






最近在给企业、政府讲解B端或者G端大模型应用的时候普遍会有这样一个问题:通用大模型好是好,但是怎么把企业自己的知识安全灌给大模型,让自己部署的大模型更懂自己呢?我们用一张图和一段文字来说清楚这事儿。
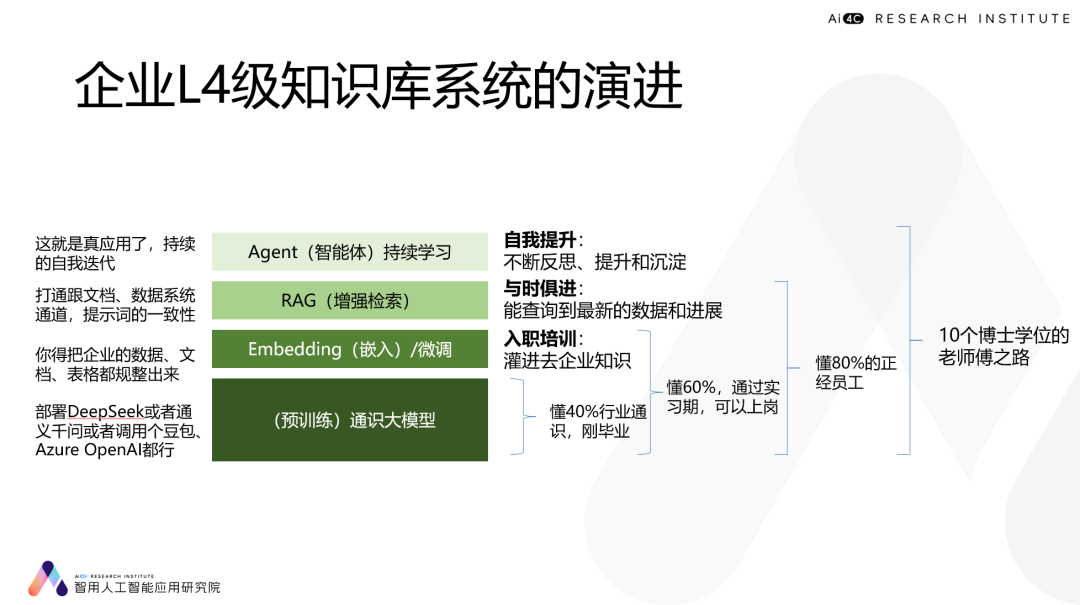
企业真的要上DeepSeek一体机的话挺好,不过要区分V3和R1,R1是个推理模型,而且把推理逻辑放在模型里,你要让它能理解企业中五花八门的逻辑有一定难度。而下面这四种方法是目前你能用上的,不过经常会搞混的。
一、核心概念与技术边界区分
- 预训练(Pre-training)
- 定义
:从零开始构建模型,通过海量通用数据(如全网文本)训练底层语言表征能力。
- 典型场景
:需完全自主可控的行业基础模型研发(如金融、医疗专用大模型)。
- 技术门槛
:千亿级参数训练需万卡集群,单次训练成本超千万美元。
- 定义
:将文本映射为高维向量,用于语义相似度计算、聚类等非生成任务。
- 典型场景
:企业内部知识检索、用户意图匹配、推荐系统冷启动。
- 技术优势
:无需修改模型结构,直接调用API获取向量空间表征。
- 定义
:在预训练模型基础上,用领域数据调整参数以适应特定任务。
- 典型场景
:法律文书生成、医疗报告结构化等垂直领域生成任务。
- 数据需求
:需万级标注数据实现稳定性能提升。
- 定义
:通过检索外部知识库动态补充生成内容,实现事实性增强。
- 典型场景
:客服问答系统、实时数据报告生成、多源知识融合场景。
- 系统复杂度
:需构建向量数据库与检索排序算法联调。
二、决策四维评估模型
(通过需求优先级排序选择技术路径)
| 评估维度 | 预训练 | Embedding | 微调 | RAG |
|---|---|---|---|---|
| 数据私有化需求 | 极高 | 中 | 高 | 中(依赖外部知识库) |
| 领域专业深度 | 行业重构级 | 浅层语义理解 | 深度适配 | 动态知识扩展 |
| 实时性要求 | 无 | 高 | 中 | 极高(需秒级更新) |
| 成本投入 | 亿元级,或者千万级 | 十万级 | 百万级 | 百万级(含高级知识库建设) |
典型案例对照:
- 制造业设备手册问答
:选择RAG(动态接入最新维修记录+标准文档)
- 法律合同生成
:微调(需精准匹配法条表述风格)
- 电商评论情感分析
:Embedding(快速聚类用户反馈)
- 金融风险模型
:预训练(构建行业专属风险评估逻辑)
三、混合策略与进阶实践
- 级联式架构
前端用RAG实现事实准确性,后端用微调模型优化生成流畅度(如医疗问诊系统)
