







内容都是百度AIstudio的内容,我只是在这里做个笔记,不是原创。
训练并保存好模型,我们可以开始实践电影推荐了,推荐方式可以有多种,比如:
- 根据一个电影推荐其相似的电影。
- 根据用户的喜好,推荐其可能喜欢的电影。
- 给指定用户推荐与其喜好相似的用户喜欢的电影。
这里我们实现第二种推荐方式,另外两种留作实践作业。
根据用户喜好推荐电影
在前面章节,我们已经完成了神经网络的设计,并根据用户对电影的喜好(评分高低)作为训练指标完成训练。神经网络有两个输入,用户数据和电影数据,通过神经网络提取用户特征和电影特征,并计算特征之间的相似度,相似度的大小和用户对该电影的评分存在对应关系。即如果用户对这个电影感兴趣,那么对这个电影的评分也是偏高的,最终神经网络输出的相似度就更大一些。完成训练后,我们就可以开始给用户推荐电影了。
根据用户喜好推荐电影,是通过计算用户特征和电影特征之间的相似性,并排序选取相似度最大的结果来进行推荐,流程如下:

从计算相似度到完成推荐的过程,步骤包括:
- 读取保存的特征,根据一个给定的用户ID、电影ID,我们可以索引到对应的特征向量。
- 通过计算用户特征和其他电影特征向量的相似度,构建相似度矩阵。
- 对这些相似度排序后,选取相似度最大的几个特征向量,找到对应的电影ID,即得到推荐清单。
- 加入随机选择因素,从相似度最大的top_k结果中随机选取pick_num个推荐结果,其中pick_num必须小于top_k。
1. 读取特征向量
上一节我们已经训练好模型,并保存了电影特征,因此可以不用经过计算特征的步骤,直接读取特征。 特征以字典的形式保存,字典的键值是用户或者电影的ID,字典的元素是该用户或电影的特征向量。
下面实现根据指定的用户ID和电影ID,索引到对应的特征向量。
import pickle
import numpy as np
mov_feat_dir = 'mov_feat.pkl'
usr_feat_dir = 'usr_feat.pkl'
usr_feats = pickle.load(open(usr_feat_dir, 'rb'))
mov_feats = pickle.load(open(mov_feat_dir, 'rb'))
usr_id = 2
usr_feat = usr_feats[str(usr_id)]
mov_id = 1
# 通过电影ID索引到电影特征
mov_feat = mov_feats[str(mov_id)]
# 电影特征的路径
movie_data_path = "./work/ml-1m/movies.dat"
mov_info = {}
# 打开电影数据文件,根据电影ID索引到电影信息
with open(movie_data_path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
for item in data:
item = item.strip().split("::")
mov_info[str(item[0])] = item
usr_file = "./work/ml-1m/users.dat"
usr_info = {}
# 打开文件,读取所有行到data中
with open(usr_file, 'r') as f:
data = f.readlines()
for item in data:
item = item.strip().split("::")
usr_info[str(item[0])] = item
print("当前的用户是:")
print("usr_id:", usr_id, usr_info[str(usr_id)])
print("对应的特征是:", usr_feats[str(usr_id)])
print("\n当前电影是:")
print("mov_id:", mov_id, mov_info[str(mov_id)])
print("对应的特征是:")
print(mov_feat)


2. 计算用户和所有电影的相似度,构建相似度矩阵
如下示例均以向 userid = 2 的用户推荐电影为例。与训练一致,以余弦相似度作为相似度衡量。
import paddle.fluid as fluid
import paddle.fluid.dygraph as dygraph
# 根据用户ID获得该用户的特征
usr_ID = 2
# 读取保存的用户特征
usr_feat_dir = 'usr_feat.pkl'
usr_feats = pickle.load(open(usr_feat_dir, 'rb'))
# 根据用户ID索引到该用户的特征
usr_ID_feat = usr_feats[str(usr_ID)]
# 记录计算的相似度
cos_sims = []
# 记录下与用户特征计算相似的电影顺序
with dygraph.guard():
# 索引电影特征,计算和输入用户ID的特征的相似度
for idx, key in enumerate(mov_feats.keys()):
