







爬虫下载精美图片
测试网站为:https://pic.netbian.com/4kdongwu/
from pyquery import PyQuery as pq
import urllib.request as urq
import urllib.response
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
doc=pq(url='https://pic.netbian.com/4kdongwu/')
a=doc('#main ul li a ')
mylist=[]
for i in a:
mylist.append(i.attrib['href'])
print(mylist)
dec='https://pic.netbian.com'
addr = 'pic.netbian.com'
for i in mylist:
xx=pq(url=dec+i)
# hr=xx('.photo-pic #img img')
hr=xx('#main .photo .view .photo-pic img') #.photo .view .photo-pic
xxy=hr.attr('src')
name=xxy.split('/')[-1]
# T urllib
request=urq.Request(dec+xxy,headers=headers)
response=urq.urlopen(request)
with open('vm3/'+name,'wb') as f:
f.write(response.read())
代码的步骤是
1.设置响应头
2.用pq获取数据doc
3.将首页 小图片里面的链接属性加到列表
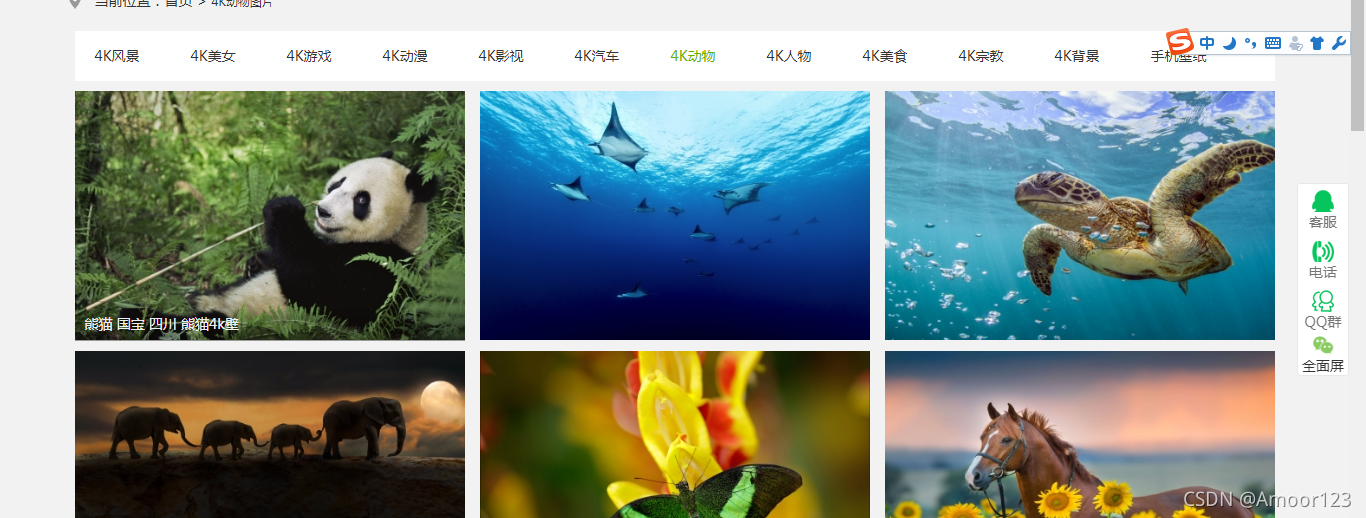
这是小图片
4.针对列表里面的每个网址提取后面的大图的地址

这是大图片
5.取得网址后分解得到文件名
6.用urllib的request获取图片数据
7.保存图片















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











