoice2-0.5B:alex", # 系统预置音色
# 用户输入信息
input=f"{text}",
response_format="mp3"# 支持 mp3, wav, pcm, opus 格式
) as response:
response.stream_to_file("output10.mp3")
# 初始化 pygame 混音器
pygame.mixer.init()
pygame.mixer.music.load("output10.mp3")
# # 播放音频
pygame.mixer.music.play()
# # 等待音频播放完成
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)效果:
还可以上传音色,我试了一下,真的很像,感兴趣可以自己去试试。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