mov_feat = mov_feats[key]
usr_feat = dygraph.to_variable(usr_ID_feat)
mov_feat = dygraph.to_variable(mov_feat)
# 计算余弦相似度
sim = fluid.layers.cos_sim(usr_feat, mov_feat)
# 打印特征和相似度的形状
if idx==0:
print("电影特征形状:{}, 用户特征形状:{}, 相似度结果形状:{},相似度结果:{}".format(mov_feat.shape, usr_feat.shape, sim.numpy().shape, sim.numpy()))
# 从形状为(1,1)的相似度sim中获得相似度值sim.numpy()[0][0],并添加到相似度列表cos_sims中
cos_sims.append(sim.numpy()[0][0])
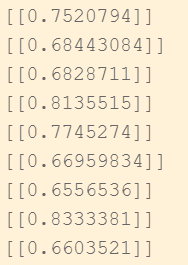
![]()
sim.numpy()长这样,所以需要[0][0]
3. 对相似度排序,选出最大相似度
使用np.argsort()函数完成从小到大的排序,注意返回值是原列表位置下标的数组。因为cos_sims 和 mov_feats.keys()的顺序一致,所以都可以用index数组的内容索引,获取最大的相似度值和对应电影。
处理流程是先计算相似度列表 cos_sims,将其排序后返回对应的下标列表 index,最后从cos_sims和mov_info中取出相似度值和对应的电影信息。
# 对相似度排序,获得最大相似度在cos_sims中的位置
index = np.argsort(cos_sims)
# 打印相似度最大的前topk个位置
topk = 5
print("相似度最大的前{}个索引是{}\n对应的相似度是:{}\n".format(topk, index[-topk:], [cos_sims[k] for k in index[-topk:]]))
for i in index[-topk:]:
print("对应的电影分别是:movie:{}".format(mov_info[list(mov_feats.keys())[i]]))
4.加入随机选择因素,使得每次推荐的结果有“新鲜感”
为了确保推荐的多样性,维持用户阅读推荐内容的“新鲜感”,每次推荐的结果需要有所不同,我们随机抽取top_k结果中的一部分,作为给用户的推荐。比如从相似度排序中获取10个结果,每次随机抽取6个结果推荐给用户。
使用np.random.choice函数实现随机从top_k中选择一个未被选的电影,不断选择直到选择列表res长度达到pick_num为止,其中pick_num必须小于top_k。
读者可以反复运行本段代码,观测推荐结果是否有所变化。
代码实现如下:
top_k, pick_num = 10, 6
# 对相似度排序,获得最大相似度在cos_sims中的位置
index = np.argsort(cos_sims)[-top_k:]
print("当前的用户是:")
# usr_id, usr_info 是前面定义、读取的用户ID、用户信息
print("usr_id:", usr_id, usr_info[str(usr_id)])
print("推荐可能喜欢的电影是:")
res = []
# 加入随机选择因素,确保每次推荐的结果稍有差别
while len(res) < pick_num:
val = np.random.choice(len(index), 1)[0]
idx = index[val]
mov_id = list(mov_feats.keys())[idx]
if mov_id not in res:
res.append(mov_id)
for id in res:
print("mov_id:", id, mov_info[str(id)])

最后,我们将根据用户ID推荐电影的实现封装成一个函数,方便直接调用,其函数实现如下。
# 定义根据用户兴趣推荐电影
def recommend_mov_for_usr(usr_id, top_k, pick_num, usr_feat_dir, mov_feat_dir, mov_info_path):
assert pick_num <= top_k
# 读取电影和用户的特征
usr_feats = pickle.load(open(usr_feat_dir, 'rb'))
mov_feats = pickle.load(open(mov_feat_dir, 'rb'))
usr_feat = usr_feats[str(usr_id)]
cos_sims = []
with dygraph.guard():
# 索引电影特征,计算和输入用户ID的特征的相似度
for idx, key in enumerate(mov_feats.keys()):
mov_feat = mov_feats[key]
