






语言模型越来越受欢迎,原因之一是它们能生成自然、连贯、甚至令人印象深刻的回答。尤其在聊天对话中,我们只需要用日常语言提问,就能获得看起来很有道理的答复。但问题来了——这些回答到底靠不靠谱?这就涉及一个关键概念:groundedness(有据可依)。
什么是 groundedness?
groundedness 表示语言模型的回答是否“有根有据”,也就是:
是否基于真实、可靠的信息?
是否结合了特定语境或数据?
问题:回答可能“看着靠谱,其实是编的”
语言模型的训练数据,通常来自互联网上的大量文字。这意味着它并不了解你的具体业务或文档,回答也是“猜”出来的,甚至有时会编造不存在的东西。
例如:
我该用哪个产品来完成 X?
[AI 回答]:推荐使用 XR-2Z 产品。
但这个产品也许根本不存在!
解决方法:让 AI 回答基于你的真实数据
为了解决“凭空捏造”的问题,可以用 RAG(检索增强生成):
先查资料:根据问题去搜索你提供的真实数据;
再答问题:让 AI 用查到的资料来生成回答。
这样,AI 生成的内容不仅语法正确,而且内容真实、信息有据。
RAG 的流程长啥样?
用户提问
系统检索相关资料(文档、数据库等)
把这些资料加进 Prompt(提示词)
一起发送给语言模型(比如 GPT-4)
AI 基于资料回答问题
如何让 Azure 的 AI 知道“你的数据”?
可以用 Azure AI Foundry 来构建自己的“智能助手(Agent)”,让它查指定的数据,再结合大模型生成回答。支持的数据来源包括:
Azure Blob 存储
Azure Data Lake Storage Gen2
Microsoft OneLake
上传的文档(PDF、Word、文本等)
检索数据用什么工具?
最常用的是 Azure AI Search ——它可以对文件和数据内容建立搜索索引,让 AI 快速查找资料。常见检索方式:
关键词搜索:匹配词语
语义搜索:理解含义
向量搜索:找“意思相近”的内容
混合搜索:关键词 + 向量,效果更好
什么是向量搜索?举个例子
这两句话意思很接近:
"The children played joyfully in the park."
"Kids happily ran around the playground."
这两段文字虽然用词不同,但在语义上是相近的。通过为文本生成向量嵌入,可以用数学方式计算它们之间的语义关系。
你可以想象把这些文档中的关键词提取出来,并在一个多维空间中以向量形式表示:
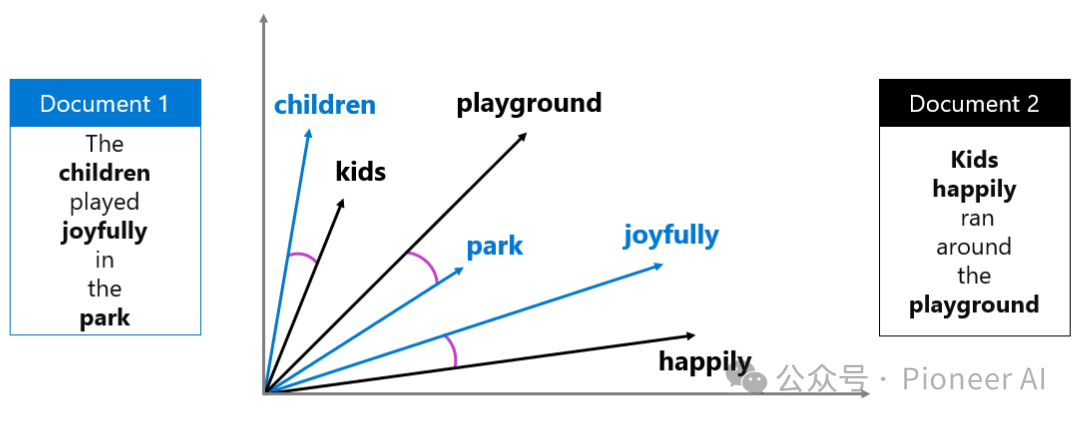
通过用向量表示词语及其含义,即便你的数据来源包含不同格式(如文本或图片)或语言,系统也能从中提取出相关的上下文信息。
如果你希望使用向量搜索来查询数据,就需要在创建搜索索引时生成嵌入向量。你可以使用 Azure AI Foundry中提供的 Azure OpenAI嵌入模型来为你的搜索索引生成这些向量。
如何在 Azure 上配置搜索索引?
上传数据到 Azure AI Foundry;
系统会自动生成嵌入向量;
使用 Azure AI Search 创建索引;
在应用中引用该索引完成智能问答。
总结:为什么要用 RAG?
问题 | 没有 RAG | 使用 RAG |
|---|---|---|
回答真实度 | 可能编造、不准确 | 结合真实数据,信息可靠 |
上下文支持 | 无法引用文档内容 | 可检索并引用数据 |
应用场景 | 仅限通用问答 | 企业数据问答、产品推荐等更多场景 |
如果想构建一个基于自有数据、真实可靠的智能问答系统,RAG 值得一试。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