成本效益:降低30%-90%幻觉率(100%没有幻觉但凡用了大模型目前都是做不到的,别写在标书里了,控制幻觉的范围才是正道),同时减少50%标注数据需求
A[Embedding快速验证] --> B{RAG解决知识盲区}
B --> C[微调提升核心任务性能]
C --> D[预训练构建竞争壁垒] - 中小企业推荐路径
:80%企业止步于B阶段即可满足需求
- 数据泄露防护
:微调时采用差分隐私技术,RAG检索层部署内容过滤
- 模型退化监控
:设置生成质量衰退预警指标(如困惑度突变检测)
四、2025年技术融合新趋势(基于智用人工智能应用研究院研究和预判)
- MoE(混合专家)架构
将预训练基座与多个微调模块动态组合,实现多任务统一调度
MoE在大模型中和在Agent框架中(如智用AI Agent Foundry)都可以应用,但在Agent框架中更为企业可控
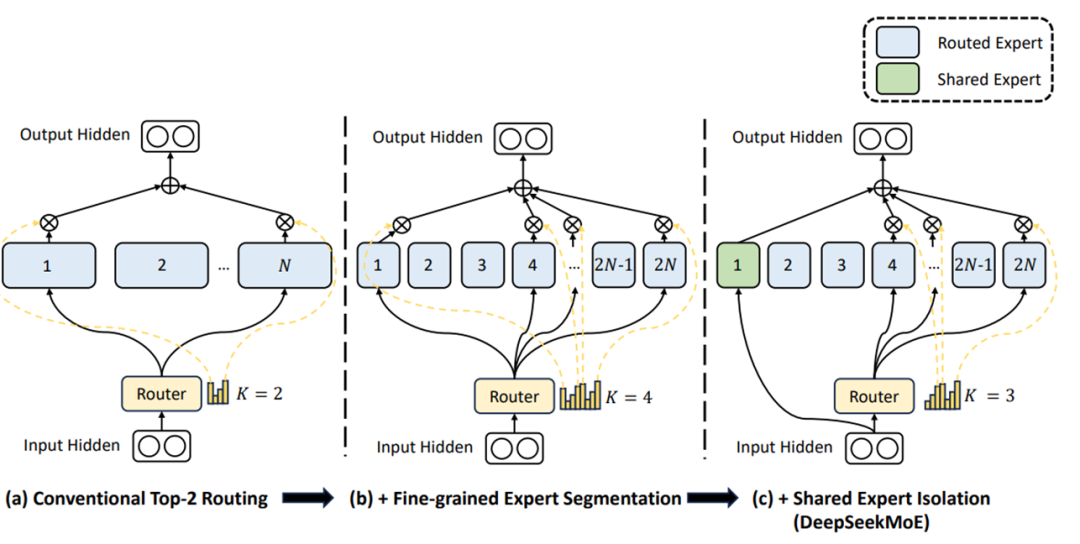
- 向量计算的发展
国内多家企业推出Embedding专用FPGA卡或向量数据库,检索延迟降至毫秒级
书写文件的工具的默认向量化,以前的Word、WPS的文档结构都老了,如果基于Transformer架构的大模型在未来还会继续发展的话,要么是微软、金山、Adobe自己出新Office,要么是创业团队出一个书写工具,让生成的文档天生就是向量,这样大家都不用费老鼻子劲切割表格、图例还不准确了。
知识库自动更新(如通过AI Agent Foundry的ACP架构或者Claude MCP架构对接企业ERP实时数据流)
检索-生成联合优化
五、决策行动清单
- 紧急项
梳理业务场景中的事实性错误容忍度(决定RAG的必要性和架构)
盘点现有数据资产的结构化程度与标注预算,无论如何,数据都要有个治理的思路
评估领域知识壁垒高度(如核电vs快消,技术路径权重差异显著)
规划3年内的算力投入预算(决定能否支撑预训练迭代)
建立生成内容合规审查链路(尤其微调/RAG可能放大偏见风险)
设计模型替换成本评估模型(避免被单一技术方案绑定)
结语:
企业需摒弃"技术崇拜",回归场景价值公式:
技术选型收益 = (任务提升效率 × 业务覆盖广度或频率) - (数据治理成本 + 系统维护复杂度)
我举过几个实际例子,如果一个提效项目看起来只有10%的效果,但每天会发生一万遍,那就是高价值场景。建议通过A/B测试对比不同方案在核心指标(如客户满意度、处理时效)上的边际收益,以数据驱动决策而非技术潮流。
欢迎在后台给我们留言,或者联系智用人工智能应用研究院,这企业级AI应用这事儿上,我们是专业的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