usr_feat = dygraph.to_variable(usr_feat)
mov_feat = dygraph.to_variable(mov_feat)
sim = fluid.layers.cos_sim(usr_feat, mov_feat)
cos_sims.append(sim.numpy()[0][0])
# 对相似度排序
index = np.argsort(cos_sims)[-top_k:]
mov_info = {}
# 读取电影文件里的数据,根据电影ID索引到电影信息
with open(mov_info_path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
for item in data:
item = item.strip().split("::")
mov_info[str(item[0])] = item
print("当前的用户是:")
print("usr_id:", usr_id)
print("推荐可能喜欢的电影是:")
res = []
# 加入随机选择因素,确保每次推荐的都不一样
while len(res) < pick_num:
val = np.random.choice(len(index), 1)[0]
idx = index[val]
mov_id = list(mov_feats.keys())[idx]
if mov_id not in res:
res.append(mov_id)
for id in res:
print("mov_id:", id, mov_info[str(id)])
movie_data_path = "./work/ml-1m/movies.dat"
top_k, pick_num = 10, 6
usr_id = 1
recommend_mov_for_usr(usr_id, top_k, pick_num, 'usr_feat.pkl', 'mov_feat.pkl', movie_data_path)
从上面的推荐结果来看,给ID为2的用户推荐的电影多是Drama、War类型的。我们可以通过用户的ID从已知的评分数据中找到其评分最高的电影,观察和推荐结果的区别。
下面代码实现给定用户ID,输出其评分最高的topk个电影信息,通过对比用户评分最高的电影和当前推荐的电影结果,观察推荐是否有效。
# 给定一个用户ID,找到评分最高的topk个电影
usr_a = 1
topk = 10
##########################################
## 获得ID为usr_a的用户评分过的电影及对应评分 ##
##########################################
rating_path = "./work/ml-1m/ratings.dat"
# 打开文件,ratings_data
with open(rating_path, 'r') as f:
ratings_data = f.readlines()
usr_rating_info = {}
for item in ratings_data:
item = item.strip().split("::")
# 处理每行数据,分别得到用户ID,电影ID,和评分
usr_id,movie_id,score = item[0],item[1],item[2]
if usr_id == str(usr_a):
usr_rating_info[movie_id] = float(score)
# 获得评分过的电影ID
movie_ids = list(usr_rating_info.keys())
print("ID为 {} 的用户,评分过的电影数量是: ".format(usr_a), len(movie_ids))
#####################################
## 选出ID为usr_a评分最高的前topk个电影 ##
#####################################
ratings_topk = sorted(usr_rating_info.items(), key=lambda item:item[1])[-topk:]
movie_info_path = "./work/ml-1m/movies.dat"
# 打开文件,编码方式选择ISO-8859-1,读取所有数据到data中
with open(movie_info_path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
movie_info = {}
for item in data:
item = item.strip().split("::")
# 获得电影的ID信息
v_id = item[0]
movie_info[v_id] = item
for k, score in ratings_topk:
print("电影ID: {},评分是: {}, 电影信息: {}".format(k, score, movie_info[k]))

通过上述代码的输出可以发现,Drama类型的电影是用户喜欢的类型,可见推荐结果和用户喜欢的电影类型是匹配的。但是推荐结果仍有一些不足的地方,这些可以通过改进神经网络模型等方式来进一步调优。
几点思考收获
-
Deep Learning is all about “Embedding Everything”。不难发现,深度学习建模是套路满满的。任何事物均用向量的方式表示,可以直接基于向量完成“分类”或“回归”任务;也可以计算多个向量之间的关系,无论这种关系是“相似性”还是“比较排序”。在深度学习兴起不久的2015年,当时AI相关的国际学术会议上,大部分论文均是将某个事物Embedding后再进行挖掘,火热的程度仿佛即使是路边一块石头,也要Embedding一下看看是否能挖掘出价值。直到近些年,能够Embedding的事物基本都发表过论文,Embeddding的方法也变得成熟,这方面的论文才逐渐有减少的趋势。
-
在深度学习兴起之前,不同领域之间的迁移学习往往要用到很多特殊设计的算法。但深度学习兴起后,迁移学习变得尤其自然。训练模型和使用模型未必是同样的方式,中间基于Embedding的向量表示,即可实现不同任务交换信息。例如本章的推荐模型使用用户对电影的评分数据进行监督训练,训练好的特征向量可以用于计算用户与用户的相似度,以及电影与电影之间的相似度。对特征向量的使用可以极其灵活,而不局限于训练时的任务。
-
网络调参:神经网络模型并没有一套理论上可推导的最优规则,实际中的网络设计往往是在理论和经验指导下的“探索”活动。例如推荐模型的每层网络尺寸的设计遵从了信息熵的原则,原始信息量越大对应表示的向量长度就越长。但具体每一层的向量应该有多长,往往是根据实际训练的效果进行调整。所以,建模工程师被称为数据处理工程师和调参工程师是有道理的,大量的精力花费在处理样本数据和模型调参上。
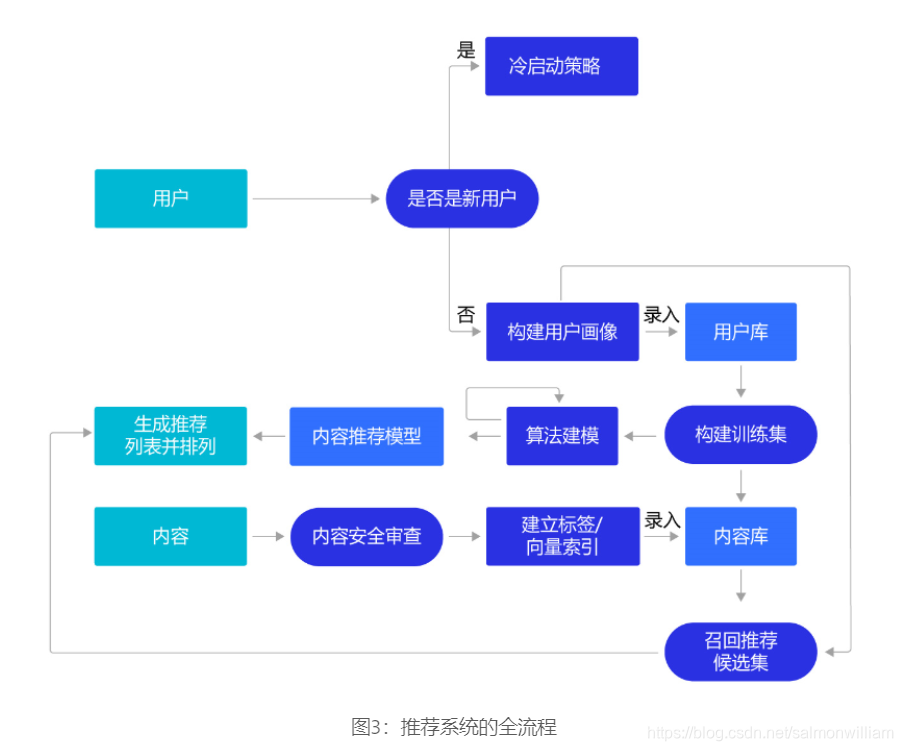
在工业实践中的推荐系统
本章介绍了比较简单的推荐系统构建方法,在实际应用中,验证一个推荐系统的好坏,除了预测准确度,还需要考虑多方面的因素,比如多样性、新颖性,甚至商业目标匹配度等。要实践一个好的推荐系统,值得更深入的探索研究。下面将工业实践推荐系统还需要考虑的主要问题做一个概要性的介绍。
1. 推荐来源:推荐来源会更加多样化,除了使用深度学习模型的方式,还大量使用标签匹配的个性化推荐方式。此外,推荐热门的内容,具有时效性的内容和一定探索性的内容,都非常关键。对于新闻类的内容推荐,用户不希望地球人都在谈论的大事自己毫无所知,期望更快更全面的了解。如果用户经常使用的推荐产品总推荐“老三样”,会使得用户丧失“新鲜感”而流失。因此,除了推荐一些用户喜欢的内容之外,谨慎的推荐一些用户没表达过喜欢的内容,可探索用户更广泛的兴趣领域,以便有更多不重复的内容可以向用户推荐。
2. 检索系统:将推荐系统构建成“召回+排序”架构的高性能检索系统,以更短的特征向量建倒排索引。在“召回+排序”的架构下,通常会训练出两种不同长度的特征向量,使用较短的特征向量做召回系统,从海量候选中筛选出几十个可能候选。使用较短的向量做召回,性能高但不够准确,然后使用较长的特征向量做几十个候选的精细排序,因为待排序的候选很少,所以性能低一些也影响不大。
3. 冷启动问题:现实中推荐系统往往要在产品运营的初期一起上线,但这时候系统尚没有用户行为数据的积累。这时,我们往往建立一套专家经验的规则系统,比如一个在美妆行业工作的店小二对各类女性化妆品偏好是非常了解的。通过规则系统运行一段时间积累数据后,再逐渐转向机器学习的系统。很多推荐系统也会主动向用户收集一些信息,比如大家注册一些资讯类APP时,经常会要求选择一些兴趣标签。
4. 推荐系统的评估:推荐系统的评估不仅是计算模型Loss所能代表的,是使用推荐系统用户的综合体验。除了采用更多代表不同体验的评估指标外(准确率、召回率、覆盖率、多样性等),还会从两个方面收集数据做分析:
(1)行为日志:如用户对推荐内容的点击率,阅读市场,发表评论,甚至消费行为等。
(2)人工评估:选取不同的具有代表性的评估员,从兴趣相关度、内容质量、多样性、时效性等多个维度评估。如果评估员就是用户,通常是以问卷调研的方式下发和收集。
其中,多样性的指标是针对探索性目标的。而推荐的覆盖度也很重要,代表了所有的内容有多少能够被推荐系统送到用户面前。如果推荐每次只集中在少量的内容,大部分内容无法获得用户流量的话,会影响系统内容生态的健康。比如电商平台如果只推荐少量大商家的产品给用户,多数小商家无法获得购物流量,会导致平台上的商家集中度越来越高,生态不再繁荣稳定。
从上述几点可见,搭建一套实用的推荐系统,不只是一个有效的推荐模型。要从业务的需求场景出发,构建完整的推荐系统,最后再实现模型的部分。如果技术人员的视野只局限于模型本身,是无法在工业实践中搭建一套有业务价值的推荐系统的。














 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









